B
grep
grep命令

目录
[toc]
介绍
SHELL四剑客之二的Grep工具,主要是用于查找Linux操作系统 某个文本文件中关键词,可以根据指定关键词去文本文件中匹配;
Grep工具的语法格式:
bash
grep–option(参数)word(关键词|正则)file(文本文件);Option参数:
-a(文本方式)、-c(统计)、-i(忽略大小写)、-n(行号)、-v(反选)、-w(词组)、-o(打印匹配)、-A(匹 配之后)、-B(匹配之前)、-C(匹配前后)等;
选项
grep是一个强大的文本搜索工具,常用于查找文件中的特定模式。以下是一些常见的 grep选项及其含义:
-E选项允许使用扩展正则表达式。
-i:忽略大小写进行匹配。bashgrep-i"pattern"filename-v:反向匹配,输出不匹配模式的行。bashgrep-v"pattern"filename-r或-R:递归搜索,搜索指定目录及其子目录中的文件。bashgrep-r"pattern"directory/-l:只输出匹配模式的文件名,而不输出匹配的行。bashgrep-l"pattern"*-n:在输出中显示匹配行的行号。bashgrep-n"pattern"filename-c:输出每个文件中匹配模式的行数。bashgrep-c"pattern"filename-w:只匹配整个单词。bashgrep-w"pattern"filename-A:在匹配行之后输出指定数量的行。bashgrep-A3"pattern"filename# 输出匹配行及其后面3行-B:在匹配行之前输出指定数量的行。bashgrep-B3"pattern"filename# 输出匹配行及其前面3行-C:在匹配行之前和之后输出指定数量的行。bashgrep-C3"pattern"filename# 输出匹配行及其上下各3行-q:安静模式,不输出任何内容,只返回退出状态(0 表示找到匹配,1 表示未找到)。bashgrep-q"pattern"filename--color:高亮显示匹配的部分,便于查看。bashgrep--color"pattern"filename
这些选项可以组合使用,以满足特定的搜索需求。通过熟练使用这些选项,可以更高效地找到所需的信息。
案例:反选 -v
如果要进行反向搜索(输出不匹配该模式的行),可加-v参数。
bash
$ls-ltRdocs|grep".md"|grep-v"^d"|head-n10-rw-r--r--1Win19712188912月815:303、latestUpdateArcticleTop10.md-rw-r--r--1Win1971213112月814:572、网站监控.md-rw-r--r--1Win197121191212月814:571、关于本站.md-rw-r--r--1Win197121579512月807:01微信公众号排版工具.md-rw-r--r--1Win197121287612月612:45_博客模板.md-rw-r--r--1Win197121484812月409:20画图软件.md-rw-r--r--1Win197121226012月302:27录屏软件.md-rw-r--r--1Win19712117412月210:00字体.md-rw-r--r--1Win1971214827411月2912:45wiki.md-rw-r--r--1Win197121250911月2912:44IT技术logo.md案例:查看指定内容的前一行或后一行:-A 和 -B选项
bash
-B,--before-context=NUMprintNUMlinesofleadingcontext-A,--after-context=NUMprintNUMlinesoftrailingcontext#说明-A<显示行数>--after-context=<显示行数># 除了显示符合范本样式的那一行之外,并显示 该行之后的内容。-B<显示行数>--before-context=<显示行数># 除了显示符合样式的那一行之外,并显示该行 之前的内容。[root@k8s-master ~]#kubectl get service -o yaml|grepselector-A1#-A 1表示后一行, -B代表前一行[root@k8s-master ~]#kubectl get service -o yaml|grepselector-B1#-A 1表示后一行, -B代表前一行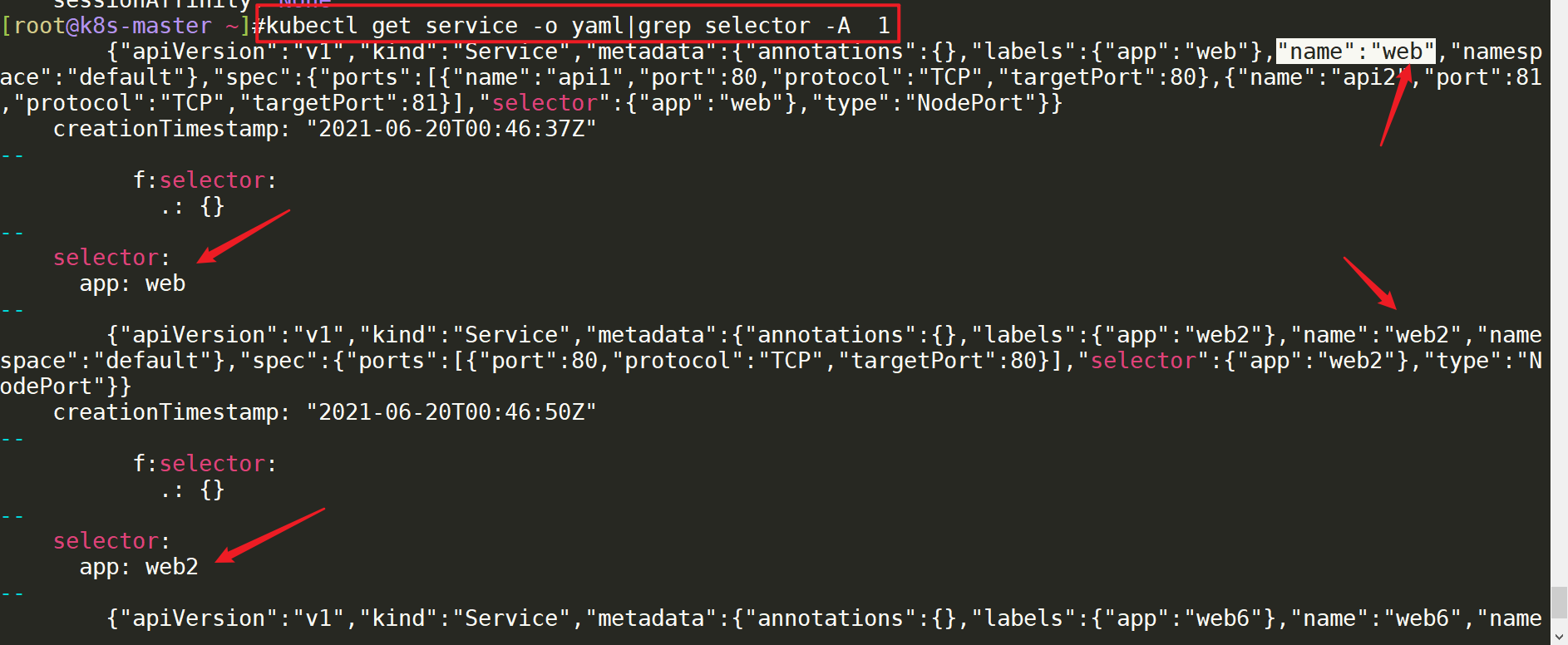

案例:-i选项忽略大小写查找匹配
- 例子:要检查定义就绪探针时使用的所有参数(比如initialDelaySeconds、periodSeconds等)的详细状态,运行kubectl describe命令。
bash
[root@k8s-master ~]#kubectl describe pod nginx |grep-ireadinessReadiness:http-gethttp:#-i选项说明:-i,--ignore-caseIgnorecasedistinctionsinboththePATTERNandtheinputfiles.(-i isspecifiedbyPOSIX.)
-E选项
案例1
bash
