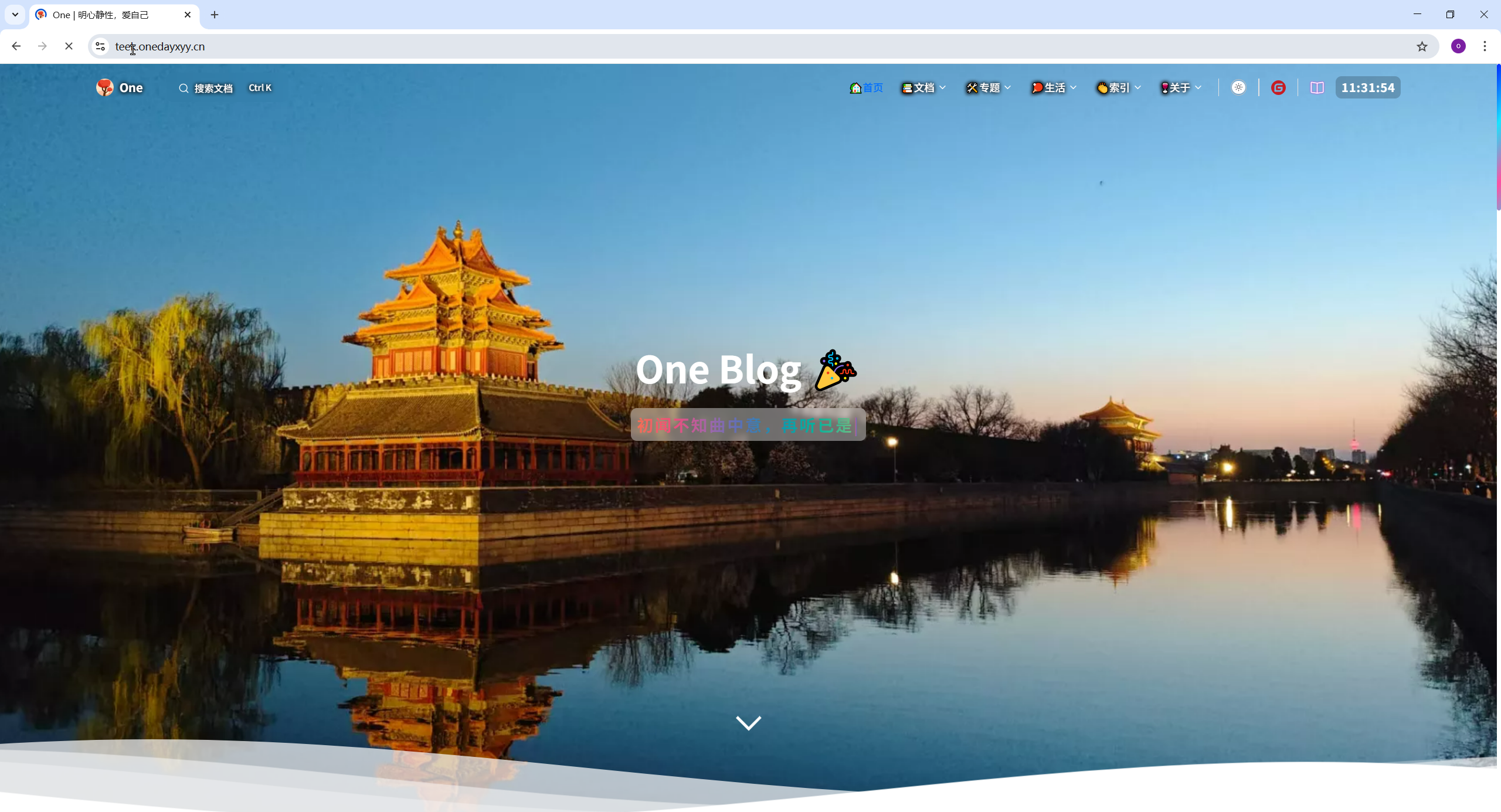
明心静性,爱自己
明心静性,爱自己。 人,生而孤独,何惧道阻且长。 孤勇者。
基于hugo搭建的轻量化个人博客
基于vitepress搭建的现代化技术博客
如果你有任何想交流的内容,或是想合作的想法,都可以通过以下方式找到我