
Gitlab排错
Gitlab排错
目录
[toc]
2024.7.7-ts-Gitlab卡顿问题(宿主机内存使用率太高)(已解决)
1、报错现象
nuc 32g的内存被干的不行了(我nuc装的win11,然后里装vmwareworkstation跑devops环境),今天gitalb用起来经常出问题……
自己实验都做完了,最后一步从gitlab下载代码时,就卡顿了……
前面几次一直销毁k8s集群,再安装gitlab都是没问题的,但是单独重装gitlab一直起不来……
个人感觉很大程度是gitlab pod资源使用紧张问题(或者说是宿主机资源使用紧张)……
jenkin都没问题,但gitlab一直有问题……(卡顿)
- 故障现象就是点击Gitlab后卡顿,无法操作:
2、排查过程
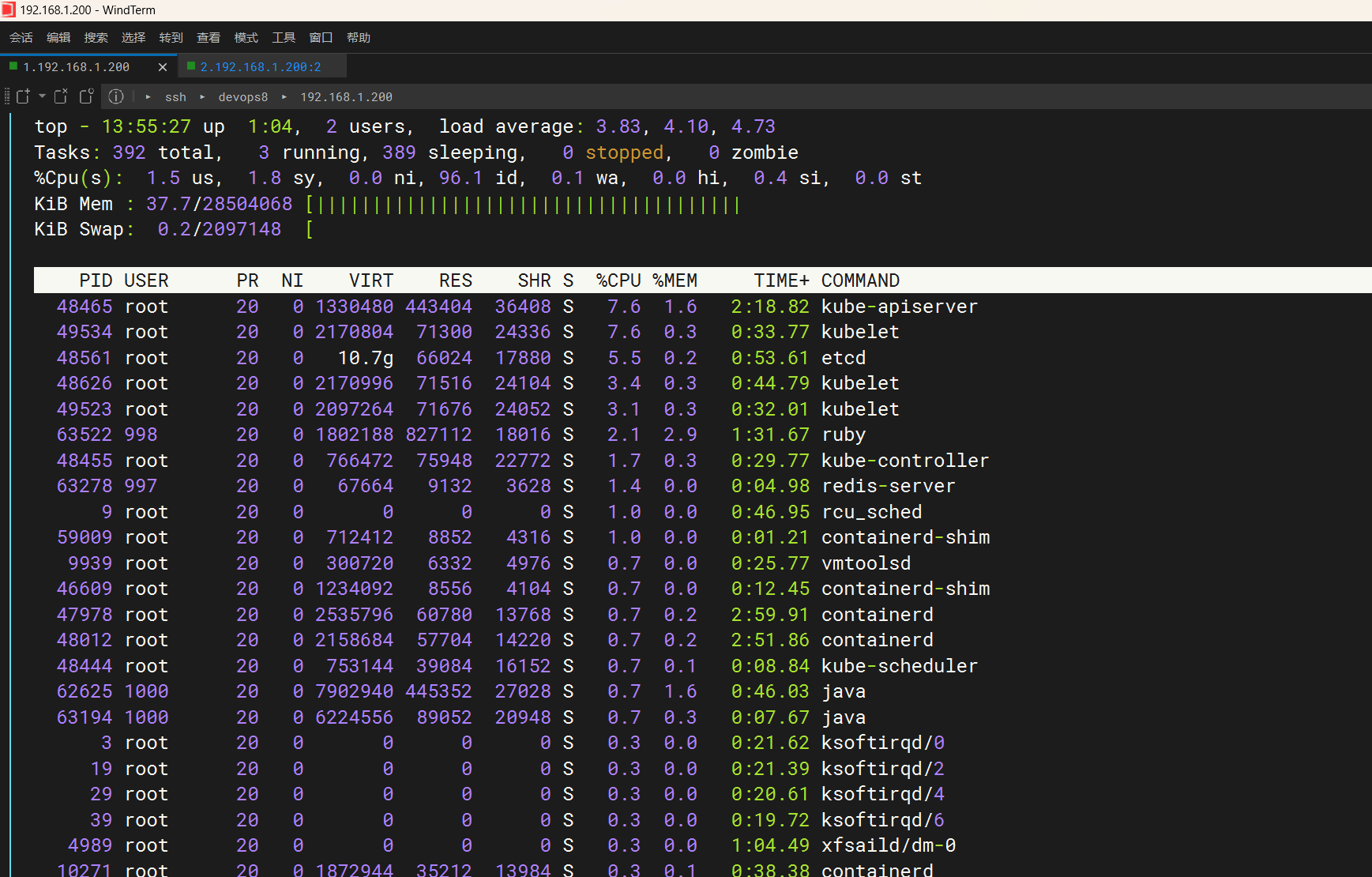
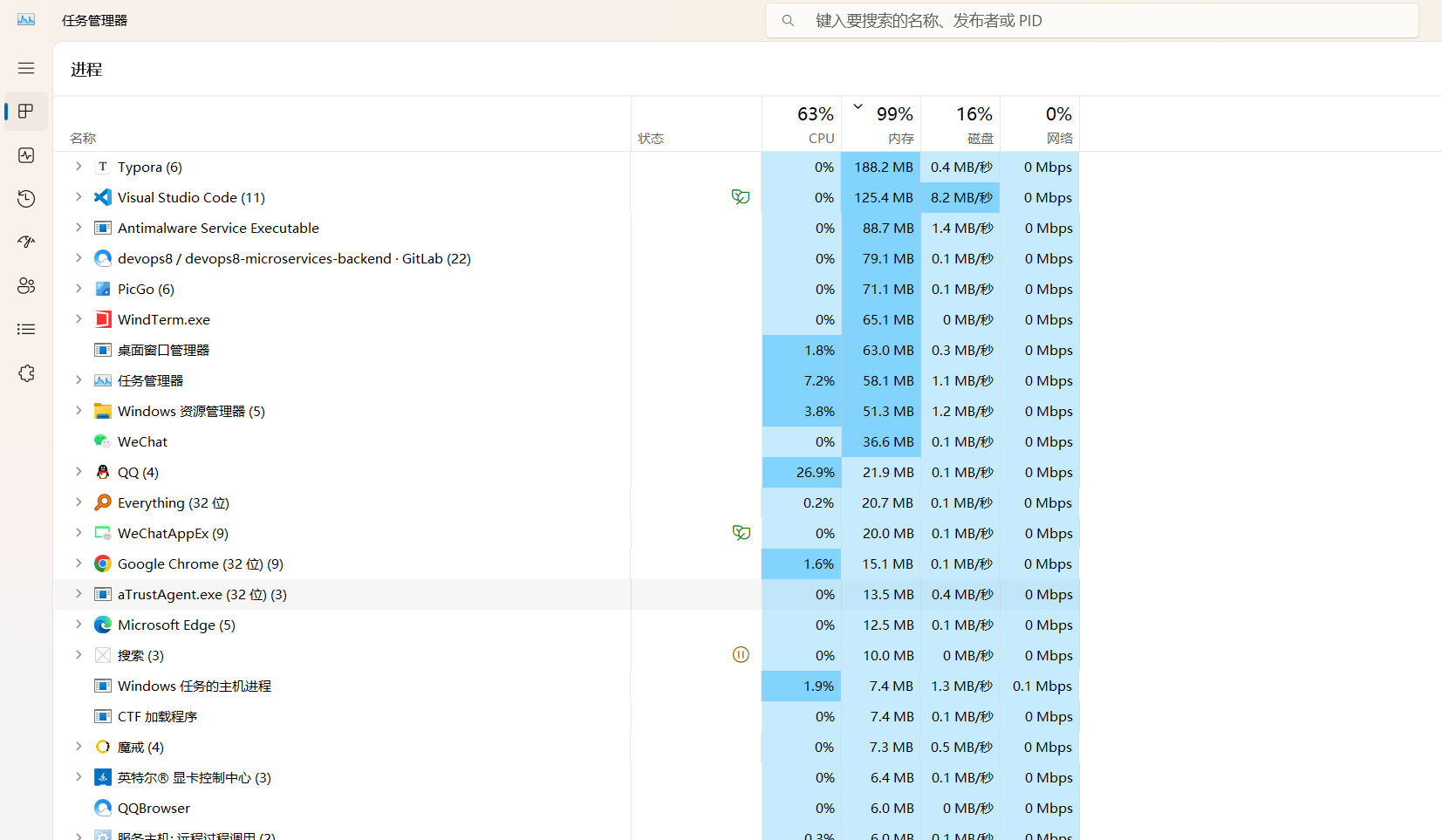
ee,自己gitlab卡顿感觉是因为自己pc(nuc)内存不够用了……
nuc内存达到93%左右
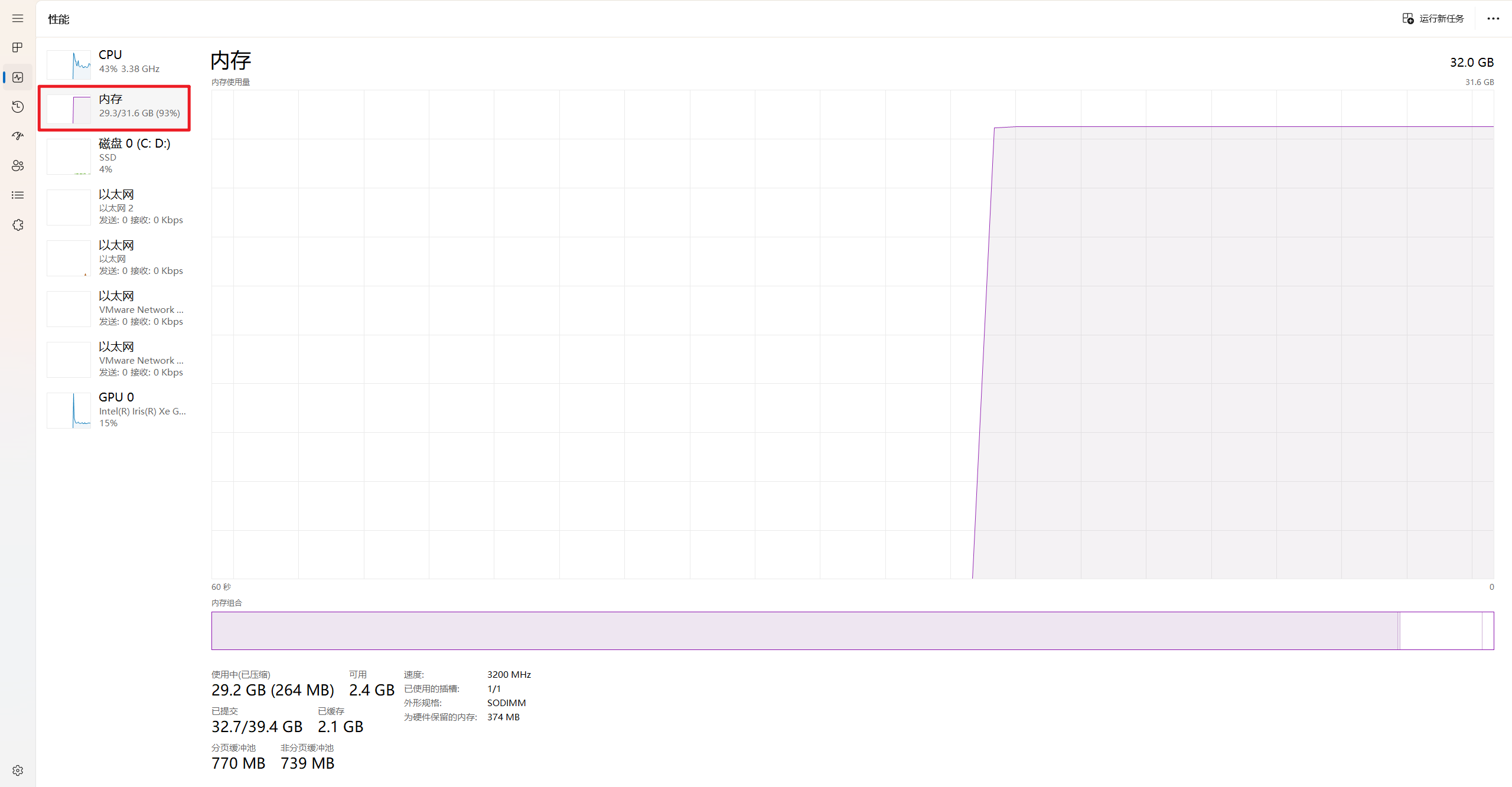
删除2个僵尸后还是有问题
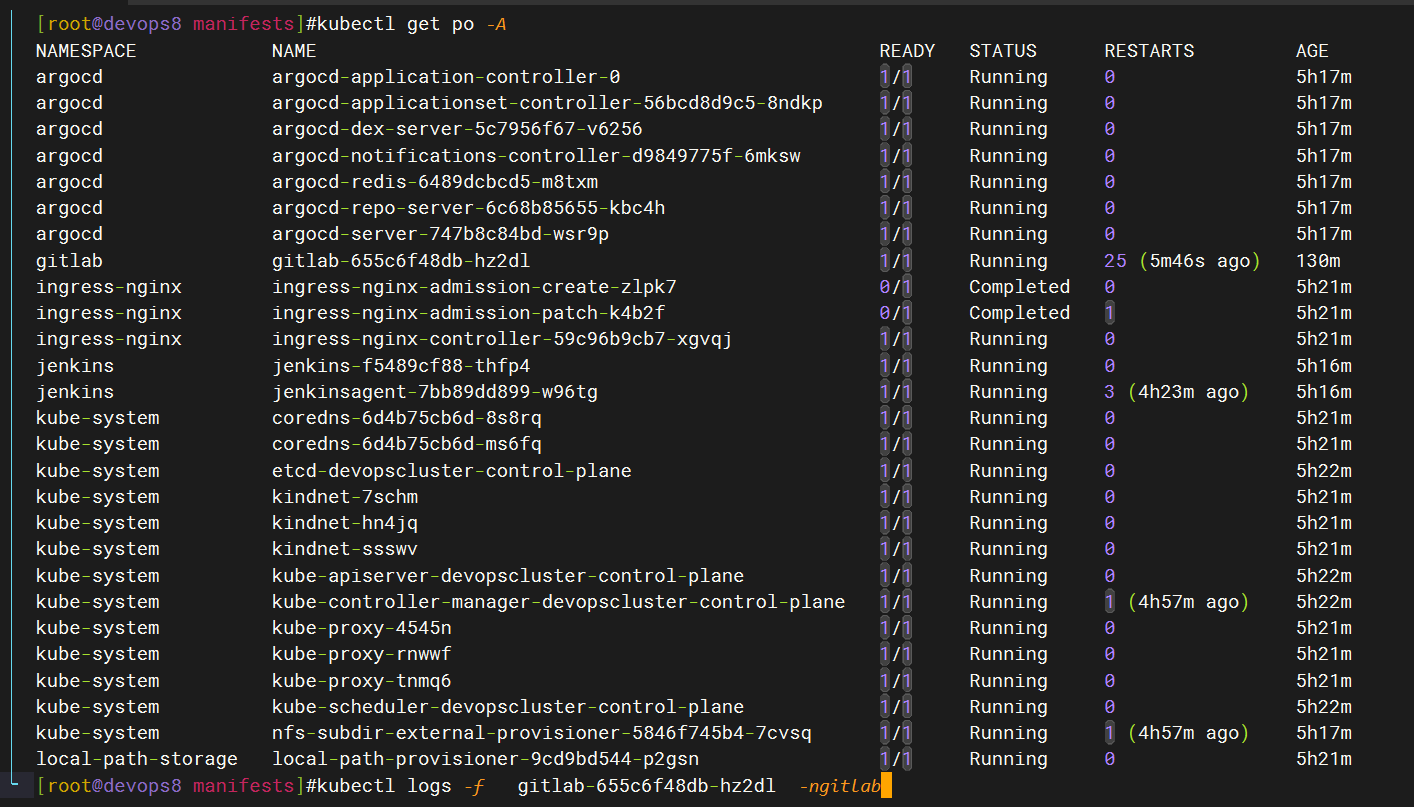
devops8虚机内存:
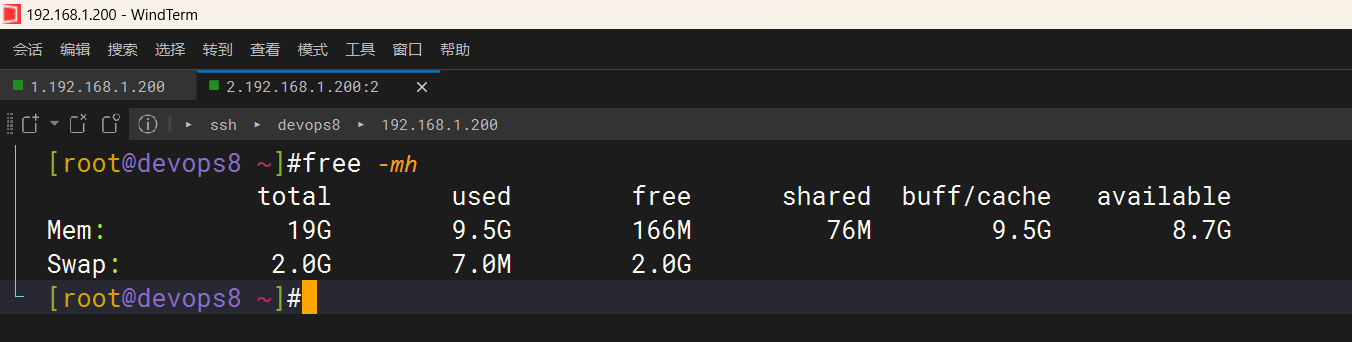
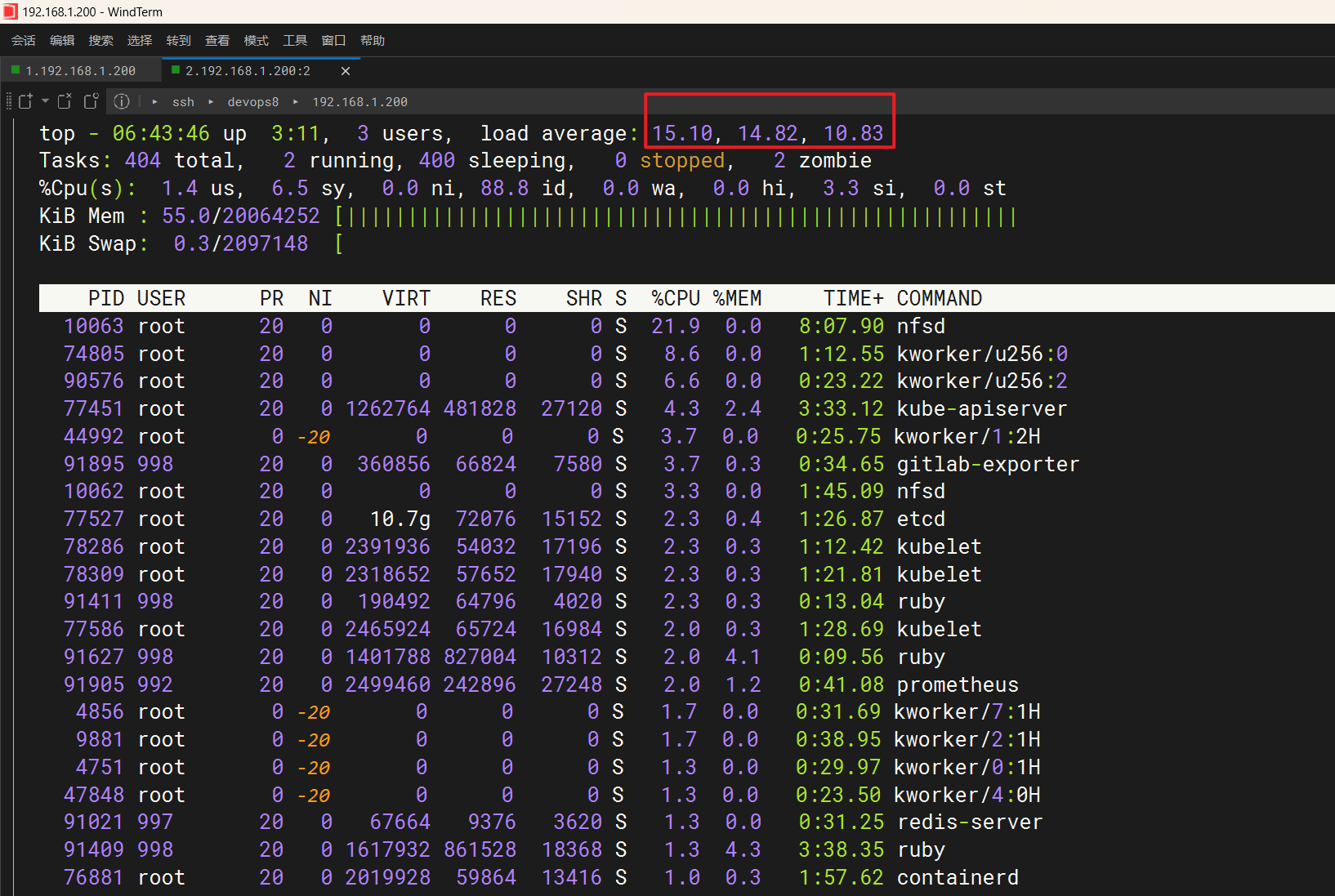
怎么还有僵尸进程……
处理过程:
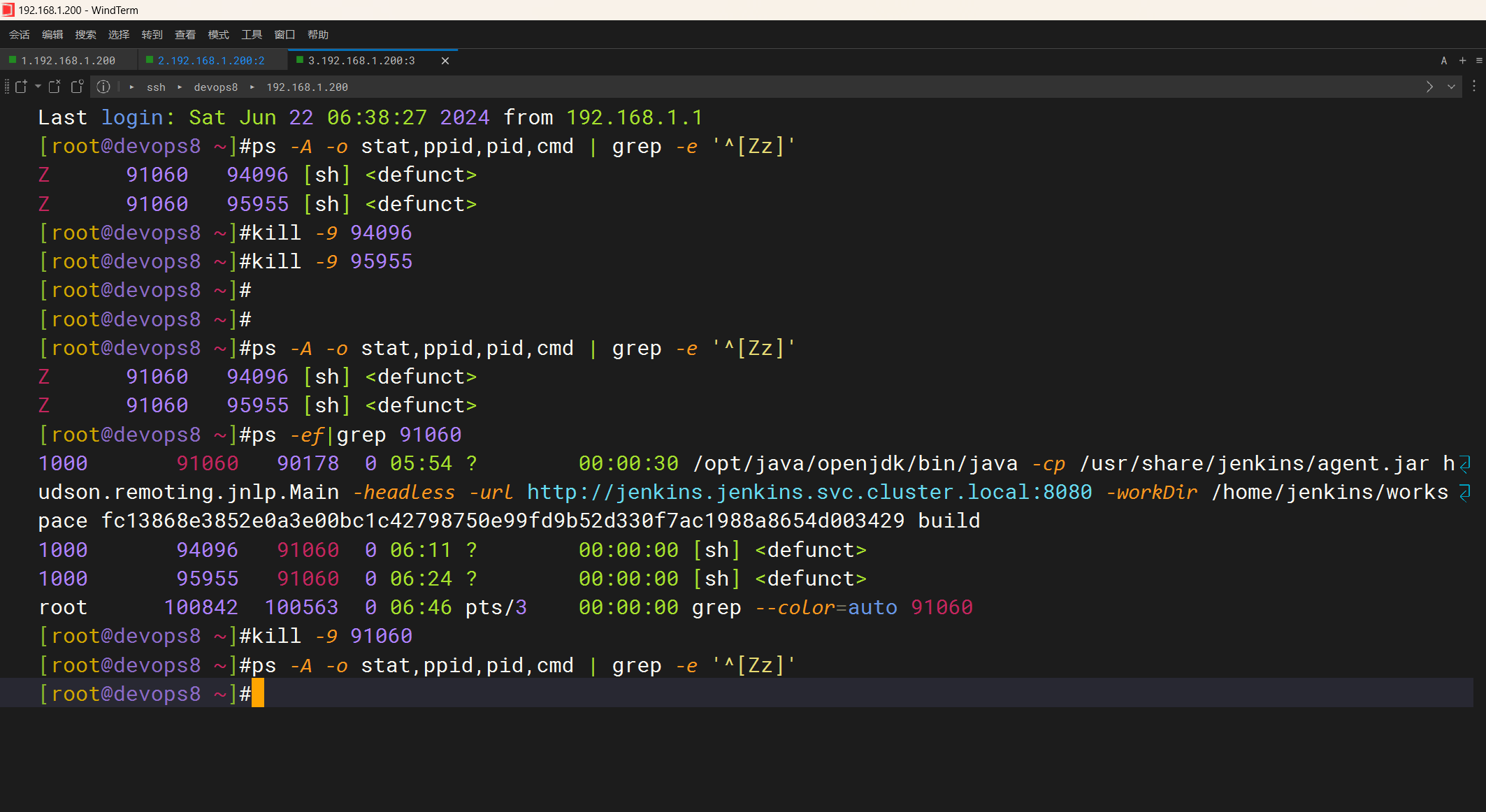
处理完后,可以看到僵尸进程被杀死了
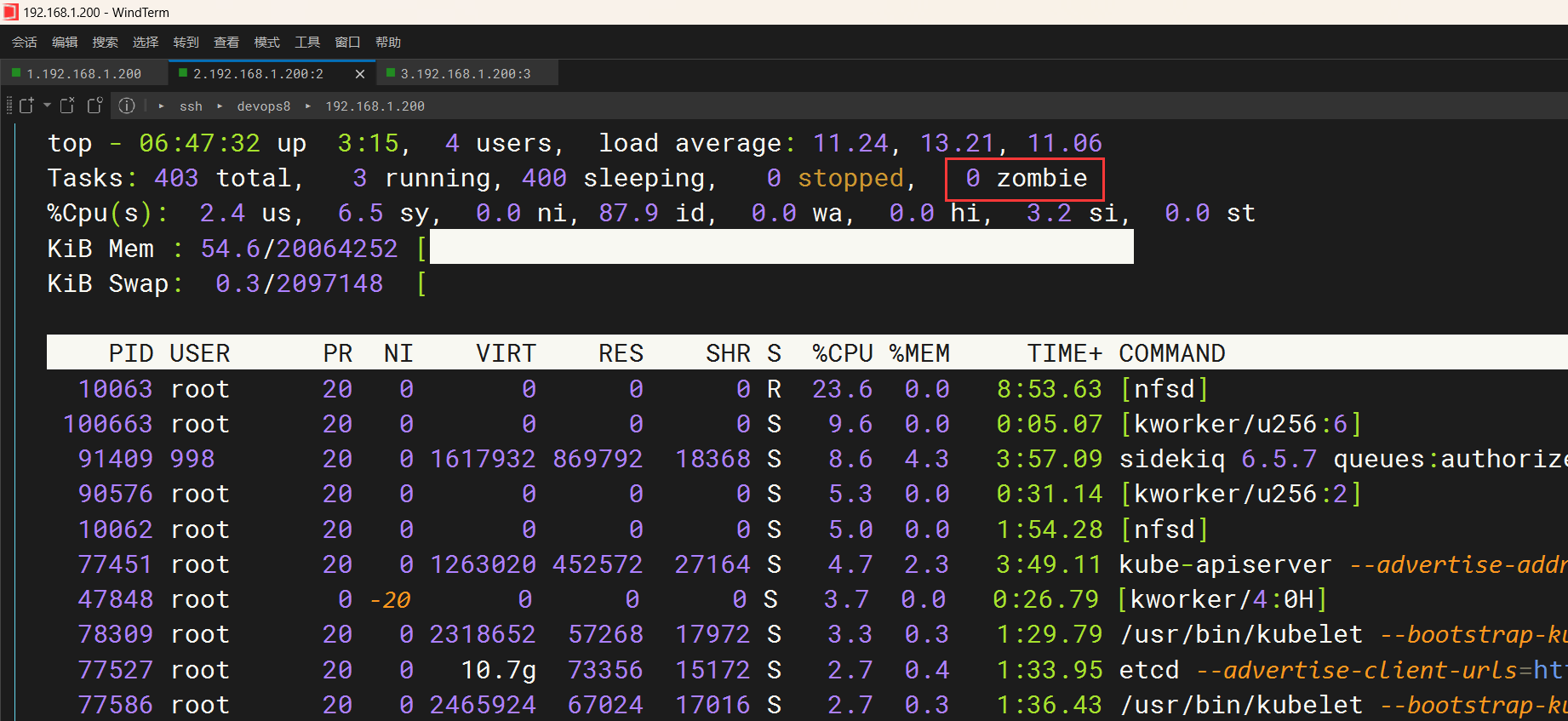
呃呃,果真jenkins-agent被杀死了……
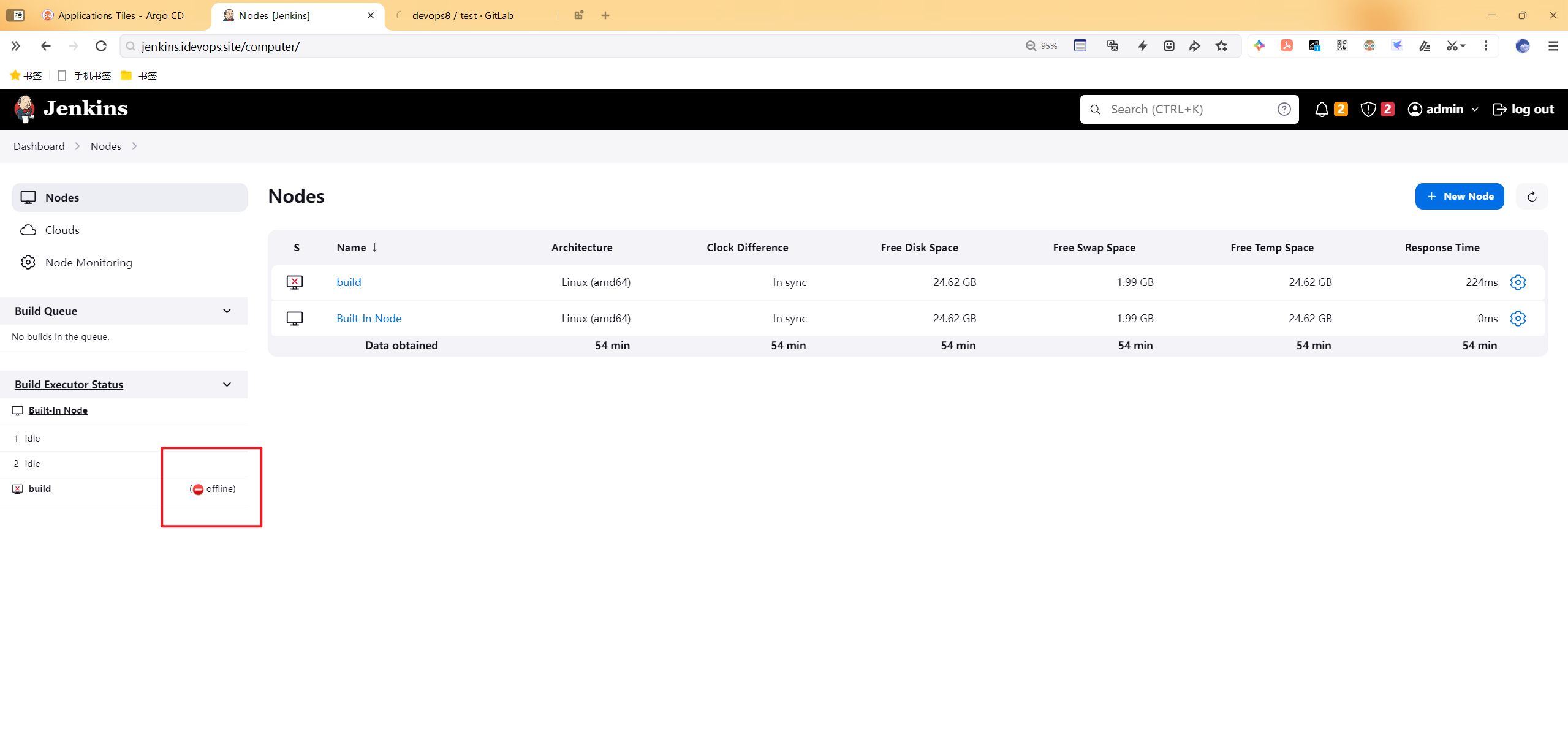
呃呃,自己又拉起来了
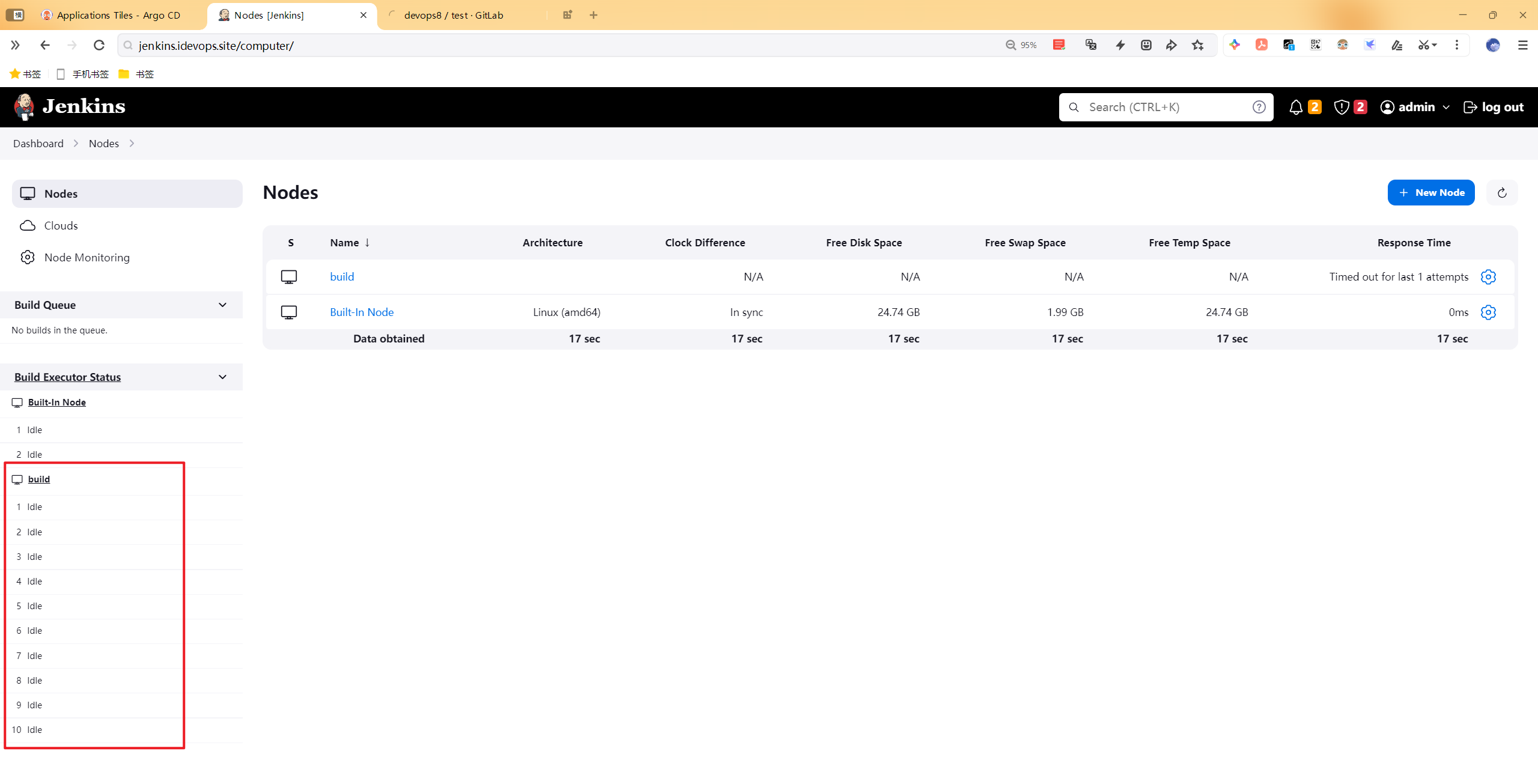
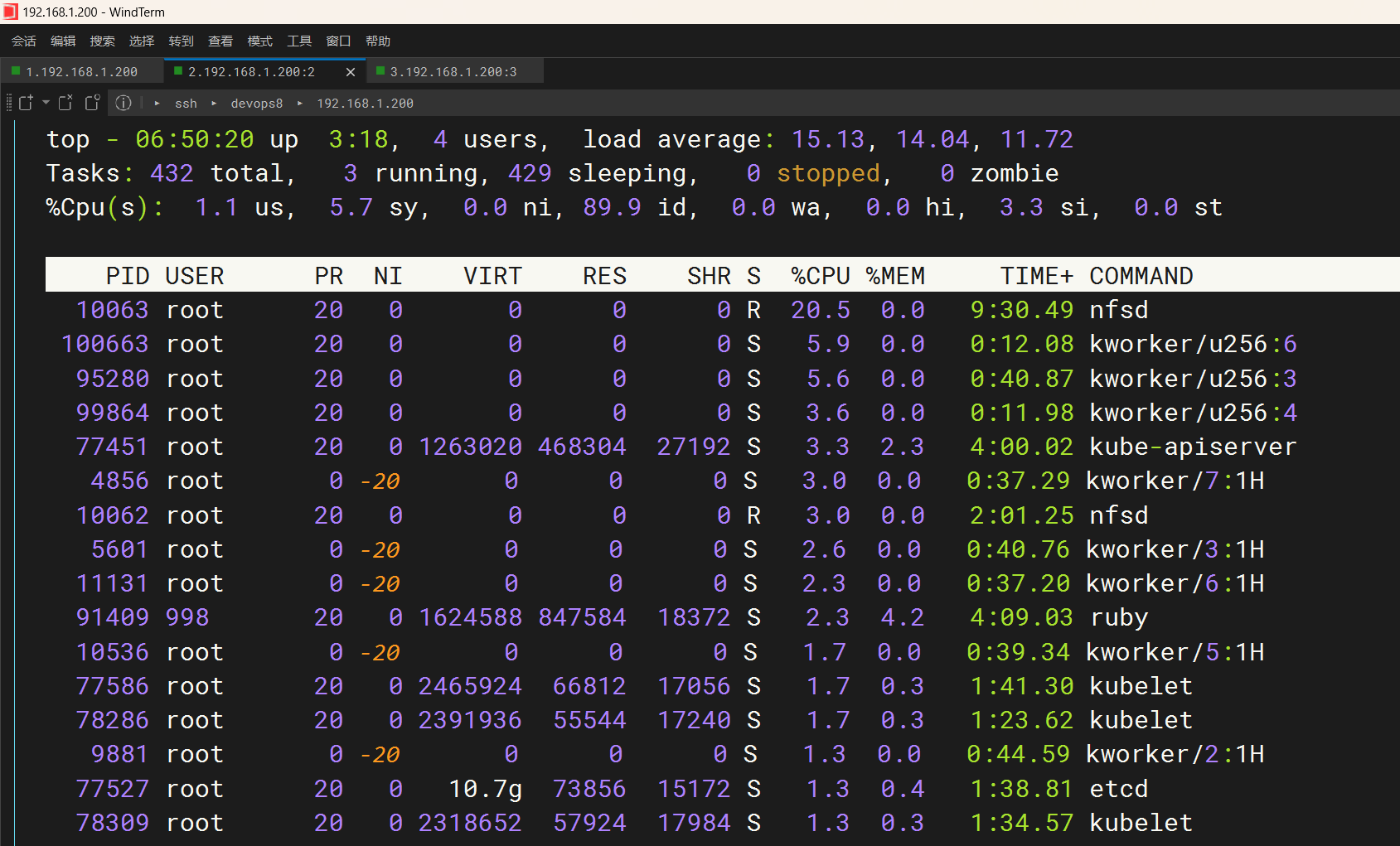
结束部分应用程序后,giotlab还是不行
我结束了一部分pc应用程序后,自己的gitlab算是基本能操作了。
nuc内存使用了也没降多少呀……
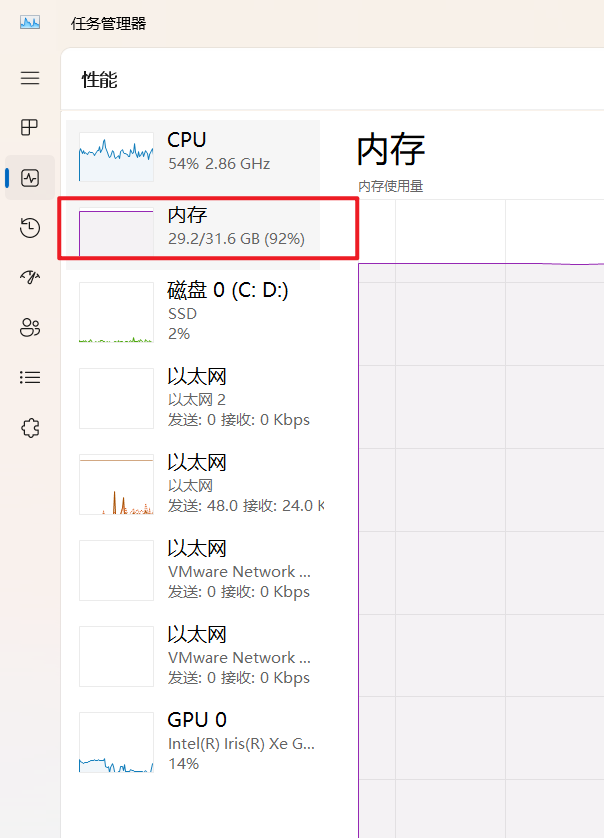
还是卡顿……
gitlab limits也挺大呀
是不是gitlab里限制内存的配置limits设置的比较低呀……
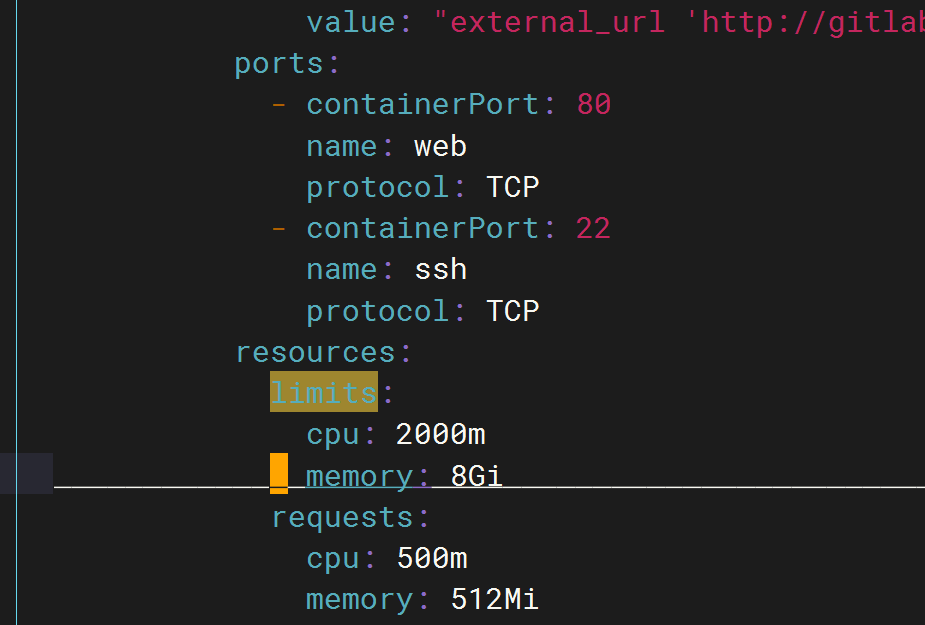
这资源配置也不低呀
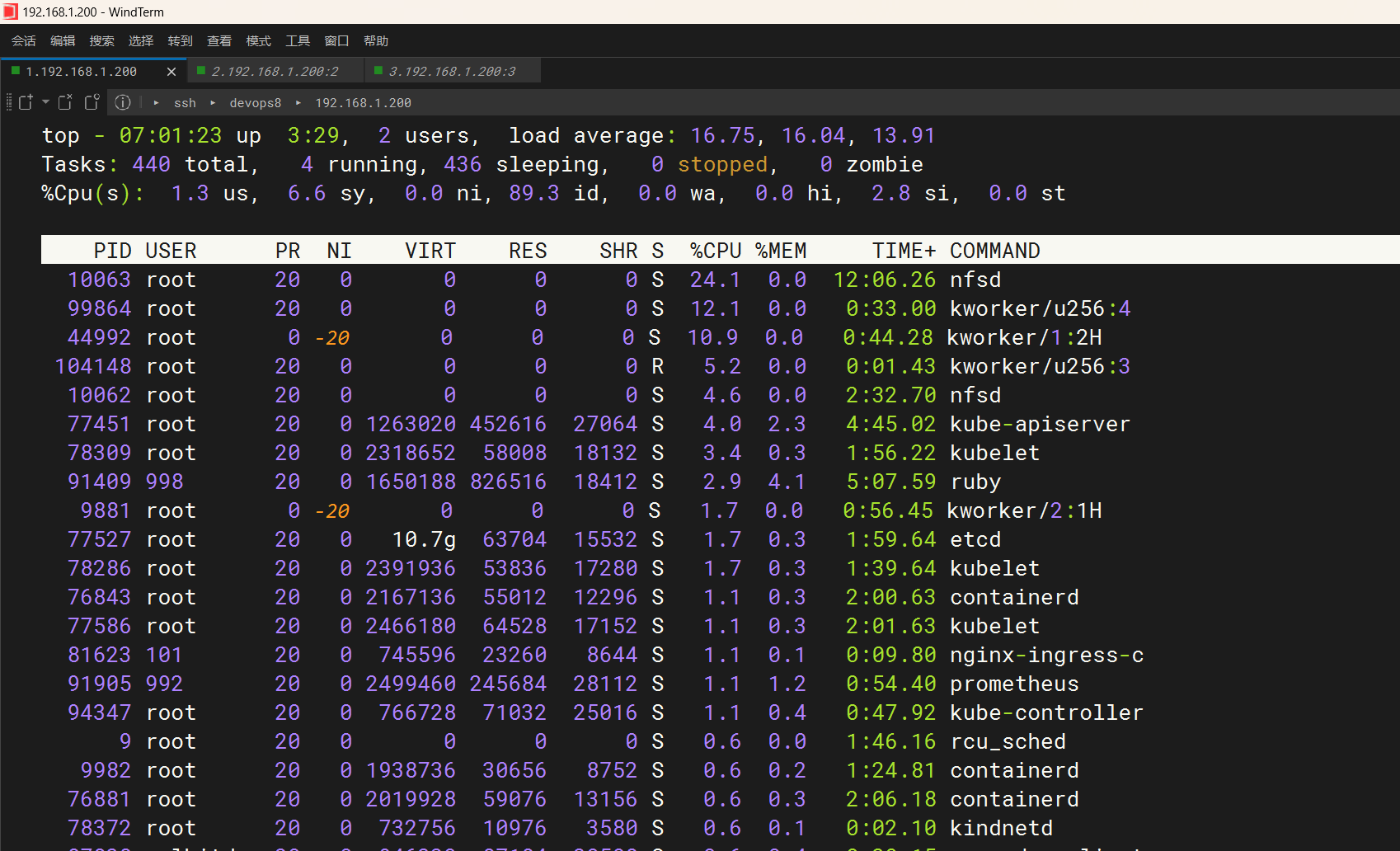
我们来看下具体这个pod的资源占用情况(待安装metrics-server)
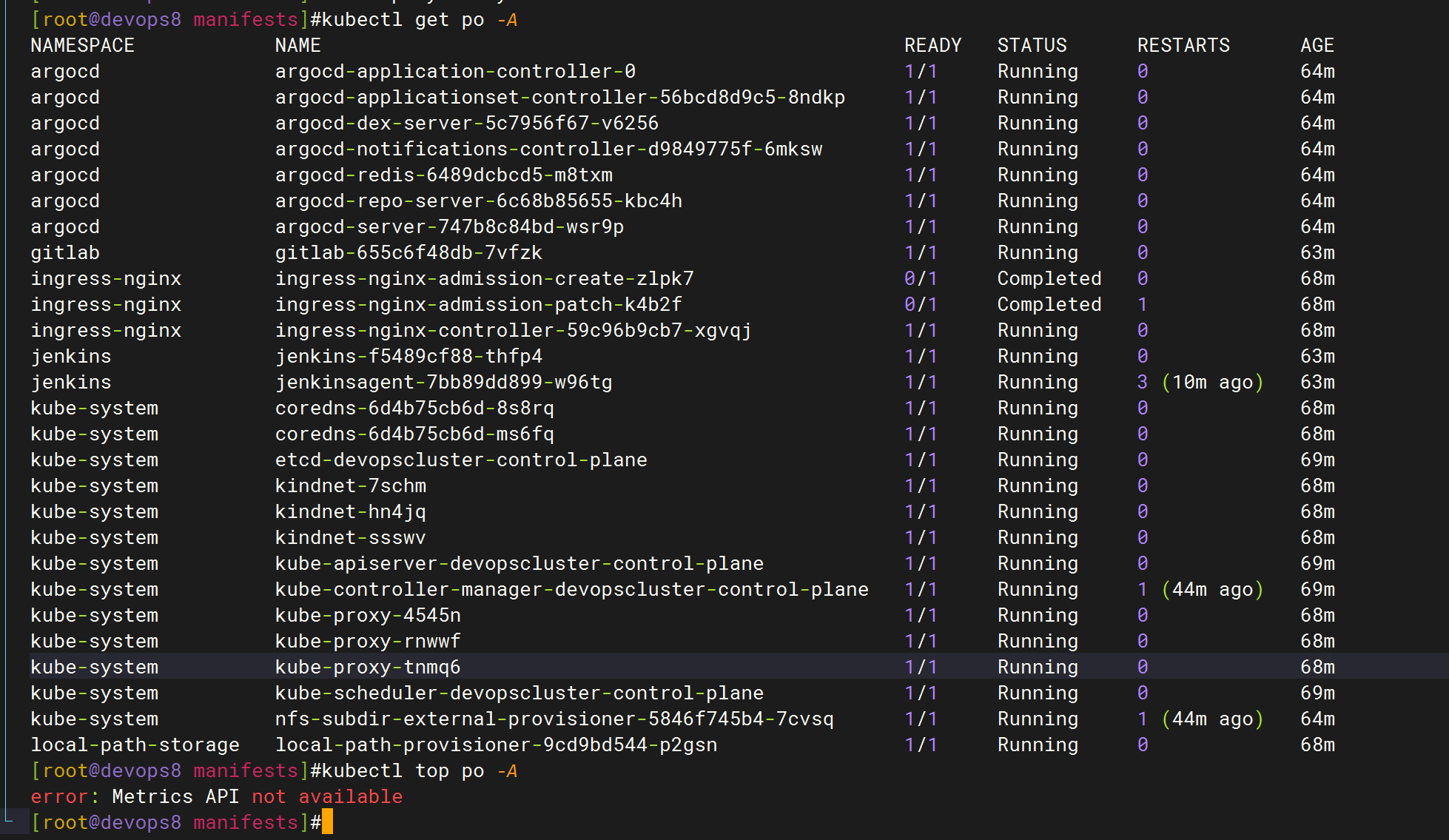
感觉还是自己虚机负载太高了……
装好metrics-server后
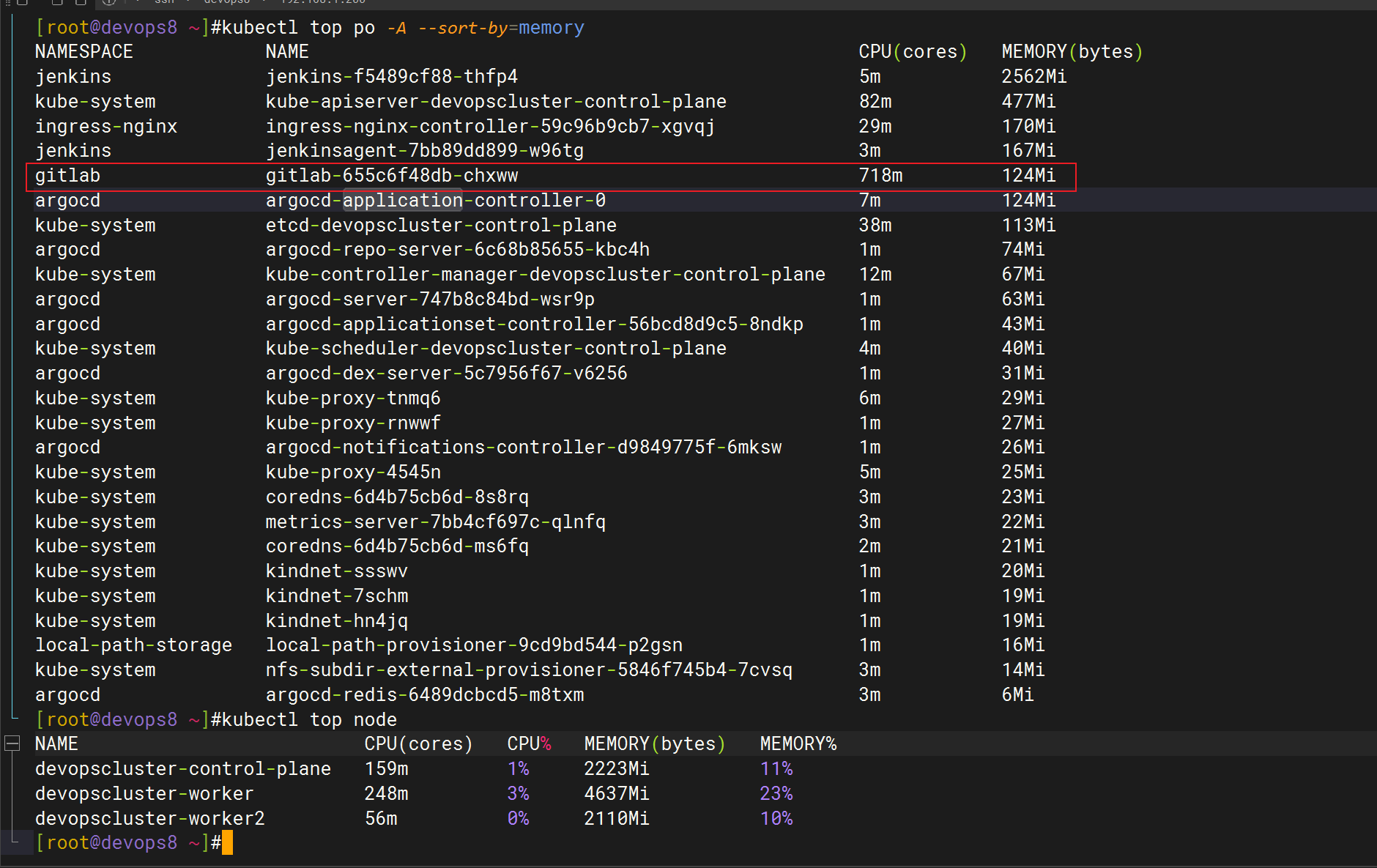
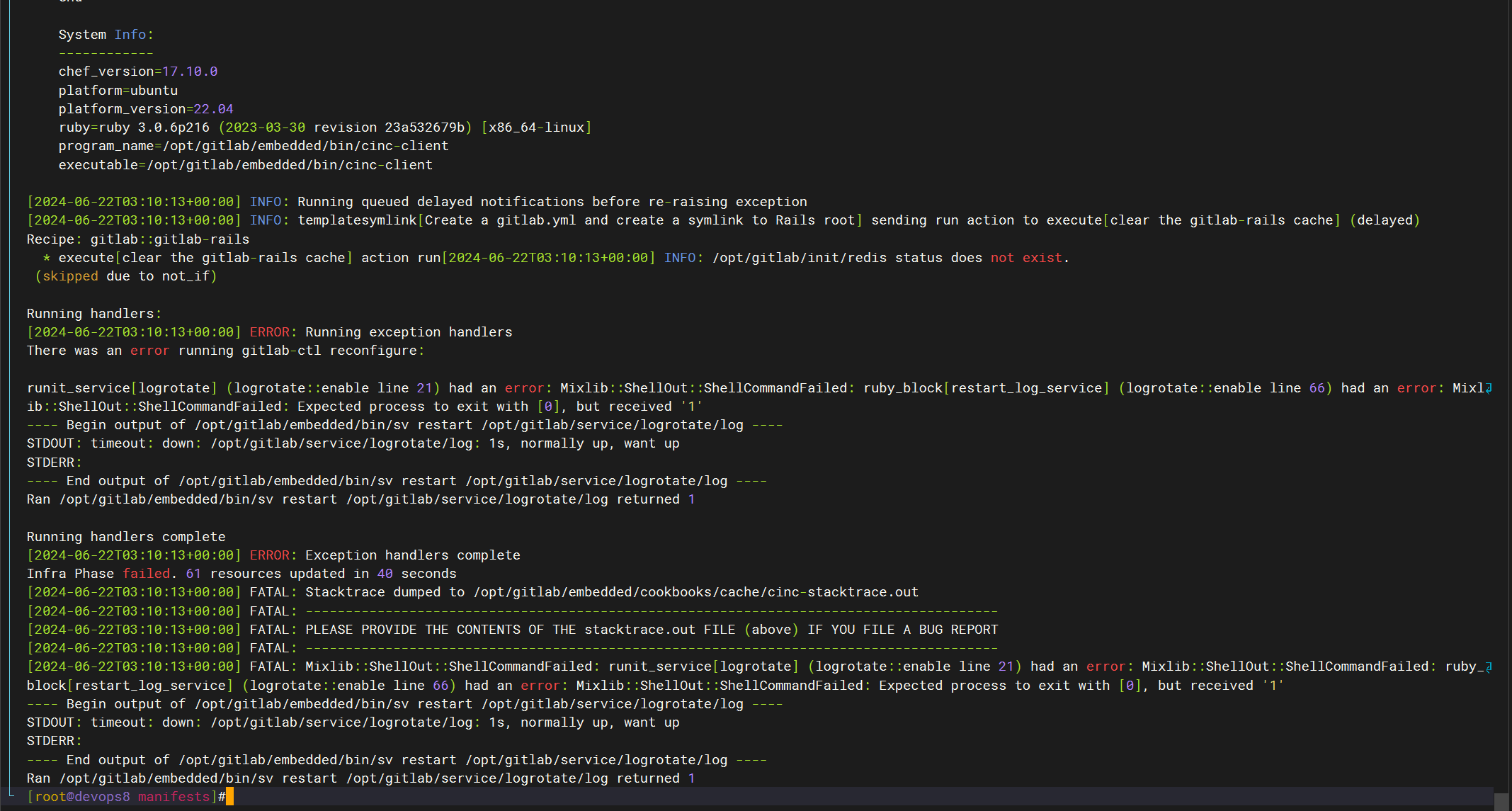
咋又报错了呢……
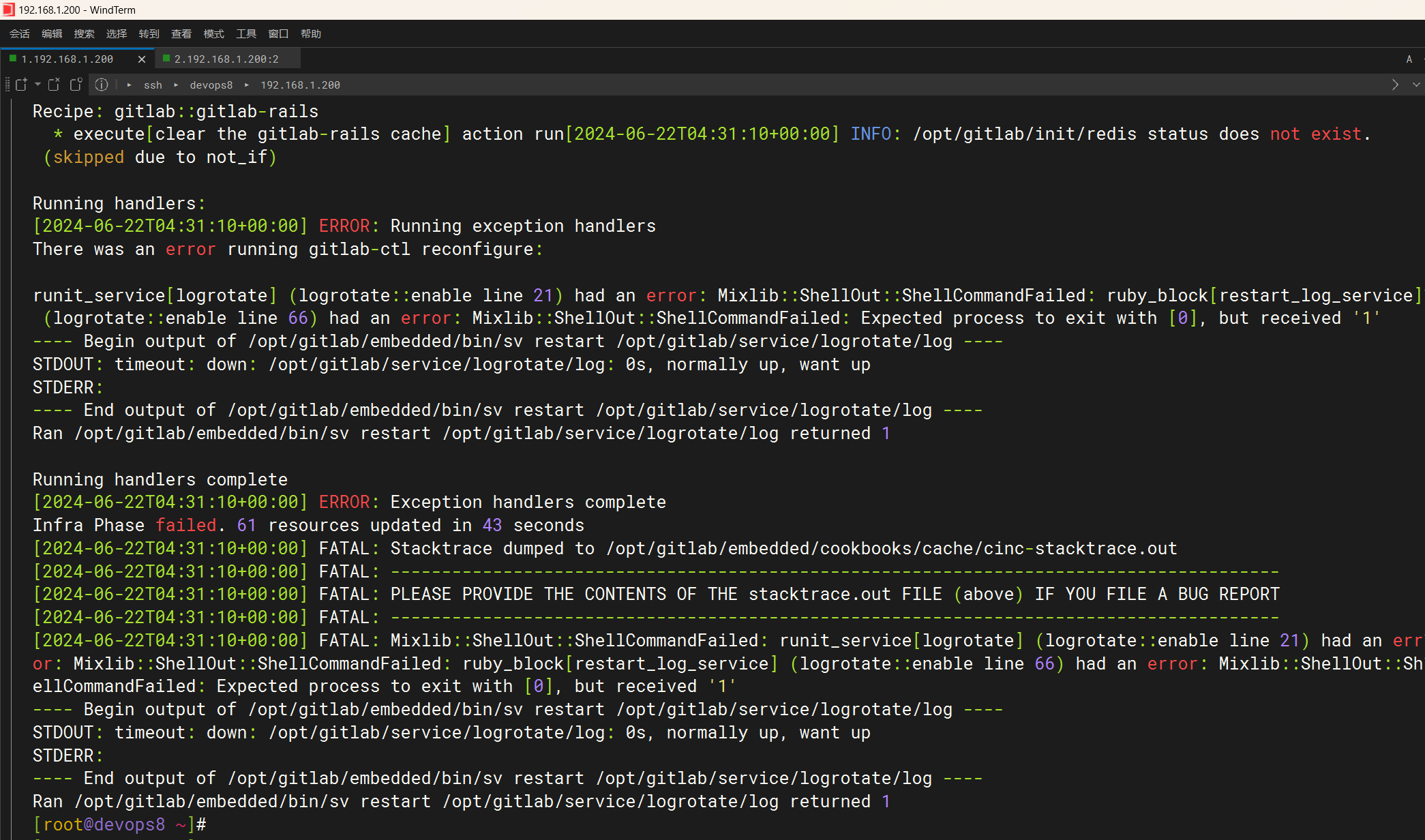
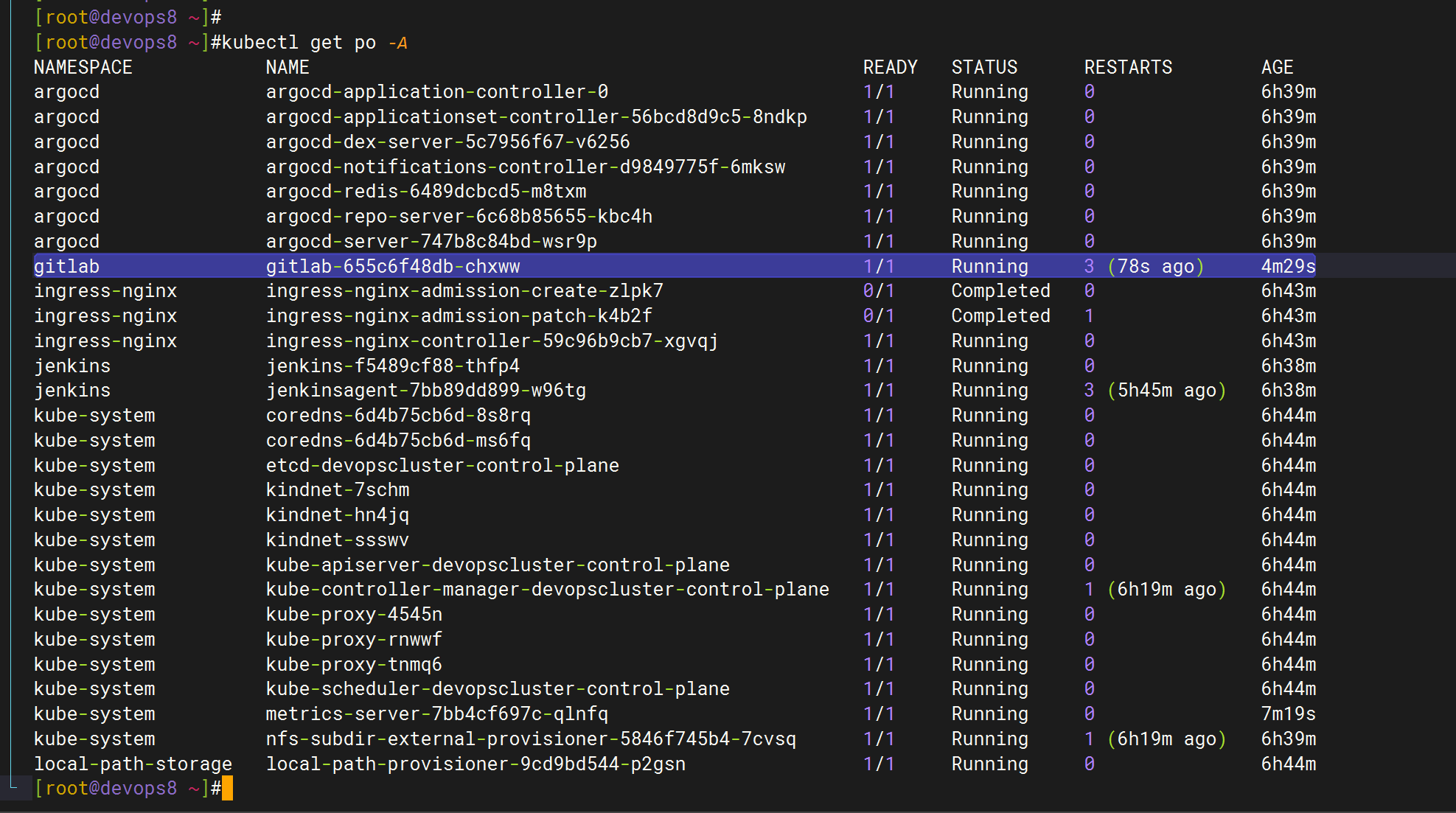
咋好多skiped的呢??
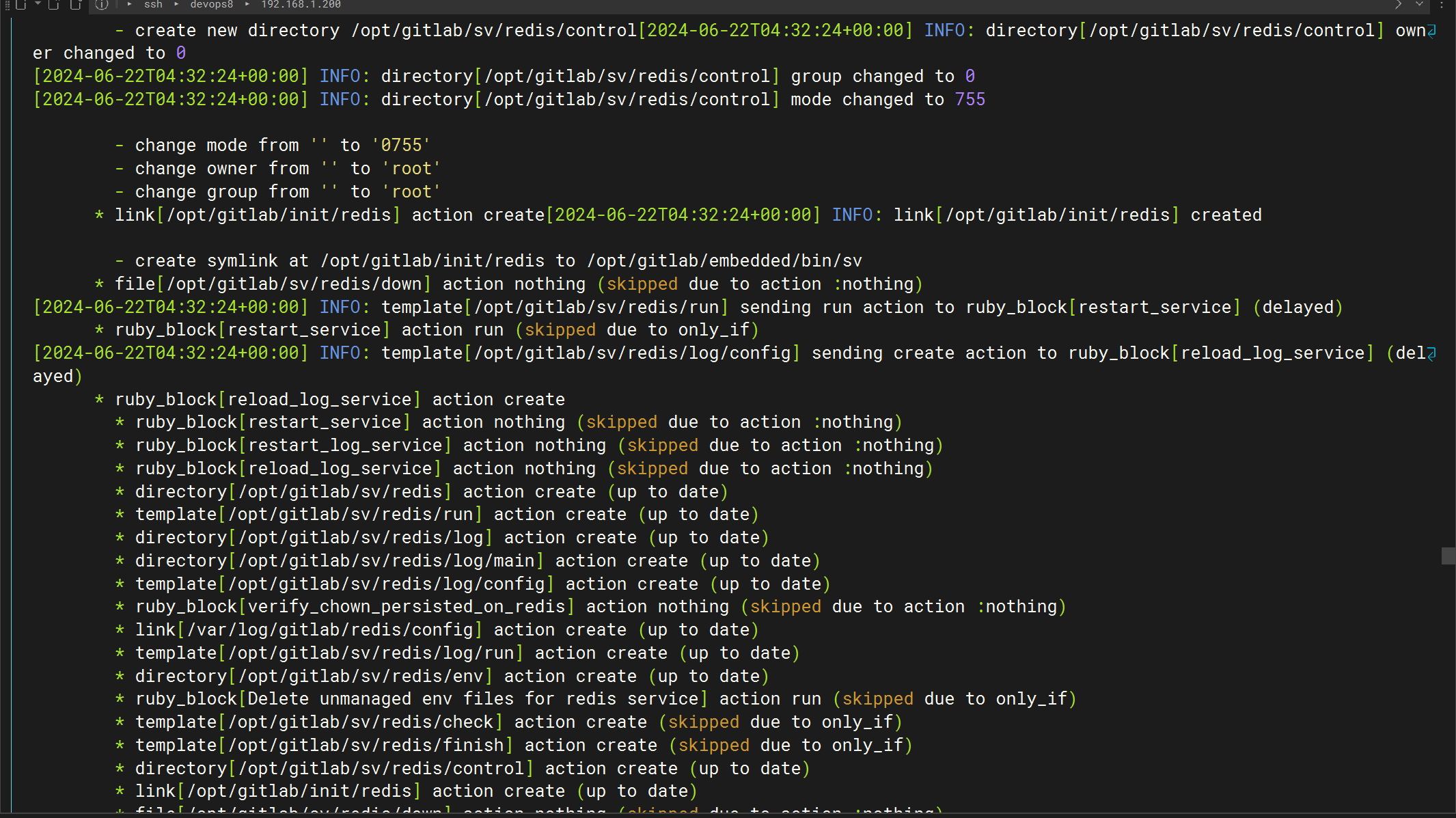
咋一直重启呢?
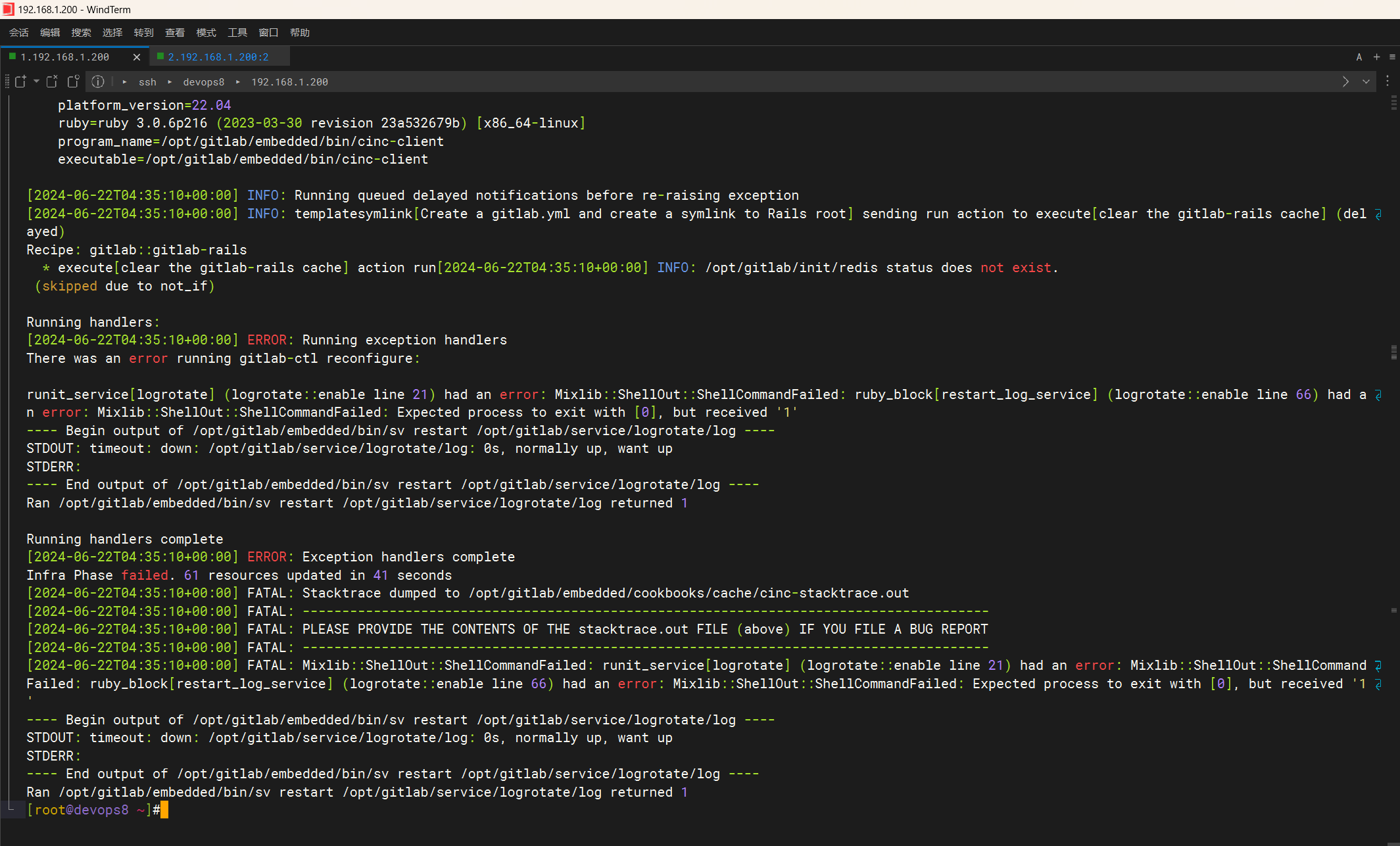
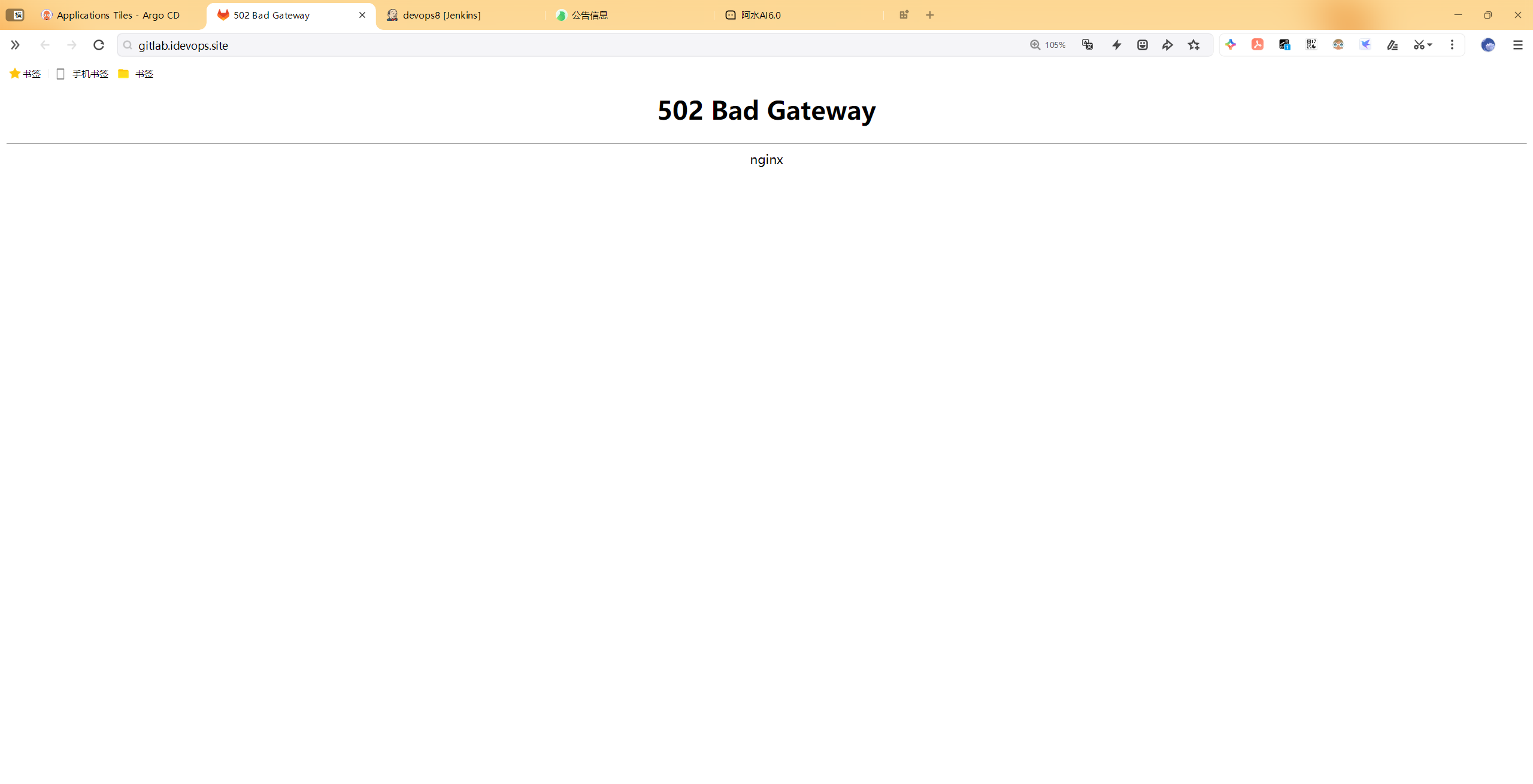
感觉不像是内存的问题,像是gitlab本身的问题,这里销毁掉集群,再次安装
淦:存储满了
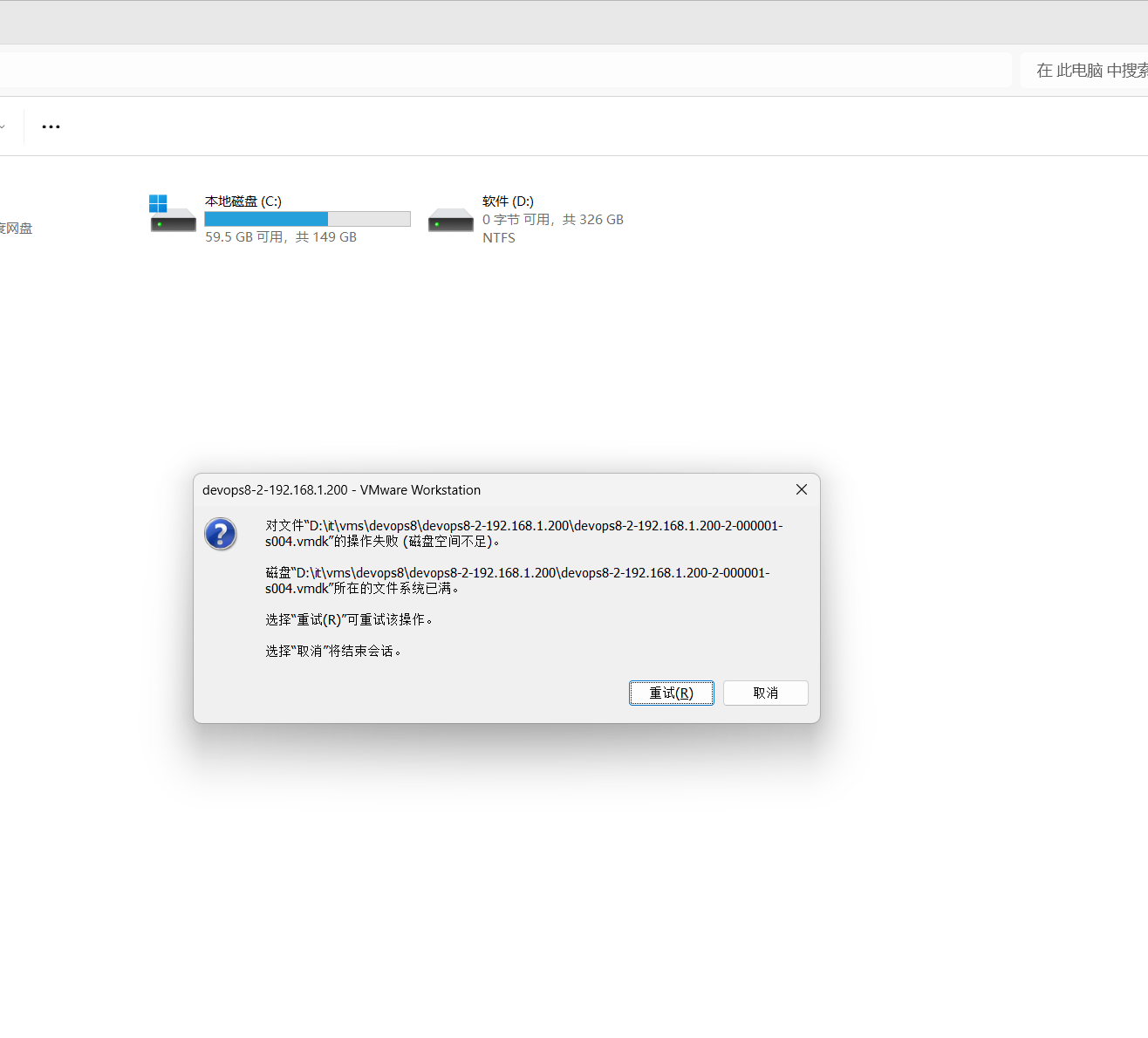
销毁后再次创建还是有问题
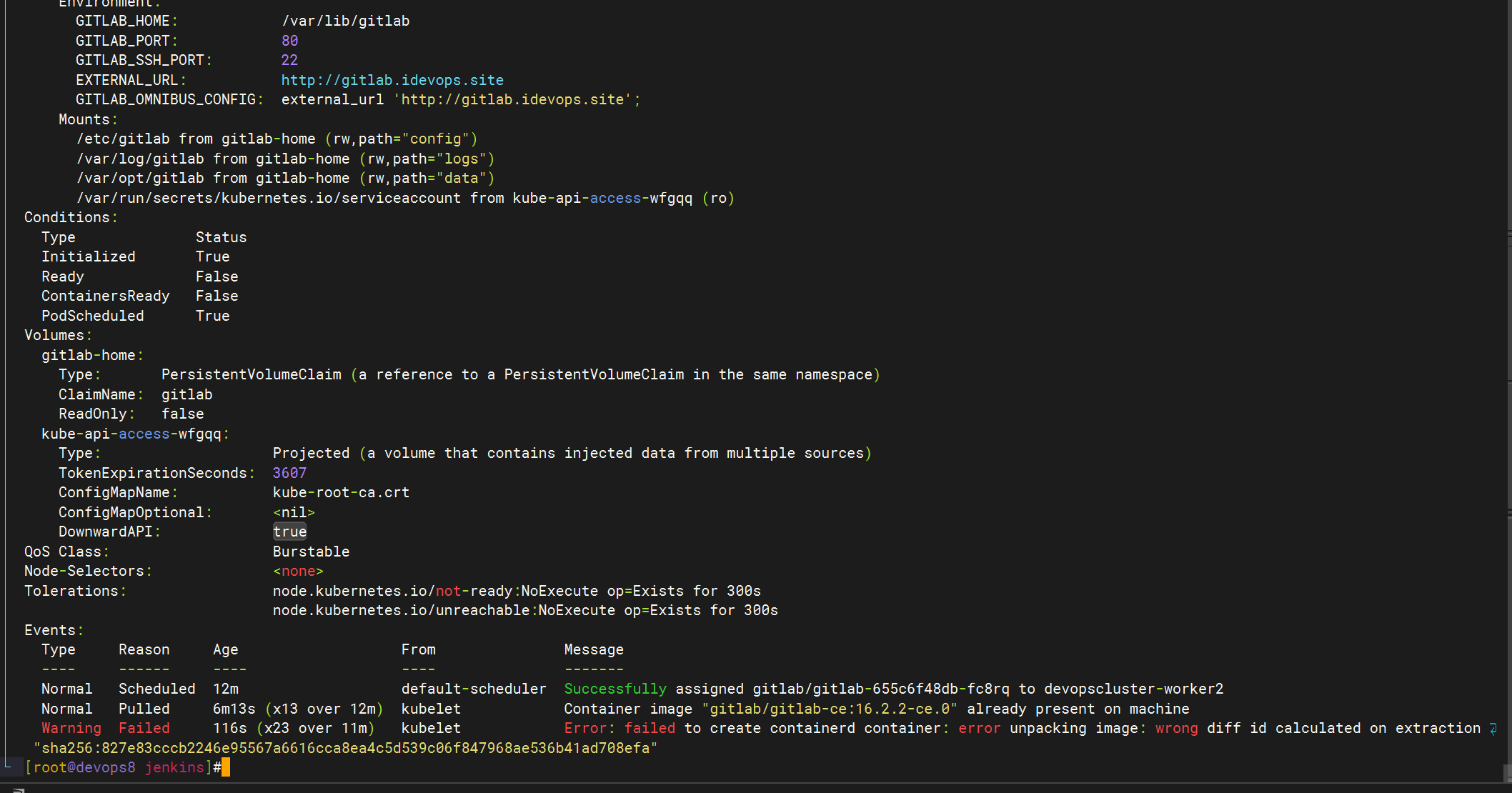
gpt
这个错误信息表明在 Kubernetes 集群中,一个名为 gitlab-655c6f48db-fc8rq 的 Pod 在尝试拉取或创建容器时遇到了问题。具体错误是 failed to create containerd container: error unpacking image: wrong diff id calculated on extraction。这个错误通常与容器运行时(如 containerd)在处理镜像时出现问题有关。
错误解释
- Normal Scheduled: 表示 Pod 已经被成功调度到
devopscluster-worker2节点。 - Normal Pulled: 表示 kubelet 已经确认镜像
gitlab/gitlab-ce:16.2.2-ce.0已经在节点上存在。 - Warning Failed: 表示 kubelet 在尝试创建容器时失败了。错误信息指出在解压镜像时计算出的 diff ID 不正确。
可能的原因
- 镜像损坏: 镜像可能在传输过程中损坏,或者在节点上存储时出现问题。
- 容器运行时问题: 容器运行时(containerd)可能存在 bug 或者配置不当。
- 存储问题: 节点上的存储系统可能存在问题,导致镜像文件损坏。
解决步骤
重新拉取镜像: 尝试在节点上手动重新拉取镜像,看是否能够解决问题。可以使用以下命令:
bashdocker pull gitlab/gitlab-ce:16.2.2-ce.0或者,如果使用的是 containerd,可以使用相应的命令。
检查容器运行时: 确保容器运行时(containerd)是最新的,并且配置正确。
检查存储系统: 检查节点上的存储系统是否正常工作,没有损坏的文件系统。
查看日志: 查看 kubelet 和 containerd 的日志,了解更多关于错误的详细信息。
回滚镜像版本: 如果问题持续存在,尝试使用一个不同的镜像版本,看是否能够避免这个问题。
联系支持: 如果问题仍然无法解决,可能需要联系镜像的维护者或者 Kubernetes/容器运行时的支持团队。
通过上述步骤,您应该能够诊断并解决这个问题。如果问题仍然存在,可能需要进一步的技术支持或查阅相关社区和文档。
再处理
[root@devops8 jenkins]#kind load docker-image gitlab/gitlab-ce:16.2.2-ce.0 --name devopscluster
Image: "gitlab/gitlab-ce:16.2.2-ce.0" with ID "sha256:75e848a8f32158987aafcc2d8e43b57a77b0cc9cf644a1e8af5d53481e6cb09a" found to be already present on all nodes.kind搭建的k8s集群,我之前使用kind load docker-image gitlab/gitlab-ce:16.2.2-ce.0 --name devopscluster命令将镜像加载到了k8s集群,但后面发现导入的镜像可能已经损坏了,我该如何删除和这个导入的镜像呢?在使用 kind 搭建的 Kubernetes 集群中,当你使用 kind load 命令将 Docker 镜像加载到集群时,实际上是将镜像复制到了集群中每个节点的 Docker 守护进程中。因此,要删除这些镜像,你需要在每个节点的 Docker 环境中删除它们。
以下是删除 kind 集群中导入的镜像的步骤:
登录到
kind集群的节点: 由于kind是在本地运行容器来模拟 Kubernetes 节点,你需要通过 Docker 来访问这些节点。你可以使用以下命令来访问集群中的第一个节点(通常是控制平面节点):bashdocker exec -it kind-control-plane bash这里的
kind-control-plane是节点的默认名称,如果你有自定义名称,请替换为你的节点名称。在节点上删除镜像: 一旦你登录到节点,你可以使用 Docker 命令来删除镜像。首先,列出所有镜像以找到你要删除的镜像:
bashdocker images然后,使用
docker rmi命令删除镜像:bashdocker rmi gitlab/gitlab-ce:16.2.2-ce.0重复步骤 1 和 2 在其他节点上: 如果你的
kind集群中有多个节点,你需要重复上述步骤在每个节点上删除镜像。退出节点: 删除镜像后,你可以使用
exit命令退出节点。重启
kind集群(可选): 在某些情况下,即使你删除了镜像,kind集群可能仍然保留了一些镜像的引用。为了确保所有引用都被清除,你可以重启kind集群:bashkind delete cluster --name devopscluster kind create cluster --name devopscluster
通过上述步骤,你可以从 kind 集群中删除导入的损坏镜像。请确保在删除镜像之前,没有正在运行的 Pod 依赖于这些镜像。如果你不确定,可以先停止或删除相关的 Pod,然后再删除镜像。
没有docker命令:

再销毁一次
好了
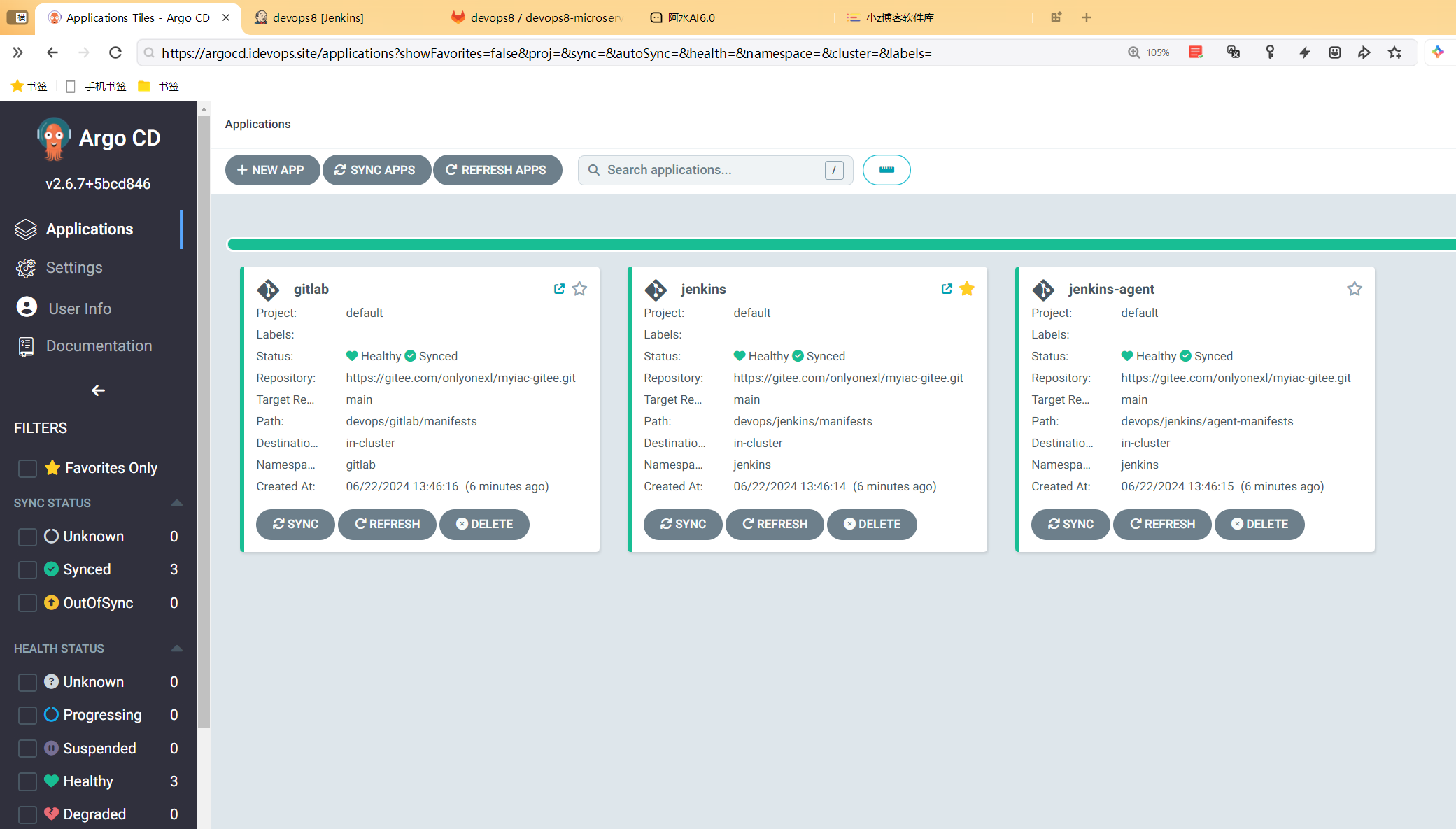
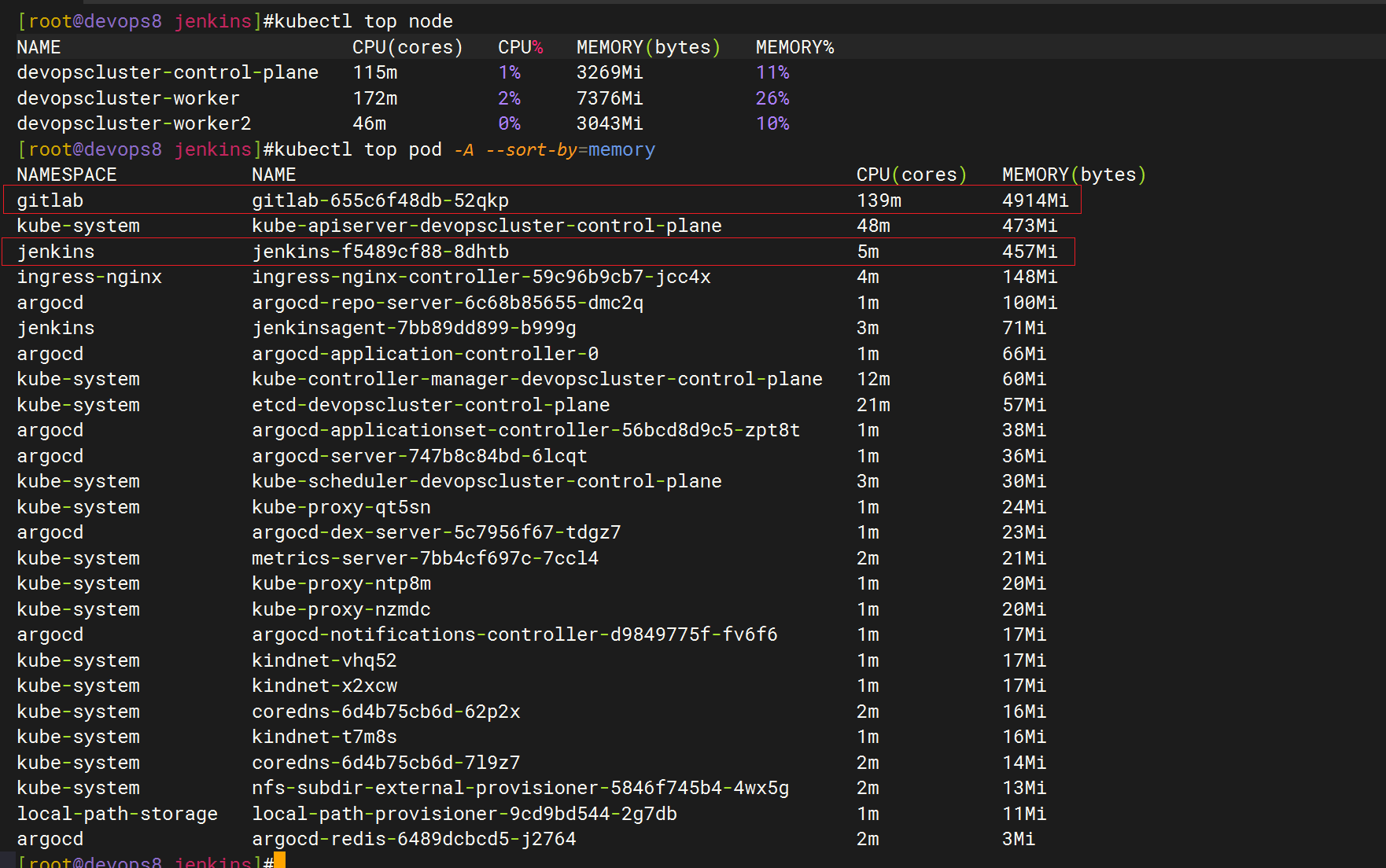
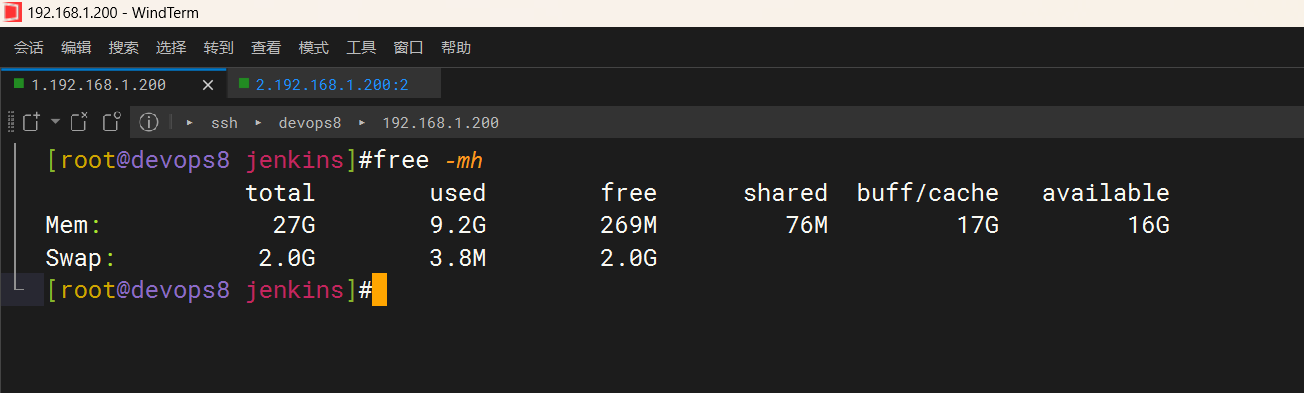
3、解决办法
扩展nuc内存由32g变成64g;
4、总结
基础环境试验一定不能出现问题,否则后面得试验没法做的。