#选项说明-E,--extended-regexpInterpretPATTERNasanextendedregularexpression(ERE,seebelow). (-EisspecifiedbyPOSIX.)例子:[root@k8s-master ~]#journalctl -u kubelet |grep-E"failed|error"#查看k8s案例2
bash
[root@mysql ~]# mysql -uroot -e 'show databases'+--------------------+|Database|+--------------------+|db2||hellodb||hellodb2||information_schema||mysql||performance_schema|+--------------------+[root@mysql ~]# mysql -uroot -e 'show databases'|grep-Ev'^(Database|information_schema|performance_schema)$'db2hellodbhellodb2mysql案例:-o选项
grep命令里-o选项是什么意思?
在 grep命令中,-o选项用于仅显示匹配到的文本的实际内容,而不是整行。这意味着 grep -o将只输出与模式匹配的文本片段,而不是包含该文本的整行。
以下是一个简单的示例:
bash
[root@I ~]# echo "The quick brown fox"|grep-o'fox'fox[root@I ~]#在这个例子中,grep -o 'fox'将只输出字符串 "fox",而不是整个句子 "The quick brown fox"。
这对于从文本中提取特定模式的信息非常有用,特别是当你关心的是匹配文本的一部分而不是整个行的内容时。
grep正则提取字符串用法介绍
匹配特定字符
正则表达式可以使用特定的符号来匹配特定的字符。
示例代码:
bash
.表示匹配任意字符\d表示匹配数字\w表示匹配字母或数字\s表示匹配空白字符例如,要匹配任意一个字符加上“at”的字符串,可以使用以下命令:
bash
grep".at"file该命令将输出所有包含任意一个字符加上"at"的字符串。
匹配重复字符
正则表达式可以使用特定的符号来匹配重复出现的字符。
示例代码:
bash
*表示匹配前面的字符出现0次或多次+表示匹配前面的字符出现1次或多次?表示匹配前面的字符出现0次或1次{n} 表示匹配前面的字符出现n次{n,} 表示匹配前面的字符至少出现n次{n,m} 表示匹配前面的字符出现n到m次例如,要匹配一个字符串中至少重复一次的字母"o",可以使用以下命令:
bash
grep"o+"file该命令将输出任意包含至少重复一次字母"o"的字符串。
限定匹配范围
正则表达式可以使用特定的符号来限制匹配范围。
示例代码:
^ 表示匹配字符串的开头$ 表示匹配字符串的结尾[] 表示匹配字符集合中的任意一个字符[^ ] 表示匹配不在字符集合中的任意一个字符例如,要匹配以字母"t"开头的字符串,可以使用以下命令:
grep "^t"file该命令将输出所有以字母"t"开头的字符串。
使用分组匹配
正则表达式可以用括号将匹配项分组。
示例代码:
() 表示匹配项分组|表示或者关系\1 表示引用第一个匹配组例如,要匹配以数字开头、后面紧跟"-"或".",再后面是4个数字的字符串,可以使用以下命令:
grep "^(\d+[-.])?\d{4}$"file该命令将输出所有符合以上规则的字符串。
案例:去除空格和以#开头的行
bash
[root@test ~]# grep ^[^#] /etc/sudoersDefaults!visiblepwDefaultsalways_set_homeDefaultsmatch_group_by_gidDefaultsalways_query_group_pluginDefaultsenv_resetDefaultsenv_keep="COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"Defaultsenv_keep+="MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"Defaultsenv_keep+="LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"Defaultsenv_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"Defaultsenv_keep+="LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"Defaultssecure_path=/sbin:/bin:/usr/sbin:/usr/binrootALL=(ALL) ALL%wheelALL=(ALL) ALL[root@test ~]#案例:-w选项
bash
echo-e"\tVersion :$(cat/etc/os-release |grep-w"PRETTY_NAME"|cut-d=-f2|tr-d'"')"#-w,--word-regexp force PATTERN to match only whole words #-w、 --单词正则表达式强制PATTERN仅匹配整个单词
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 个人主页: