
Victormetrics
Victormetrics
目录
[toc]
1、单节点
1.简介
VictoriaMetrics(VM) 是一个支持高可用、经济高效且可扩展的监控解决方案和时间序列数据库,可用于 Prometheus 监控数据做长期远程存储。
前面章节我们介绍了 Thanos 方案也可以用来解决 Prometheus 的高可用和远程存储的问题,那么为什么我们还要使用 VictoriaMetrics 呢?
相对于 Thanos,VictoriaMetrics 主要是一个可水平扩容的本地全量持久化存储方案,VictoriaMetrics 不仅仅是时序数据库,它的优势主要体现在一下几点。(Thanos:它不是做本地全量的,其很多数据都是存储在oss上的。)
- 对外支持 Prometheus 相关的 API,可 以直接用于 Grafana 作为 Prometheus 数据源使用
- 指标数据摄取和查询具备高性能和良好的可扩展性,性能比 InfluxDB 和 TimescaleDB 高出 20 倍
- 在处理高基数时间序列时,内存方面也做了优化,比 InfluxDB 少 10x 倍,比 Prometheus、Thanos 或 Cortex 少 7 倍
- 高性能的数据压缩方式,与 TimescaleDB 相比,可以将多达 70 倍的数据点存入有限的存储空间,与 Prometheus、Thanos 或 Cortex 相比,所需的存储空间减少 7 倍
- 它针对具有高延迟 IO 和低 IOPS 的存储进行了优化
- 提供全局的查询视图,多个 Prometheus 实例或任何其他数据源可能会将数据摄取到 VictoriaMetrics
- 操作简单
- VictoriaMetrics 由一个没有外部依赖的小型可执行文件组成
- 所有的配置都是通过明确的命令行标志和合理的默认值完成的
- 所有数据都存储在 - storageDataPath 命令行参数指向的目录中
- 可以使用
vmbackup/vmrestore工具轻松快速地从实时快照备份到 S3 或 GCS 对象存储中
- 支持从第三方时序数据库获取数据源
- 由于存储架构,它可以保护存储在非正常关机(即 OOM、硬件重置或 kill -9)时免受数据损坏
- 同样支持指标的 relabel 操作
2.架构
VM 分为单节点和集群两个方案,根据业务需求选择即可。
单节点版直接运行一个二进制文件既,官方建议采集数据点(data points)低于 100w/s,推荐 VM 单节点版,简单好维护,但不支持告警。
集群版支持数据水平拆分。
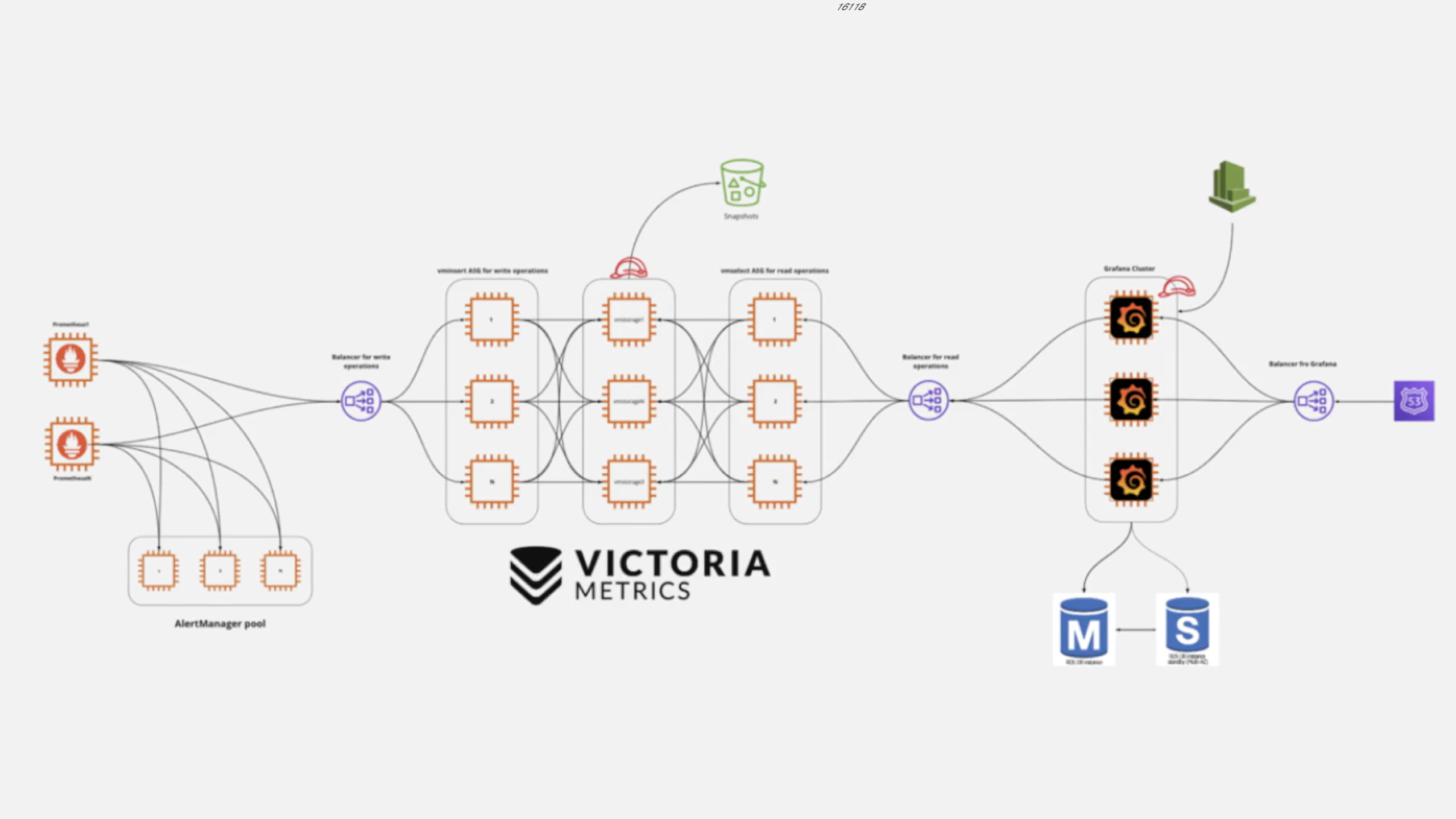
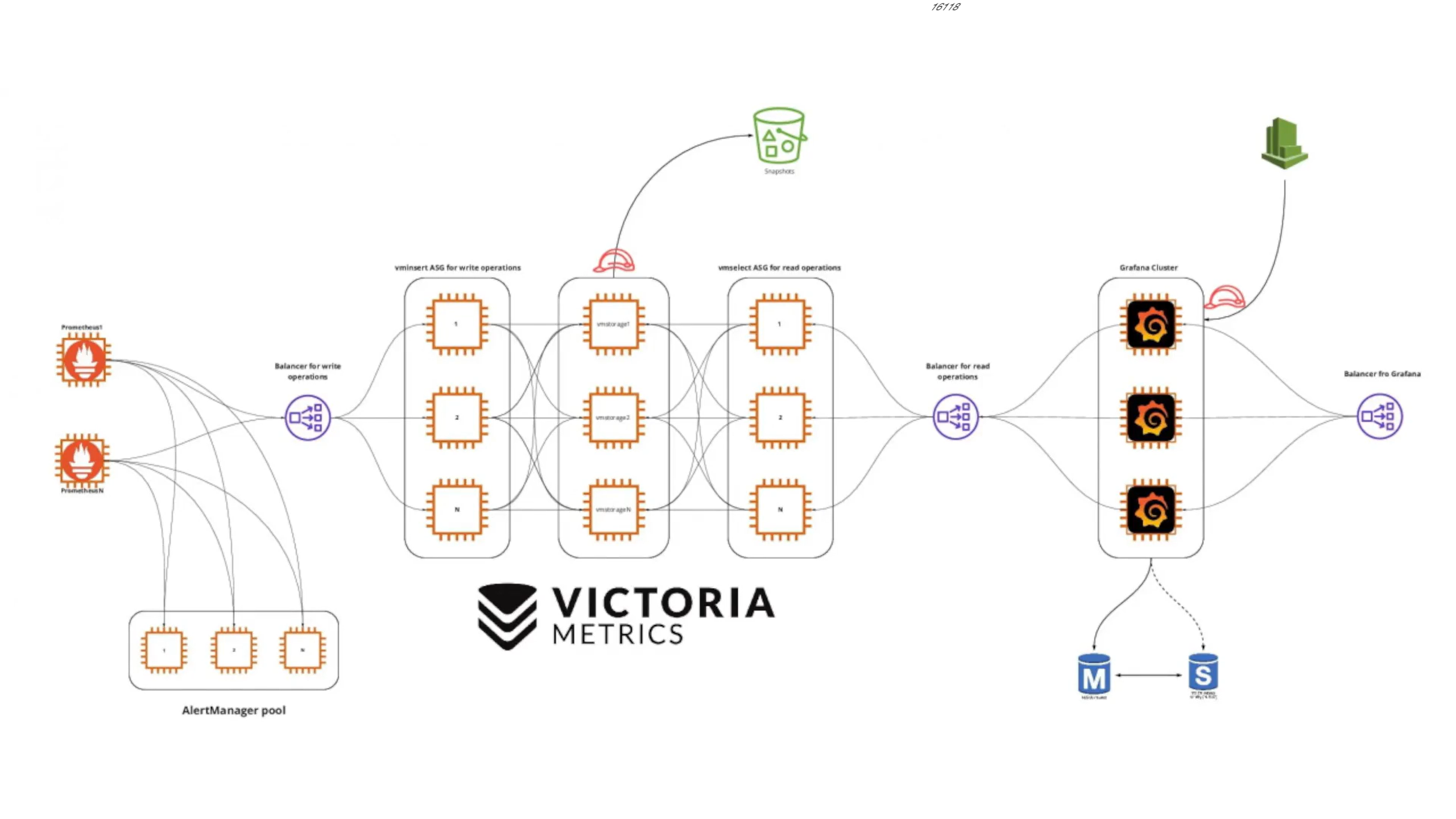
下图是 VictoriaMetrics 集群版官方的架构图。
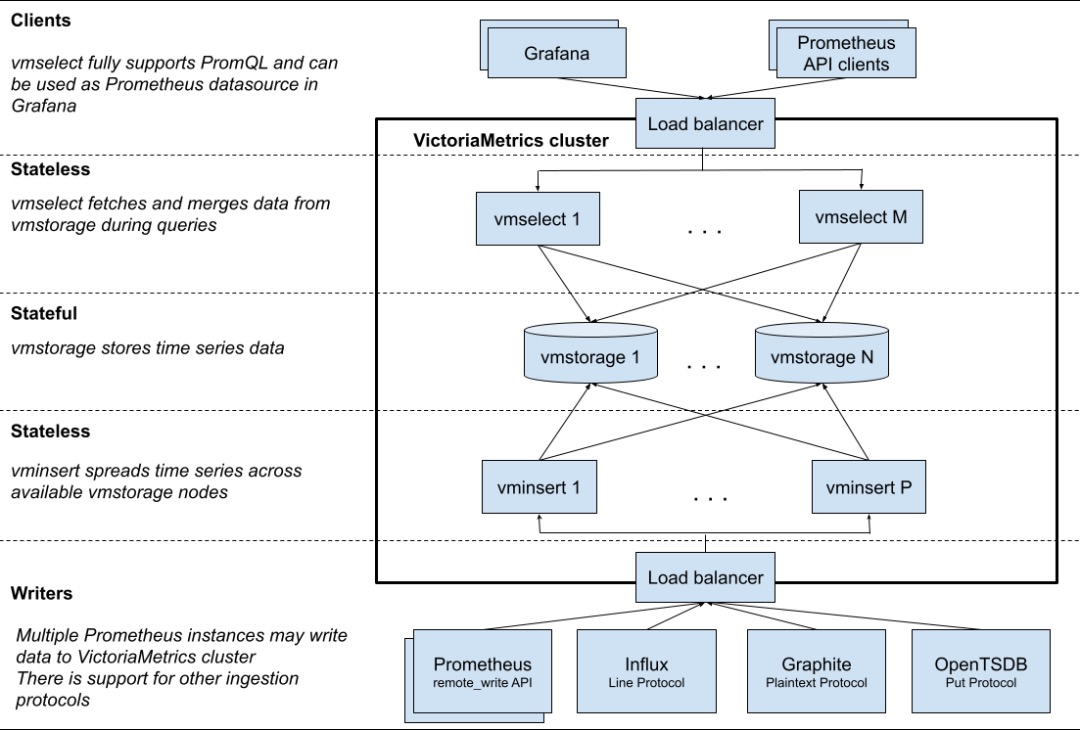
注意
vmselect这里是有配置一个缓存的,当然你可以用StatefuleSet的pvc把缓存持久化下来。这里就使用无状态服务的Deployment的emptyDir了。
主要包含以下几个组件:
vmstorage:数据存储以及查询结果返回,默认端口为 8482vminsert:数据录入,可实现类似分片、副本功能,默认端口 8480vmselect:数据查询,汇总和数据去重,默认端口 8481vmagent:数据指标抓取,支持多种后端存储,会占用本地磁盘缓存,默认端口 8429vmalert:报警相关组件,如果不需要告警功能可以不使用该组件,默认端口为 8880
集群方案把功能拆分为 vmstorage、 vminsert、vmselect 组件,如果要替换 Prometheus,还需要使用 vmagent、vmalert。从上图也可以看出 vminsert 以及 vmselect 都是无状态的,所以扩展很简单,只有 vmstorage 是有状态的。
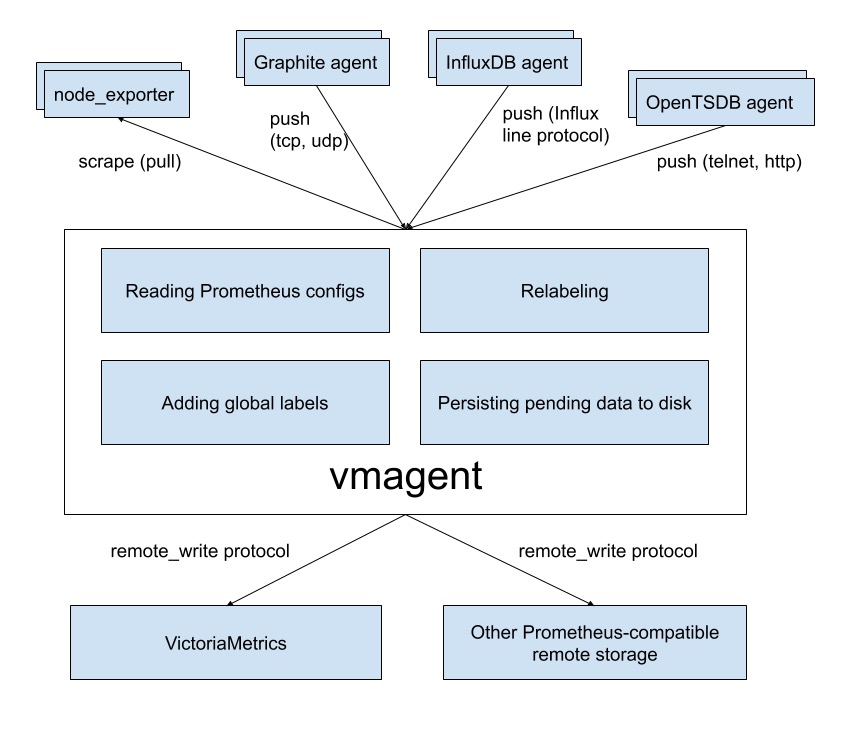
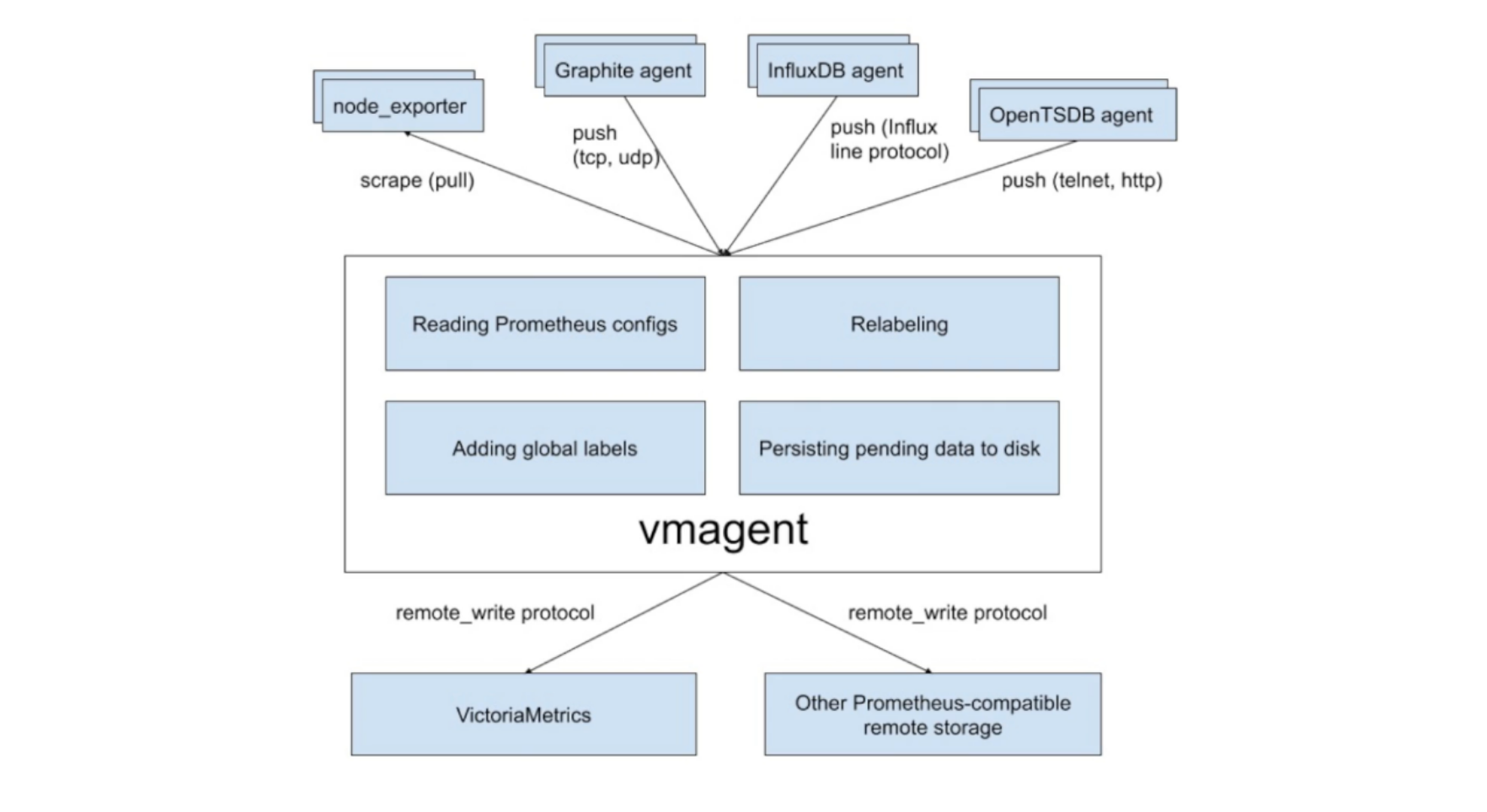
vmagent 的主要目的是用来收集指标数据然后存储到 VM 以及 Prometheus 兼容的存储系统中(支持 remote_write 协议即可)。
下图是 vmagent 的一个简单架构图,可以看出该组件也实现了 metrics 的 push 功能,此外还有很多其他特性:
- 替换 prometheus 的 scraping target
- 支持基于 prometheus relabeling 的模式添加、移除、修改 labels,可以方便在数据发送到远端存储之前进行数据的过滤
- 支持多种数据协议,influx line 协议,graphite 文本协议,opentsdb 协议,prometheus remote write 协议,json lines 协议,csv 数据
- 支持收集数据的同时,并复制到多种远端存储系统
- 支持不可靠远端存储(通过本地存储
-remoteWrite.tmpDataPath),同时支持最大磁盘占用 - 相比 prometheus 使用较少的内存、cpu、磁盘 io 以及网络带宽
接下来我们就分别来介绍了 VM 的单节点和集群两个方案的使用。
3.单节点
💘 实战:vm单节点安装及使用(测试成功)-2022.7.24
这里我们采集 node-exporter 为例进行说明,首先使用 Prometheus 采集数据,然后将 Prometheus 数据远程写入 VM 远程存储。
由于 VM 提供了 vmagent 组件,最后我们使用 VM 来完全替换 Prometheus,可以使架构更简单、更低的资源占用。🤣
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5实验软件
链接:https://pan.baidu.com/s/1_ts7SfiA_BeoIpPLrUetUQ?pwd=cjku
提取码:cjku
2022.7.25-VictoriaMetrics之单节点-实验软件
环境准备
1.创建kube-vm 命名空间
- 这里我们将所有资源运行在
kube-vm命名空间之下:
[root@master1 ~]#kubectl create ns kube-vm
namespace/kube-vm created2.创建DaemonSet 类型的node-exporter
- 首先我们这
kube-vm命名空间下面使用 DaemonSet 控制器运行 node-exporter,对应的资源清单文件如下所示:
[root@master1 ~]#mkdir vm
[root@master1 ~]#cd vm
[root@master1 vm]#vim vm-node-exporter.yaml
# vm-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-vm
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true #注意这里是hostNetwork方式
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.3.1
args:
- --web.listen-address=$(HOSTIP):9111 #这里修改监听端口为9111
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --no-collector.hwmon # 禁用不需要的一些采集器
- --no-collector.nfs
- --no-collector.nfsd
- --no-collector.nvme
- --no-collector.dmi
- --no-collector.arp
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9111
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations: # 添加容忍
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /由于前面章节中我们也创建了 node-exporter,为了防止端口冲突,这里我们使用参数 --web.listen-address=$(HOSTIP):9111 配置端口为 9111。

- 直接应用上面的资源清单即可。
[root@master1 vm]#kubectl apply -f vm-node-exporter.yaml
daemonset.apps/node-exporter created
[root@master1 vm]#kubectl get po -owide -nkube-vm
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-56p88 1/1 Running 0 12s 172.29.9.51 master1 <none> <none>
node-exporter-bjk82 1/1 Running 0 12s 172.29.9.53 node2 <none> <none>
node-exporter-wnwgt 1/1 Running 0 12s 172.29.9.52 node1 <none> <none>3.重新部署一套独立的 Prometheus
然后重新部署一套独立的 Prometheus,为了简单我们直接使用 static_configs 静态配置方式来抓取 node-exporter 的指标,配置清单如下所示:
- 创建p8s的ConfigMap资源对象:
[root@master1 vm]#pwd
/root/vm
[root@master1 vm]#vim vm-prom-config.yaml
# vm-prom-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-vm
data:
prometheus.yaml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: "nodes"
static_configs:
- targets: ['172.29.9.51:9111', '172.29.9.52:9111', '172.29.9.53:9111']
relabel_configs: # 通过 relabeling 从 __address__ 中提取 IP 信息,为了后面验证 VM 是否兼容 relabeling
- source_labels: [__address__]
regex: "(.*):(.*)"
replacement: "${1}"
target_label: 'ip'
action: replace上面配置中通过 relabel 操作从 __address__ 中将 IP 信息提取出来,后面可以用来验证 VM 是否兼容 relabel 操作。
- 对p8s做数据持久化:
同样要给 Prometheus 数据做持久化,所以也需要创建一个对应的 PVC 资源对象:
先到node2节点上创建下本地目录:
[root@master1 ~]#cd vm
[root@master1 vm]#ssh node2
Last login: Sat Jul 23 11:55:59 2022 from master1
[root@node2 ~]#mkdir -p /data/k8s/prometheus
[root@node2 ~]#exit
logout
Connection to node2 closed.[root@master1 vm]#vim vm-prom-pvc.yaml
# apiVersion: storage.k8s.io/v1
# kind: StorageClass
# metadata:
# name: local-storage
# provisioner: kubernetes.io/no-provisioner
# volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-data
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: kube-vm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage- 然后直接创建 Prometheus 即可,将上面的 PVC 和 ConfigMap 挂载到容器中,通过
--config.file参数指定配置文件文件路径,指定 TSDB 数据路径等,资源清单文件如下所示:
[root@master1 vm]#vim vm-prom-deploy.yaml
# vm-prom-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-vm
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- name: config-volume
configMap:
name: prometheus-config
containers:
- image: prom/prometheus:v2.35.0
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yaml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--storage.tsdb.retention.time=2d"
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
securityContext:
runAsUser: 0
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-vm
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http- 直接应用上面的资源清单即可。
[root@master1 vm]#kubectl apply -f vm-prom-config.yaml
configmap/prometheus-config created
service/prometheus created
[root@master1 vm]#kubectl apply -f vm-prom-pvc.yaml
persistentvolume/prometheus-data created
persistentvolumeclaim/prometheus-data created
[root@master1 vm]#kubectl apply -f vm-prom-deploy.yaml
deployment.apps/prometheus created
[root@master1 vm]#kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
grafana-local 2Gi RWO Retain Bound monitor/grafana-pvc local-storage 80d
prometheus-data 20Gi RWO Retain Bound kube-vm/prometheus-data local-storage 8m34s
prometheus-local 20Gi RWO Retain Bound monitor/prometheus-data local-storage 84d
pv001 1Gi RWO Retain Terminating default/www-web-0 251d
pv002 1Gi RWO Retain Terminating default/www-web-1 251d
[root@master1 vm]#kubectl get pvc -nkube-vm
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-data Bound prometheus-data 20Gi RWO local-storage 8m40s
[root@master1 vm]#kubectl get po -owide -nkube-vm
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-56p88 1/1 Running 0 4h40m 172.29.9.51 master1 <none> <none>
node-exporter-bjk82 1/1 Running 0 4h40m 172.29.9.53 node2 <none> <none>
node-exporter-wnwgt 1/1 Running 0 4h40m 172.29.9.52 node1 <none> <none>
prometheus-dfc9f6-l59mw 1/1 Running 0 6m13s 10.244.2.225 node2 <none> <none>
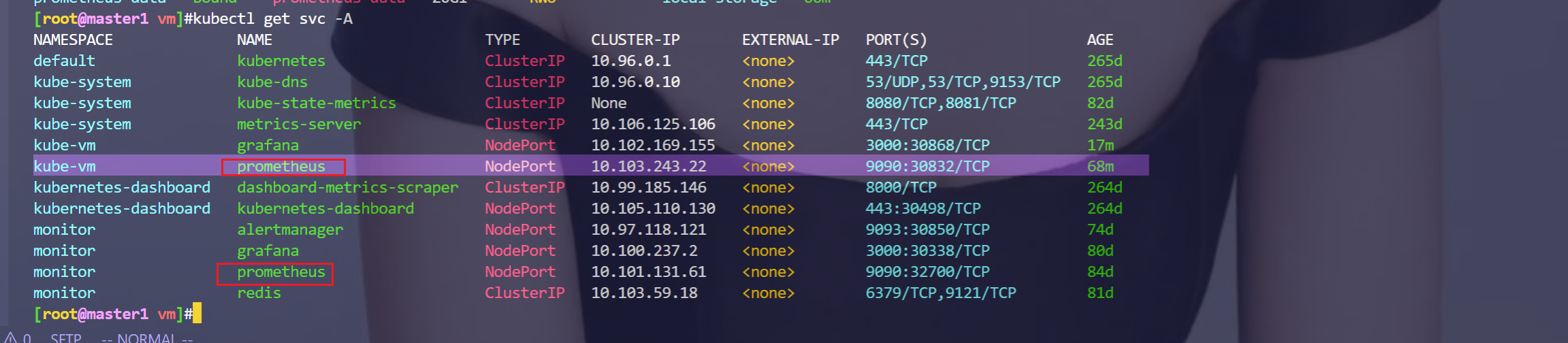
[root@master1 vm]#kubectl get svc -nkube-vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.103.243.22 <none> 9090:30832/TCP 6m21s
[root@master1 vm]#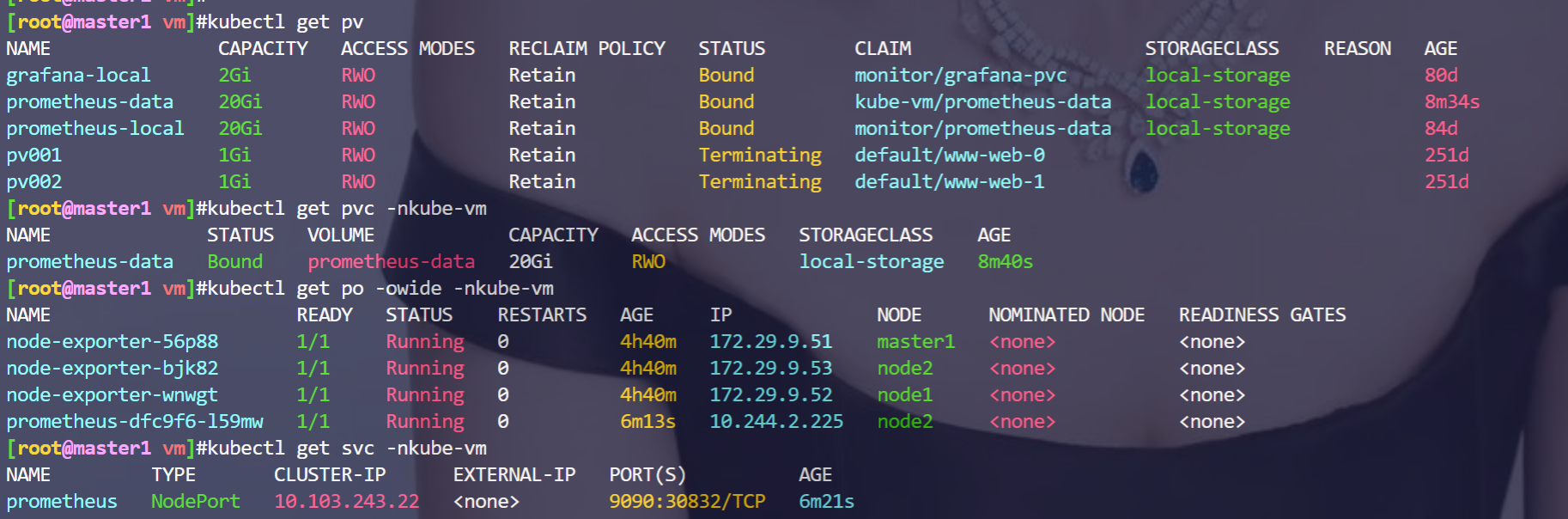
- 部署完成后可以通过
http://<node-ip>:30832访问 Prometheus,正常可以看到采集的 3 个 node 节点的指标任务。
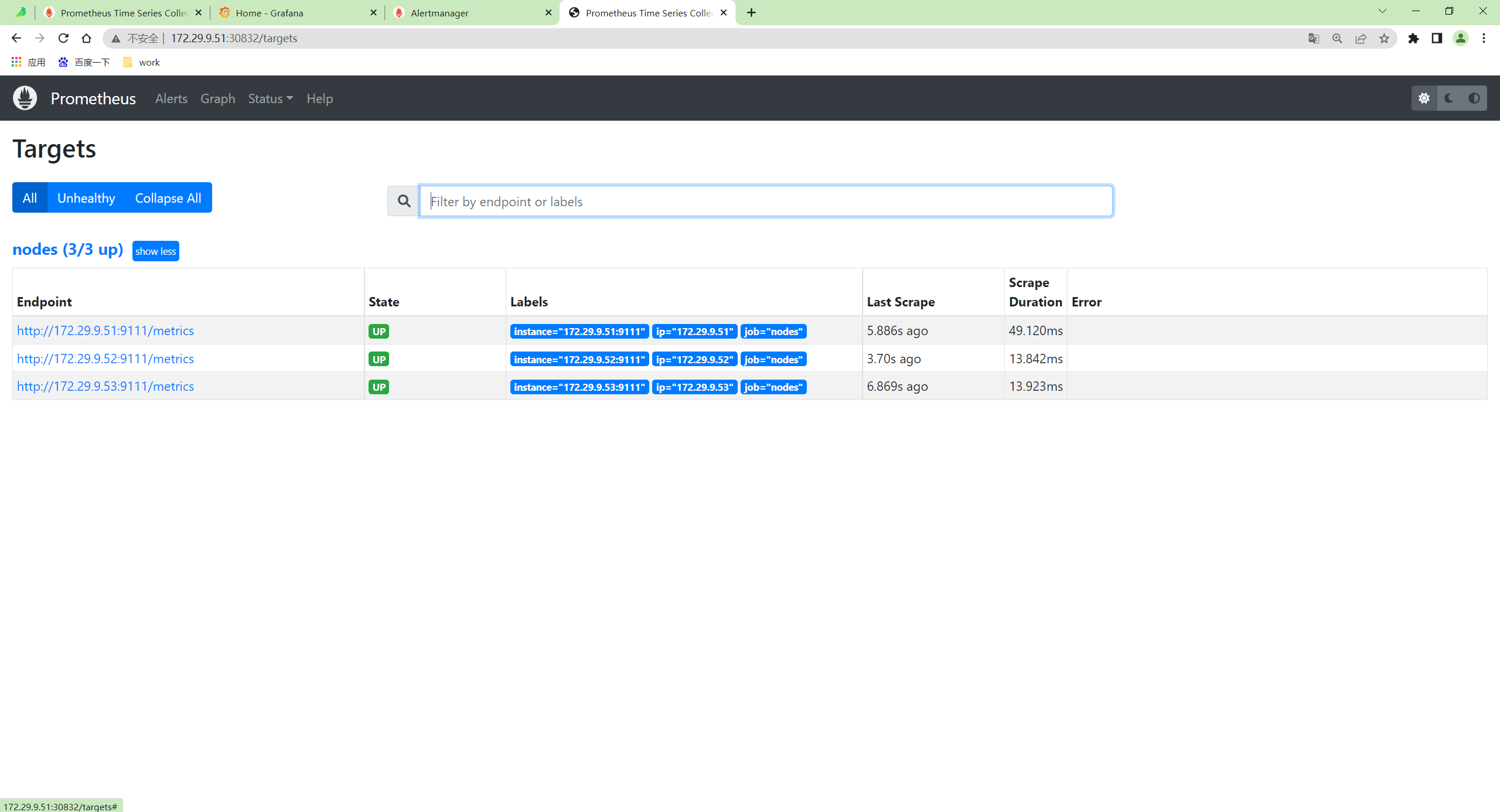
搭建成功。
这边有2个疑问:
疑问1:说不是还要部署prometheus的rbac资源呢?(已解决)
之前p8s部署在k8s里的课程,是有配置这个步骤的,但是本次实验,为啥没有这一个操作的。
按理说不是还需要再创建一个这个SA吧?
# prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount #创建一个ServiceAccount
metadata:
name: prometheus
namespace: kube-vm
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
- kind: ServiceAccount
name: prometheus
namespace: kube-vm这里直接在原来那个yaml里更新,或者重新创建一个就好吧。
这边可以先不创建,先当做遗留问题就好。
经测试,先不创建这个rbac资源,p8s是可以正常起来的。
哈哈,老师解惑了:
问题:我们这里是不是没配置rbac,p8s也是可以访问的呢?
答案:
因为目前只是p8s静态地去把数据抓取过来的,而不是自动发现的(不是用过apiserver去访问的)。所以现在,我们没有配置rbac是没有任何问题的。
疑问2:这里的local-storage只是一个标识而已的吧?(已解决)
按老师说的,这里要重新创建一个sc呀……
注意:
但是自己之前的实验这里都是没创建local-storage的sc呀……
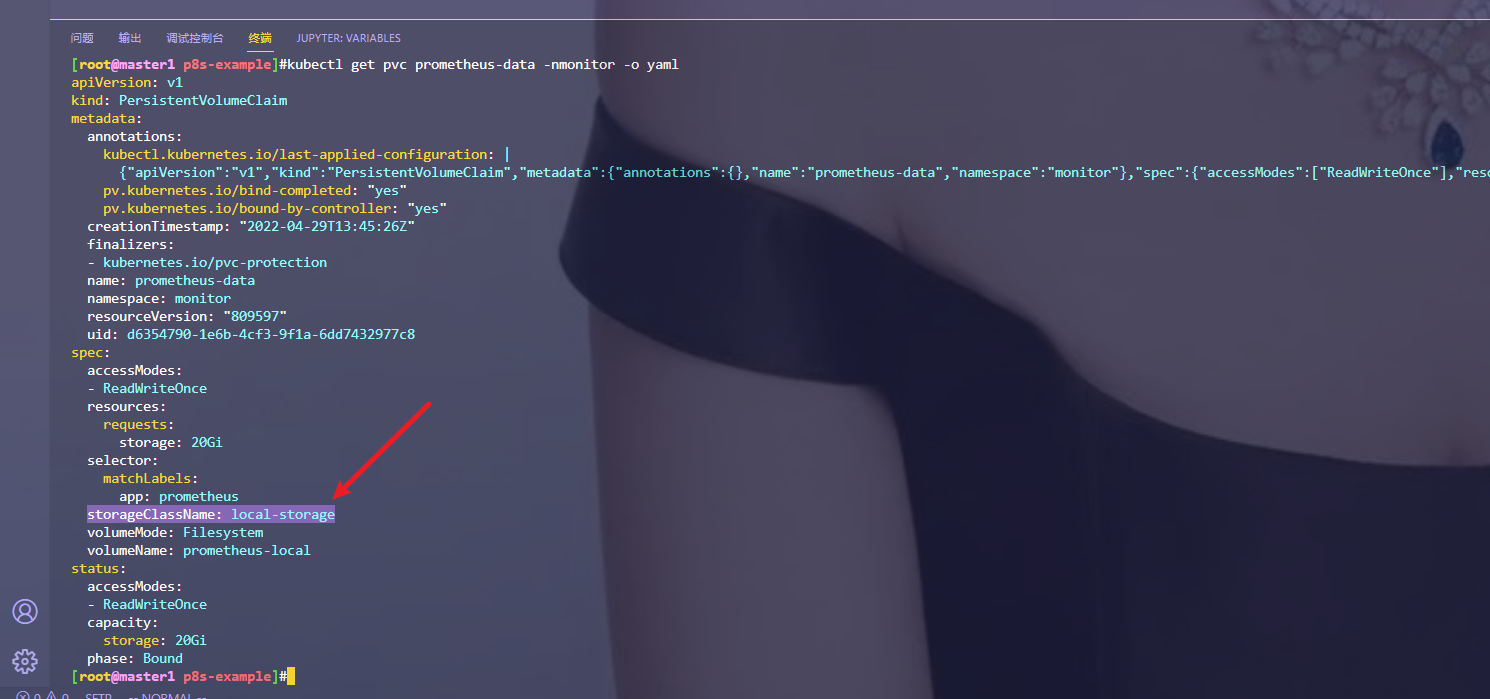
个人预测结论:
这里的local-storage只是一个标识而已,不需要来创建。!!!
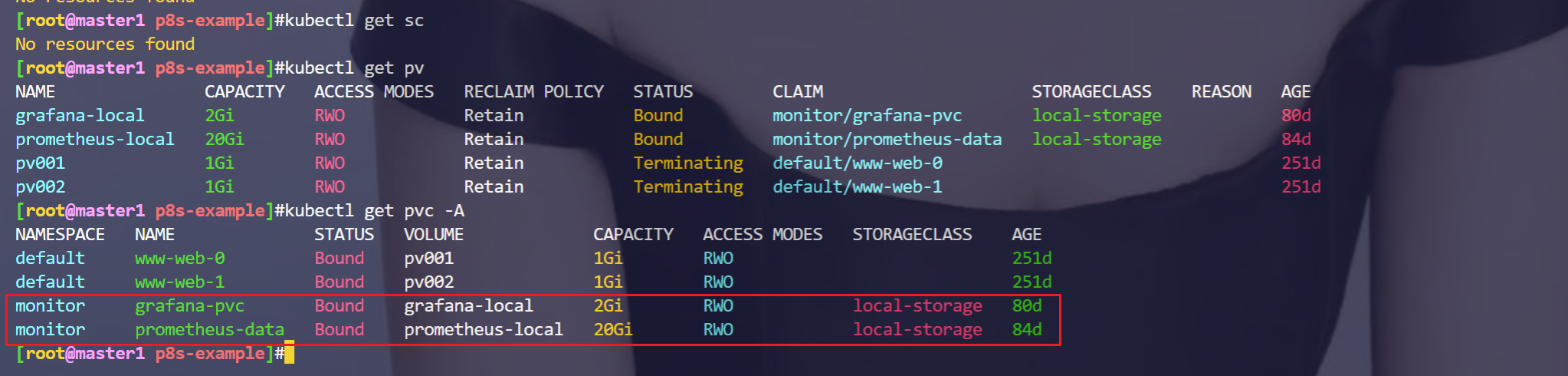
经测试:
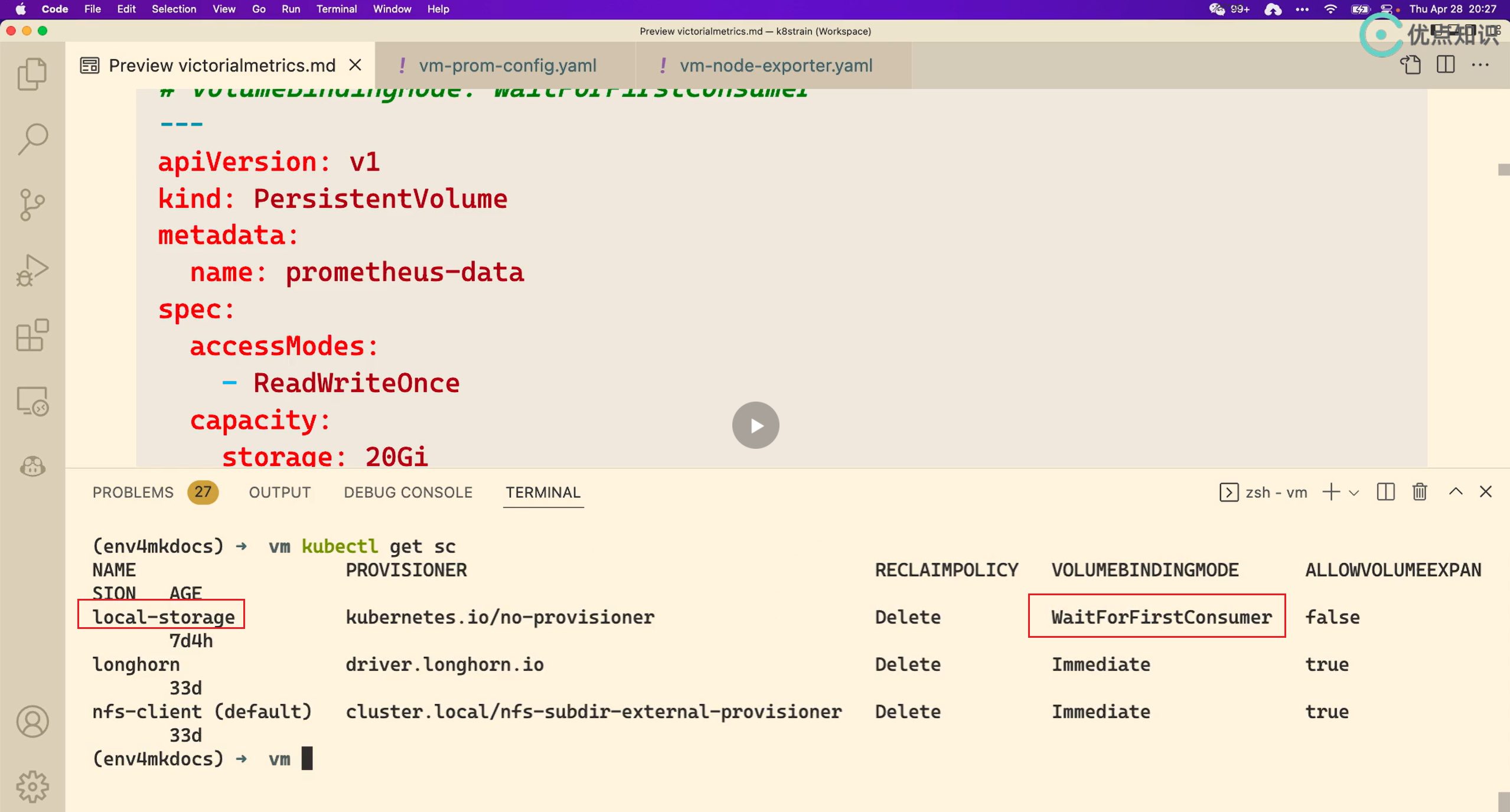
我的k8s集群里未创建这个local-storage sc,也是可以正常使用pv/pvc的。因此,这里的storageClassName: local-storage只是一个标识而已。

- 结论
storageClassName这里只是一个标识而已!!!
4.以同样的方式重新部署 Grafana
- 先到node2节点上创建下本地目录:
[root@master1 vm]#ssh node2
Last login: Sat Jul 23 16:14:21 2022 from master1
[root@node2 ~]#mkdir -p /data/k8s/grafana
[root@node2 ~]#exit
logout
Connection to node2 closed.- 同样的方式重新部署 Grafana,资源清单如下所示:
[root@master1 vm]#vim vm-grafana.yaml
# vm-grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-vm
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana-data
containers:
- name: grafana
image: grafana/grafana:main
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
securityContext:
runAsUser: 0
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-vm
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-data
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
storageClassName: local-storage
local:
path: /data/k8s/grafana
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-data
namespace: kube-vm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: local-storage- 部署
[root@master1 vm]#kubectl apply -f vm-grafana.yaml
deployment.apps/grafana created
service/grafana created
persistentvolume/grafana-data created
persistentvolumeclaim/grafana-data created- 查看
- 同样通过
http://<node-ip>:30868就可以访问 Grafana 了,进入 Grafana 配置 Prometheus 数据源。
admin/admin321
- 然后导入 16098 这个 Dashboard,导入后效果如下图所示。(次json文件已下载到本地)
到这里就完成了使用 Prometheus 收集节点监控指标,接下来我们来使用 VM 来改造现有方案。
疑问1:这个是一个老问题了,我的grafna这里使用svc直接访问为啥有问题,老师的没问题?
- 我的有问题
- 只能使用nodeip:nodePort来访问了:
- 老师的却没问题:
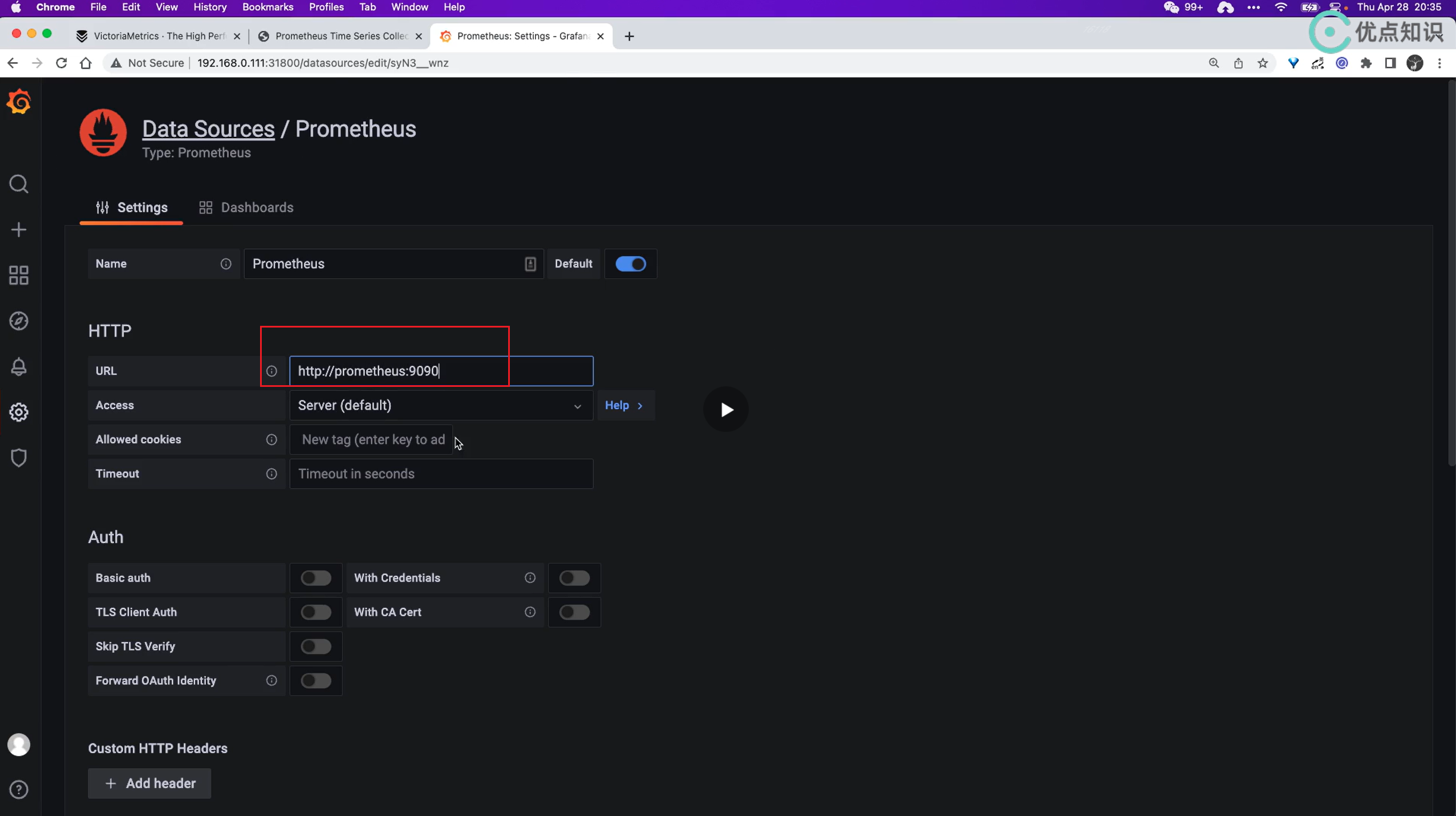
- 个人预测:
应该是和我k8s集群之前的core dns环境有关,稍后要排查下的。😢
这个问题先放着吧,后面再研究下。(2022年7月31日11:24:36)
1.远程存储 VictoriaMetrics
首先需要一个单节点模式的 VM,运行 VM 很简单,可以直接下载对应的二进制文件启动,也可以使用 docker 镜像一键启动,我们这里同样部署到 Kubernetes 集群中。
k8s里部署单节点vm
- 资源清单文件如下所示。
先在node2上创建持久化路径:
[root@master1 vm]#ssh node1
Last login: Wed May 4 19:51:38 2022 from master1
[root@node1 ~]#mkdir -p /data/k8s/vm[root@master1 vm]#vim vm.yaml
# vm.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: victoria-metrics
namespace: kube-vm
spec:
selector:
matchLabels:
app: victoria-metrics
template:
metadata:
labels:
app: victoria-metrics
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: victoria-metrics-data
containers:
- name: vm
image: victoriametrics/victoria-metrics:v1.76.1
imagePullPolicy: IfNotPresent
args:
- -storageDataPath=/var/lib/victoria-metrics-data
- -retentionPeriod=1w #默认一个月
ports:
- containerPort: 8428
name: http
volumeMounts:
- mountPath: /var/lib/victoria-metrics-data
name: storage
---
apiVersion: v1
kind: Service #vm还附带了一个web服务,类似于p8s的那个web界面,方便我们操作。
metadata:
name: victoria-metrics
namespace: kube-vm
spec:
type: NodePort
ports:
- port: 8428
selector:
app: victoria-metrics
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: victoria-metrics-data
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/vm #必须先创建这个路径
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: victoria-metrics-data
namespace: kube-vm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage这里我们使用 -storageDataPath 参数指定了数据存储目录,然后同样将该目录进行了持久化,-retentionPeriod 参数可以用来配置数据的保持周期。
- 直接应用上面的资源清单即可。
[root@master1 vm]#kubectl apply -f vm.yaml
deployment.apps/victoria-metrics created
service/victoria-metrics created
persistentvolume/victoria-metrics-data created
persistentvolumeclaim/victoria-metrics-data created
[root@master1 vm]#kubectl get deploy,svc,pod -n kube-vm
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 16h
deployment.apps/prometheus 1/1 1 1 17h
deployment.apps/victoria-metrics 1/1 1 1 5m1s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana NodePort 10.102.169.155 <none> 3000:30868/TCP 16h
service/prometheus NodePort 10.103.243.22 <none> 9090:30832/TCP 17h
service/victoria-metrics NodePort 10.111.174.185 <none> 8428:31526/TCP 5m1s
NAME READY STATUS RESTARTS AGE
pod/grafana-bbd99dc7-gjwxk 1/1 Running 0 16h
pod/node-exporter-56p88 1/1 Running 0 21h
pod/node-exporter-bjk82 1/1 Running 0 21h
pod/node-exporter-wnwgt 1/1 Running 0 21h
pod/prometheus-dfc9f6-l59mw 1/1 Running 0 17h
pod/victoria-metrics-7b5b5d4b65-zthq9 1/1 Running 0 2m14s
[root@master1 vm]#kubectl logs -f victoria-metrics-7b5b5d4b65-zthq9 -nkube-vm
2022-07-24T01:37:50.461Z info VictoriaMetrics/lib/mergeset/table.go:257 opening table "/var/lib/victoria-metrics-data/indexdb/1704A027396769B6"...
2022-07-24T01:37:50.462Z info VictoriaMetrics/lib/mergeset/table.go:292 table "/var/lib/victoria-metrics-data/indexdb/1704A027396769B6" has been opened in 0.001 seconds; partsCount: 0; blocksCount: 0, itemsCount: 0; sizeBytes: 0
2022-07-24T01:37:50.463Z info VictoriaMetrics/app/vmstorage/main.go:113 successfully opened storage "/var/lib/victoria-metrics-data" in 0.011 seconds; partsCount: 0; blocksCount: 0; rowsCount: 0; sizeBytes: 0
2022-07-24T01:37:50.464Z info VictoriaMetrics/app/vmselect/promql/rollup_result_cache.go:111 loading rollupResult cache from "/var/lib/victoria-metrics-data/cache/rollupResult"...
2022-07-24T01:37:50.466Z info VictoriaMetrics/app/vmselect/promql/rollup_result_cache.go:137 loaded rollupResult cache from "/var/lib/victoria-metrics-data/cache/rollupResult" in 0.002 seconds; entriesCount: 0, sizeBytes: 0
2022-07-24T01:37:50.467Z info VictoriaMetrics/app/victoria-metrics/main.go:61 started VictoriaMetrics in 0.015 seconds
2022-07-24T01:37:50.467Z info VictoriaMetrics/lib/httpserver/httpserver.go:91 starting http server at http://127.0.0.1:8428/
2022-07-24T01:37:50.467Z info VictoriaMetrics/lib/httpserver/httpserver.go:92 pprof handlers are exposed at http://127.0.0.1:8428/debug/pprof/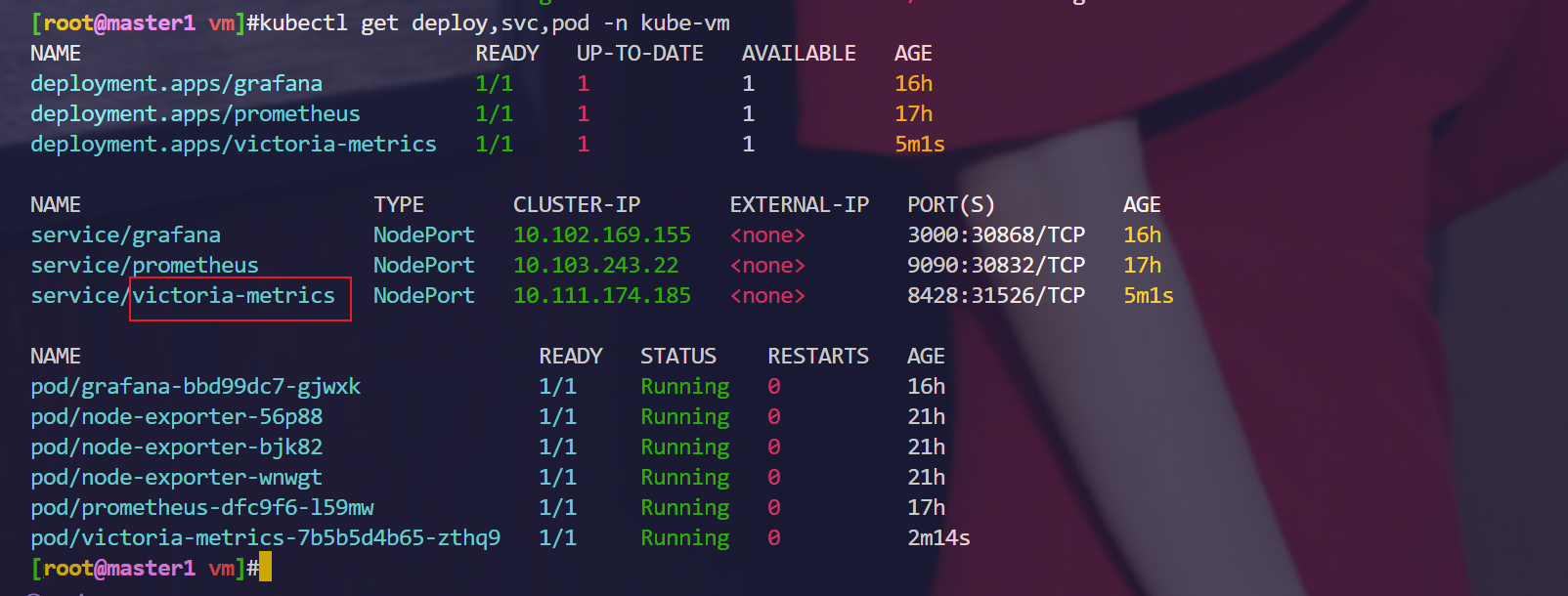
到这里我们单节点的 VictoriaMetrics 就部署成功了。
远程存储 VictoriaMetrics
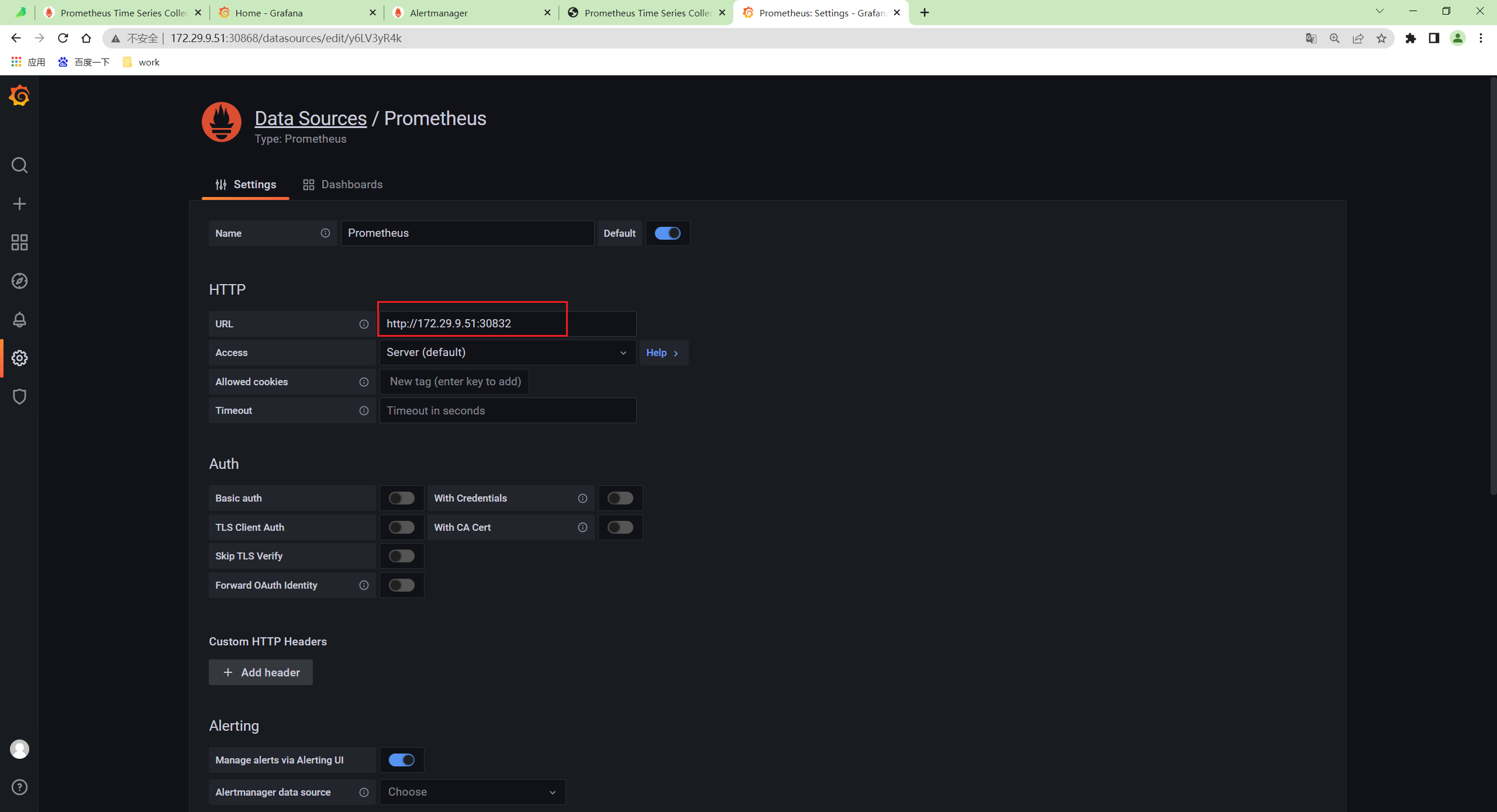
- 接下来我们只需要在 Prometheus 中配置远程写入我们的 VM 即可,更改 Prometheus 配置:
[root@master1 vm]#pwd
/root/vm
[root@master1 vm]#ls
vm-grafana.yaml vm-node-exporter.yaml vm-prom-config.yaml vm-prom-deploy.yaml vm-prom-pvc.yaml vm.yaml
[root@master1 vm]#vim vm-prom-config.yaml
# vm-prom-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-vm
data:
prometheus.yaml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
remote_write: # 远程写入到远程 VM 存储
- url: http://victoria-metrics:8428/api/v1/write
scrape_configs:
- job_name: "nodes"
static_configs:
- targets: ['192.168.0.109:9111', '192.168.0.110:9111', '192.168.0.111:9111']
relabel_configs: # 通过 relabeling 从 __address__ 中提取 IP 信息,为了后面验证 VM 是否兼容 relabeling
- source_labels: [__address__]
regex: "(.*):(.*)"
replacement: "${1}"
target_label: 'ip'
action: replace- 重新更新 Prometheus 的配置资源对象:
[root@master1 vm]#kubectl apply -f vm-prom-config.yaml
configmap/prometheus-config configured
# 更新后执行 reload 操作重新加载 prometheus 配置
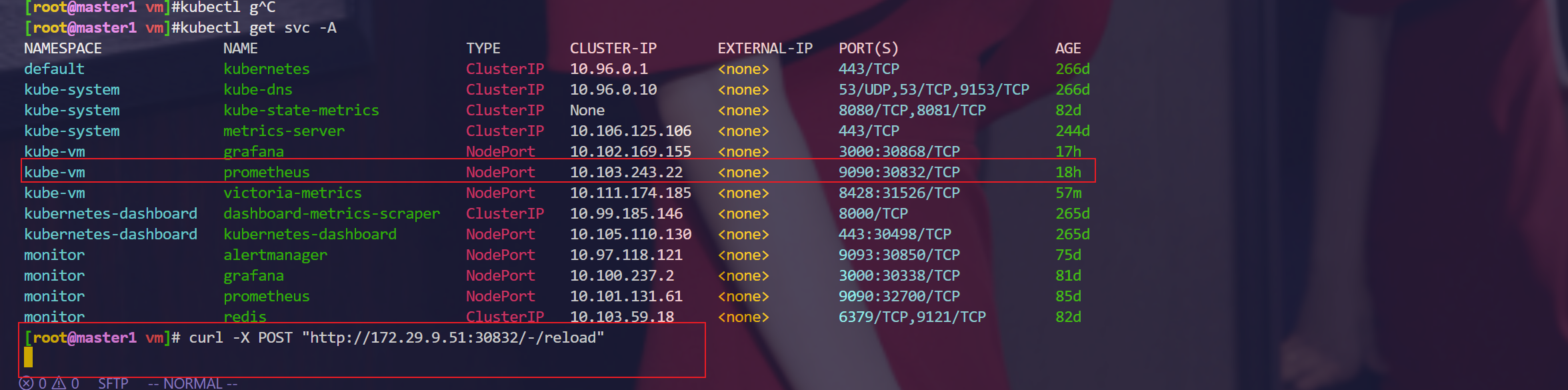
[root@master1 vm]# curl -X POST "http://172.29.9.51:30832/-/reload"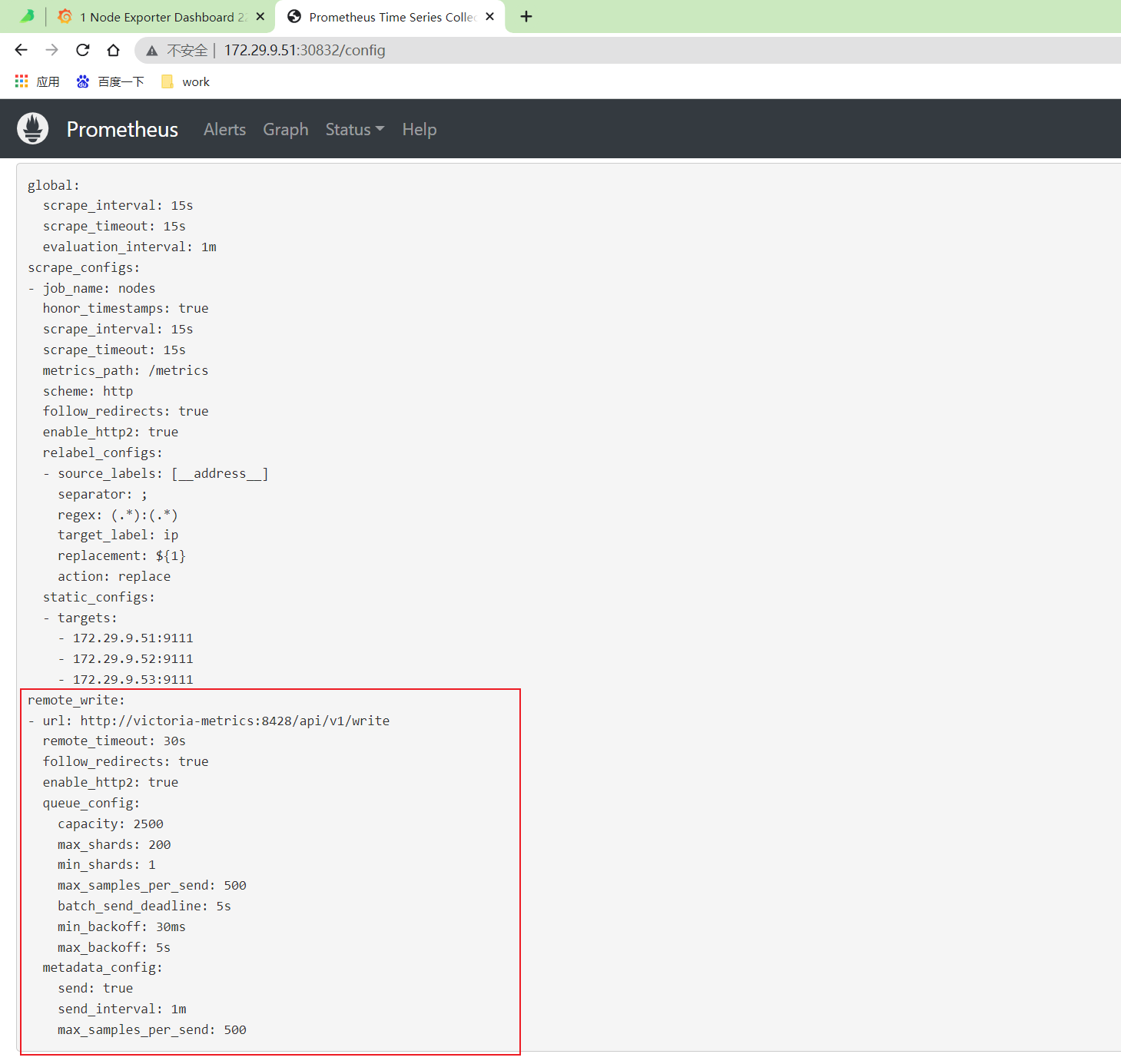
注意
这里其实可以部署一个sidecar容器,它去检查这个配置文件的变化,如果检测到了其有变化,他就会主动触发一个reload操作,这样就不用我们每次去执行reload操作了!!!(之前那个thanos就是这个原理)
- 配置生效后 Prometheus 就会开始将数据远程写入 VM 中,我们可以查看 VM 的持久化数据目录是否有数据产生来验证:
[root@master1 vm]#ssh node2
Last login: Sun Jul 24 09:34:40 2022 from master1
[root@node2 ~]#ll /data/k8s/vm/data/
total 0
drwxr-xr-x 3 root root 23 Jul 24 09:37 big
-rw-r--r-- 1 root root 0 Jul 24 09:37 flock.lock
drwxr-xr-x 3 root root 23 Jul 24 09:37 small- 现在我们去直接将 Grafana 中的数据源地址修改成 VM 的地址:
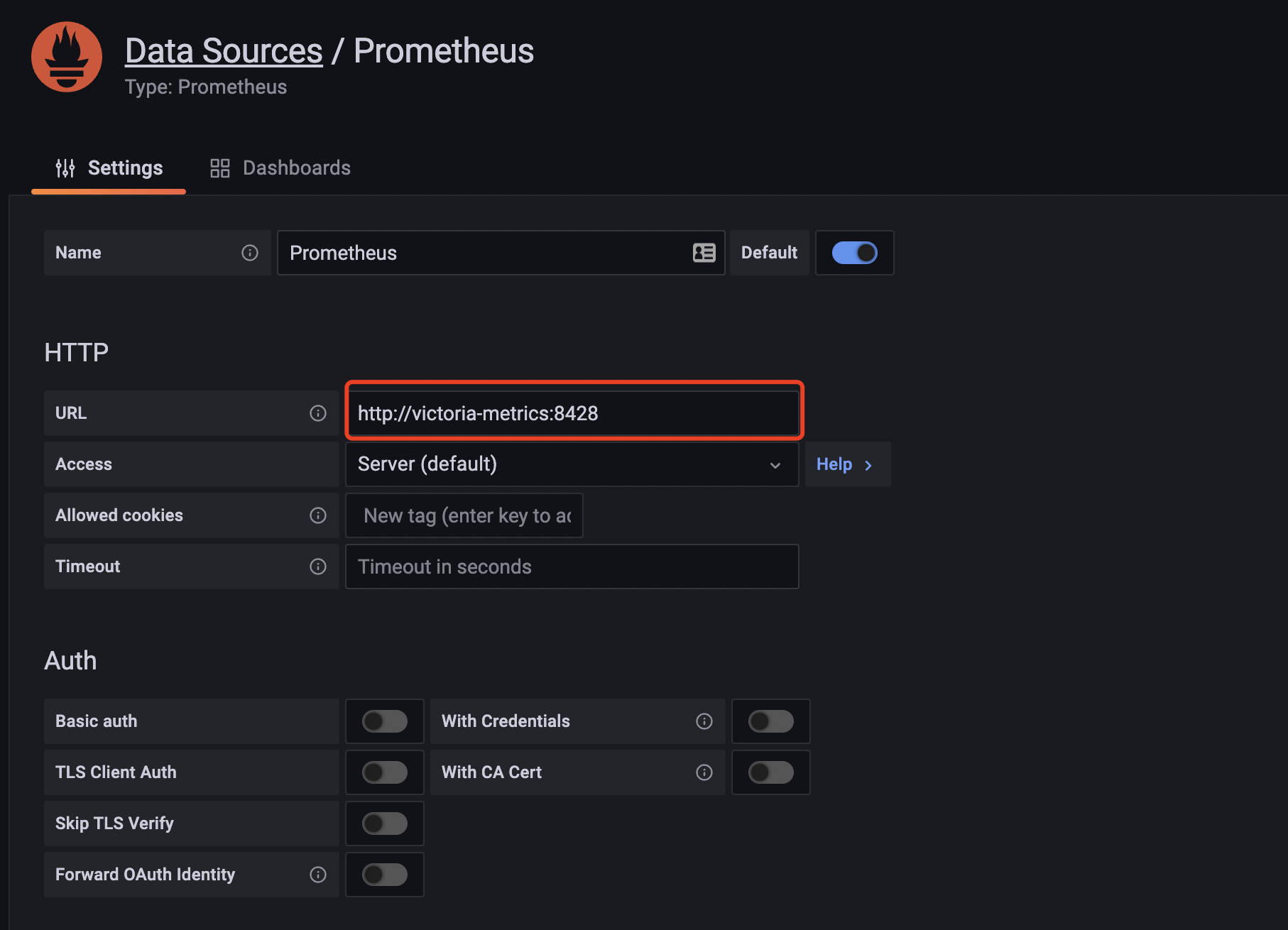
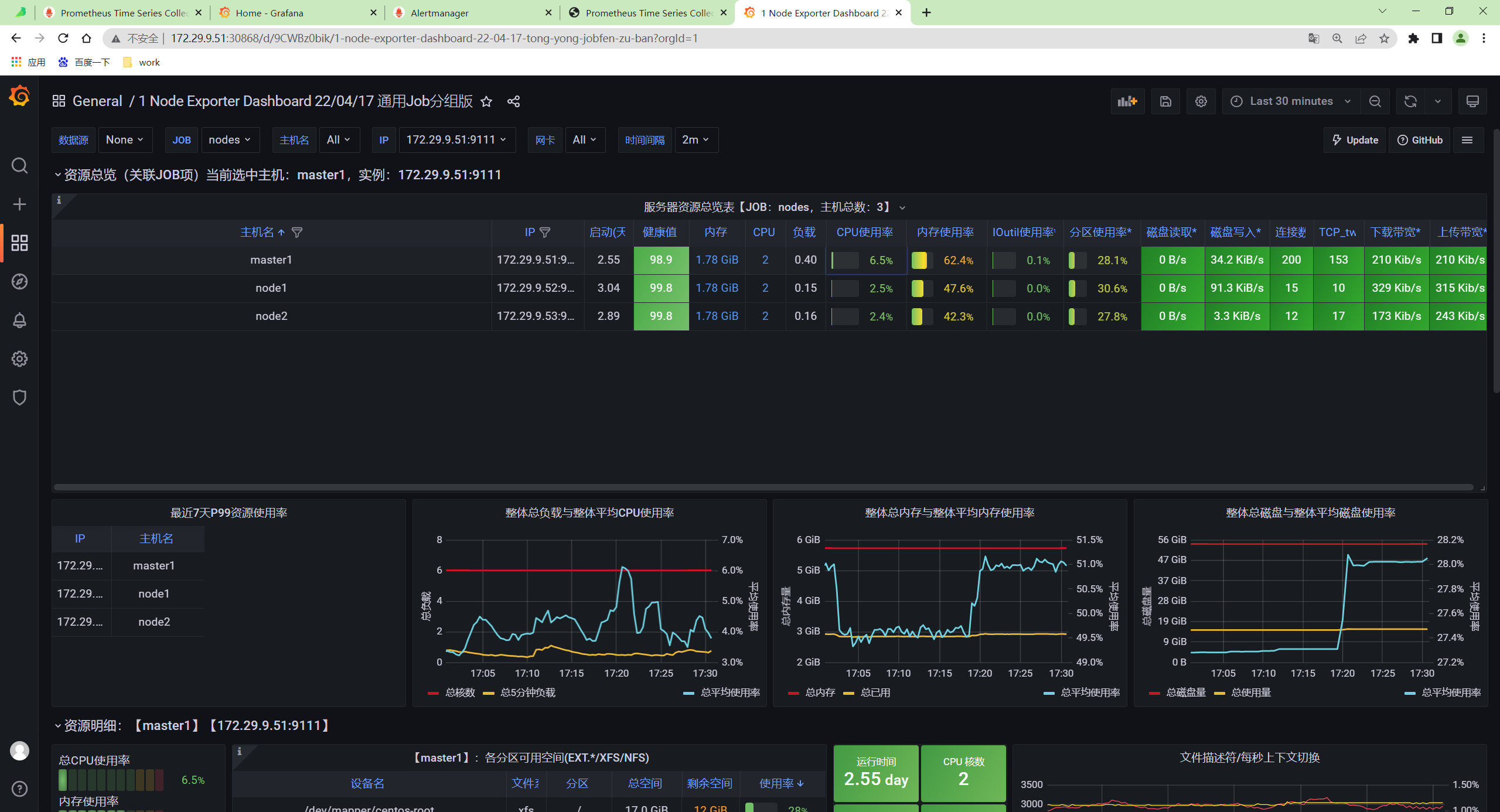
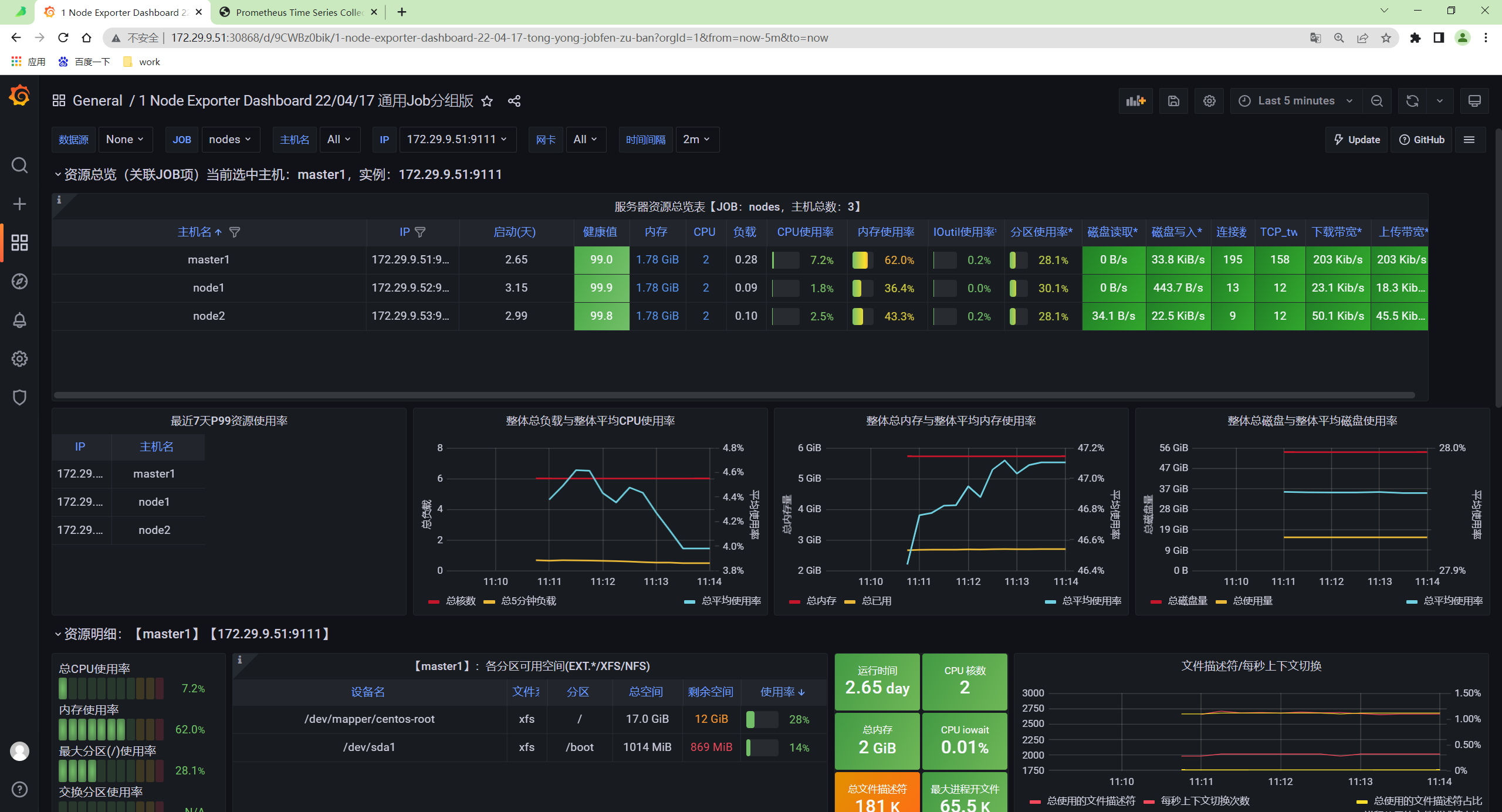
修改完成后重新访问 node-exporter 的 dashboard,正常可以显示,证明 VM 是兼容的。
奇怪:自己这个为什没数据呢?
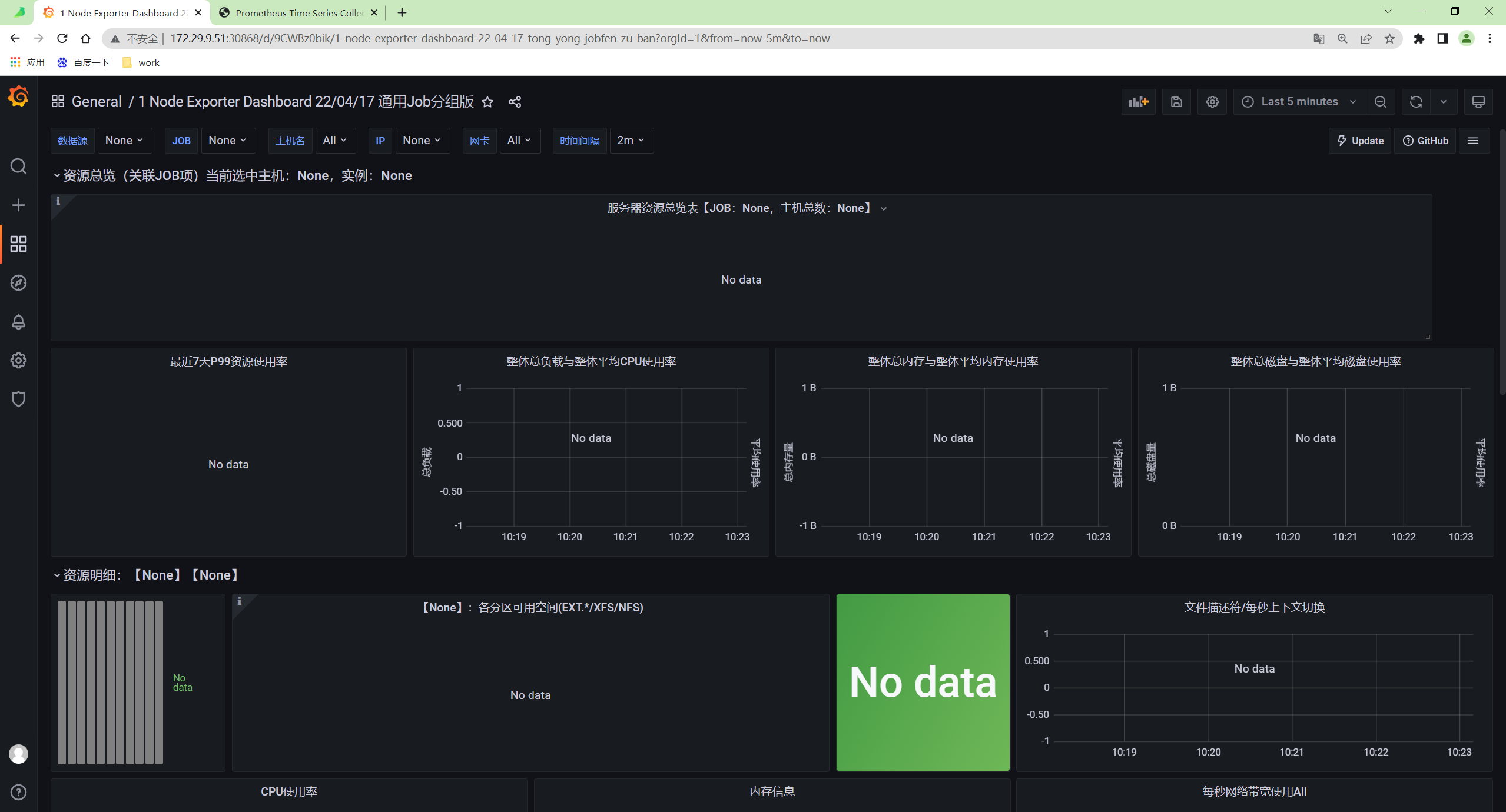
估计是这个问题……
替换了不行的,这里有问题……reload不了。
但是,后面又有数据了……

还是有一些信息的。
2.替换 Prometheus
上面我们将 Prometheus 数据远程写入到了 VM,但是 Prometheus 开启 remote write 功能后会增加其本身的资源占用。理论上其实我们也可以完全用 VM 来替换掉 Prometheus,这样就不需要远程写入了,而且本身 VM 就比 Prometheus 占用更少的资源。
- 现在我们先停掉 Prometheus 的服务:
[root@master1 vm]#kubectl scale deployment prometheus --replicas=0 -nkube-vm
deployment.apps/prometheus scaled- 然后将 Prometheus 的配置文件挂载到 VM 容器中,使用参数
-promscrape.config来指定 Prometheus 的配置文件路径,如下所示:
[root@master1 vm]#pwd
/root/vm
[root@master1 vm]#ls
vm-grafana.yaml vm-node-exporter.yaml vm-prom-config.yaml vm-prom-deploy.yaml vm-prom-pvc.yaml vm.yaml
[root@master1 vm]#vim vm.yaml
# vm.yaml
#本次新增内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: victoria-metrics
namespace: kube-vm
spec:
selector:
matchLabels:
app: victoria-metrics
template:
metadata:
labels:
app: victoria-metrics
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: victoria-metrics-data
- name: prometheus-config
configMap: #这里使用ConfigMap
name: prometheus-config
containers:
- name: vm
image: victoriametrics/victoria-metrics:v1.76.1
imagePullPolicy: IfNotPresent
args:
- -storageDataPath=/var/lib/victoria-metrics-data
- -retentionPeriod=1w
- -promscrape.config=/etc/prometheus/prometheus.yaml #这里将prometheus.yaml 挂载进来
ports:
- containerPort: 8428
name: http
volumeMounts:
- mountPath: /var/lib/victoria-metrics-data
name: storage
- mountPath: /etc/prometheus #挂载路径
name: prometheus-config完整代码如下:
cat vm.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: victoria-metrics
namespace: kube-vm
spec:
selector:
matchLabels:
app: victoria-metrics
template:
metadata:
labels:
app: victoria-metrics
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: victoria-metrics-data
- name: prometheus-config
configMap: #这里使用ConfigMap
name: prometheus-config
containers:
- name: vm
image: victoriametrics/victoria-metrics:v1.76.1
imagePullPolicy: IfNotPresent
args:
- -storageDataPath=/var/lib/victoria-metrics-data
- -retentionPeriod=1w
- -promscrape.config=/etc/prometheus/prometheus.yaml #这里将prometheus.yaml 挂载进来
ports:
- containerPort: 8428
name: http
volumeMounts:
- mountPath: /var/lib/victoria-metrics-data
name: storage
- mountPath: /etc/prometheus #挂载路径
name: prometheus-config
---
apiVersion: v1
kind: Service #vm还附带了一个web服务,类似于p8s的那个web界面,方便我们操作。
metadata:
name: victoria-metrics
namespace: kube-vm
spec:
type: NodePort
ports:
- port: 8428
selector:
app: victoria-metrics
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: victoria-metrics-data
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/vm #必须先创建这个路径
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: victoria-metrics-data
namespace: kube-vm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage- 记得先将 Prometheus 配置文件中的 remote_write 模块去掉:
[root@master1 vm]#ls
vm-grafana.yaml vm-node-exporter.yaml vm-prom-config.yaml vm-prom-deploy.yaml vm-prom-pvc.yaml vm.yaml
[root@master1 vm]#vim vm-prom-config.yaml
[root@master1 vm]#kubectl delete -f vm-prom-config.yaml
configmap "prometheus-config" deleted
[root@master1 vm]#kubectl apply -f vm-prom-config.yaml
configmap/prometheus-config created- 更新vm部署文件:
[root@master1 vm]#kubectl apply -f vm-prom-config.yaml
configmap/prometheus-config configerd
[root@master1 vm]#kubectl delete -f vm.yaml
deployment.apps "victoria-metrics" deleted
service "victoria-metrics" deleted
persistentvolume "victoria-metrics-data" deleted
persistentvolumeclaim "victoria-metrics-data" deleted
[root@master1 vm]#kubectl apply -f vm.yaml
deployment.apps/victoria-metrics created
service/victoria-metrics created
persistentvolume/victoria-metrics-data created
persistentvolumeclaim/victoria-metrics-data created
[root@master1 vm]#kubectl get pods -n kube-vm -l app=victoria-metrics
NAME READY STATUS RESTARTS AGE
victoria-metrics-8466844968-s9slx 1/1 Running 0 35s
[root@master1 vm]#kubectl logs victoria-metrics-8466844968-s9slx -nkube-vm
......
2022-07-24T03:10:29.799Z info VictoriaMetrics/app/victoria-metrics/main.go:61 started VictoriaMetrics in 0.021 seconds
2022-07-24T03:10:29.799Z info VictoriaMetrics/lib/httpserver/httpserver.go:91 starting http server at http://127.0.0.1:8428/
2022-07-24T03:10:29.799Z info VictoriaMetrics/lib/httpserver/httpserver.go:92 pprof handlers are exposed at http://127.0.0.1:8428/debug/pprof/
2022-07-24T03:10:29.799Z info VictoriaMetrics/lib/promscrape/scraper.go:103 reading Prometheus configs from "/etc/prometheus/prometheus.yaml"
2022-07-24T03:10:29.800Z info VictoriaMetrics/lib/promscrape/config.go:96 starting service discovery routines...
2022-07-24T03:10:29.800Z info VictoriaMetrics/lib/promscrape/config.go:102 started service discovery routines in 0.000 seconds
2022-07-24T03:10:29.800Z info VictoriaMetrics/lib/promscrape/scraper.go:395 static_configs: added targets: 3, removed targets: 0; total targets: 3从 VM 日志中可以看出成功读取了 Prometheus 的配置,并抓取了 3 个指标(node-exporter)。
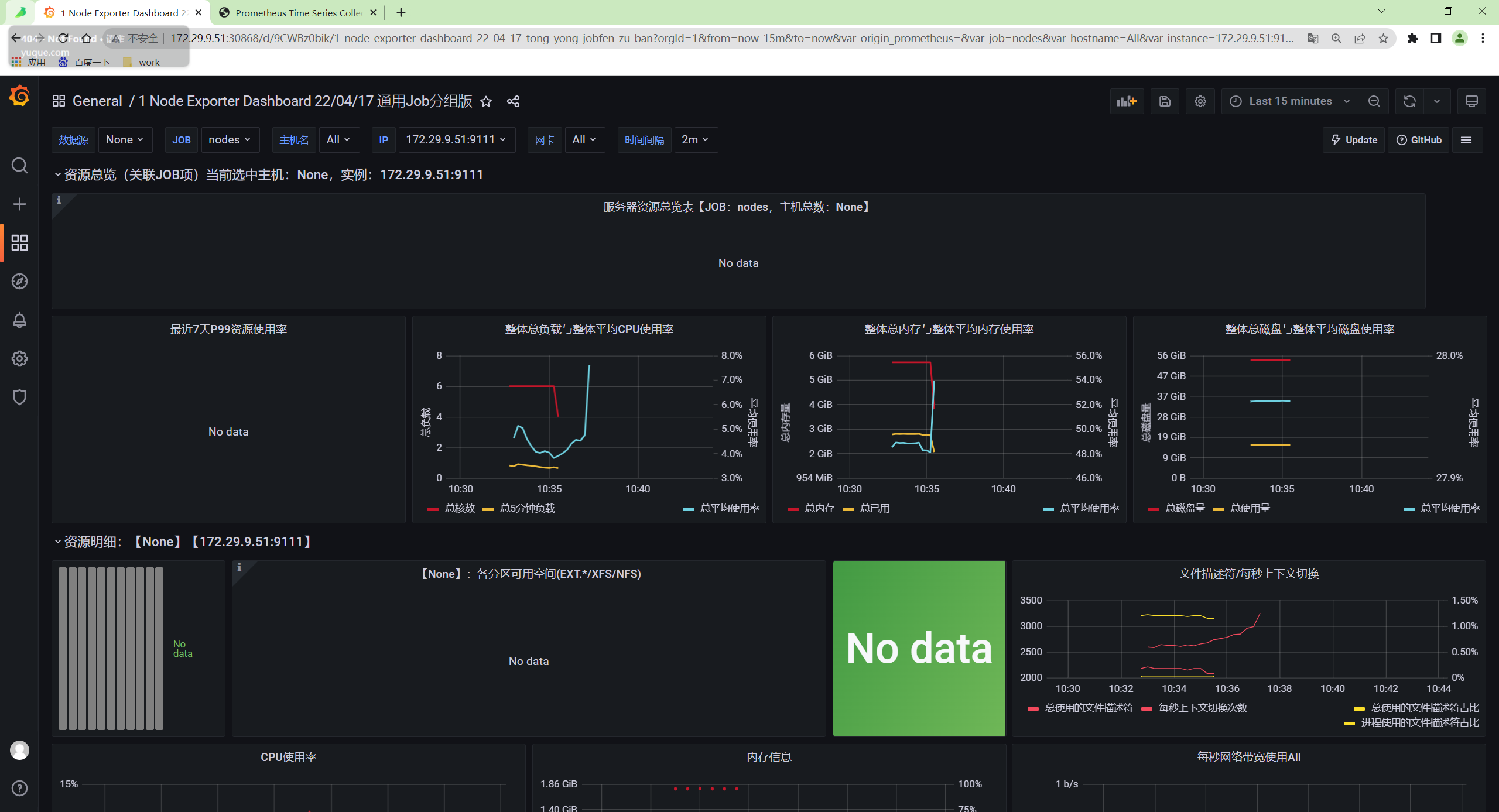
- 现在我们再去 Grafana 查看 node-exporter 的 Dashboard 是否可以正常显示。先保证数据源是 VM 的地址。

这样我们就使用 VM 替换掉了 Prometheus,我们也可以这 Grafana 的 Explore 页面去探索采集到的指标。
3.UI 界面
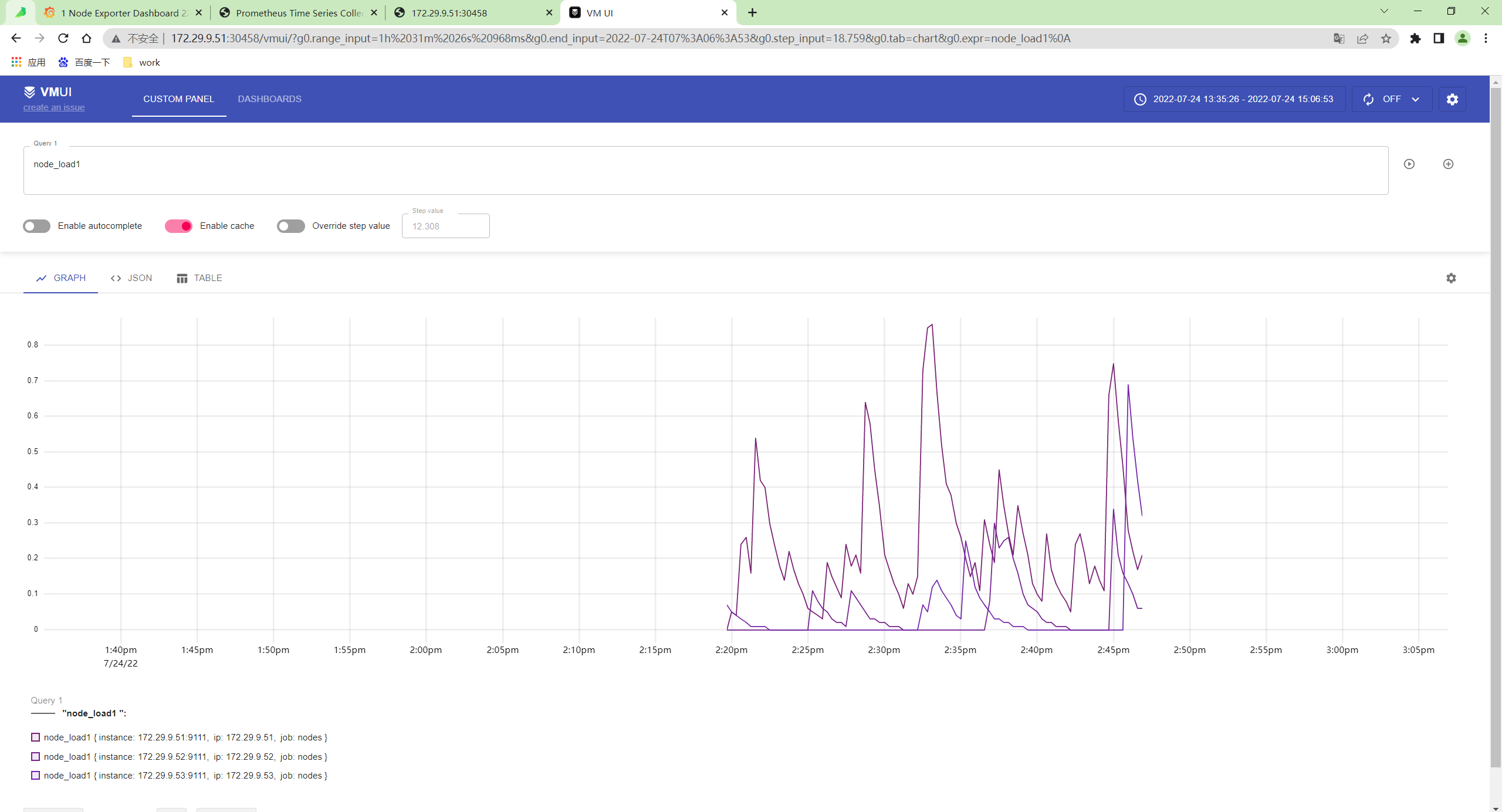
VM 单节点版本本身自带了一个 Web UI 界面 - vmui,不过目前功能比较简单。
- 可以直接通过 VM 的 NodePort 端口进行访问。
[root@master1 ~]#kubectl get svc -nkube-vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.102.169.155 <none> 3000:30868/TCP 21h
prometheus NodePort 10.103.243.22 <none> 9090:30832/TCP 22h
victoria-metrics NodePort 10.103.196.207 <none> 8428:30458/TCP 3h33m我们这里可以通过 http://<node-ip>:30458 访问到 vmui:
- 可以通过
/vmui这个 endpoint 访问 UI 界面:
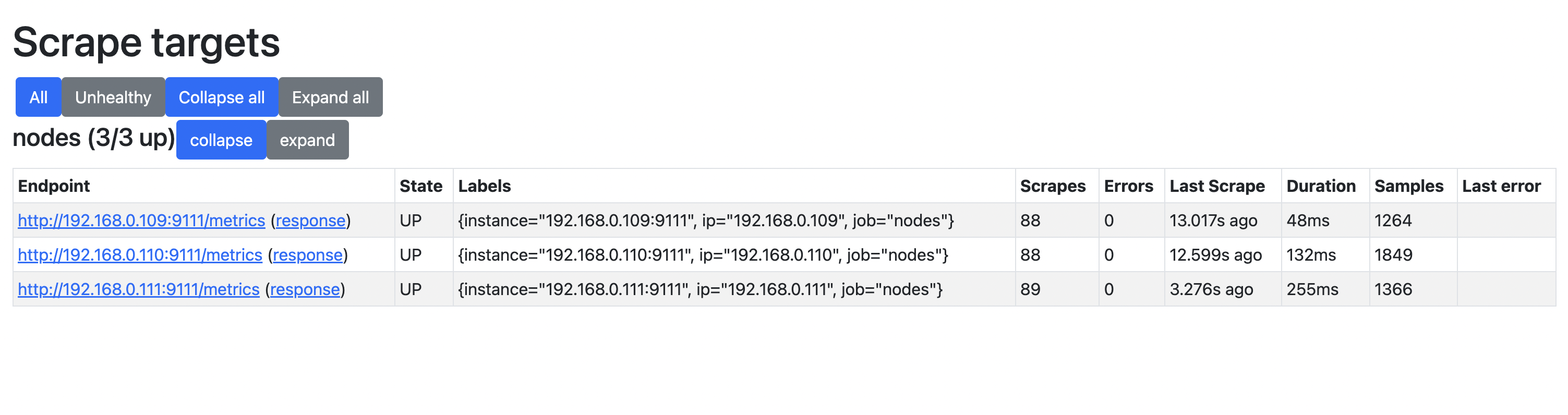
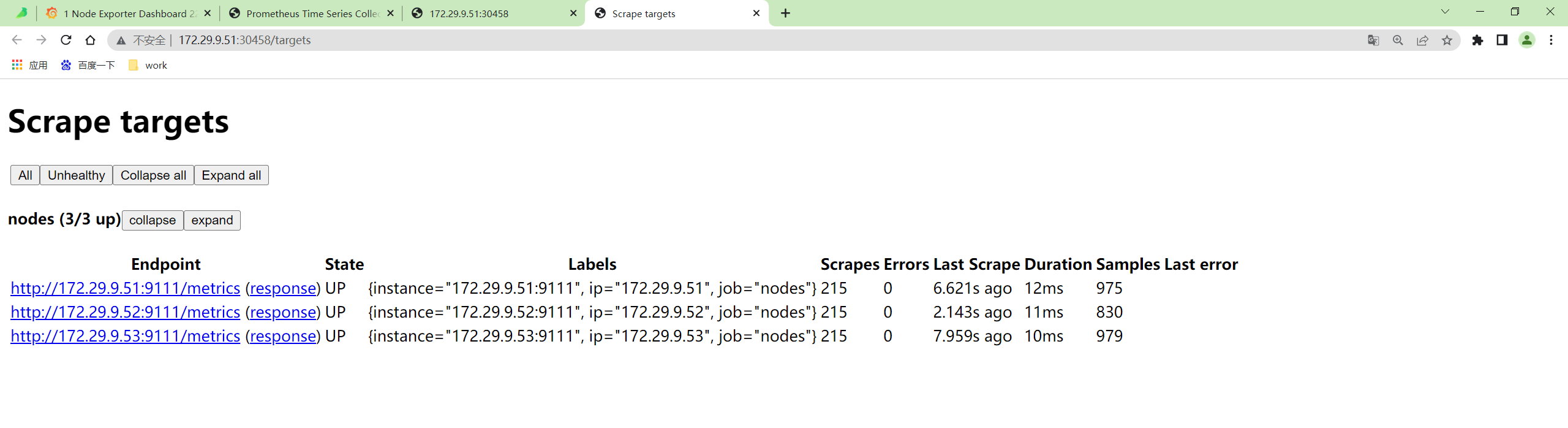
- 如果你想查看采集到的指标 targets,那么可以通过
/targets这个 endpoint 来获取:
这些功能基本上可以满足我们的一些需求,但是还是太过简单。
哈哈,我的是这个显示……
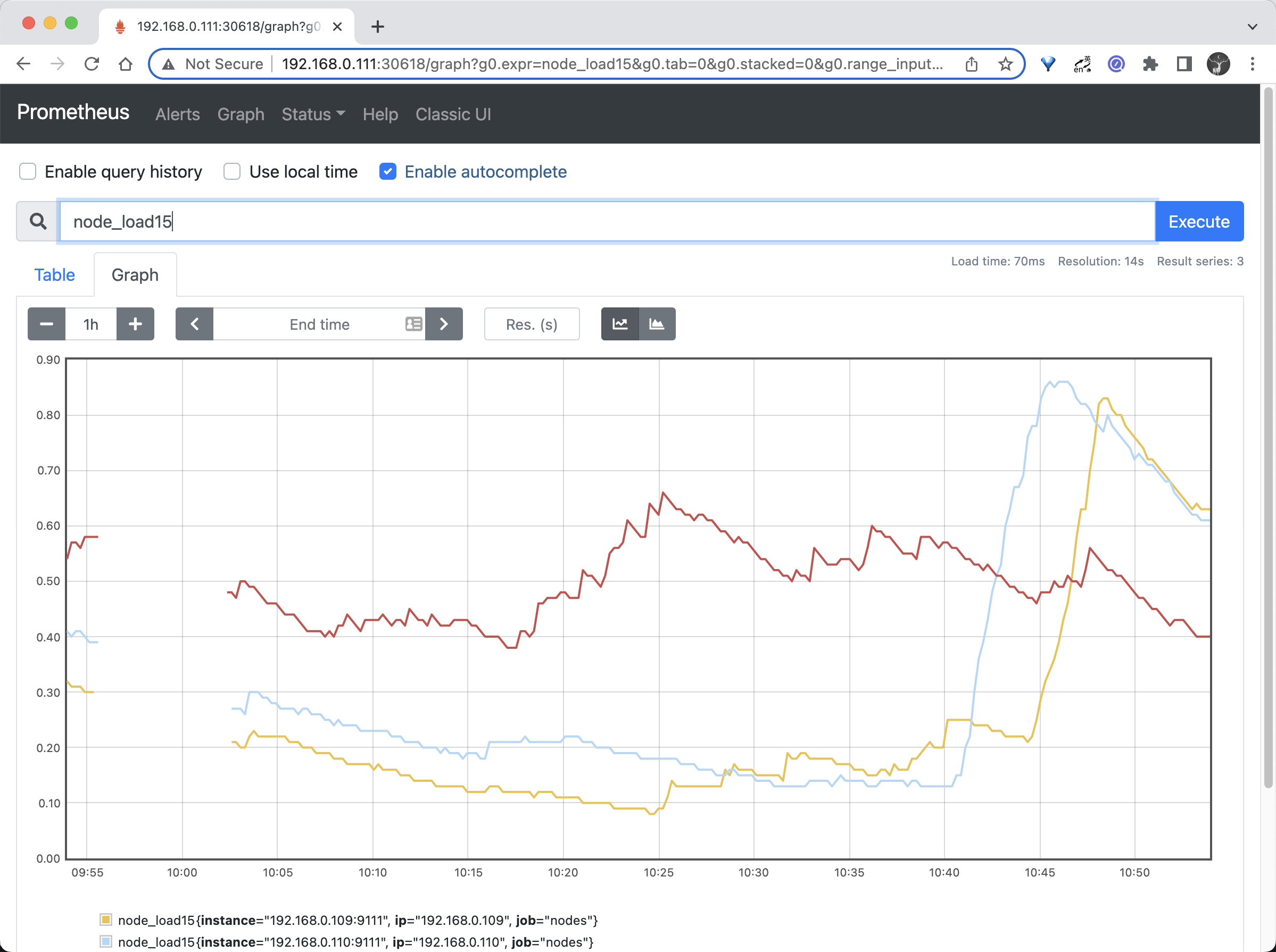
- 如果你习惯了 Prometheus 的 UI 界面,那么我们可以使用
promxy来代替vmui,而且promxy还可以进行多个 VM 单节点(不只是vm,对p8s也是可以的)的数据聚合,以及 targets 查看等,对应的资源清单文件如下所示:
[root@master1 vm]#pwd
/root/vm
[root@master1 vm]#ls
vm-grafana.yaml vm-node-exporter.yaml vm-prom-config.yaml vm-prom-deploy.yaml vm-prom-pvc.yaml vm.yaml
[root@master1 vm]#vim vm-promxy.yaml
# vm-promxy.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: promxy-config
namespace: kube-vm
data:
config.yaml: |
promxy:
server_groups:
- static_configs:
- targets: [victoria-metrics:8428] # 指定vm地址,有多个则往后追加即可
path_prefix: /prometheus # 配置前缀
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: promxy
namespace: kube-vm
spec:
selector:
matchLabels:
app: promxy
template:
metadata:
labels:
app: promxy
spec:
containers:
- args:
- "--config=/etc/promxy/config.yaml"
- "--web.enable-lifecycle"
- "--log-level=trace"
env:
- name: ROLE
value: "1"
command:
- "/bin/promxy"
image: quay.io/jacksontj/promxy
imagePullPolicy: Always
name: promxy
ports:
- containerPort: 8082
name: web
volumeMounts:
- mountPath: "/etc/promxy/"
name: promxy-config
readOnly: true
- args: # container to reload configs on configmap change 这个需要特别注意下哦,是一个sidecar容器。
- "--volume-dir=/etc/promxy"
- "--webhook-url=http://localhost:8082/-/reload"
image: jimmidyson/configmap-reload:v0.1
name: promxy-server-configmap-reload
volumeMounts:
- mountPath: "/etc/promxy/"
name: promxy-config
readOnly: true
volumes:
- configMap:
name: promxy-config
name: promxy-config
---
apiVersion: v1
kind: Service
metadata:
name: promxy
namespace: kube-vm
spec:
type: NodePort
ports:
- port: 8082
selector:
app: promxy- 直接应用上面的资源对象即可:
[root@master1 vm]#kubectl apply -f vm-promxy.yaml
configmap/promxy-config created
deployment.apps/promxy created
service/promxy created
[root@master1 vm]#kubectl get pods -n kube-vm -l app=promxy
NAME READY STATUS RESTARTS AGE
promxy-5f7dfdbc64-82cr6 2/2 Running 0 34s
[root@master1 vm]#kubectl get svc promxy -n kube-vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
promxy NodePort 10.97.84.86 <none> 8082:32380/TCP 52s- 访问 Promxy 的页面效果和 Prometheus 自带的 Web UI 基本一致的。
这里面我们简单介绍了单机版的 victoriametrics 的基本使用。
额额,我这里又报这个错误了……
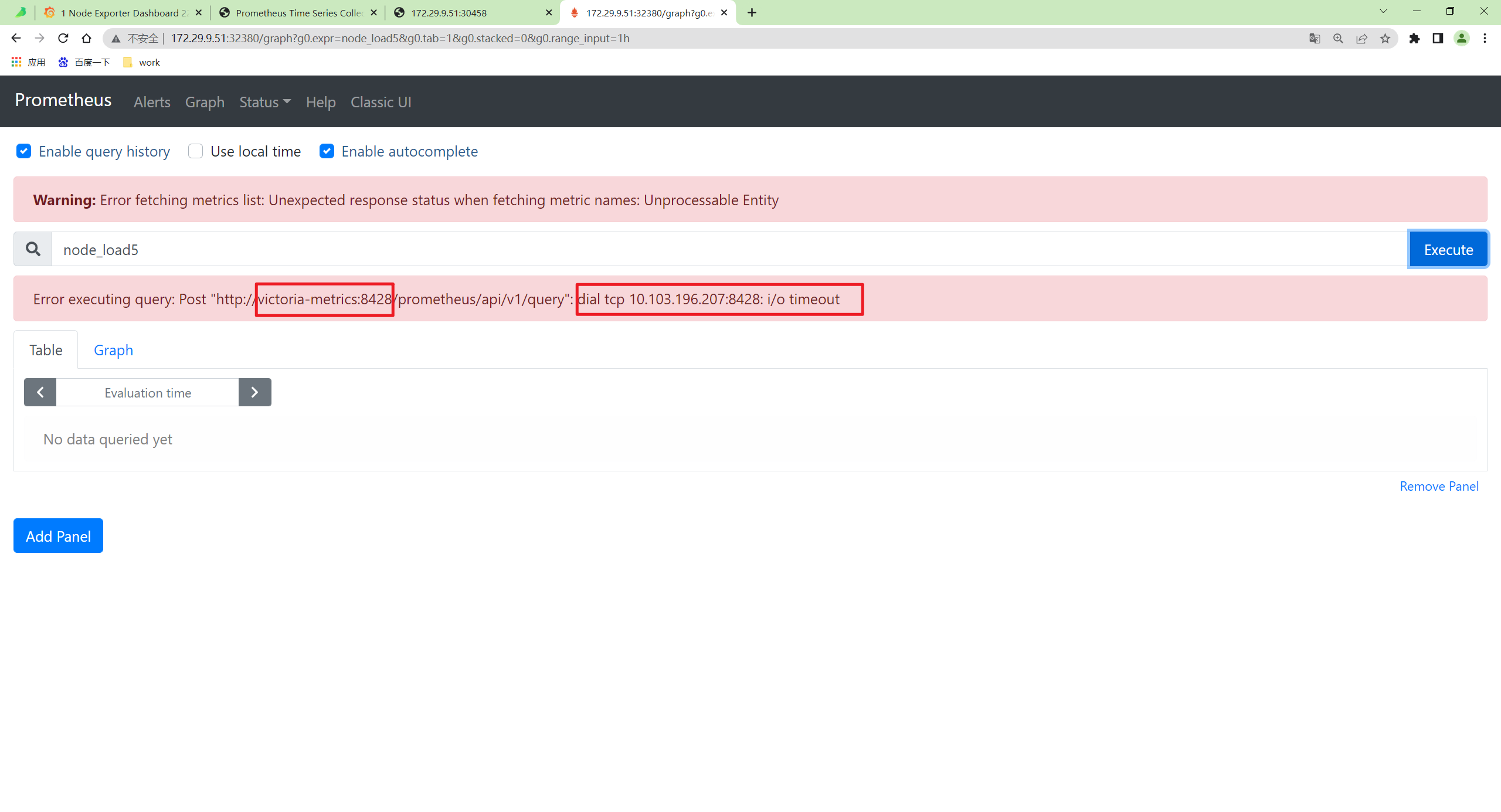
估计是这里的问题:
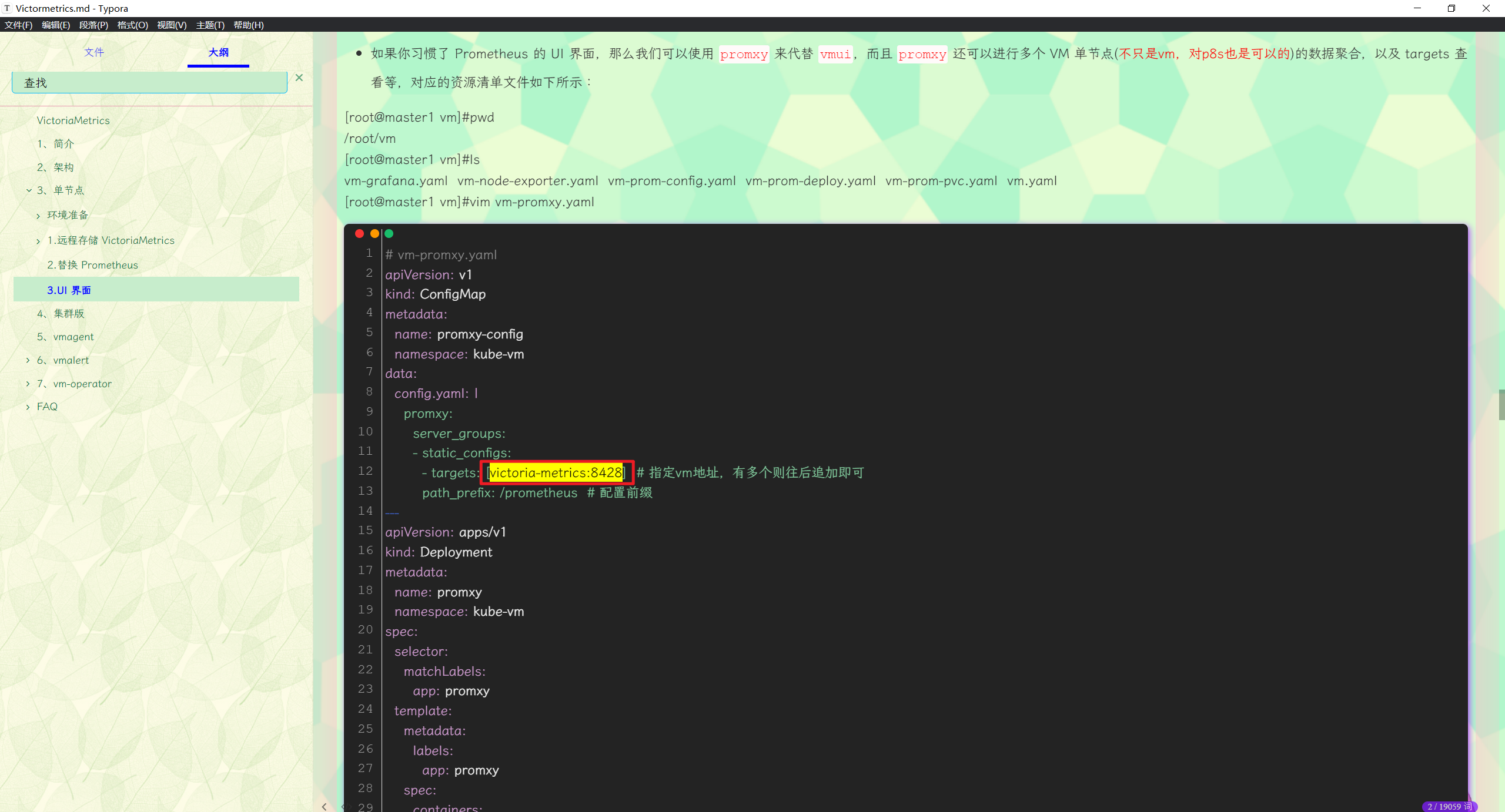
- 这里修改下,再次测试下
[root@master1 vm]#vim vm-promxy.yaml

[root@master1 vm]#kubectl apply -f vm-promxy.yaml
configmap/promxy-config configured
deployment.apps/promxy unchanged
service/promxy unchanged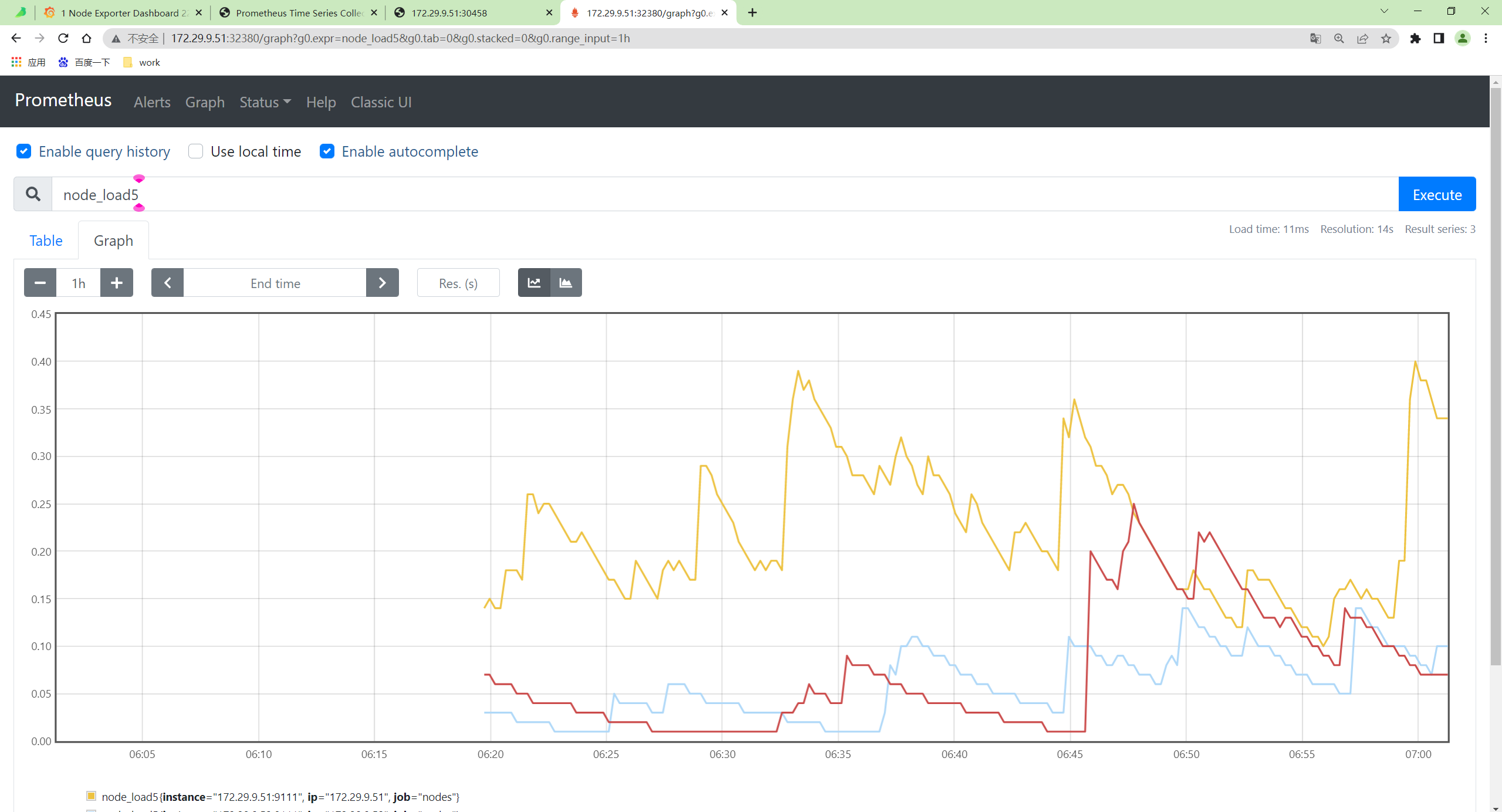
(修改后果然好了。。。。)🤣
- 这里是有点不一样,其他都差不多
测试结束。😘
2、集群版
对于低于每秒一百万个数据点的摄取率,建议使用单节点版本而不是集群版本。单节点版本可根据 CPU 内核、RAM 和可用存储空间的数量进行扩展。单节点版本比集群版本更容易配置和操作,所以在使用集群版本之前要三思而后行。上面我们介绍了 VM 的单节点版本的基本使用,接下来我们来介绍下如何使用集群版。
集群版主要特点
- 支持单节点版本的所有功能。
- 性能和容量水平扩展。
- 支持时间序列数据的多个独立命名空间(多租户)。
- 支持多副本。
组件服务
前面我们了解了 VM 的基本架构,对于集群模式下主要包含以下几个服务:
vmstorage:存储原始数据并返回指定标签过滤器在给定时间范围内的查询数据,当-storageDataPath指向的目录包含的可用空间少于-storage.minFreeDiskSpaceBytes时,vmstorage节点会自动切换到只读模式,vminsert节点也会停止向此类节点发送数据并开始将数据重新路由到剩余的vmstorage节点。vminsert:接受摄取的数据并根据指标名称及其所有标签的一致性哈希将其分散存储到vmstorage节点。vmselect:通过从所有配置的vmstorage节点获取所需数据来执行查询。
每个服务都可以进行独立扩展,vmstorage 节点之间互不了解、互不通信,并且不共享任何数据。这样可以增加集群的可用性,并且简化了集群的维护和扩展。
最小集群必须包含以下节点:
- 带有
-retentionPeriod(最小数据保留时间)和-storageDataPath参数的单vmstorage节点 - 带有
-storageNode=<vmstorage_host>的单vminsert节点 - 带有
-storageNode=<vmstorage_host>的单vmselect节点
但是我们建议为每个服务组件运行至少两个节点以实现高可用性,这样当单个节点暂时不可用时,集群会继续工作,而且其余节点还可以处理增加的工作负载。如果你的集群规模较大,那么可以运行多个小型的 vmstorage 节点,因为这样可以在某些 vmstorage 节点暂时不可用时减少剩余 vmstorage 节点上的工作负载增加。
各个服务除了可以通过参数标志进行配置之外,也可以通过环境变量的方式进行配置:
-envflag.enable标志必须设置- 每个标志中的
.必须替换为_,例如-insert.maxQueueDuration <duration>可以转换为insert_maxQueueDuration=<duration> - 对于重复的标志,可以使用另一种语法,通过使用
,作为分隔符将不同的值连接成一个,例如-storageNode <nodeA> -storageNode <nodeB>将转换为-storageNode=<nodeA>,<nodeB> - 可以使用
-envflag.prefix为环境变量设置前缀,例如设置了-envflag.prefix=VM*,则环境变量参数必须以VM*开头
多租户
此外 VM 集群也支持多个独立的租户(也叫命名空间),租户由 accountID 或 accountID:projectID 来标识,它们被放在请求的 urls 中。
- 每个
accountID和projectID都由一个 [0 .. 2^32] 范围内的任意 32 位整数标识,如果缺少projectID,则自动将其分配为 0。有关租户的其他信息,例如身份验证令牌、租户名称、限额、计费等,将存储在一个单独的关系型数据库中。此数据库必须由位于 VictoriaMetrics 集群前面的单独服务管理,例如vmauth或vmgateway。 - 当第一个数据点写入指定租户时,租户被自动创建。
- 所有租户的数据均匀分布在可用的
vmstorage节点中,当不同租户有不同的数据量和不同的查询负载时,这保证了vmstorage节点之间的均匀负载。 - 数据库性能和资源使用不依赖于租户的数量,它主要取决于所有租户中活跃时间序列的总数。如果一个时间序列在过去一小时内至少收到一个样本,或者在过去一小时内被查询,则认为时间序列是活跃的。
- VictoriaMetrics 不支持在单个请求中查询多个租户。
集群大小调整和可扩展性
VM 集群的性能和容量可以通过两种方式进行扩展:
- 通过向集群中的现有节点添加更多资源(CPU、RAM、磁盘 IO、磁盘空间、网络带宽),也叫垂直可扩展性。
- 通过向集群添加更多节点,又叫水平扩展性。
对于集群扩展有一些通用的建议:
- 向现有
vmselect节点添加更多 CPU 和内存,可以提高复杂查询的性能,这些查询可以处理大量的时间序列和大量的原始样本。 - 添加更多
vmstorage节点可以增加集群可以处理的活跃时间序列的数量,这也提高了对高流失率(churn rate)的时间序列的查询性能。集群稳定性也会随着vmstorage节点数量的增加而提高,当一些vmstorage节点不可用时,活跃的vmstorage节点需要处理较低的额外工作负载。 - 向现有
vmstorage节点添加更多 CPU 和内存,可以增加集群可以处理的活跃时间序列的数量。与向现有vmstorage节点添加更多 CPU 和内存相比,最好添加更多vmstorage节点,因为更多的vmstorage节点可以提高集群稳定性,并提高对高流失率的时间序列的查询性能。 - 添加更多的
vminsert节点会提高数据摄取的最大速度,因为摄取的数据可以在更多的vminsert节点之间进行拆分。 - 添加更多的
vmselect节点可以提高查询的最大速度,因为传入的并发请求可能会在更多的vmselect节点之间进行拆分。
集群可用性
- HTTP 负载均衡器需要停止将请求路由到不可用的
vminsert和vmselect节点。 - 如果至少存在一个
vmstorage节点,则集群仍然可用:vminsert将传入数据从不可用的vmstorage节点重新路由到健康的vmstorage节点- 如果至少有一个
vmstorage节点可用,则vmselect会继续提供部分响应。如果优先考虑可用性的一致性,则将-search.denyPartialResponse标志传递给vmselect或将请求中的deny_partial_response=1查询参数传递给vmselect。
重复数据删除
如果 -dedup.minScrapeInterval 命令行标志设置为大于 0 的时间,VictoriaMetrics 会去除重复数据点。例如,-dedup.minScrapeInterval=60s 将对同一时间序列上的数据点进行重复数据删除,如果它们位于同一离散的 60 秒存储桶内,最早的数据点将被保留。在时间戳相等的情况下,将保留任意数据点。
-dedup.minScrapeInterval 的推荐值是等于 Prometheus 配置中的 scrape_interval 的值,建议在所有抓取目标中使用一个 scrape_interval 配置。
如果 HA 中多个相同配置的 vmagent 或 Prometheus 实例将数据写入同一个 VictoriaMetrics 实例,则重复数据删除会减少磁盘空间使用。这些 vmagent 或 Prometheus 实例在其配置中必须具有相同的 external_labels 部分,因此它们将数据写入相同的时间序列。
容量规划
根据我们的案例研究,与竞争解决方案(Prometheus、Thanos、Cortex、TimescaleDB、InfluxDB、QuestDB、M3DB)相比,VictoriaMetrics 在生产工作负载上使用的 CPU、内存和存储空间更少。
每种节点类型 - vminsert、vmselect 和 vmstorage 都可以在最合适的硬件上运行。集群容量随着可用资源的增加而线性扩展。每个节点类型所需的 CPU 和内存数量很大程度上取决于工作负载 - 活跃时间序列的数量、序列流失率、查询类型、查询 qps 等。建议为你的生产工作负载部署一个测试的 VictoriaMetrics 集群,并反复调整每个节点的资源和每个节点类型的节点数量,直到集群变得稳定。同样也建议为集群设置监控,有助于确定集群设置中的瓶颈问题。
指定保留所需的存储空间(可以通过 vmstorage 中的 -retentionPeriod 命令行标志设置)可以从测试运行中的磁盘空间使用情况推断出来。例如,如果在生产工作负载上运行一天后的存储空间使用量为 10GB,那么对于 -retentionPeriod=100d(100 天保留期)来说,它至少需要 10GB*100=1TB 的磁盘空间。可以使用 VictoriaMetrics 集群的官方 Grafana 仪表板监控存储空间使用情况。
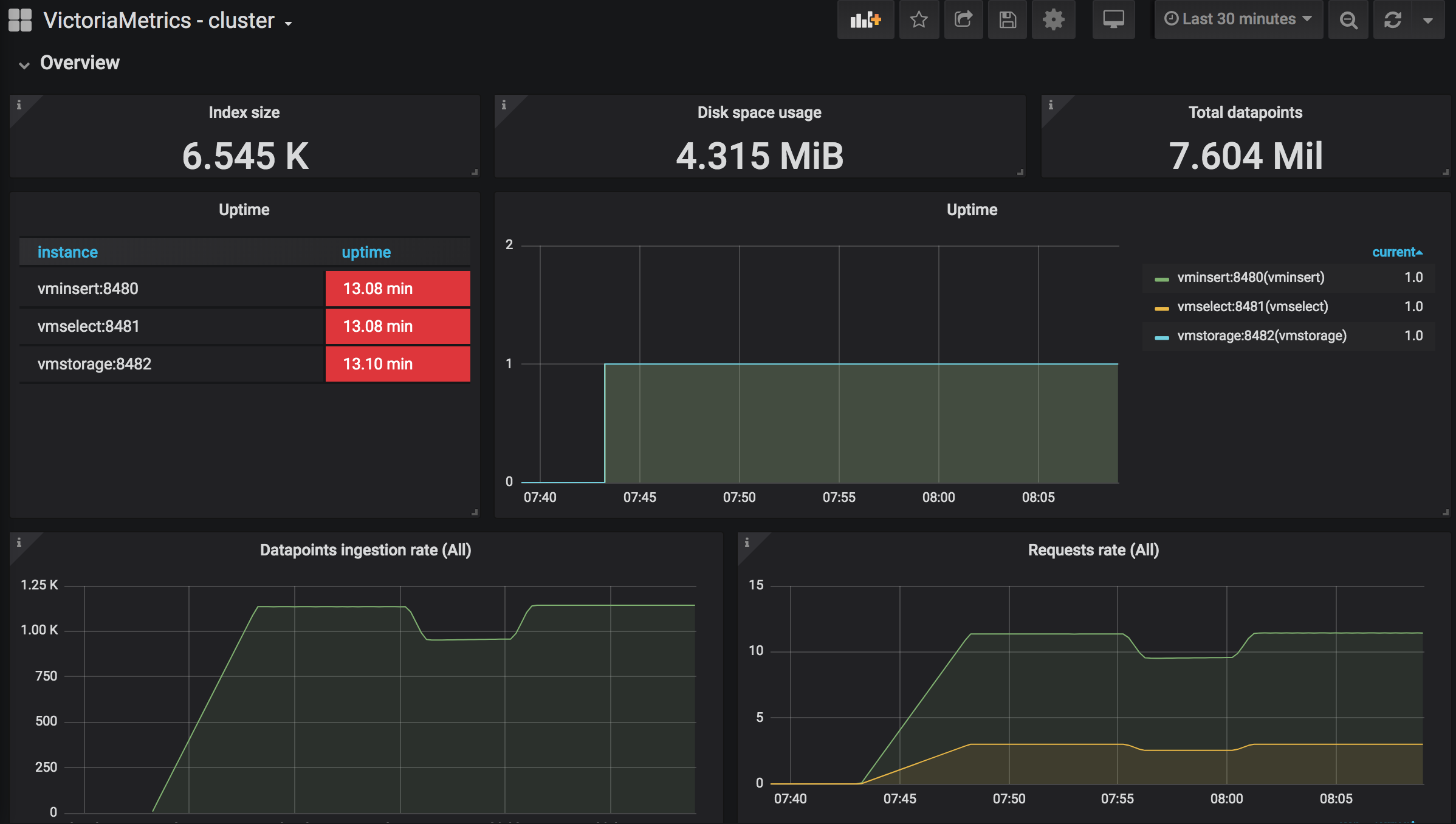
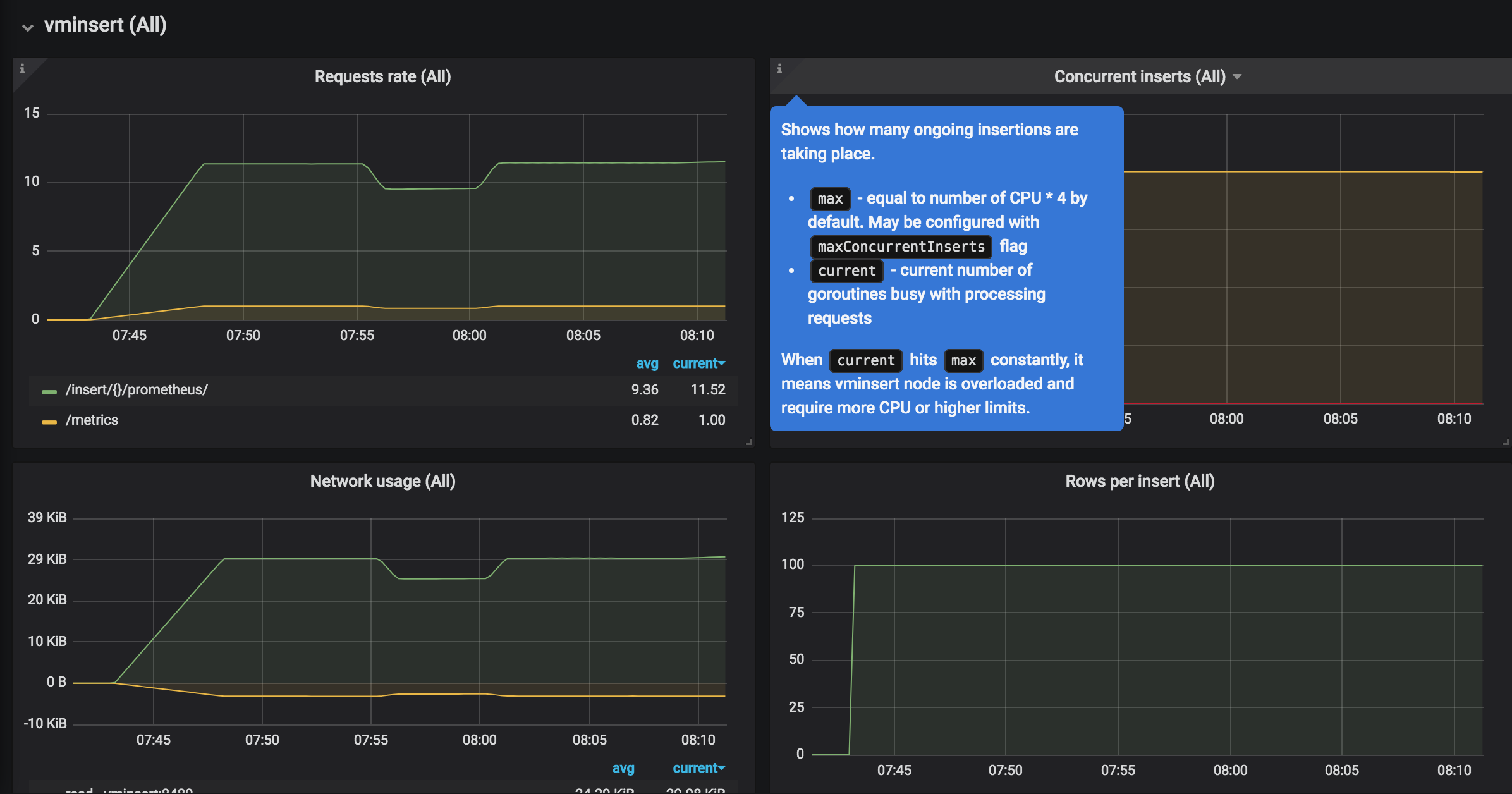
建议留出以下数量的备用资源。
- 所有节点类型中 50% 的空闲内存,以减少工作负载临时激增时因为 OOM 崩溃的可能性。
- 所有节点类型中 50% 的空闲 CPU,以减少工作负载临时高峰期间的慢速概率。
vmstorage节点上-storageDataPath命令行标志指向的目录中至少有 30% 的可用存储空间。
VictoriaMetrics 集群的一些容量规划技巧:
- 副本集将集群所需的资源量最多增加 N 倍,其中 N 是复制因子。
- 可以通过添加更多
vmstorage节点和/或通过增加每个vmstorage节点的内存和 CPU 资源来增加活跃时间序列的集群容量。 - 可以通过增加
vmstorage节点的数量和/或通过增加每个vmselect节点的内存和 CPU 资源来减少查询延迟。 - 所有
vminsert节点所需的 CPU 内核总数可以通过摄取率计算:CPUs = ingestion_rate / 100K。 vminsert节点上的-rpc.disableCompression命令行标志可以增加摄取容量,但代价是vminsert和vmstorage之间的网络带宽使用率会更高。
复制和数据安全
默认情况下,VictoriaMetrics 的数据复制依赖 -storageDataPath 指向的底层存储来完成。
但是我们也可以手动通过将 -replicationFactor=N 命令参数传递给 vminsert 来启用复制,这保证了如果多达 N-1 个 vmstorage 节点不可用,所有数据仍可用于查询。集群必须至少包含 2*N-1 个 vmstorage 节点,其中 N 是复制因子,以便在 N-1 个存储节点丢失时为新摄取的数据维持指定的复制因子。
例如,当 -replicationFactor=3 传递给 vminsert 时,它将所有摄取的数据复制到 3 个不同的 vmstorage 节点,因此最多可以丢失 2 个 vmstorage 节点而不会丢失数据。vmstorage 节点的最小数量应该等于 2*3-1 = 5,因此当 2 个 vmstorage 节点丢失时,剩余的 3 个 vmstorage 节点可以为新摄取的数据提供服务。
启用复制后,必须将 -dedup.minScrapeInterval=1ms 命令行标志传递给 vmselect 节点,当多达 N-1 个 vmstorage 节点响应缓慢和/或暂时不可用时,可以将可选的 -replicationFactor=N 参数传递给 vmselect 以提高查询性能,因为 vmselect 不等待来自多达 N-1 个 vmstorage 节点的响应。有时,vmselect 节点上的 -replicationFactor 可能会导致部分响应。-dedup.minScrapeInterval=1ms 在查询期间对复制的数据进行重复数据删除,如果重复数据从配置相同的 vmagent 实例或 Prometheus 实例推送到 VictoriaMetrics,则必须根据重复数据删除文档将 -dedup.minScrapeInterval 设置为更大的值。 请注意,复制不会从灾难中保存,因此建议执行定期备份。另外 复制会增加资源使用率 - CPU、内存、磁盘空间、网络带宽 - 最多 -replicationFactor 倍。所以可以将复制转移 -storageDataPath 指向的底层存储来做保证,例如 Google Compute Engine 永久磁盘,该磁盘可以防止数据丢失和数据损坏,它还提供始终如一的高性能,并且可以在不停机的情况下调整大小。对于大多数用例来说,基于 HDD 的永久性磁盘应该足够了。
备份
建议从即时快照执行定期备份,以防止意外数据删除等错误。必须为每个 vmstorage 节点执行以下步骤来创建备份:
通过导航到/snapshot/create HTTP handler 来创建一个即时快照。它将创建快照并返回其名称。
- 可以通过访问
/snapshot/create这个 HTTP handler 来创建即时快照,它将创建快照并返回其名称。 - 使用
vmbackup组件从<-storageDataPath>/snapshots/<snapshot_name>文件夹归档创建的快照。归档过程不会干扰vmstorage工作,因此可以在任何合适的时间执行。 - 通过
/snapshot/delete?snapshot=<snapshot_name>或/snapshot/delete_all删除未使用的快照,以释放占用的存储空间。 - 无需在所有
vmstorage节点之间同步备份。
从备份恢复:
- 使用
kill -INT停止vmstorage节点。 - 使用
vmrestore组件将备份中的数据还原到-storageDataPath目录。 - 启动
vmstorage节点。
在了解了 VM 集群的一些配置细节后,接下来我们就来开始部署 VM 集群。
部署
💘 实战:VictoriaMetrics集群版部署(测试成功)-2022.8.13
如果你已经对 VM 组件非常了解了,那么推荐使用 Helm Chart 的方式进行一键安装。
☸ ➜ helm repo add vm https://victoriametrics.github.io/helm-charts/
☸ ➜ helm repo update
# 导出默认的 values 值到 values.yaml 文件中
☸ ➜ helm show values vm/victoria-metrics-cluster > values.yaml
# 根据自己的需求修改 values.yaml 文件配置
# 执行下面的命令进行一键安装
☸ ➜ helm install victoria-metrics vm/victoria-metrics-cluster -f values.yaml -n NAMESPACE
# 获取 vm 运行的 pods 列表
☸ ➜ kubectl get pods -A | grep 'victoria-metrics'我们这里选择手动方式进行部署,之所以选择手动部署的方式是为了能够了解各个组件的更多细节。
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5实验软件
链接:https://pan.baidu.com/s/1iqnWMtrZT-Z5KEU9kq14OA?pwd=b3wd
提取码:b3wd
2022.8.13-VictoriaMetrics之集群版-code
前置条件
- 注意呀:这里要把之前的单节点版vm集群给停掉!
- 提前部署好prometheus和grafna;
- 自己本次实验是在上次实验基础上测试的;
1、部署vmstorage 组件
由于 vmstorage 组件是有状态的,这里我们先使用 StatefulSet 进行部署,由于该组件也是可以进行扩展的,这里我们首先部署两个副本,对应的资源清单如下所示:
vim cluster-vmstorage.yaml
# cluster-vmstorage.yaml
apiVersion: v1
kind: Service
metadata:
name: cluster-vmstorage
namespace: kube-vm
labels:
app: vmstorage
spec:
clusterIP: None #因为你是一个Statefulset,所以要用一个headless无头服务来着的
ports:
- port: 8482
targetPort: http
name: http
- port: 8401
targetPort: vmselect
name: vmselect
- port: 8400
targetPort: vminsert
name: vminsert
selector:
app: vmstorage
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: vmstorage
namespace: kube-vm
labels:
app: vmstorage
spec:
serviceName: cluster-vmstorage
selector:
matchLabels:
app: vmstorage
replicas: 2
podManagementPolicy: OrderedReady #这个是什么??
template:
metadata:
labels:
app: vmstorage
spec:
containers:
- name: vmstorage
image: "victoriametrics/vmstorage:v1.77.0-cluster"
imagePullPolicy: "IfNotPresent"
args:
- "--retentionPeriod=1" #默认也是1个月
- "--storageDataPath=/storage"
- --envflag.enable=true
- --envflag.prefix=VM_
- --loggerFormat=json
ports:
- name: http #storage暴露的api接口
containerPort: 8482
- name: vminsert
containerPort: 8400
- name: vmselect
containerPort: 8401
livenessProbe:
failureThreshold: 10
initialDelaySeconds: 30
periodSeconds: 30
tcpSocket:
port: http
timeoutSeconds: 5
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
httpGet:
path: /health
port: http
volumeMounts:
- name: storage
mountPath: /storage
volumeClaimTemplates: #因为你是一个无状态,所以这里要使用volumeClaimTemplates
- metadata:
name: storage
spec:
storageClassName: longhorn #裂了,那我的k8s环境还要再部署一遍longhorn环境喽…… 后面自己已经部署好了longhorn环境了
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"首先需要创建一个 Headless 的 Service,因为后面的组件需要访问到每一个具体的 Pod,在 vmstorage 启动参数中通过 --retentionPeriod 参数指定指标数据保留时长,1 表示一个月,这也是默认的时长,然后通过 --storageDataPath 参数指定了数据存储路径,记得要将该目录进行持久化。
- 这里使用nfs存储类也是可以的哈:
或者,当然你用OpenDBs去做一个LocalPV的自动创建也是可以的哈。😢
- 同样直接应用该资源即可:
#[root@master1 vm-cluster]#kubectl apply -f cluster-vmstorage.yaml
service/cluster-vmstorage created
statefulset.apps/vmstorage created
[root@master1 vm-cluster]#kubectl get pods -n kube-vm -l app=vmstorage -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vmstorage-0 1/1 Running 0 6m7s 10.244.2.70 node2 <none> <none>
vmstorage-1 1/1 Running 0 2m22s 10.244.2.71 node2 <none> <none>
[root@master1 vm-cluster]#kubectl get svc -n kube-vm -l app=vmstorage
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cluster-vmstorage ClusterIP None <none> 8482/TCP,8401/TCP,8400/TCP 10m2、部署vmselect 组件
接着可以部署 vmselect 组件,由于该组件是无状态的,我们可以直接使用 Deployment 来进行管理,对应的资源清单文件如下所示:
[root@master1 vm-cluster]#vim cluster-vmselect.yaml
# cluster-vmselect.yaml
apiVersion: v1
kind: Service
metadata:
name: vmselect
namespace: kube-vm
labels:
app: vmselect
spec:
ports:
- name: http
port: 8481
targetPort: http
selector:
app: vmselect
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vmselect
namespace: kube-vm
labels:
app: vmselect
spec:
selector:
matchLabels:
app: vmselect
template:
metadata:
labels:
app: vmselect
spec:
containers:
- name: vmselect
image: "victoriametrics/vmselect:v1.77.0-cluster"
imagePullPolicy: "IfNotPresent"
args:
- "--cacheDataPath=/cache"
- --storageNode=vmstorage-0.cluster-vmstorage.kube-vm.svc.cluster.local:8401
- --storageNode=vmstorage-1.cluster-vmstorage.kube-vm.svc.cluster.local:8401
- --envflag.enable=true
- --envflag.prefix=VM_
- --loggerFormat=json
ports:
- name: http
containerPort: 8481
readinessProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
livenessProbe:
tcpSocket:
port: http
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}其中最重要的部分是通过 --storageNode 参数指定所有的 vmstorage 节点地址,上面我们使用的 StatefulSet 部署的,所以可以直接使用 FQDN 的形式进行访问。直
- 接着应用上面的对象:
[root@master1 vm-cluster]#kubectl apply -f cluster-vmselect.yaml
service/vmselect created
deployment.apps/vmselect created
[root@master1 vm-cluster]#kubectl get pods -n kube-vm -l app=vmselect -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vmselect-bcb54965f-kq49c 1/1 Running 0 2m51s 10.244.1.181 node1 <none> <none>
[root@master1 vm-cluster]#kubectl get svc -n kube-vm -l app=vmselect
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vmselect ClusterIP 10.100.142.147 <none> 8481/TCP 3m8s3、部署vminsert 组件
接着就需要部署用来接收指标数据插入的 vminsert 组件,同样该组件是无状态的,其中最重要的也是需要通过 --storageNode 参数指定所有的 vmstorage 节点:
[root@master1 vm-cluster]#vim cluster-vminsert.yaml
# cluster-vminsert.yaml
apiVersion: v1
kind: Service
metadata:
name: vminsert
namespace: kube-vm
labels:
app: vminsert
spec:
ports:
- name: http
port: 8480
targetPort: http
selector:
app: vminsert
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vminsert
namespace: kube-vm
labels:
app: vminsert
spec:
selector:
matchLabels:
app: vminsert
template:
metadata:
labels:
app: vminsert
spec:
containers:
- name: vminsert
image: "victoriametrics/vminsert:v1.77.0-cluster"
imagePullPolicy: "IfNotPresent"
args:
- --storageNode=vmstorage-0.cluster-vmstorage.kube-vm.svc.cluster.local:8400
- --storageNode=vmstorage-1.cluster-vmstorage.kube-vm.svc.cluster.local:8400
- --envflag.enable=true
- --envflag.prefix=VM_
- --loggerFormat=json
ports:
- name: http
containerPort: 8480
readinessProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
livenessProbe:
tcpSocket:
port: http
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3由于本身是无状态的,所以可以根据需要增加副本数量,也可以配置 HPA 进行自动扩缩容。
- 直接应用上面的资源清单:
[root@master1 vm-cluster]#kubectl apply -f cluster-vminsert.yaml
service/vminsert created
deployment.apps/vminsert created
[root@master1 vm-cluster]#kubectl get pods -n kube-vm -l app=vminsert
NAME READY STATUS RESTARTS AGE
vminsert-66c88cd497-6wg2l 1/1 Running 0 10m
[root@master1 vm-cluster]#kubectl get svc -n kube-vm -l app=vminsert
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vminsert ClusterIP 10.98.142.18 <none> 8480/TCP 11m4、配置Prometheus的remote_write
集群模式的相关组件部署完成后。
我们看下当前k8s环境,因为上次实验我们已经用vm单节点替代了prometheus了:
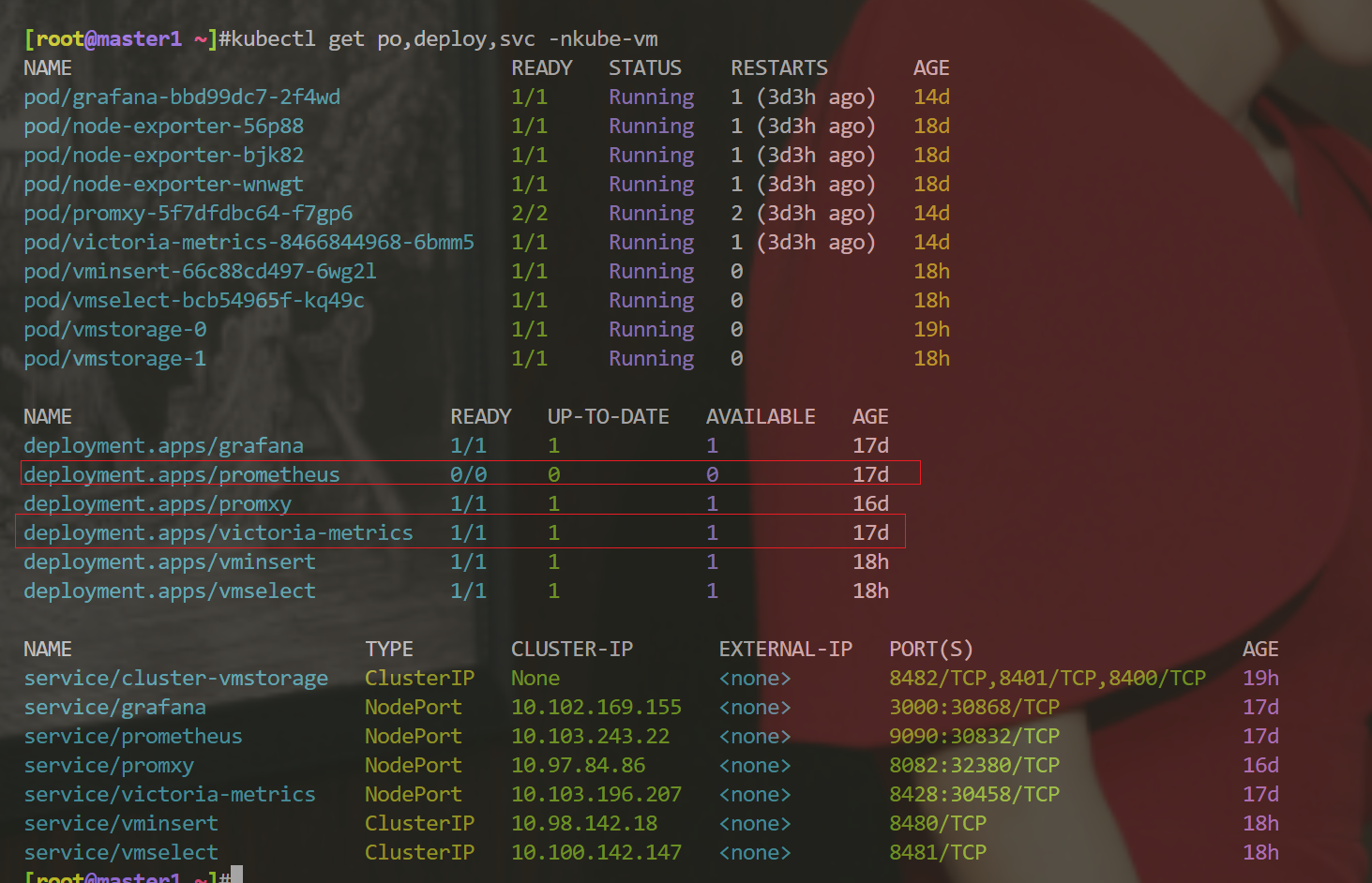
- 先停掉vm单节点,将prometheus实例恢复过来
[root@master1 vm]#kubectl scale deploy victoria-metrics --replicas=0 -n kube-vm
deployment.apps/victoria-metrics scaled
[root@master1 vm]#kubectl scale deploy prometheus --replicas=1 -n kube-vm
deployment.apps/prometheus scaled- 同样我们可以先去配置前面的 Prometheus,将其数据远程写入到 VM 中来,修改
remote_write的地址为http://vminsert:8480/insert/0/prometheus/,注意和单节点模式的 API 路径不一样,如下所示:
[root@master1 vm]#vim vm-prom-config3.yaml
# vm-prom-config3.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-vm
data:
prometheus.yaml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
remote_write: # 写入到远程 VM 存储,url 是远程写入接口地址
- url: http://vminsert:8480/insert/0/prometheus/
# queue_config: # 如果 Prometheus 抓取指标很大,可以加调整 queue,但是会提高内存占用
# max_samples_per_send: 10000 # 每次发送的最大样本数
# capacity: 20000
# max_shards: 30 # 最大分片数,即并发量。
scrape_configs:
- job_name: "nodes"
static_configs:
- targets: ['172.29.9.51:9111', '172.29.9.52:9111', '172.29.9.53:9111']
relabel_configs: # 通过 relabeling 从 __address__ 中提取 IP 信息,为了后面验证 VM 是否兼容 relabeling
- source_labels: [__address__]
regex: "(.*):(.*)"
replacement: "${1}"
target_label: 'ip'
action: replace- 更新 Prometheus 配置
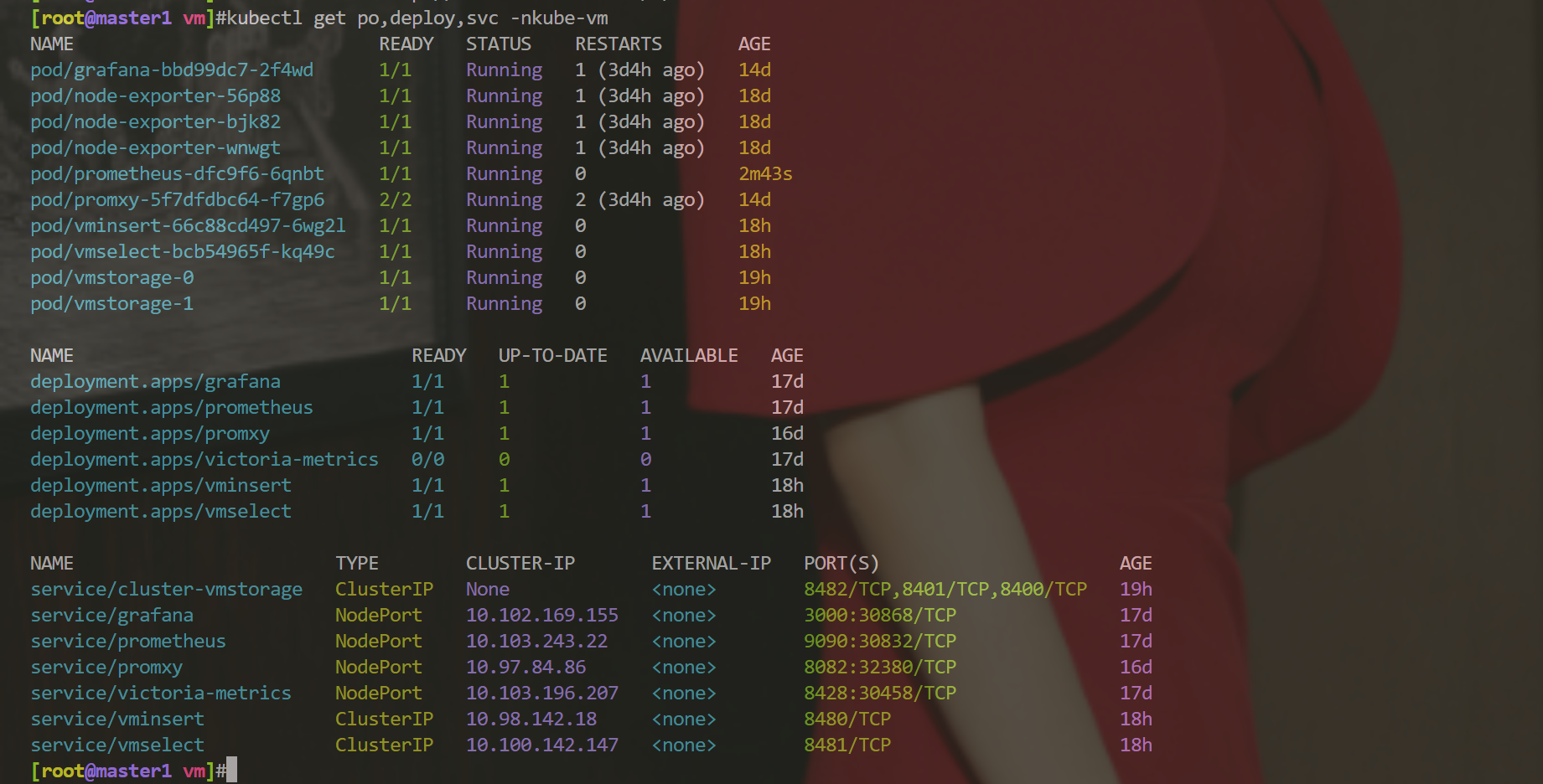
[root@master1 vm]#kubectl apply -f vm-prom-config3.yaml
configmap/prometheus-config configured
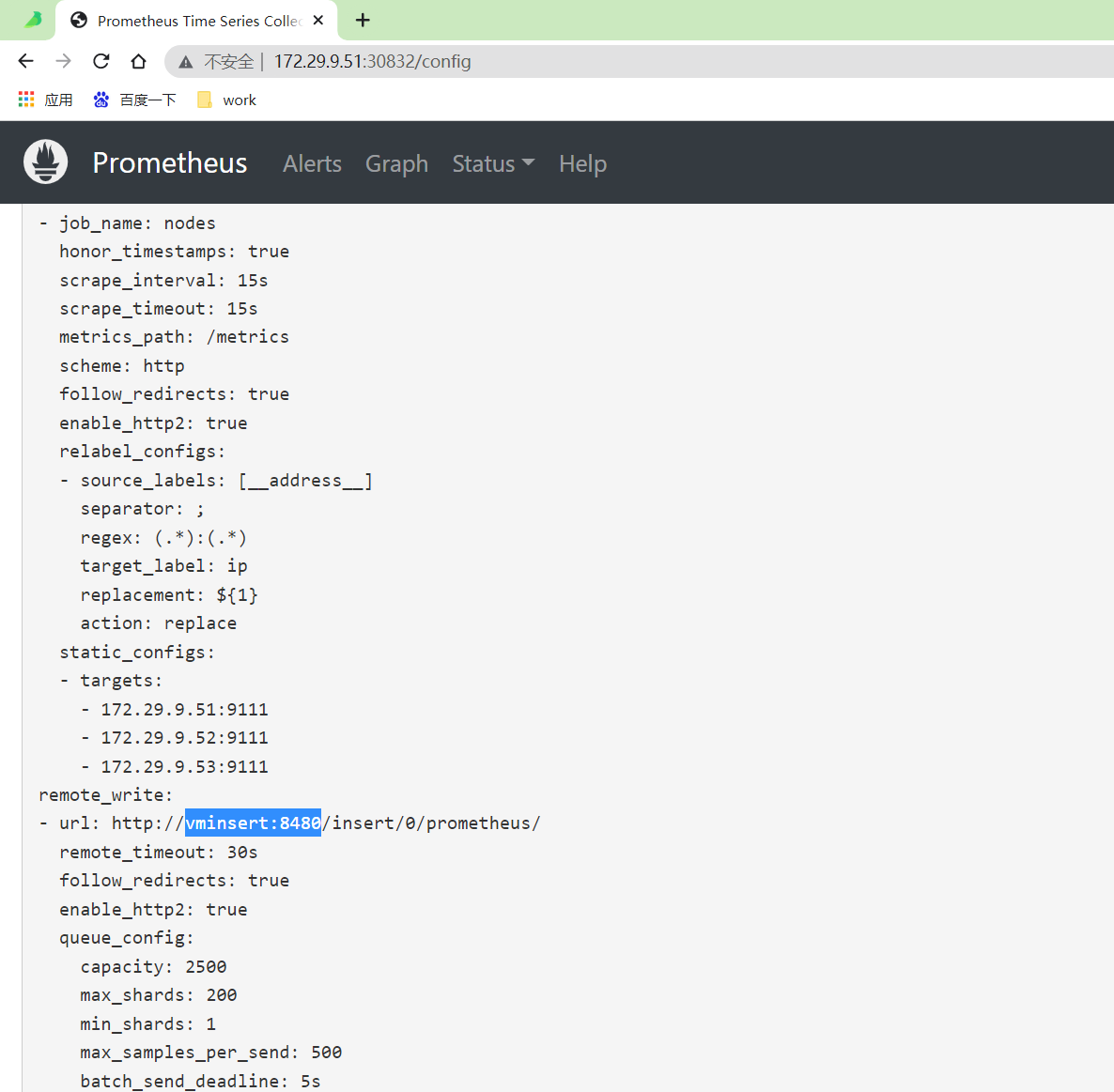
[root@master1 vm]#curl -X POST "http://172.29.9.51:30832/-/reload" #执行下curl操作观察效果:
此时,来到prometheus,看下其配置文件是否有更改过来?
- 再来到grafana,配置下数据源,如果要进行查询,那么我们可以直接对外暴露 vmselect 这个 Service 服务即可,修改 Grafana 数据源地址为
http://<select-service>/select/0/prometheus/。
http://vmselect:8481/select/0/prometheus/
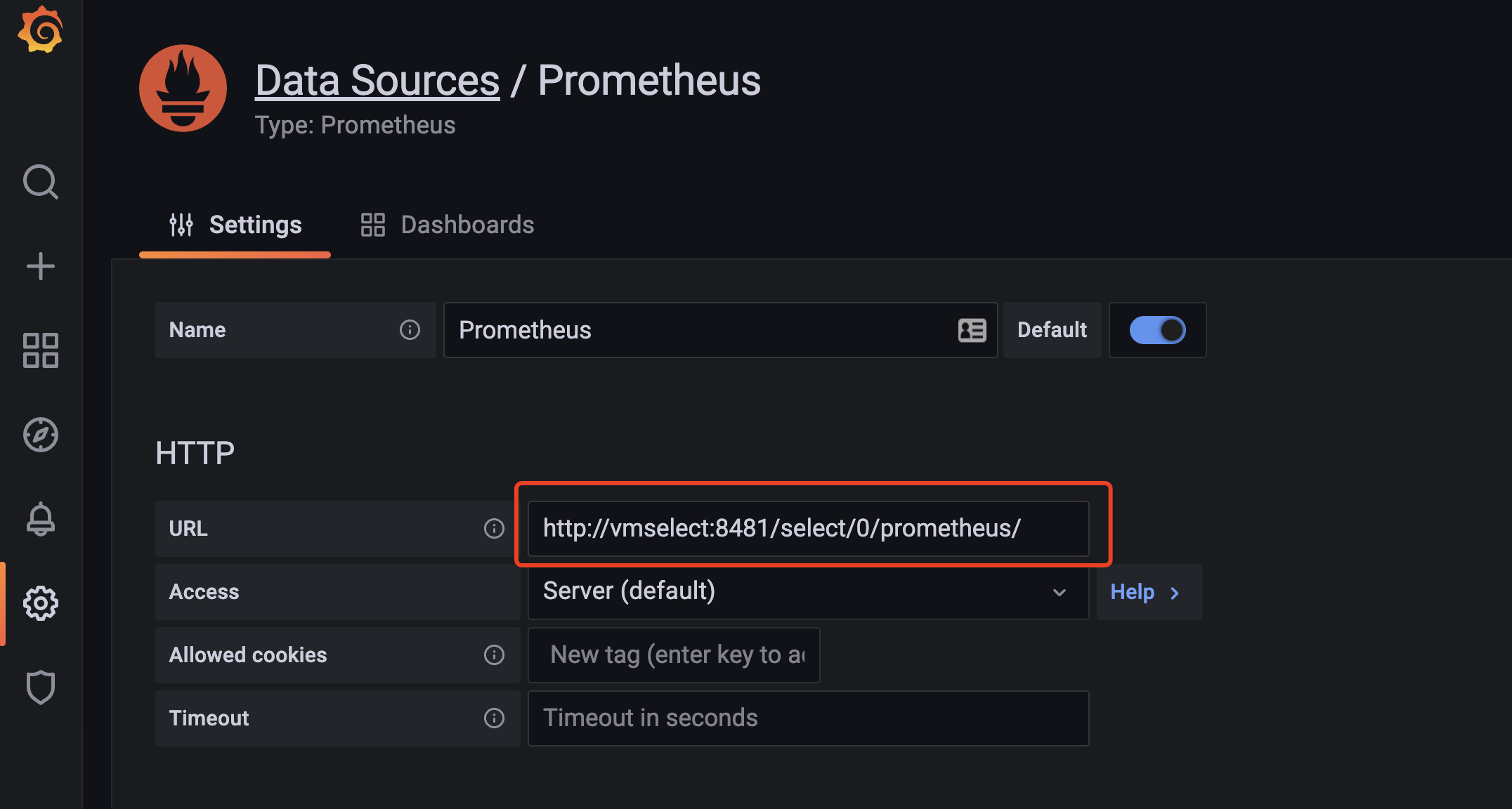
5、验证
- 配置成功后正常数据就可以开始写入到 vmstorage 了,查看 vmstorage 日志可以看到成功创建了 partition,证明现在已经在开始接收数据了:
☸ ➜ kubectl logs -f vmstorage-0 -n kube-vm
......
{"ts":"2022-05-06T08:35:15.786Z","level":"info","caller":"VictoriaMetrics/lib/storage/partition.go:206","msg":"creating a partition \"2022_05\" with smallPartsPath=\"/storage/data/small/2022_05\", bigPartsPath=\"/storage/data/big/2022_05\""}
{"ts":"2022-05-06T08:35:15.802Z","level":"info","caller":"VictoriaMetrics/lib/storage/partition.go:222","msg":"partition \"2022_05\" has been created"}- 然后可以去 Grafana 重新查看 Dashboard 是否正常:
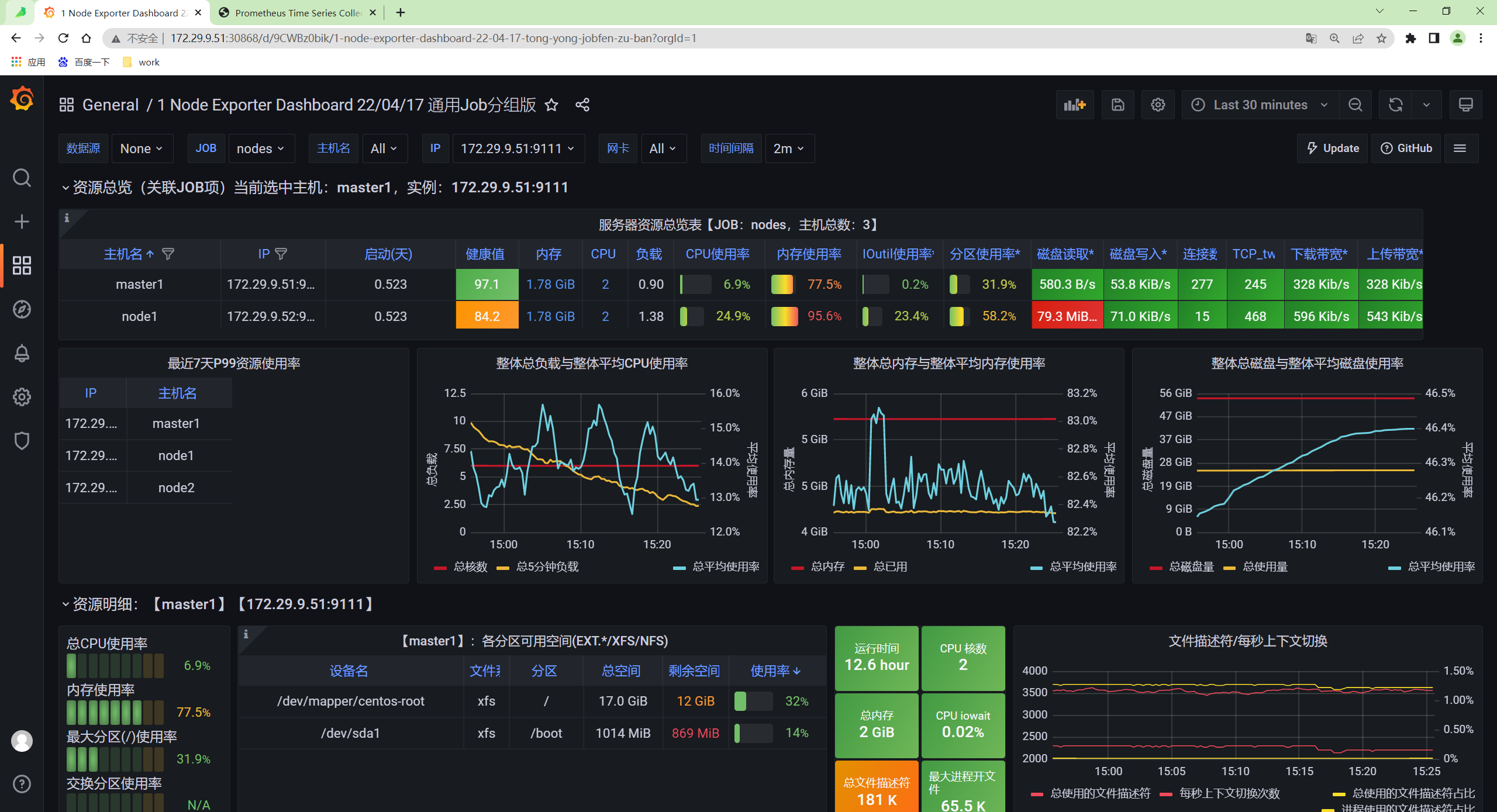
测试结束。😘
6、新增 vmstorage 节点的方法
如果现在需要新增 vmstorage 节点,那么需要按照下面的步骤进行操作:
- 使用与集群中现有节点相同的
-retentionPeriod配置启动新的vmstorage节点。 - 逐步重新启动所有的
vmselect节点,添加新的-storageNode参数包含<new_vmstorage_host>。 - 逐步重新启动所有的
vminsert节点,添加新的-storageNode参数包含<new_vmstorage_host>。
注意事项
🍀 又是老问题了:
grafna那里配置数据源,一直有问题……
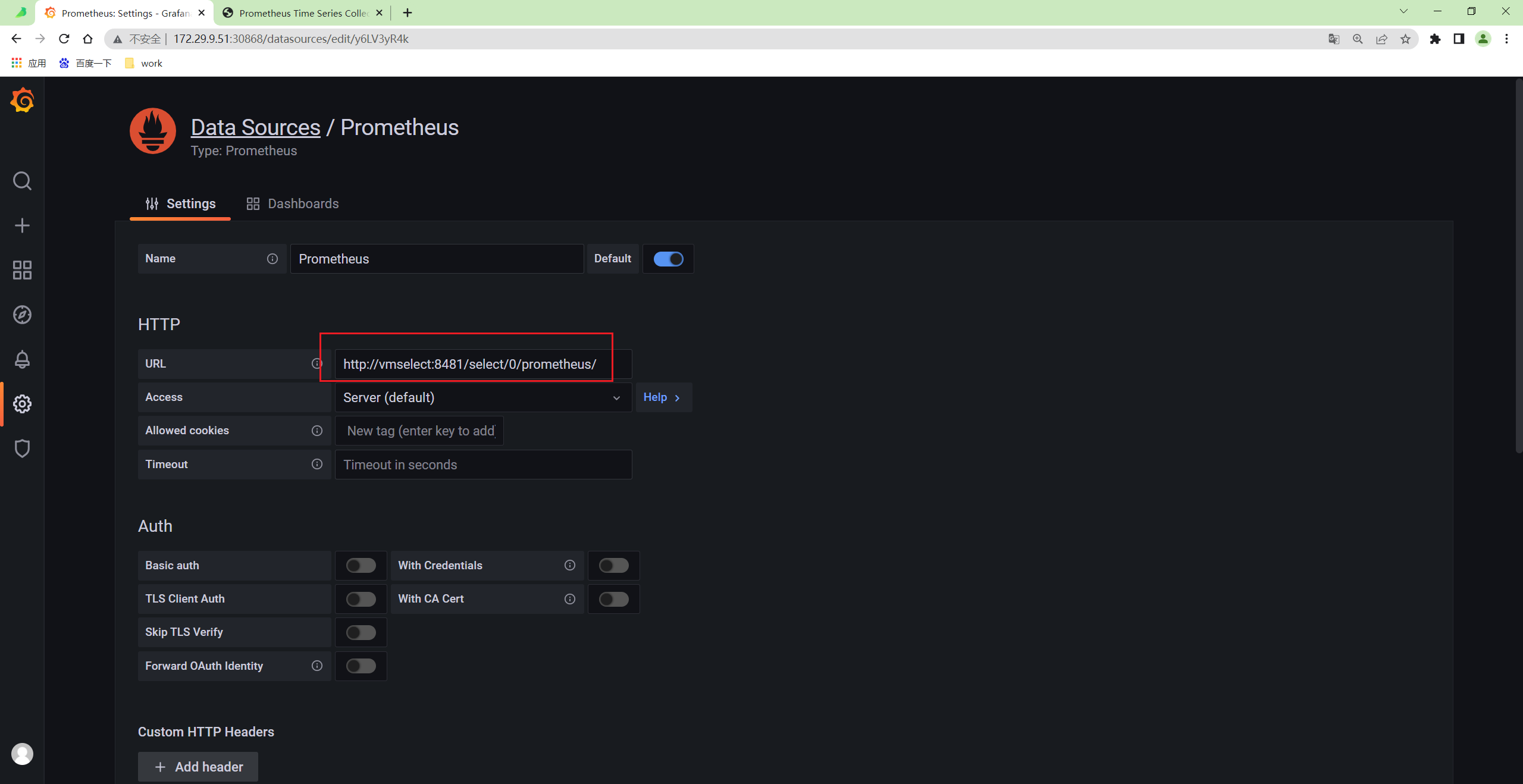
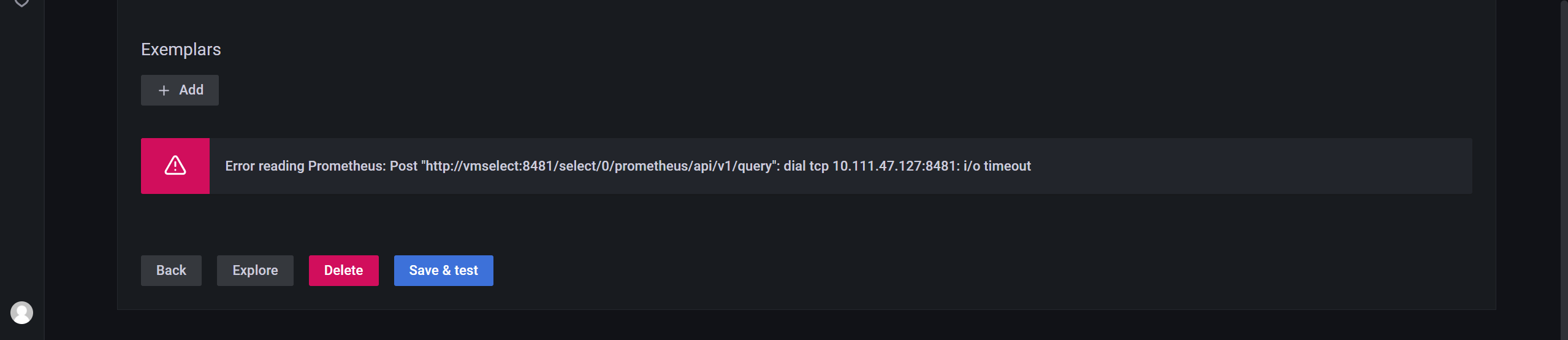
因此:我把这个vmselect用NodePort类型的服务暴露出去,再使用nodeIP:nodePort来访问就可以了……
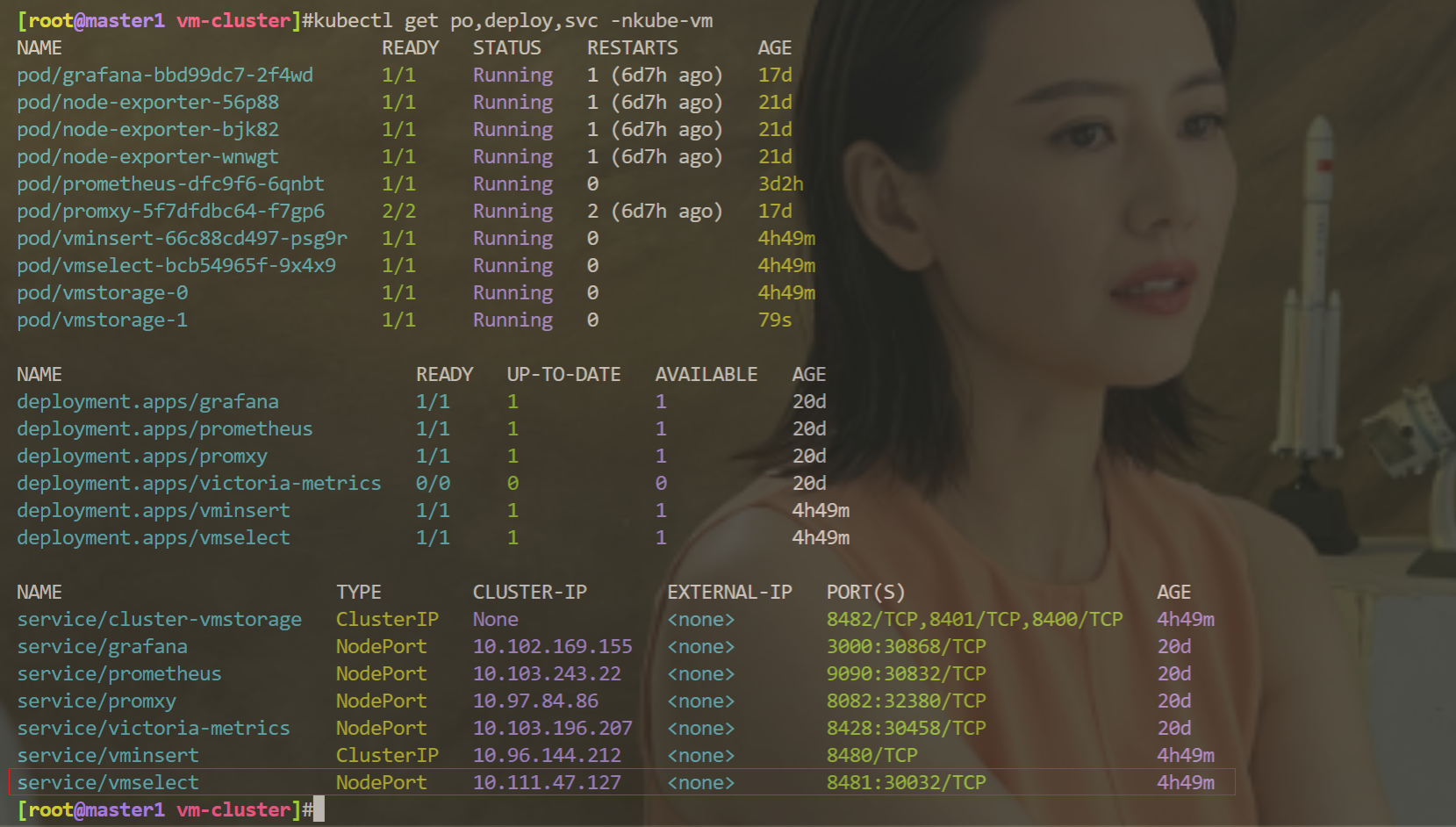
使用nodeIP:nodePort来访问:
此时,grafna上就可以正常访问了:
3、vmagent
1.vmagent
vmagent --就是帮我们去抓取指标的。
vmagent 可以帮助我们从各种来源收集指标并将它们存储到 VM 或者任何其他支持 remote write 协议的 Prometheus 兼容的存储系统中。vmagent 相比于 Prometheus 抓取指标来说具有更多的灵活性,比如除了拉取(pull)指标还可以推送(push)指标,此外还有很多其他特性:
- 可以替换 prometheus 的 scraping target
- 支持从 Kafka 读写数据
- 支持基于 prometheus relabeling 的模式添加、移除、修改 labels,可以在数据发送到远端存储之前进行数据的过滤
- 支持多种数据协议,influx line 协议,graphite 文本协议,opentsdb 协议,prometheus remote write 协议,json lines 协议,csv 数据等
- 支持收集数据的同时,并复制到多种远端存储系统
- 支持不可靠远端存储,如果远程存储不可用,收集的指标会在
-remoteWrite.tmpDataPath缓冲,一旦与远程存储的连接被修复,缓冲的指标就会被发送到远程存储,缓冲区的最大磁盘用量可以用-remoteWrite.maxDiskUsagePerURL来限制。 - 相比 prometheus 使用更少的内存、cpu、磁盘 io 以及网络带宽
- 当需要抓取大量目标时,抓取目标可以分散到多个 vmagent 实例中
- 可以通过在抓取时间和将其发送到远程存储系统之前限制唯一时间序列的数量来处理高基数和高流失率问题
- 可以从多个文件中加载 scrape 配置
接下来我们以抓取 Kubernetes 集群指标为例说明如何使用 vmagent,我们这里使用自动发现的方式来进行配置。vmagent 是兼容 prometheus 中的 kubernetes_sd_configs 配置的,所以我们同样可以使用。
2.部署
💘 实战:vmagent部署(测试成功)-2022.8.14

实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5实验软件
链接:https://pan.baidu.com/s/1NraH13Omsc5xEDXcLagMCw?pwd=bcwc
提取码:bcwc
2022.8.14-VictoriaMetrics之vmagent-code
1、配置 rbac 权限
要让 vmagent 自动发现监控的资源对象,需要访问 APIServer 获取资源对象,所以首先需要配置 rbac 权限,创建如下所示的资源清单。
vim vmagent-rbac.yaml
# vmagent-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: vmagent
namespace: kube-vm
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: vmagent
rules:
- apiGroups: ["", "networking.k8s.io", "extensions"]
resources:
- nodes
- nodes/metrics
- services
- endpoints
- endpointslices
- pods
- app
- ingresses
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- namespaces
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics", "/metrics/resources"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: vmagent
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: vmagent
subjects:
- kind: ServiceAccount
name: vmagent
namespace: kube-vm部署:
[root@master1 vm-agent]#kubectl apply -f vmagent-rbac.yaml
serviceaccount/vmagent created
clusterrole.rbac.authorization.k8s.io/vmagent created
clusterrolebinding.rbac.authorization.k8s.io/vmagent creat2、添加 vmagent 配置
- 然后添加 vmagent 配置,我们先只配置自动发现 Kubernetes 节点的任务,创建如下所示的 ConfigMap 对象:
vim vmagent-config.yaml
# vmagent-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vmagent-config
namespace: kube-vm
data:
scrape.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: "(.*):10250"
replacement: "${1}:9111"
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)这里我们通过自动发现 Kubernetes 节点获取节点监控指标,需要注意 node 这种 role 的自动发现默认获取的是节点的 10250 端口,这里我们需要通过 relabel 将其 replace 为 9111。
部署:
[root@master1 vm-agent]#kubectl apply -f vmagent-config.yaml
configmap/vmagent-config created注意:
如果是单个vmagent实例,用deployment也是可以的,本次使用后面的StatefuleSet来部署(多个vmagent实例)。
然后添加 vmagent 部署资源清单,如下所示:
# vmagent-deploy.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vmagent-pvc
namespace: kube-vm
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs-client
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vmagent
namespace: kube-vm
labels:
app: vmagent
spec:
selector:
matchLabels:
app: vmagent
template:
metadata:
labels:
app: vmagent
spec:
serviceAccountName: vmagent
containers:
- name: agent
image: "victoriametrics/vmagent:v1.77.0"
imagePullPolicy: IfNotPresent
args:
- -promscrape.config=/config/scrape.yml
- -remoteWrite.tmpDataPath=/tmpData
- -remoteWrite.url=http://vminsert:8480/insert/0/prometheus
- -envflag.enable=true
- -envflag.prefix=VM_
- -loggerFormat=json
ports:
- name: http
containerPort: 8429
volumeMounts:
- name: tmpdata
mountPath: /tmpData
- name: config
mountPath: /config
volumes:
- name: tmpdata
persistentVolumeClaim:
claimName: vmagent-pvc
- name: config
configMap:
name: vmagent-config我们将 vmagent 配置通过 ConfigMap 挂载到容器 /config/scrape.yml,另外通过 -remoteWrite.url=http://vminsert:8480/insert/0/prometheus 指定远程写入的地址,这里我们写入前面的 vminsert 服务,另外有一个参数 -remoteWrite.tmpDataPath,该路径会在远程存储不可用的时候用来缓存收集的指标,当远程存储修复后,缓存的指标就会被正常发送到远程写入,所以最好持久化该目录。
👉 注意
单个 vmagent 实例可以抓取数万个抓取目标,但是有时由于 CPU、网络、内存等方面的限制,这还不够。在这种情况下,抓取目标可以在多个 vmagent 实例之间进行拆分。集群中的每个 vmagent 实例必须使用具有不同 -promscrape.cluster.memberNum 值的相同 -promscrape.config 配置文件,该参数值必须在 0 ... N-1 范围内,其中 N 是集群中 vmagent 实例的数量。集群中 vmagent 实例的数量必须传递给 -promscrape.cluster.membersCount 命令行标志。例如,以下命令可以在两个 vmagent 实例的集群中传播抓取目标:
vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/config.yml ...
vmagent -promscrape.cluster.membersCount=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/config.yml ...当 vmagent 在 Kubernetes 中运行时,可以将 -promscrape.cluster.memberNum 设置为 StatefulSet pod 名称,pod 名称必须以 0 ... promscrape.cluster.memberNum-1 范围内的数字结尾,例如,-promscrape.cluster.memberNum=vmagent-0。
默认情况下,每个抓取目标仅由集群中的单个 vmagent 实例抓取。如果需要在多个 vmagent 实例之间复制抓取目标,则可以通过 -promscrape.cluster.replicationFactor 参数设置为所需的副本数。例如,以下命令启动一个包含三个 vmagent 实例的集群,其中每个目标由两个 vmagent 实例抓取:
vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=0 -promscrape.config=/path/to/config.yml ...
vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=1 -promscrape.config=/path/to/config.yml ...
vmagent -promscrape.cluster.membersCount=3 -promscrape.cluster.replicationFactor=2 -promscrape.cluster.memberNum=2 -promscrape.config=/path/to/config.yml ...需要注意的是如果每个目标被多个 vmagent 实例抓取,则必须在 -remoteWrite.url 指向的远程存储上启用重复数据删除。
所以如果你抓取的监控目标非常大,那么我们建议使用 vmagent 集群模式。
3、使用 StatefulSet 方式进行部署
那么可以使用 StatefulSet 方式进行部署vmagent 集群模式:
vim vmagent-sts.yaml
# vmagent-sts.yaml
apiVersion: v1
kind: Service
metadata:
name: vmagent
namespace: kube-vm
annotations:
prometheus.io/scrape: "true" #这个是为了采集vmagent本身
prometheus.io/port: "8429"
spec:
selector:
app: vmagent
clusterIP: None
ports:
- name: http
port: 8429
targetPort: http
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: vmagent
namespace: kube-vm
labels:
app: vmagent
spec:
replicas: 2
serviceName: vmagent
selector:
matchLabels:
app: vmagent
template:
metadata:
labels:
app: vmagent
spec:
serviceAccountName: vmagent
containers:
- name: agent
image: victoriametrics/vmagent:v1.77.0
imagePullPolicy: IfNotPresent
args:
- -promscrape.config=/config/scrape.yml
- -remoteWrite.tmpDataPath=/tmpData
- -promscrape.cluster.membersCount=2
# - -promscrape.cluster.replicationFactor=2 # 可以配置副本数
- -promscrape.cluster.memberNum=$(POD_NAME)
- -remoteWrite.url=http://vminsert:8480/insert/0/prometheus #注意:vmagent的remote_write只能写在这里
- -envflag.enable=true
- -envflag.prefix=VM_
- -loggerFormat=json
ports:
- name: http
containerPort: 8429
env:
- name: POD_NAME #downward api
valueFrom:
fieldRef:
fieldPath: metadata.name
volumeMounts:
- name: tmpdata
mountPath: /tmpData
- name: config
mountPath: /config
volumes:
- name: config
configMap:
name: vmagent-config
volumeClaimTemplates:
- metadata:
name: tmpdata
spec:
accessModes:
- ReadWriteOnce
storageClassName: nfs-client #注意下:这里自己要部署下nfs的,当然用longhorn也是可以的,这里就使用nfs了。
resources:
requests:
storage: 1Gi我们这里就使用 StatefulSet 的形式来管理 vmagent,直接应用上面的资源即可:
# 先将前面示例中的 prometheus 停掉
☸ ➜ kubectl scale deploy prometheus --replicas=0 -n kube-vm
部署:
☸ ➜ kubectl apply -f vmagent-sts.yaml
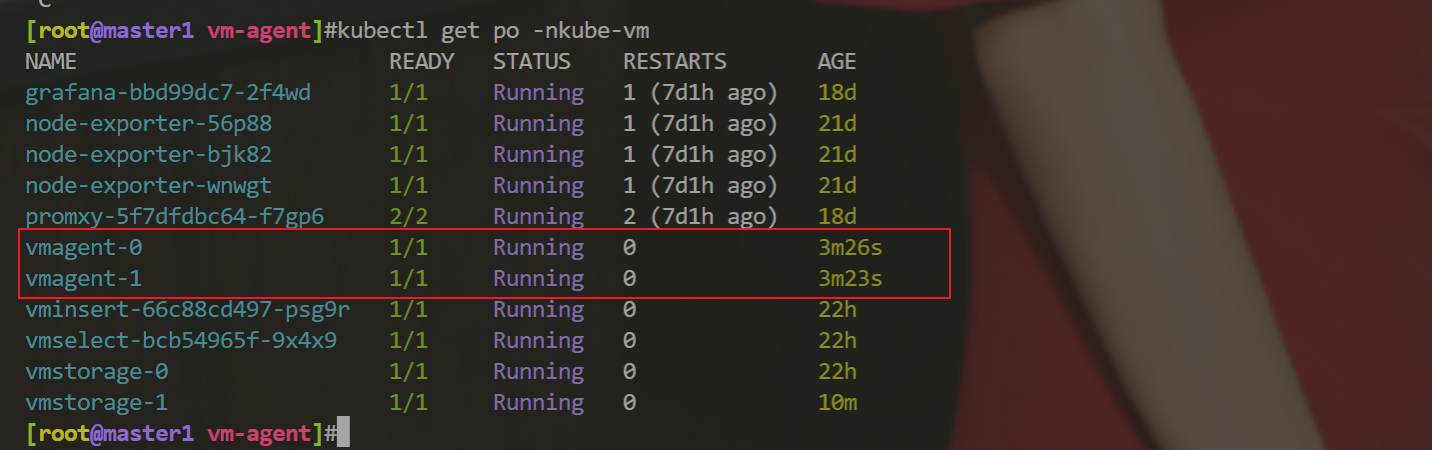
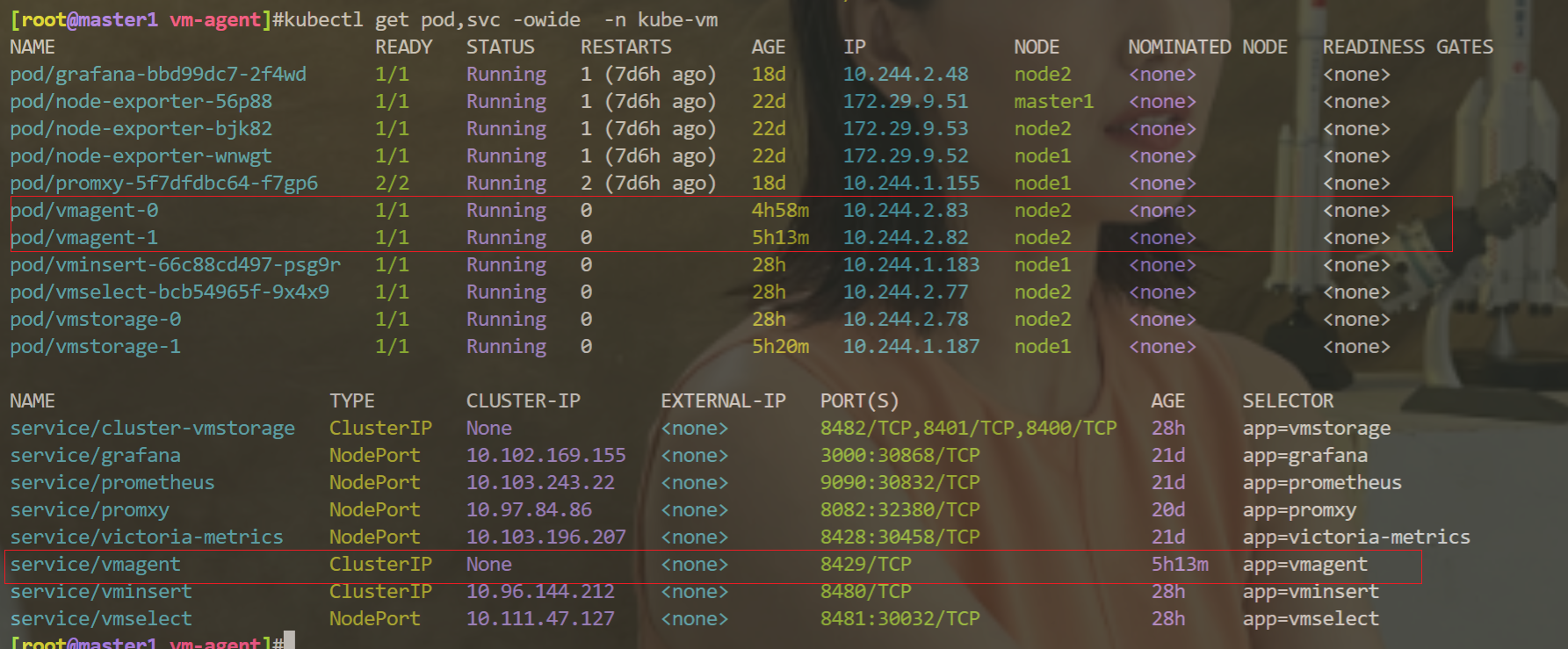
[root@master1 vm-agent]#kubectl get pods -n kube-vm -l app=vmagent
NAME READY STATUS RESTARTS AGE
vmagent-0 1/1 Running 0 3m
vmagent-1 1/1 Running 0 117s4、验证
这里我们部署了两个 vmagent 实例来抓取监控指标,我们这里一共 3 个节点。
[root@master1 vm-agent]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 287d v1.22.2
node1 Ready <none> 287d v1.22.2
node2 Ready <none> 287d v1.22.2 44d v1.22.8所以两个 vmagent 实例会分别采集部分指标,我们可以通过查看日志来进行验证:
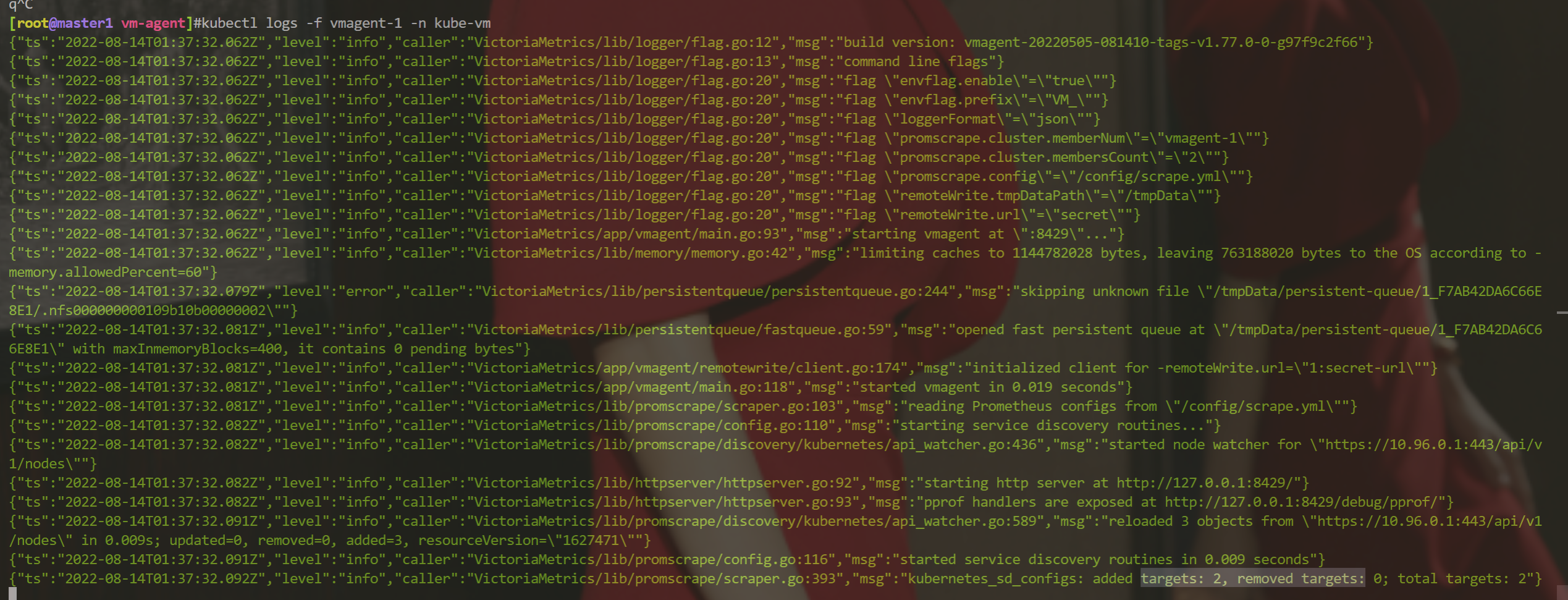
☸ ➜ kubectl logs -f vmagent-0 -n kube-vm
# ......
{"ts":"2022-08-14T01:22:15.317Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/discovery/kubernetes/api_watcher.go:436","msg":"started node watcher for \"https://10.96.0.1:443/api/v1/nodes\""}
{"ts":"2022-08-14T01:22:15.327Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/discovery/kubernetes/api_watcher.go:589","msg":"reloaded 3 objects from \"https://10.96.0.1:443/api/v1/nodes\" in 0.010s; updated=0, removed=0, added=3, resourceVersion=\"1624413\""}
{"ts":"2022-08-14T01:22:15.327Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/config.go:116","msg":"started service discovery routines in 0.010 seconds"}
{"ts":"2022-08-14T01:22:15.332Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/scraper.go:393","msg":"kubernetes_sd_configs: added targets: 1, removed targets: 0; total targets: 1"}
☸ ➜ kubectl logs -f vmagent-1 -n kube-vm
# ......
{"ts":"2022-08-14T01:23:30.033Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/discovery/kubernetes/api_watcher.go:436","msg":"started node watcher for \"https://10.96.0.1:443/api/v1/nodes\""}
{"ts":"2022-08-14T01:23:30.044Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/discovery/kubernetes/api_watcher.go:589","msg":"reloaded 3 objects from \"https://10.96.0.1:443/api/v1/nodes\" in 0.011s; updated=0, removed=0, added=3, resourceVersion=\"1624666\""}
{"ts":"2022-08-14T01:23:30.044Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/config.go:116","msg":"started service discovery routines in 0.011 seconds"}
{"ts":"2022-08-14T01:23:30.045Z","level":"info","caller":"VictoriaMetrics/lib/promscrape/scraper.go:393","msg":"kubernetes_sd_configs: added targets: 2, removed targets: 0; total targets: 2"}从日志可以看出 vmagent-0 实例发现了 1个 targets,vmagent-1 实例发现了 2 个 targets,这也符合我们预期的。
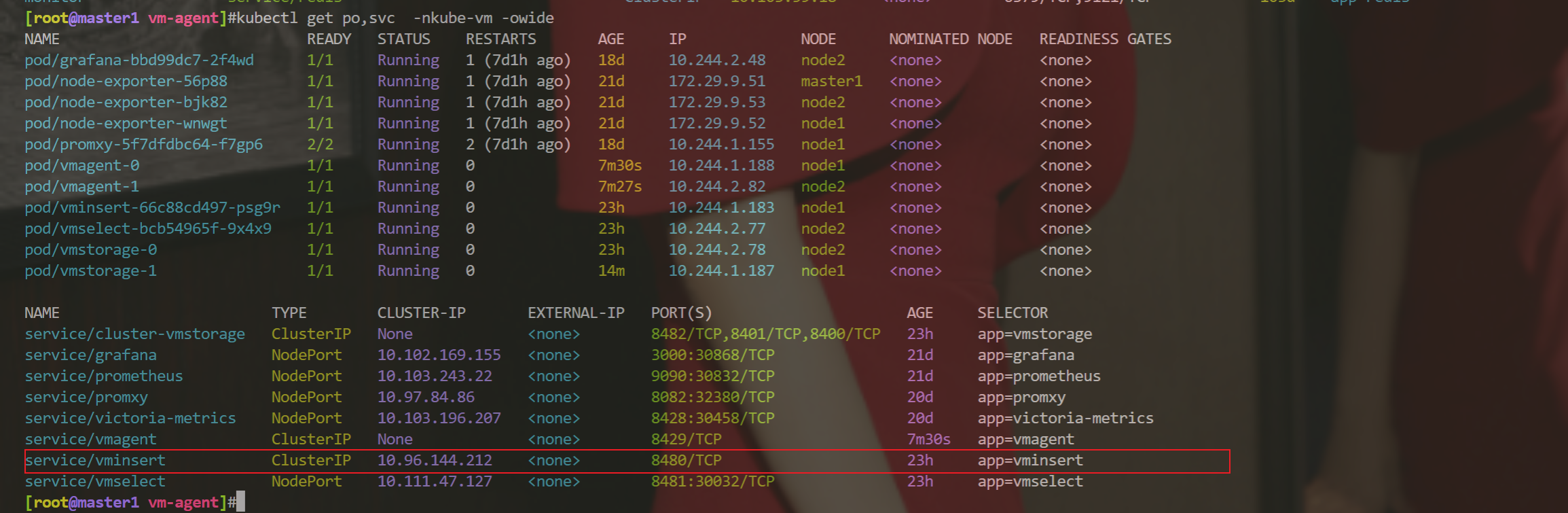
5、访问Web UI
在集群版里,默认是带了之前的那个UI界面的
[root@master1 vm-agent]#kubectl get svc -nkube-vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cluster-vmstorage ClusterIP None <none> 8482/TCP,8401/TCP,8400/TCP 23h
grafana NodePort 10.102.169.155 <none> 3000:30868/TCP 21d
prometheus NodePort 10.103.243.22 <none> 9090:30832/TCP 21d
promxy NodePort 10.97.84.86 <none> 8082:32380/TCP 20d
victoria-metrics NodePort 10.103.196.207 <none> 8428:30458/TCP 20d
vmagent ClusterIP None <none> 8429/TCP 16m
vminsert ClusterIP 10.96.144.212 <none> 8480/TCP 23h
vmselect NodePort 10.111.47.127 <none> 8481:30032/TCP 23h这里把vmselect用nodePort类型服务部署起来,然后再浏览器里访问:
http://172.29.9.51:30032/select/0/
然后访问Web UI就好:
注意下,此时有个现象,就是有个vmagent节点一直会报异常log,导致granfana那边采集会出现问题哈……

奇怪啊……
少一个节点了:
你删除下那个有问题的pod后,再次查看就发现正常了……
6、再新增其他内容的监控,比如 APIServer、容器
接下来我们再新增其他内容的监控,比如 APIServer、容器等等,配置如下所示:
vim vmagent-config2.yaml
# vmagent-config2.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vmagent-config
namespace: kube-vm
data:
scrape.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: "(.*):10250"
replacement: "${1}:9111"
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: apiserver
scheme: https
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
- job_name: cadvisor
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: /metrics/cadvisor
target_label: __metrics_path__
- job_name: endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: drop
regex: true
source_labels:
- __meta_kubernetes_pod_container_init
- action: keep_if_equal
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_port
- __meta_kubernetes_pod_container_port_number
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: service
- replacement: ${1}
source_labels:
- __meta_kubernetes_service_name
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node大部分的配置在前面 Prometheus 章节都介绍过了,核心就是通过 relabel_configs 来控制抓取的任务。
vmagent 是兼容传统的 prometheus 重新标记规则的,但也有一些独特的 action,比如上面配置中我们使用了一个 keep_if_equal 的操作,该操作的意思是如果指定的标签值相等则将该条数据保留下来。
有时,如果某个指标包含两个具有相同值的标签,则需要删除它。这可以通过 vmagent 支持的 drop_if_equal 操作来完成。例如,如果以下 relabel 规则包含 real_port 和 required_port 的相同标签值,则它会删除指标:
- action: drop_if_equal
source_labels: [real_port, needed_port]该规则将删除以下指标:foo{real_port="123",needed_port="123"},但会保留以下指标:foo{real_port="123",needed_port="456"}。
有时可能需要只对指标子集应用 relabel,在这种情况下,可以将 if 选项添加到 relabel_configs 规则中,例如以下规则仅将 {foo="bar"} 标签添加到与 metric{label=~"x|y"} 序列选择器匹配的指标:
- if: 'metric{label=~"x|y"}'
target_label: "foo"
replacement: "bar"if 选项可以简化传统的 relabel_configs 规则,例如,以下规则可以删除与 foo{bar="baz"} 序列选择器匹配的指标:
- if: 'foo{bar="baz"}'
action: drop这相当于以下传统的规则:
- action: drop
source_labels: [__name__, bar]
regex: "foo;baz"不过需要注意的是 Prometheus 还不支持 if 选项,现在只支持 VictoriaMetrics。
- 现在更新 vmagent 的配置。
[root@master1 vm-agent]#kubectl apply -f vmagent-config2.yaml
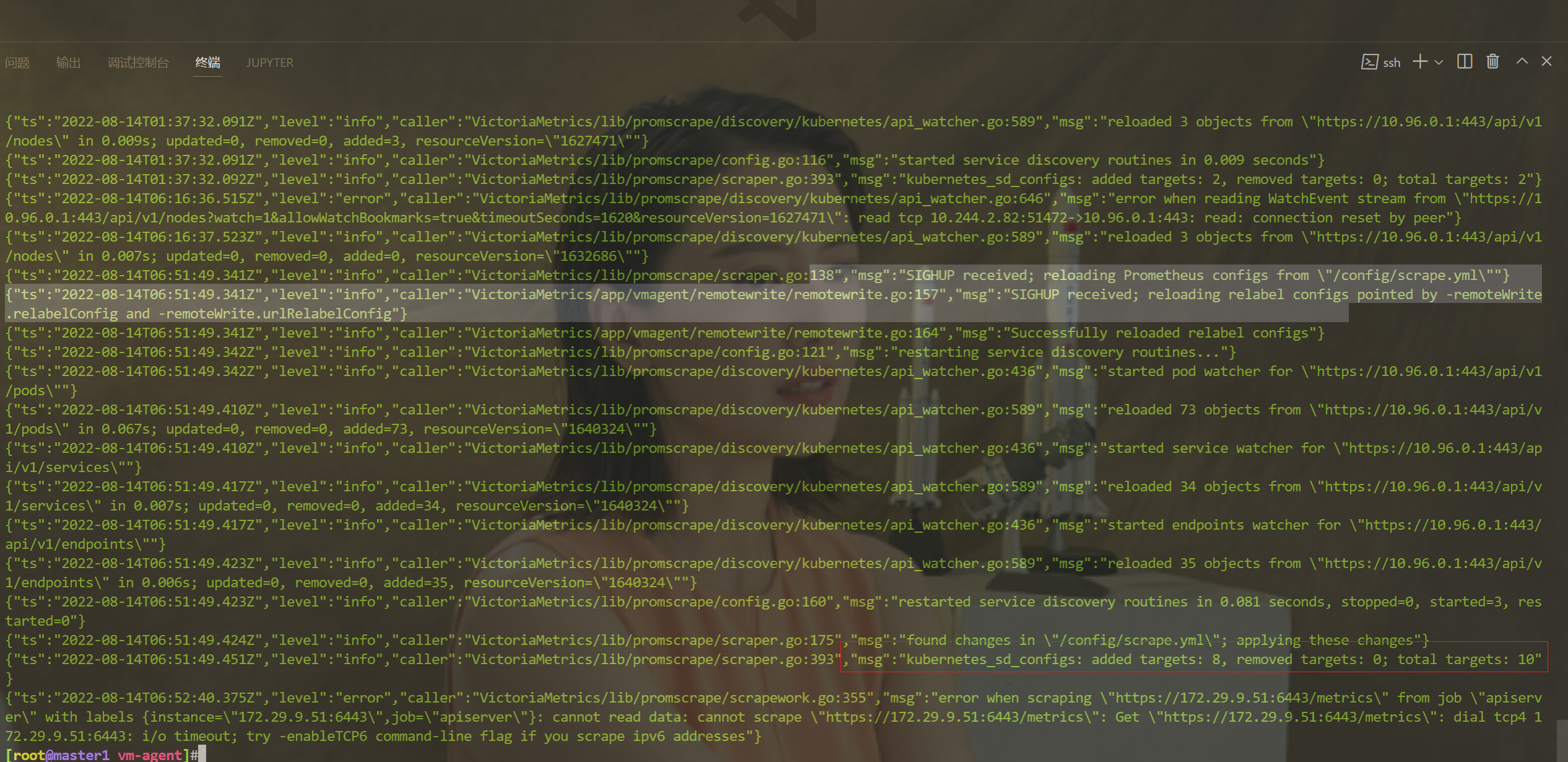
configmap/vmagent-config configured配置刷新有两种方式:
- 发送 SUGHUP 信号给 vmagent 进程
- 向
http://vmagent:8429/-/reload发送一个 http 请求
[root@master1 vm-agent]#curl -X POST http://10.244.2.83:8429/-/reload
[root@master1 vm-agent]#curl -X POST http://10.244.2.82:8429/-/reload- 查看vmagent日志
[root@master1 vm-agent]#kubectl logs vmagent-0 -nkube-vm
[root@master1 vm-agent]#kubectl logs vmagent-1 -nkube-vm
- 刷新后就可以开始采集上面的指标了,同样我们也可以通过
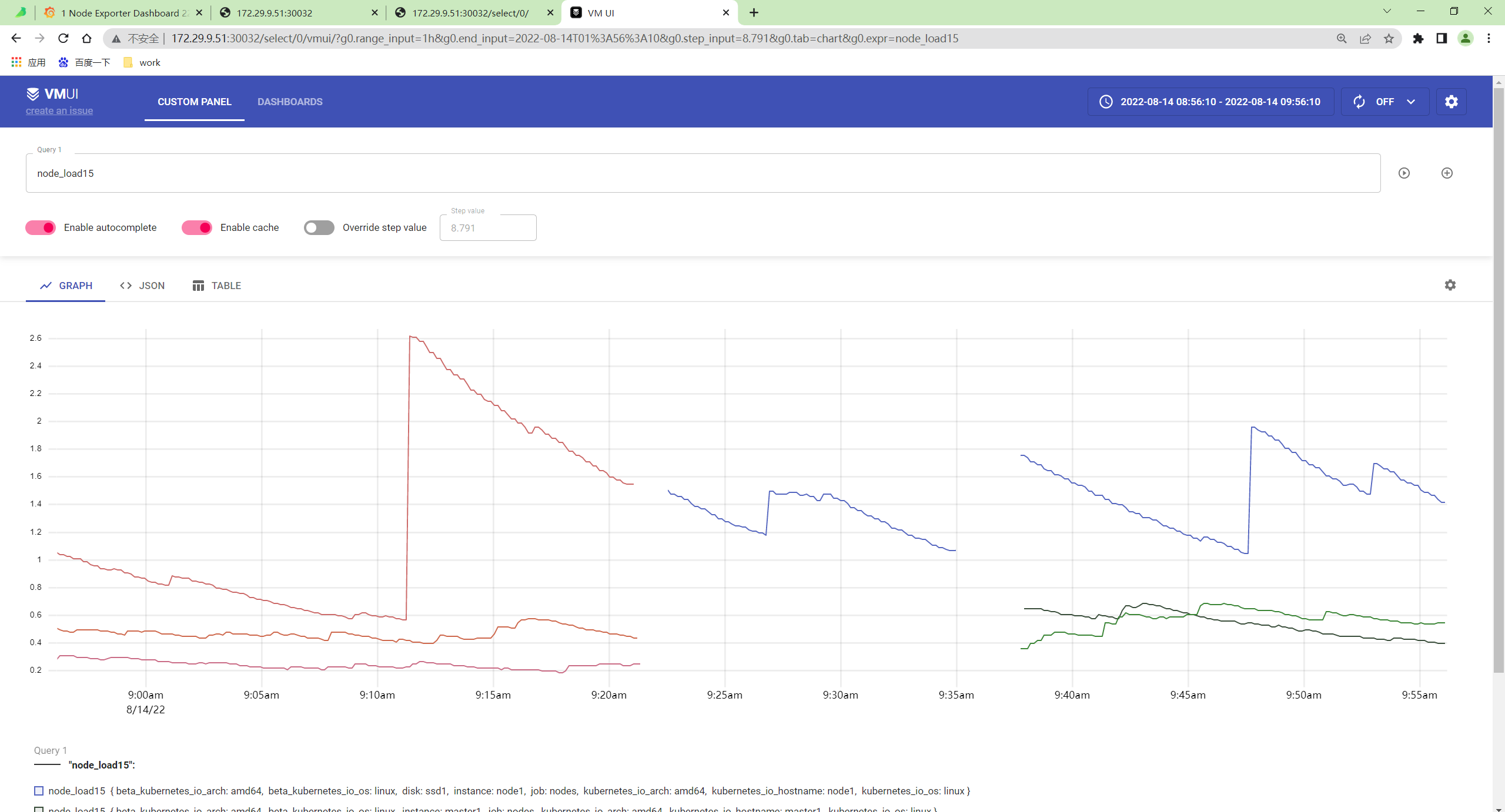
http://vmselect/select/0/vmui/来访问 vmui,比如现在我们来查询 pod 的内存使用率,可以使用如下的查询语句:
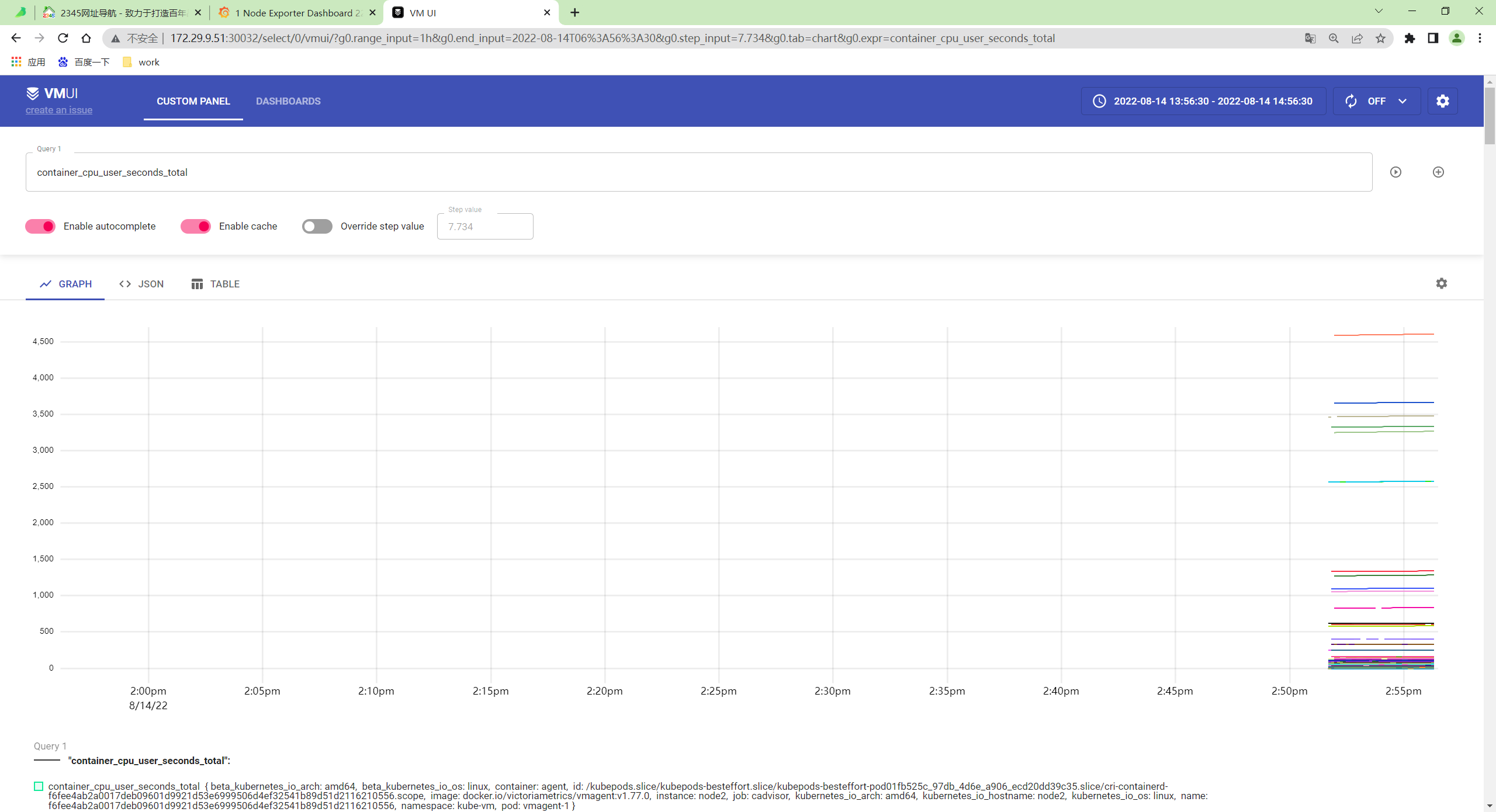
http://172.29.9.51:30032/select/0/
sum(container_memory_working_set_bytes{image!=""}) by(namespace, pod) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace, pod) * 100 != +inf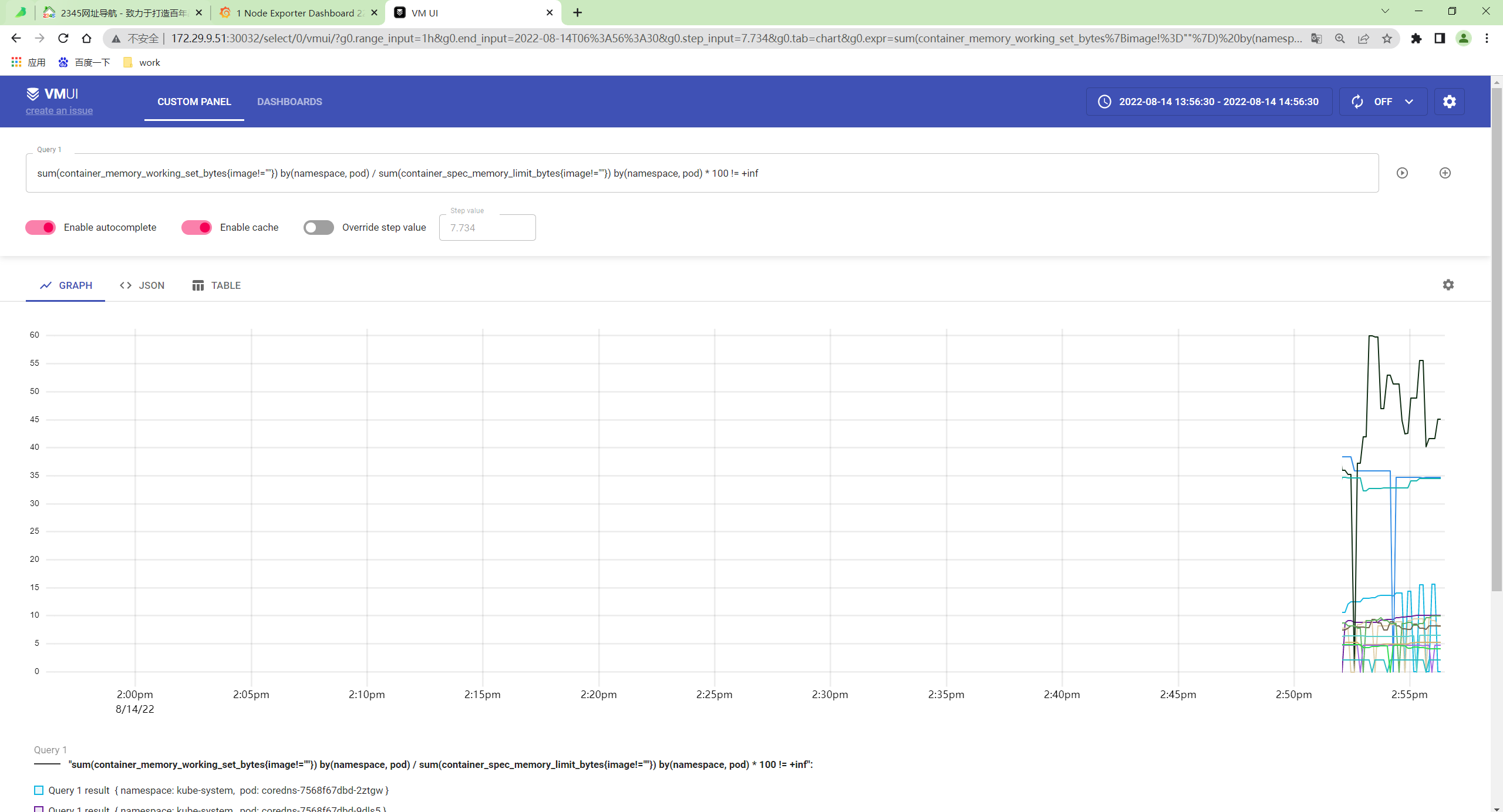
7、在grafana里展示vmagent
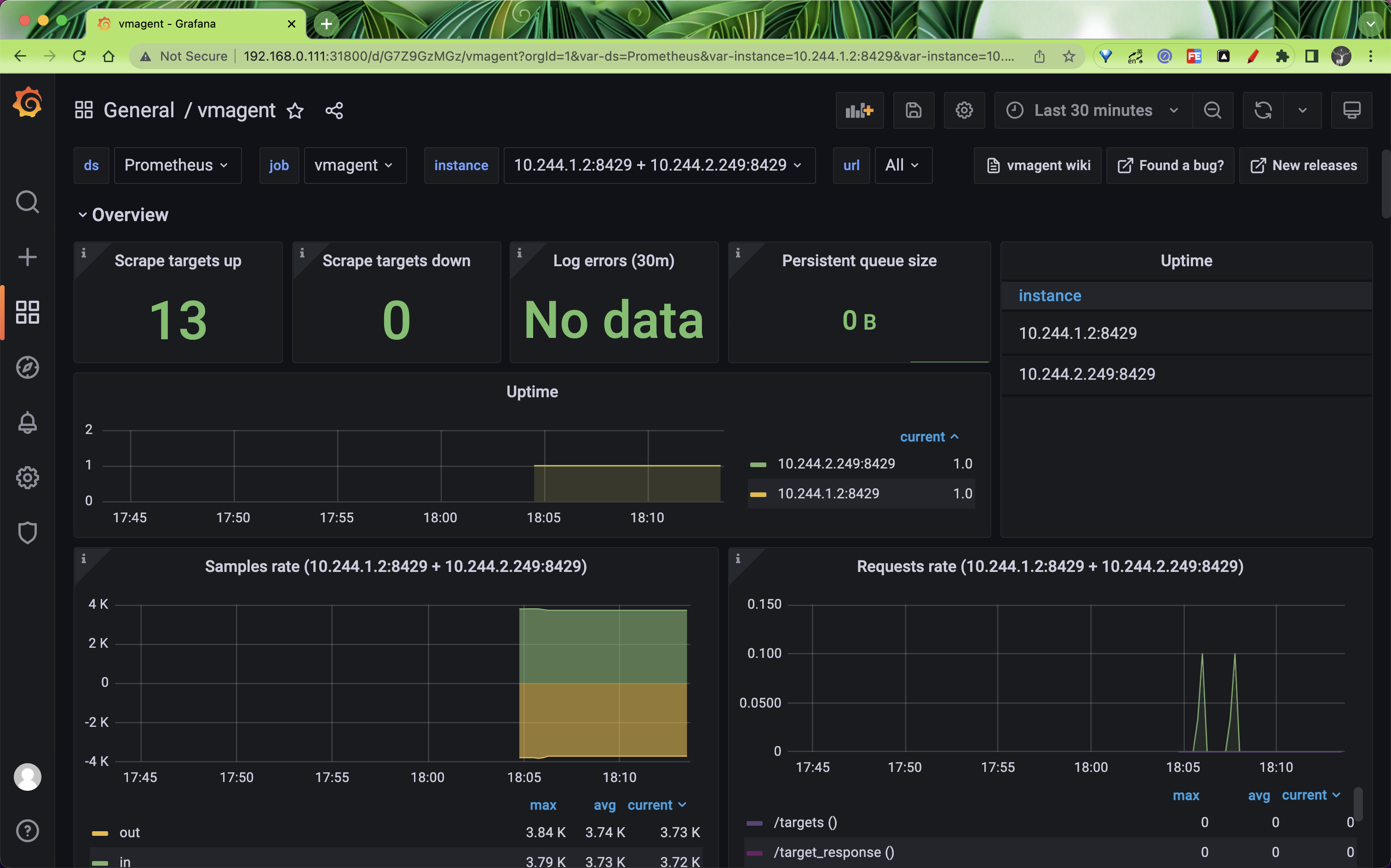
vmagent 作为采集指标重要的一环,当然对它的监控也不可少。vmagent 通过 http://vmagent:8429/metrics 暴露了很多指标,如 vmagent_remotewrite_conns 远程存储连接,vm_allowed_memory_bytes 可使用的内存大小,我们把一些重要的指标收集起来,通过 Grafana 进行展示,能够更好的帮助我们分析 vmagent 的状态。
我们可以使用 https://grafana.com/grafana/dashboards/12683 来展示 vmagent 的状态。
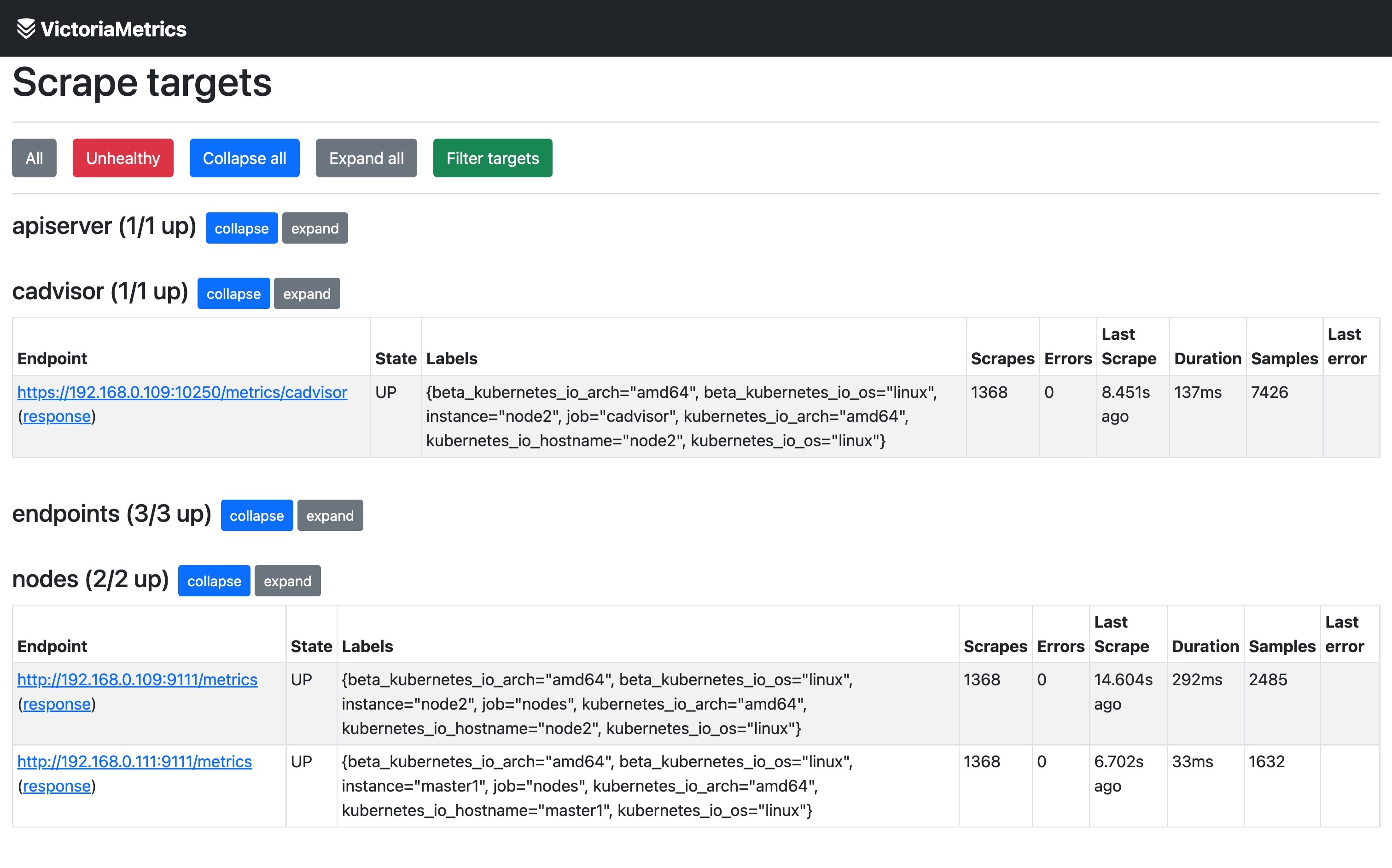
此外如果想要查看 vmagent 的抓取的 targets,也通过通过 vmagent 提供的简单页面查看,不过只能查看到指定 vmagent 的,不能直接查看所有的 targets。
测试结束。😘
4、vmalert
前面我们已经介绍了可以使用 vmagent 代替 prometheus 抓取监控指标数据,要想完全替换 prometheus 还有一个非常重要的部分就是报警模块,之前我们都是在 prometheus 中定义报警规则评估后发送给 alertmanager 的,同样对应到 vm 中也有一个专门来处理报警的模块:vmalert。
vmalert 会针对 -datasource.url 地址执行配置的报警或记录规则,然后可以将报警发送给 -notifier.url 配置的 Alertmanager,记录规则结果会通过远程写入的协议进行保存,所以需要配置 -remoteWrite.url。
1.特性
- 与 VictoriaMetrics TSDB 集成
- VictoriaMetrics MetricsQL 支持和表达式验证
- Prometheus 告警规则定义格式支持
- 与 Alertmanager 集成
- 在重启时可以保持报警状态
- Graphite 数据源可用于警报和记录规则
- 支持记录和报警规则重放
- 非常轻量级,没有额外的依赖
要开始使用 vmalert,需要满足以下条件:
- 报警规则列表:要执行的 PromQL/MetricsQL 表达式
- 数据源地址:可访问的 VictoriaMetrics 实例,用于规则执行
- 通知程序地址:可访问的 Alertmanager 实例,用于处理,汇总警报和发送通知
2.安装
💘 实战:vmalert安装(测试成功)-2022.8.15
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5实验软件
2022.8.15-VictoriaMetrics之vmalert-code
链接:https://pan.baidu.com/s/1--xB9ACMMW1oPXk1IdLRcQ?pwd=i2ci
提取码:i2ci
1.安装Alertmanager
首先需要安装一个 Alertmanager 用来接收报警信息,前面章节中我们已经详细讲解过了,这里不再赘述了,对应的资源清单如下所示:
vim alertmanager.yaml
# alertmanager.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-vm
data:
config.yml: |-
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'xxx@163.com'
smtp_auth_username: 'xxx@163.com'
smtp_auth_password: '<auth code>' # 使用网易邮箱的授权码
smtp_hello: '163.com'
smtp_require_tls: false
route:
group_by: ['severity', 'source']
group_wait: 30s
group_interval: 5m
repeat_interval: 24h
receiver: email
receivers:
- name: 'email'
email_configs:
- to: '517554016@qq.com'
send_resolved: true
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-vm
labels:
app: alertmanager
spec:
selector:
app: alertmanager
type: NodePort
ports:
- name: web
port: 9093
targetPort: http
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-vm
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: cfg
configMap:
name: alert-config
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: cfgAlertmanager 这里我们只配置了一个默认的路由规则,根据 severity、source 两个标签进行分组,然后将触发的报警发送到 email 接收器中去。
部署:
[root@master1 vmalert]#kubectl apply -f alertmanager.yaml
configmap/alert-config created
service/alertmanager created
deployment.apps/alertmanager created2.添加用于报警的规则配置
接下来需要添加用于报警的规则配置,配置方式和 Prometheus 一样的:
vim vmalert-config.yaml
# vmalert-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: vmalert-config
namespace: kube-vm
data:
record.yaml: |
groups:
- name: record
rules:
- record: job:node_memory_MemFree_bytes:percent # 记录规则名称
expr: 100 - (100 * node_memory_MemFree_bytes / node_memory_MemTotal_bytes)
pod.yaml: |
groups:
- name: pod
rules:
- alert: PodMemoryUsage
expr: sum(container_memory_working_set_bytes{pod!=""}) BY (instance, pod) / sum(container_spec_memory_limit_bytes{pod!=""} > 0) BY (instance, pod) * 100 > 60
for: 2m
labels:
severity: warning
source: pod
annotations:
summary: "Pod {{ $labels.pod }} High Memory usage detected"
description: "{{$labels.instance}}: Pod {{ $labels.pod }} Memory usage is above 60% (current value is: {{ $value }})"
node.yaml: |
groups:
- name: node
rules: # 具体的报警规则
- alert: NodeMemoryUsage # 报警规则的名称
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 30
for: 1m
labels:
source: node
severity: critical
annotations:
summary: "Node {{$labels.instance}} High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 30% (current value is: {{ $value }})"这里我们添加了一条记录规则,两条报警规则,更多报警规则配置可参考 https://awesome-prometheus-alerts.grep.to/。
部署:
[root@master1 vmalert]#kubectl apply -f vmalert-config.yaml
configmap/vmalert-config created3.部署 vmalert 组件
然后就可以部署 vmalert 组件服务了:
vim vmalert.yaml
# vmalert.yaml
apiVersion: v1
kind: Service
metadata:
name: vmalert
namespace: kube-vm
labels:
app: vmalert
spec:
ports:
- name: vmalert
port: 8080
targetPort: 8080
type: NodePort
selector:
app: vmalert
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: vmalert
namespace: kube-vm
labels:
app: vmalert
spec:
selector:
matchLabels:
app: vmalert
template:
metadata:
labels:
app: vmalert
spec:
containers:
- name: vmalert
image: victoriametrics/vmalert:v1.77.0
imagePullPolicy: IfNotPresent
args:
- -rule=/etc/ruler/*.yaml
- -datasource.url=http://vmselect.kube-vm.svc.cluster.local:8481/select/0/prometheus
- -notifier.url=http://alertmanager.kube-vm.svc.cluster.local:9093
- -remoteWrite.url=http://vminsert.kube-vm.svc.cluster.local:8480/insert/0/prometheus
- -evaluationInterval=15s
- -httpListenAddr=0.0.0.0:8080
volumeMounts:
- mountPath: /etc/ruler/
name: ruler
readOnly: true
volumes:
- configMap:
name: vmalert-config
name: ruler上面的资源清单中将报警规则以 volumes 的形式挂载到了容器中,通过 -rule 指定了规则文件路径,-datasource.url 指定了 vmselect 的路径,-notifier.url 指定了 Alertmanager 的地址,其中 -evaluationInterval 参数用来指定评估的频率的,由于我们这里添加了记录规则,所以还需要通过 -remoteWrite.url 指定一个远程写入的地址。
部署:
[root@master1 vmalert]#kubectl apply -f vmalert.yaml
service/vmalert created
deployment.apps/vmalert created4.部署
直接创建上面的资源清单即可完成部署。
[root@master1 vmalert]#kubectl get pods -n kube-vm -l app=alertmanager
NAME READY STATUS RESTARTS AGE
alertmanager-dd8fb4858-zv672 1/1 Running 0 5m19s
[root@master1 vmalert]#kubectl get svc -n kube-vm -l app=alertmanager
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager NodePort 10.103.164.31 <none> 9093:30978/TCP 5m34s
[root@master1 vmalert]#kubectl get pods -n kube-vm -l app=vmalert
NAME READY STATUS RESTARTS AGE
vmalert-866674b966-8vtqb 1/1 Running 0 72s
[root@master1 vmalert]#kubectl get svc -n kube-vm -l app=vmalert
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
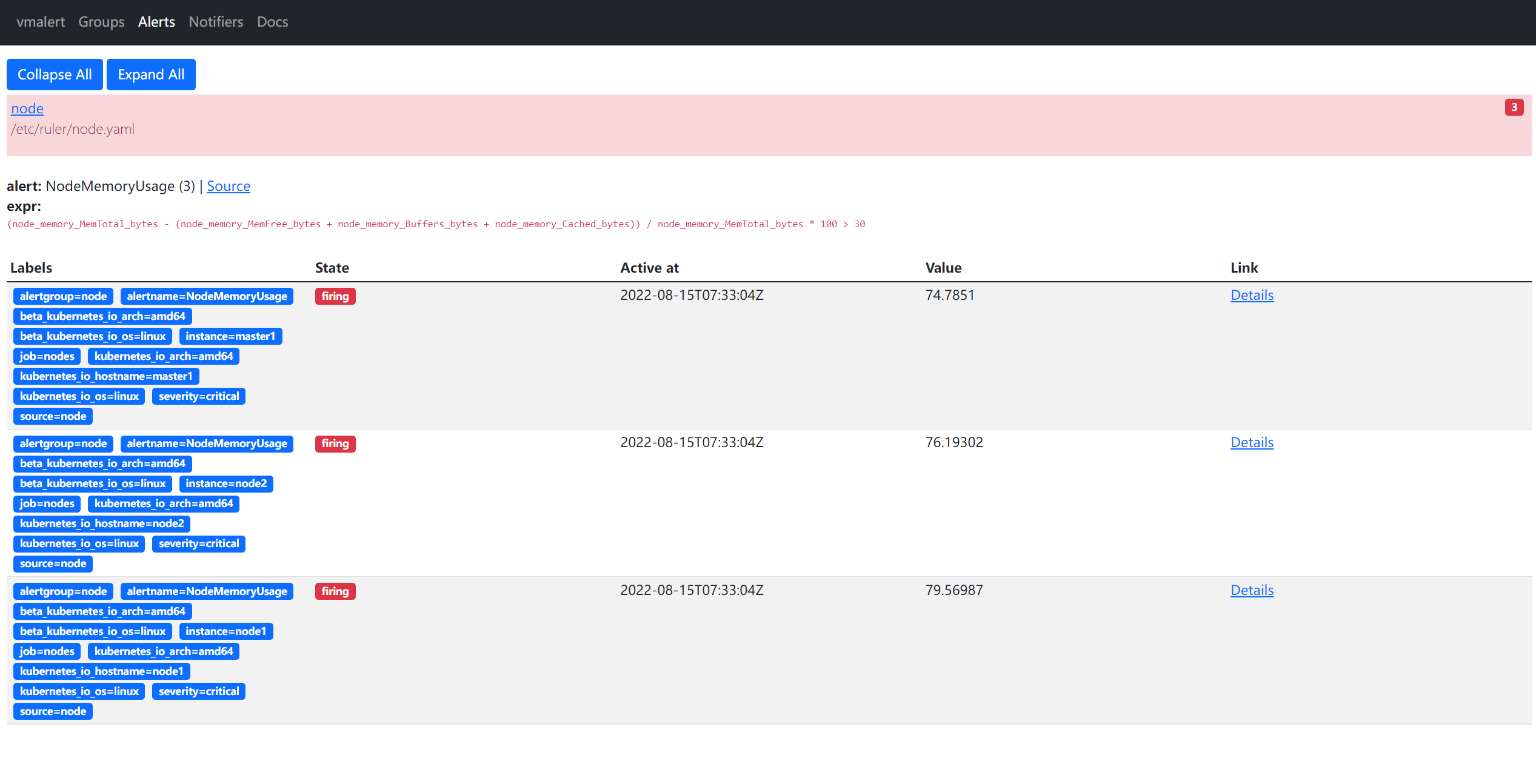
vmalert NodePort 10.109.65.27 <none> 8080:32733/TCP 79s5.验证
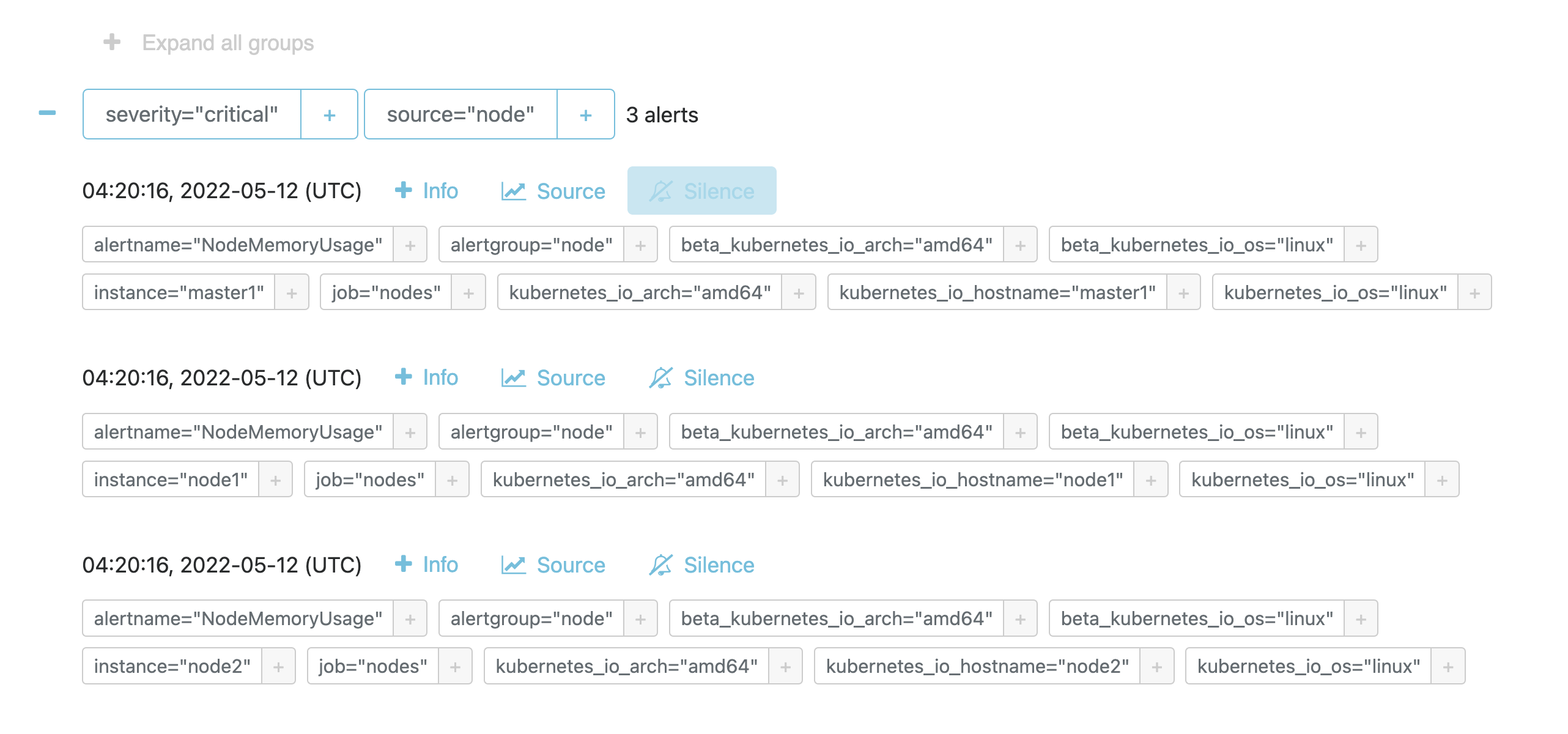
部署成功后,如果有报警规则达到了阈值就会触发报警,我们可以通过 Alertmanager 页面查看触发的报警规则:
哈哈,我这里可能有点小问题……这里没出现现象……
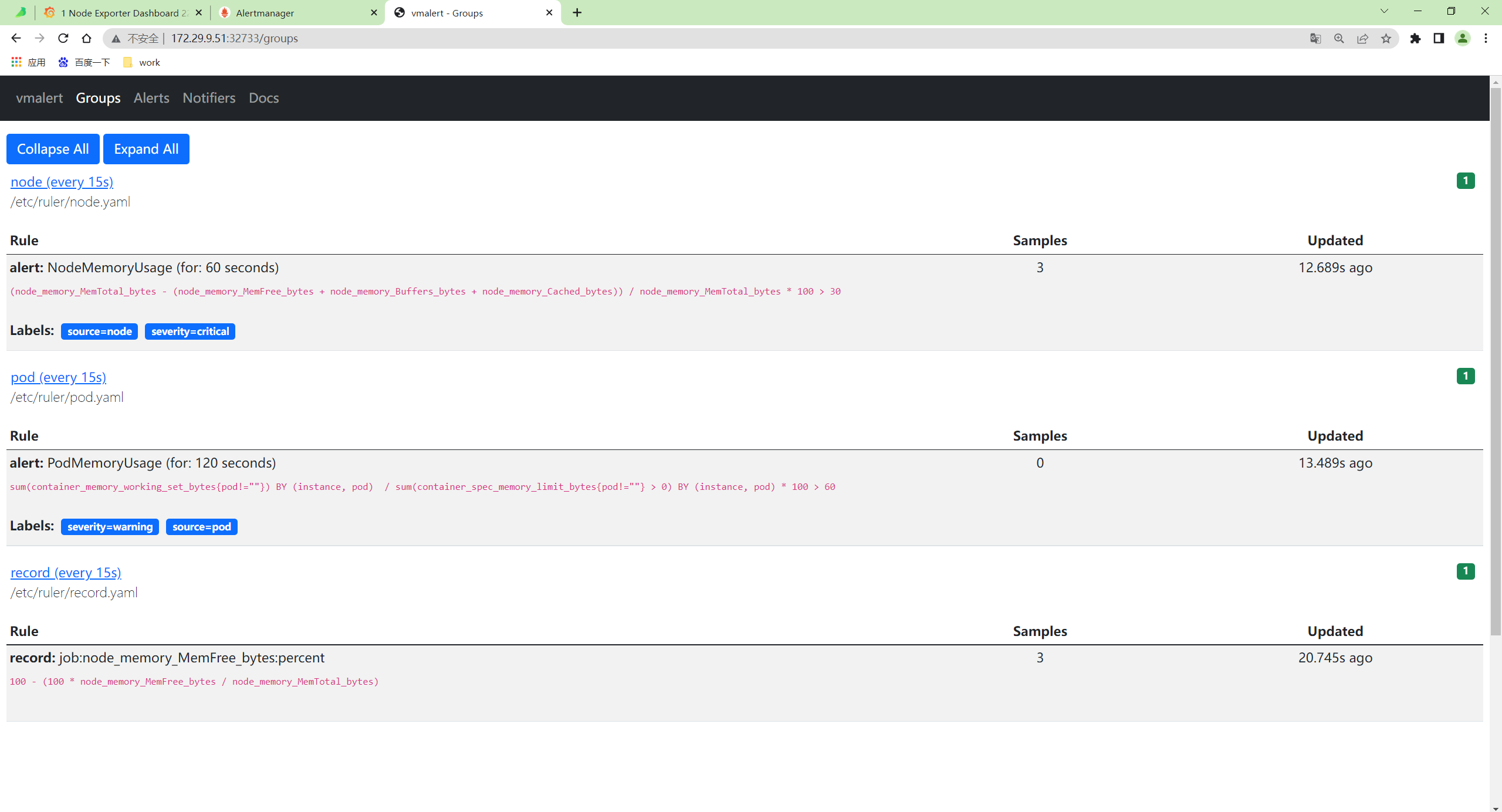
同样 vmalert 也提供了一个简单的页面,可以查看所有的 Groups:
http://172.29.9.51:32733/groups
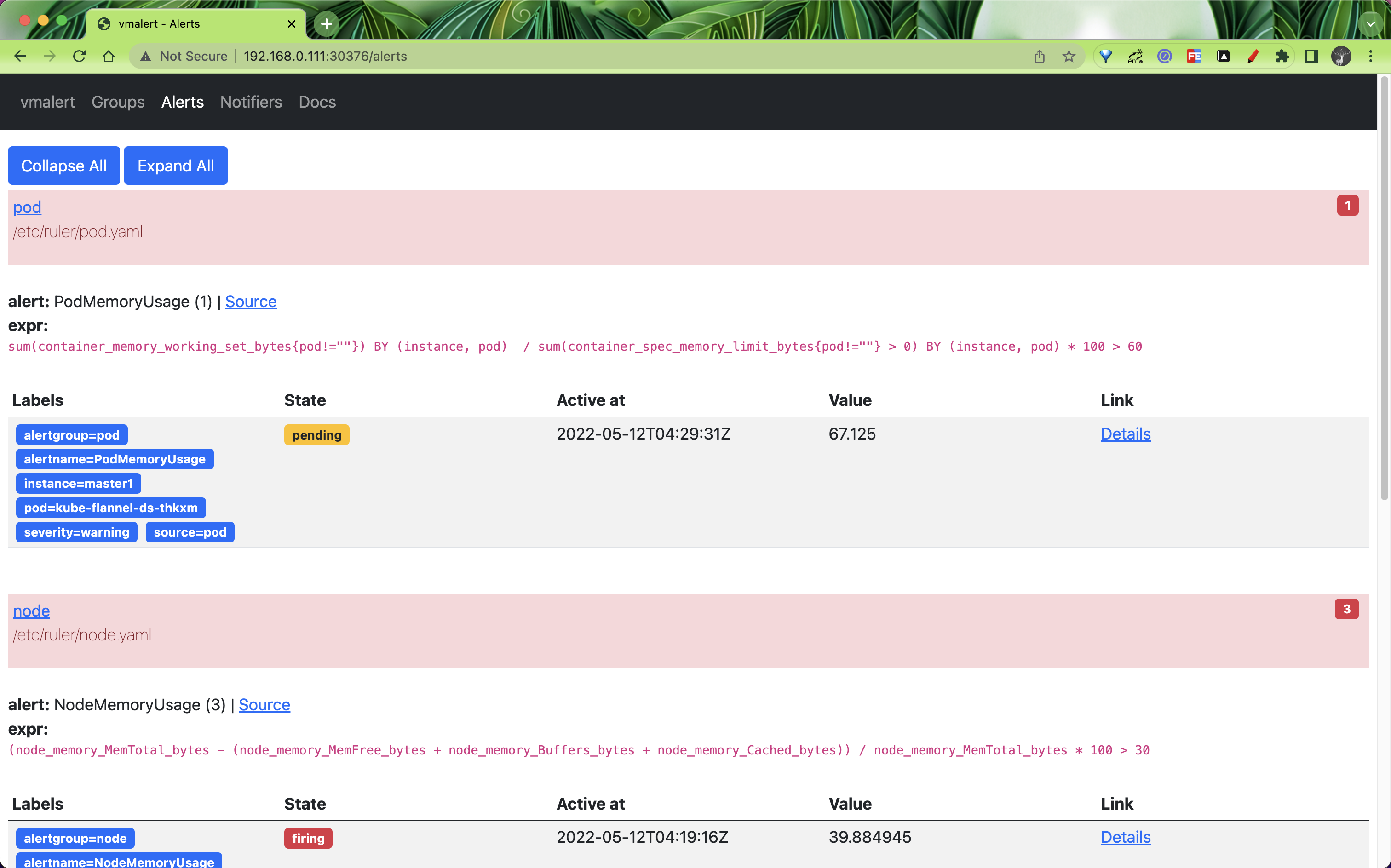
也可以查看到报警规则列表的状态:
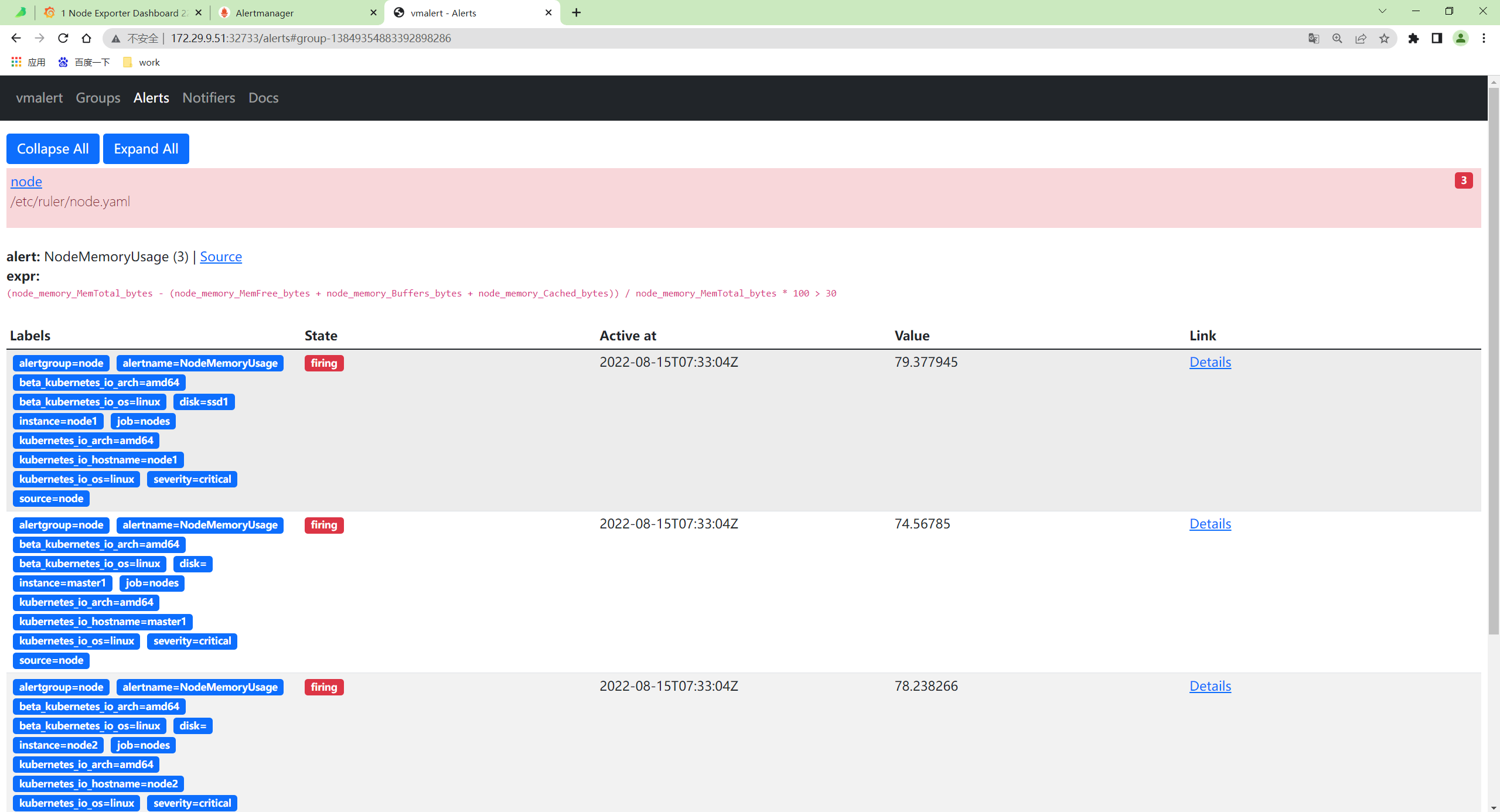
我的现象:
还可以查看到具体的一条报警规则的详细信息,如下所示:
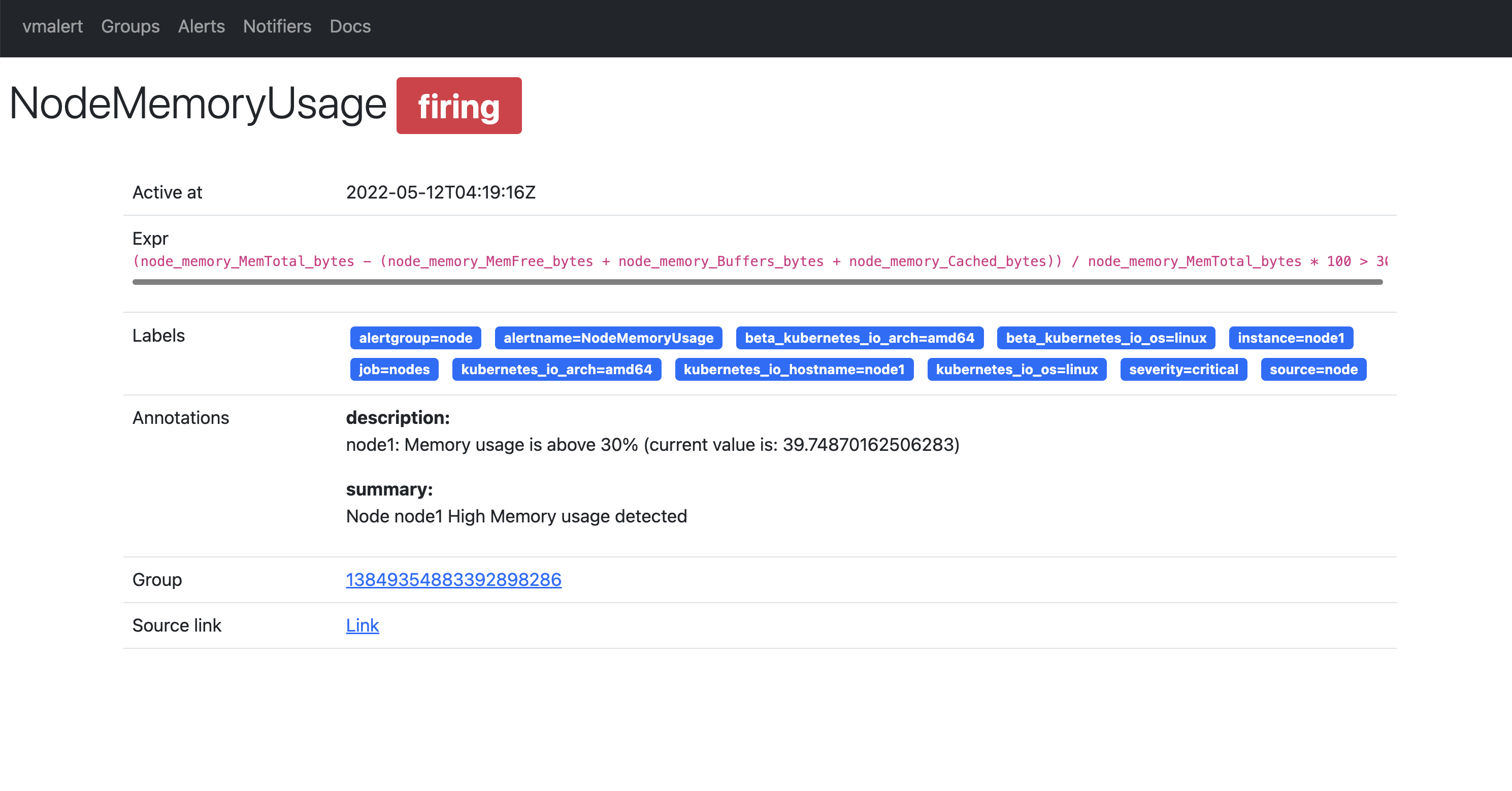
报警规则触发后怎么发送,发送到哪个接收器就是 Alertmanager 决定的了。
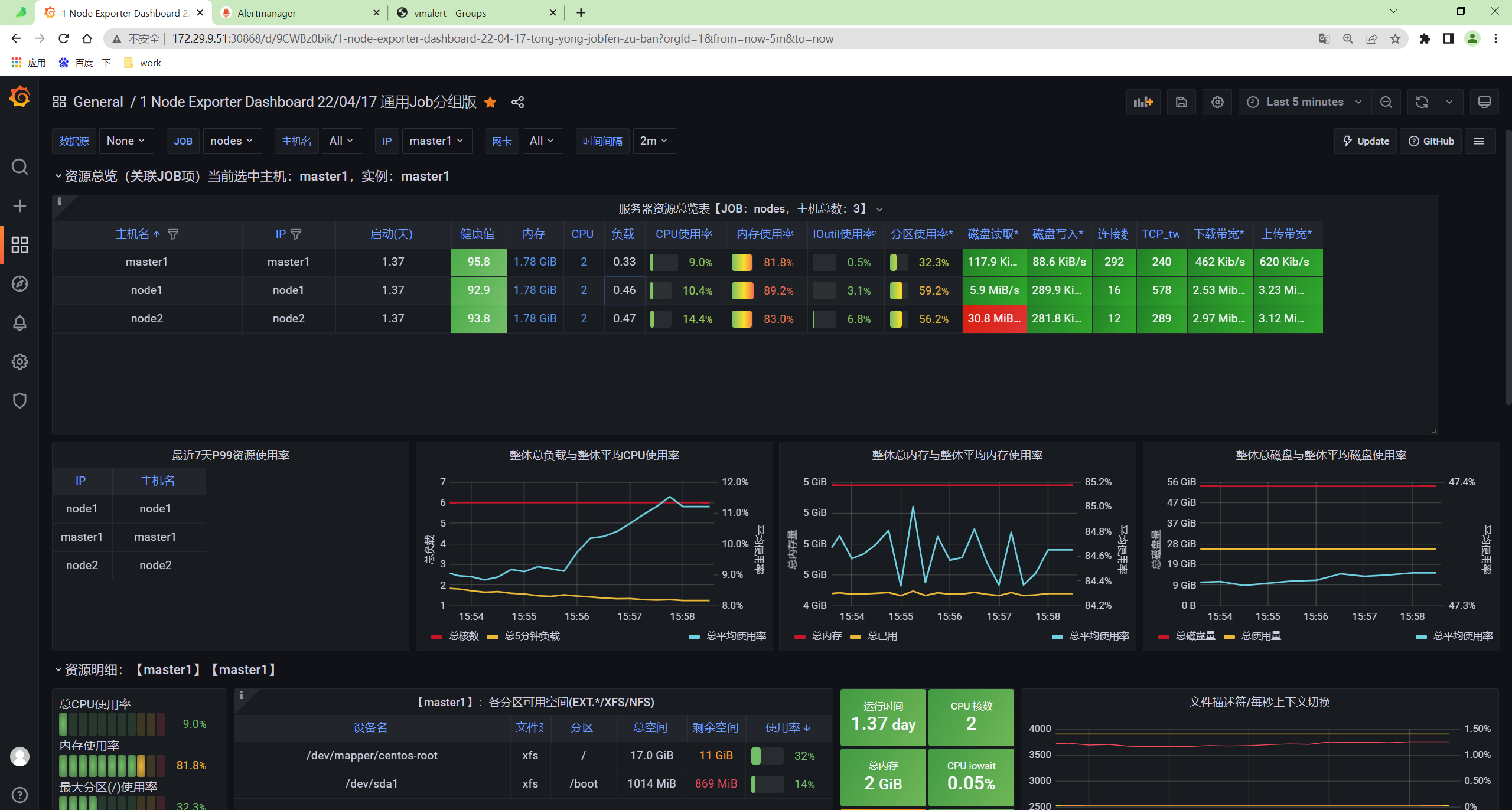
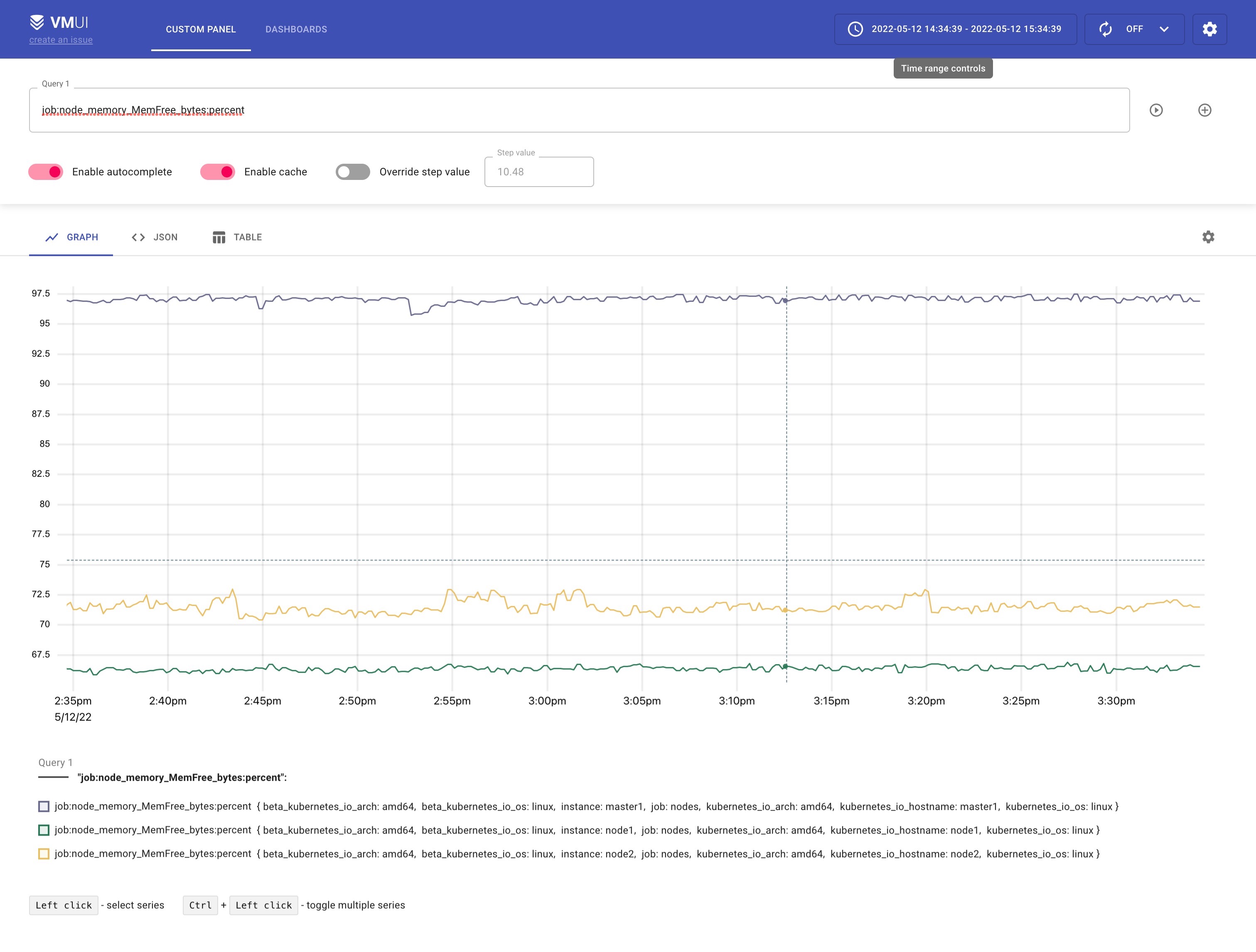
同样的上面我们添加的记录规则会通过 remote write 传递给 vminsert 保留下来,所以我们也可以通过 vmselect 查询到。
http://172.29.9.51:30032/select/0/
到这里基本上我们就完成了使用 vm 代替 prometheus 来进行监控报警了,vmagent 采集监控指标,vmalert 用于报警监控,vmstorage 存储指标数据,vminsert 接收指标数据,vmselect 查询指标数据,已经完全可以不使用 prometheus 了,而且性能非常高,所需资源也比 prometheus 低很多。
测试结束。😘
5、vm-operator
Operator 我们知道是 Kubernetes 的一大杀器,可以大大简化应用的安装、配置和管理,同样对于 VictoriaMetrics 官方也开发了一个对应的 Operator 来进行管理 - vm-operator,它的设计和实现灵感来自 prometheus-operator(后面会讲解),它是管理应用程序监控配置的绝佳工具。
vm-operator 定义了如下一些 CRD:
VMServiceScrape:定义从 Service 支持的 Pod 中抓取指标配置VMPodScrape:定义从 Pod 中抓取指标配置VMRule:定义报警和记录规则VMProbe:使用 blackbox exporter 为目标定义探测配置
此外该 Operator 默认还可以识别 prometheus-operator 中的 ServiceMonitor、PodMonitor、PrometheusRule 和 Probe 对象,还允许你使用 CRD 对象来管理 Kubernetes 集群内的 VM 应用。
💘 实战:vm-operator(测试成功)-2022.8.18
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5实验软件
链接:https://pan.baidu.com/s/1GWanP4HcHpw30S0NpnaDwg?pwd=2ggo
提取码:2ggo
2022.8.18-VictoriaMetrics之vm-operator-code
1、vm-operator安装
1.添加helm仓库
- vm-operator 提供了 Helm Charts 包,所以可以使用 Helm 来进行一键安装:
☸ ➜ helm repo add vm https://victoriametrics.github.io/helm-charts/
☸ ➜ helm repo update2.下载charts包并修改values.yaml内容
- 根据自己的需要定制 values 值,默认的
values.yaml可以通过下面的命令获得:
☸ ➜ helm show values vm/victoria-metrics-operator > values.yaml
#这里直接把这个chart包给fetch下来
[root@master1 vm-operator]#helm fetch vm/victoria-metrics-operator
[root@master1 vm-operator]#ll -h victoria-metrics-operator-0.11.3.tgz
-rw-r--r-- 1 root root 212K Aug 15 17:13 victoria-metrics-operator-0.11.3.tgz
[root@master1 vm-operator]#tar xf victoria-metrics-operator-0.11.3.tgz
[root@master1 vm-operator]#cd victoria-metrics-operator/
[root@master1 victoria-metrics-operator]#ls
Chart.yaml README.md README.md.gotmpl templates values.yaml
[root@master1 victoria-metrics-operator]#cat values.yaml
# Default values for victoria-metrics.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
image:
# -- Image repository
repository: victoriametrics/operator
# -- Image tag
tag: v0.26.2
# -- Image pull policy
pullPolicy: IfNotPresent
# -- enables CRD creation and management.
# -- with this option, if you remove this chart, all crd resources will be deleted with it.
createCRD: true
# -- uses legacy CRD api v1beta
# -- it must be enabled for kubernetes version below 1.16
useLegacyCRD: false
replicaCount: 1
# -- Secret to pull images
imagePullSecrets: []
# -- VM operatror deployment name override
nameOverride: ""
# -- Overrides the full name of server component
fullnameOverride: ""
# -- VM operator log level
# -- possible values: info and error.
logLevel: "info"
rbac:
# -- Specifies whether the RBAC resources should be created
create: true
pspEnabled: true
# -- Labels to be added to the all resources
extraLabels: {}
# extra Labels for Pods only
podLabels: {}
# -- Annotations to be added to the all resources
annotations: {}
securityContext:
{}
operator:
# -- By default, operator converts prometheus-operator objects.
disable_prometheus_converter: false
# -- By default, operator creates psp for its objects.
psp_auto_creation_enabled: true
# -- Enables ownership reference for converted prometheus-operator objects,
# it will remove corresponding victoria-metrics objects in case of deletion prometheus one.
enable_converter_ownership: false
# -- Enables custom config-reloader, bundled with operator.
# It should reduce vmagent and vmauth config sync-time and make it predictable.
useCustomConfigReloader: false
serviceAccount:
# -- Specifies whether a service account should be created
create: true
# -- The name of the service account to use. If not set and create is true, a name is generated using the fullname template
name: ""
# -- Resource object
resources: {}
# limits:
# cpu: 120m
# memory: 320Mi
# requests:
# cpu: 80m
# memory: 120Mi
# -- Pod's node selector. Ref: [https://kubernetes.io/docs/user-guide/node-selection/](https://kubernetes.io/docs/user-guide/node-selection/
nodeSelector: {}
# -- Array of tolerations object. Ref: [https://kubernetes.io/docs/concepts/configuration/assign-pod-node/](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/)
tolerations: []
# -- Pod affinity
affinity: {}
# -- extra settings for the operator deployment. full list Ref: [https://github.com/VictoriaMetrics/operator/blob/master/vars.MD](https://github.com/VictoriaMetrics/operator/blob/master/vars.MD)
env: []
# - name: VM_VMSINGLEDEFAULT_VERSION
# value: v1.43.0
# -- Additional hostPath mounts
extraHostPathMounts:
[]
# - name: certs-dir
# mountPath: /etc/kubernetes/certs
# subPath: ""
# hostPath: /etc/kubernetes/certs
# readOnly: true
# -- Extra Volumes for the pod
extraVolumes:
[]
# - name: example
# configMap:
# name: example
# -- Extra Volume Mounts for the container
extraVolumeMounts:
[]
# - name: example
# mountPath: /example
extraContainers:
[]
# - name: config-reloader
# image: reloader-image
# -- Configures resource validation
admissionWebhooks:
# -- Enables validation webhook.
enabled: false
# -- What to do in case, when operator not available to validate request.
policy: Fail
# -- Enables custom ca bundle, if you are not using cert-manager.
# -- in case of custom ca, you have to create secret - {{chart-name}}-validation
# -- with keys: tls.key, tls.crt, ca.crt
caBundle: ""
certManager:
# -- Enables cert creation and injection by cert-manager.
enabled: false
# --If needed, provide own issuer. Operator will create self-signed if empty.
issuer: {}- 我们这里只对下面的内容做了修改:
vim values.yaml
# values.yaml
rbac:
# -- Specifies whether the RBAC resources should be created
create: true
pspEnabled: false
operator:
# -- 默认情况下,vm-operator会转换prometheus-operator对象
disable_prometheus_converter: false
# -- 默认情况下,vm-operator会为它的对象创建psp
psp_auto_creation_enabled: false
# -- 启用转换后的 prometheus-operator 对象的所有权引用,如果删除 prometheus 对象,它将删除相应的 victoria-metrics 对象。
enable_converter_ownership: false
# -- Enables custom config-reloader, bundled with operator.
# It should reduce vmagent and vmauth config sync-time and make it predictable.
useCustomConfigReloader: true
# -- 是否开启资源校验的准入控制器(生产环境建议开启)
# admissionWebhooks:
# # -- Enables validation webhook.
# enabled: false
# # -- What to do in case, when operator not available to validate request.
# policy: Fail
# # -- Enables custom ca bundle, if you are not using cert-manager.
# # -- in case of custom ca, you have to create secret - {{chart-name}}-validation
# # -- with keys: tls.key, tls.crt, ca.crt
# caBundle: ""
# certManager:
# # -- Enables cert creation and injection by cert-manager.
# enabled: false
# # --If needed, provide own issuer. Operator will create self-signed if empty.
# issuer: {}3.安装
- 然后使用下面的命令即可一键安装 vm-operator:
[root@master1 vm-operator]#helm upgrade --install victoria-metrics-operator vm/victoria-metrics-operator -f values.yaml -n vm-operator --create-namespace
Release "victoria-metrics-operator" does not exist. Installing it now.
NAME: victoria-metrics-operator
LAST DEPLOYED: Mon Aug 15 17:25:20 2022
NAMESPACE: vm-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
victoria-metrics-operator has been installed. Check its status by running:
kubectl --namespace vm-operator get pods -l "app.kubernetes.io/instance=victoria-metrics-operator"
Get more information on https://github.com/VictoriaMetrics/helm-charts/tree/master/charts/victoria-metrics-operator.
See "Getting started guide for VM Operator" on https://docs.victoriametrics.com/guides/getting-started-with-vm-operator.html .4.验证
- 安装完成后可以查看 vm-operator 的状态来验证是否安装成功:
[root@master1 vm-operator]#helm ls -n vm-operator
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
victoria-metrics-operator vm-operator 1 2022-08-15 17:25:20.771034202 +0800 CST deployed victoria-metrics-operator-0.11.3 0.26.3
[root@master1 vm-operator]#kubectl --namespace vm-operator get pods -l "app.kubernetes.io/instance=victoria-metrics-operator"
NAME READY STATUS RESTARTS AGE
victoria-metrics-operator-5b98996ccc-5pcsg 1/1 Running 2 (3m10s ago) 5m52s2、安装 VM 集群
- Operator 安装完成后会包含如下所示的一些 CRD:
[root@master1 vm-operator]#kubectl get crd |grep victoriametrics
vmagents.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmalertmanagerconfigs.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmalertmanagers.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmalerts.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmauths.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmclusters.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmnodescrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmpodscrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmprobes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmrules.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmservicescrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmsingles.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmstaticscrapes.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmusers.operator.victoriametrics.com 2022-08-15T09:25:21Z比如现在我们要来部署 VM,如果只是想要单节点模式则可以直接使用 VMSingle 对象,如果要部署一套 VM 的集群则可以直接使用 VMCluster 来定义一个对象即可,完全不需要我们去手动创建各个组件,Operator 会根据我们的定义去帮我们拉起一套集群起来。
1.创建VMCluster对象
- 比如这里我们定义一个如下所示的
VMCluster对象:
vim vmcluster-demo.yaml
# vmcluster-demo.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMCluster
metadata:
name: vmcluster-demo
spec:
replicationFactor: 1
retentionPeriod: "1w"
vmstorage:
replicaCount: 2
storage:
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10G
storageClassName: nfs-client
storageDataPath: /vm-data
vmselect:
replicaCount: 2
cacheMountPath: /cache
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1G
vminsert:
replicaCount: 2这里我们通过 spec.retentionPeriod 指定了数据保留的时长为 1 周,replicaCount 用来指定各个组件的副本数为 2,通过 storage.volumeClaimTemplate 指定了数据持久化的 PVC 模板。
- 整个对象可配置的属性我们可以通过
kubectl explain来获取:
☸ ➜ kubectl explain VMCluster.spec
KIND: VMCluster
VERSION: operator.victoriametrics.com/v1beta1
RESOURCE: spec <Object>
DESCRIPTION:
VMClusterSpec defines the desired state of VMCluster
FIELDS:
clusterVersion <string>
ClusterVersion defines default images tag for all components. it can be
overwritten with component specific image.tag value.
imagePullSecrets <[]Object>
ImagePullSecrets An optional list of references to secrets in the same
namespace to use for pulling images from registries see
http://kubernetes.io/docs/user-guide/images#specifying-imagepullsecrets-on-a-pod
podSecurityPolicyName <string>
PodSecurityPolicyName - defines name for podSecurityPolicy in case of empty
value, prefixedName will be used.
replicationFactor <integer>
ReplicationFactor defines how many copies of data make among distinct
storage nodes
retentionPeriod <string> -required-
RetentionPeriod for the stored metrics Note VictoriaMetrics has data/ and
indexdb/ folders metrics from data/ removed eventually as soon as partition
leaves retention period reverse index data at indexdb rotates once at the
half of configured retention period
https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#retention
serviceAccountName <string>
ServiceAccountName is the name of the ServiceAccount to use to run the
VMSelect Pods.
vminsert <Object>
vmselect <Object>
vmstorage <Object>同样要想获取组件可以定义的属性也可以通过该方式来获取,比如查看 vmstorage 对象可以配置的属性:
☸ ➜ kubectl explain VMCluster.spec.vmstorage
KIND: VMCluster
VERSION: operator.victoriametrics.com/v1beta1
RESOURCE: vmstorage <Object>
DESCRIPTION:
<empty>
FIELDS:
affinity <>
Affinity If specified, the pod's scheduling constraints.
configMaps <[]string>
ConfigMaps is a list of ConfigMaps in the same namespace as the VMSelect
object, which shall be mounted into the VMSelect Pods. The ConfigMaps are
mounted into /etc/vm/configs/<configmap-name>.
containers <[]>
Containers property allows to inject additions sidecars or to patch
existing containers. It can be useful for proxies, backup, etc.
dnsConfig <Object>
Specifies the DNS parameters of a pod. Parameters specified here will be
merged to the generated DNS configuration based on DNSPolicy.
dnsPolicy <string>
DNSPolicy sets DNS policy for the pod
extraArgs <map[string]string>
extraEnvs <[]>
ExtraEnvs that will be added to VMSelect pod
hostNetwork <boolean>
HostNetwork controls whether the pod may use the node network namespace
image <Object>
Image - docker image settings for VMStorage
initContainers <[]>
InitContainers allows adding initContainers to the pod definition. Those
can be used to e.g. fetch secrets for injection into the VMSelect
configuration from external sources. Any errors during the execution of an
initContainer will lead to a restart of the Pod. More info:
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/ Using
initContainers for any use case other then secret fetching is entirely
outside the scope of what the maintainers will support and by doing so, you
accept that this behaviour may break at any time without notice.
livenessProbe <>
LivenessProbe that will be added CRD pod
logFormat <string>
LogFormat for VMSelect to be configured with. default or json
logLevel <string>
LogLevel for VMSelect to be configured with.
maintenanceInsertNodeIDs <[]integer>
MaintenanceInsertNodeIDs - excludes given node ids from insert requests
routing, must contain pod suffixes - for pod-0, id will be 0 and etc. lets
say, you have pod-0, pod-1, pod-2, pod-3. to exclude pod-0 and pod-3 from
insert routing, define nodeIDs: [0,3]. Useful at storage expanding, when
you want to rebalance some data at cluster.
maintenanceSelectNodeIDs <[]integer>
MaintenanceInsertNodeIDs - excludes given node ids from select requests
routing, must contain pod suffixes - for pod-0, id will be 0 and etc.
name <string>
Name is deprecated and will be removed at 0.22.0 release
nodeSelector <map[string]string>
NodeSelector Define which Nodes the Pods are scheduled on.
podDisruptionBudget <Object>
PodDisruptionBudget created by operator
podMetadata <Object>
PodMetadata configures Labels and Annotations which are propagated to the
VMSelect pods.
port <string>
Port for health check connetions
priorityClassName <string>
Priority class assigned to the Pods
readinessProbe <>
ReadinessProbe that will be added CRD pod
replicaCount <integer> -required-
ReplicaCount is the expected size of the VMStorage cluster. The controller
will eventually make the size of the running cluster equal to the expected
size.
resources <Object>
Resources container resource request and limits,
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
rollingUpdateStrategy <string>
RollingUpdateStrategy defines strategy for application updates Default is
OnDelete, in this case operator handles update process Can be changed for
RollingUpdate
runtimeClassName <string>
RuntimeClassName - defines runtime class for kubernetes pod.
https://kubernetes.io/docs/concepts/containers/runtime-class/
schedulerName <string>
SchedulerName - defines kubernetes scheduler name
secrets <[]string>
Secrets is a list of Secrets in the same namespace as the VMSelect object,
which shall be mounted into the VMSelect Pods. The Secrets are mounted into
/etc/vm/secrets/<secret-name>.
securityContext <>
SecurityContext holds pod-level security attributes and common container
settings. This defaults to the default PodSecurityContext.
serviceScrapeSpec <>
ServiceScrapeSpec that will be added to vmselect VMServiceScrape spec
serviceSpec <Object>
ServiceSpec that will be create additional service for vmstorage
startupProbe <>
StartupProbe that will be added to CRD pod
storage <Object>
Storage - add persistent volume for StorageDataPath its useful for
persistent cache
storageDataPath <string>
StorageDataPath - path to storage data
terminationGracePeriodSeconds <integer>
TerminationGracePeriodSeconds period for container graceful termination
tolerations <[]Object>
Tolerations If specified, the pod's tolerations.
topologySpreadConstraints <[]>
TopologySpreadConstraints embedded kubernetes pod configuration option,
controls how pods are spread across your cluster among failure-domains such
as regions, zones, nodes, and other user-defined topology domains
https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
vmBackup <Object>
VMBackup configuration for backup
vmInsertPort <string>
VMInsertPort for VMInsert connections
vmSelectPort <string>
VMSelectPort for VMSelect connections
volumeMounts <[]Object>
VolumeMounts allows configuration of additional VolumeMounts on the output
Deployment definition. VolumeMounts specified will be appended to other
VolumeMounts in the VMSelect container, that are generated as a result of
StorageSpec objects.
volumes <[]>
Volumes allows configuration of additional volumes on the output Deployment
definition. Volumes specified will be appended to other volumes that are
generated as a result of StorageSpec objects.- 直接应用上面定义的对象:
[root@master1 vm-operator]#kubectl apply -f vmcluster-demo.yaml
vmcluster.operator.victoriametrics.com/vmcluster-demo created
[root@master1 vm-operator]#kubectl get vmcluster
NAME INSERT COUNT STORAGE COUNT SELECT COUNT AGE STATUS
vmcluster-demo 2 2 2 12s expanding- 应用后 vm-operator 会 watch 到我们创建了该 CRD 对象,然后会根据我们的定义去自动创建对应的 VM 集群,也就是前面提到的几个组件服务:
[root@master1 ~]#kubectl get pods 1/1 Running 1 (4h13m ago) 37h
vminsert-vmcluster-demo-886ddfc84-6bnqk 1/1 Running 1 (4h13m ago) 4h23m
vminsert-vmcluster-demo-886ddfc84-899m4 1/1 Running 1 (4h13m ago) 4h23m
vmselect-vmcluster-demo-0 1/1 Running 0 4h23m
vmselect-vmcluster-demo-1 1/1 Running 0 4h23m
vmstorage-vmcluster-demo-0 1/1 Running 0 4h23m
vmstorage-vmcluster-demo-1 1/1 Running 1 (4h13m ago) 4h23m
[root@master1 ~]#kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vminsert-vmcluster-demo ClusterIP 10.106.83.249 <none> 8480/TCP 4h23m
vmselect-vmcluster-demo ClusterIP None <none> 8481/TCP 4h23m
vmstorage-vmcluster-demo ClusterIP None <none> 8482/TCP,8400/TCP,8401/TCP 4h23m我们只通过定义简单的 VMCluster 对象就可以来管理 VM 集群了,是不是非常方便,特别是当你组件副本数量非常多的时候不需要我们去手动配置 -storageNode 参数了。
- 我们这里来验证下
[root@master1 ~]#kubectl get sts vmstorage-vmcluster-demo -o yaml
……
spec:
containers:
- args:
- -dedup.minScrapeInterval=1ms
- -httpListenAddr=:8482
- -retentionPeriod=1w
- -storageDataPath=/vm-data
……
volumeMounts:
- mountPath: /vm-data
name: vmstorage-db
……
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
name: vmstorage-db
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10G
storageClassName: nfs-client
volumeMode: Filesystem
[root@master1 ~]#kubectl get sts vmselect-vmcluster-demo -oyaml
……
spec:
containers:
- args:
- -cacheDataPath=/cache
……
containers:
- args:
- -cacheDataPath=/cache
- -dedup.minScrapeInterval=1ms
- -httpListenAddr=:8481
- -selectNode=vmselect-vmcluster-demo-0.vmselect-vmcluster-demo.default:8481,vmselect-vmcluster-demo-1.vmselect-vmcluster-demo.default:8481
- -storageNode=vmstorage-vmcluster-demo-0.vmstorage-vmcluster-demo.default:8401,vmstorage-vmcluster-demo-1.vmstorage-vmcluster-demo.default:8401
……
volumeMounts:
- mountPath: /cache
name: vmselect-cachedir
……
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
name: vmselect-cachedir
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1G
storageClassName: nfs-client
volumeMode: Filesystem
[root@master1 ~]#kubectl get deploy vminsert-vmcluster-demo -oyaml
……
spec:
containers:
- args:
- -httpListenAddr=:8480
- -replicationFactor=1
- -storageNode=vmstorage-vmcluster-demo-0.vmstorage-vmcluster-demo.default:8400,vmstorage-vmcluster-demo-1.vmstorage-vmcluster-demo.default:84002.创建 VMAgent 对象
- 现在 VM 集群安装成功了,但是现在还没有任何数据,所以还需要去配置监控指标的抓取,这里我们可以直接去创建一个
VMAgent对象即可,创建一个如下所示的对象:
vim vmagent-demo.yaml
# vmagent-demo.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAgent
metadata:
name: vmagent-demo
spec:
serviceScrapeNamespaceSelector: {}
podScrapeNamespaceSelector: {}
podScrapeSelector: {}
serviceScrapeSelector: {}
nodeScrapeSelector: {}
nodeScrapeNamespaceSelector: {}
staticScrapeSelector: {}
staticScrapeNamespaceSelector: {}
replicaCount: 1
remoteWrite:
- url: "http://vminsert-vmcluster-demo.default.svc.cluster.local:8480/insert/0/prometheus/api/v1/write"同样要获取 VMAgent 的所以可配置的属性可以通过 kubectl explain VMAgent.spec 来获取,这里最主要的配置就是通过 remoteWrite.url 来指定远程写入的 URL 地址,也就是 vminsert 组件的服务地址,其他几个属性可以用来对要抓取的指标进行过滤。
- 直接应用上面的
VMAgent对象即可开始抓取监控数据:
[root@master1 vm-operator]#kubectl apply -f vmagent-demo.yaml
vmagent.operator.victoriametrics.com/vmagent-demo created
[root@master1 vm-operator]#kubectl get vmagent
NAME AGE
vmagent-demo 9s创建后 vm-operator 会根据对应的描述创建一个对应的 vmagent 实例:
[root@master1 vm-operator]#kubectl get pods -l app.kubernetes.io/name=vmagent
NAME READY STATUS RESTARTS AGE
vmagent-vmagent-demo-6749f77ffc-x22pf 2/2 Running 0 7m57s
[root@master1 vm-operator]#kubectl get deploy vmagent-vmagent-demo -oyaml
……
spec:
containers:
- args:
- --reload-url=http://localhost:8429/-/reload
- --config-envsubst-file=/etc/vmagent/config_out/vmagent.env.yaml
- --watched-dir=/etc/vm/relabeling
- --config-secret-name=default/vmagent-vmagent-demo
- --config-secret-key=vmagent.yaml.gz
command:
- /usr/local/bin/config-reloader
……
- -httpListenAddr=:8429
- -promscrape.config=/etc/vmagent/config_out/vmagent.env.yaml
- -remoteWrite.maxDiskUsagePerURL=1073741824
- -remoteWrite.tmpDataPath=/tmp/vmagent-remotewrite-data
- -remoteWrite.url=http://vminsert-vmcluster-demo.default.svc.cluster.local:8480/insert/0/prometheus/api/v1/write
image: victoriametrics/vmagent:v1.79.0可以看到 vmagent 有两个容器,一个是 vmagent 应用容器,另外一个是用于挂载 Secret 对象的 config-reloader 容器,它会 watch 配置的变化,并发送信号为 vmagent 重新加载配置,该 Secret 对象中就是定义的 vmagent 抓取指标的配置内容。
3.测试
- 我们可以运行以下命令使
vmagent的端口可以从本地机器上访问。
[root@master1 vm-operator]#kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vmagent-vmagent-demo ClusterIP 10.107.42.160 <none> 8429/TCP 11m
vminsert-vmcluster-demo ClusterIP 10.106.83.249 <none> 8480/TCP 19h
vmselect-vmcluster-demo ClusterIP None <none> 8481/TCP 19h
vmstorage-vmcluster-demo ClusterIP None <none> 8482/TCP,8400/TCP,8401/TCP 19h
[root@master1 vm-operator]#kubectl port-forward svc/vmagent-vmagent-demo 8429:8429
Forwarding from 127.0.0.1:8429 -> 8429
Forwarding from [::1]:8429 -> 8429- 我们可以在浏览器中访问 http://127.0.0.1:8429/targets 来检查
vmagent采集的集群指标:
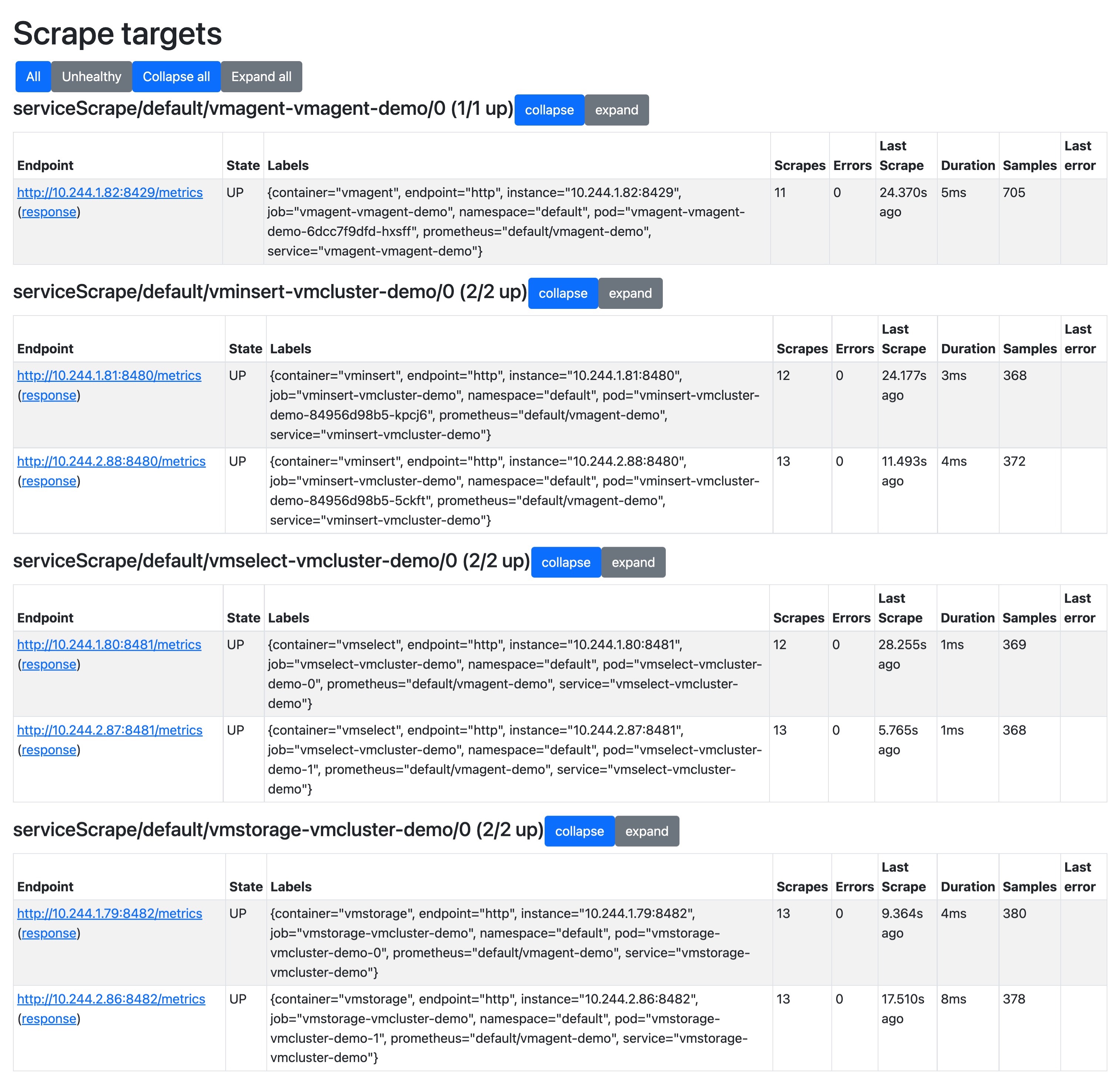
vmagent 会通过 Kubernetes 服务发现去获取需要抓取的目标,此服务发现由 vm-operator 控制。
这里存在个问题:
故障现象:
老师这里执行了kubectl port-forward svc/vmagent-vmagent-demo 8429:8429命令后,都是可以通过http://127.0.0.1:8429/targets正常访问到现象,但是我这里为啥会有问题呢? ,很奇怪……
老师这里的现象:
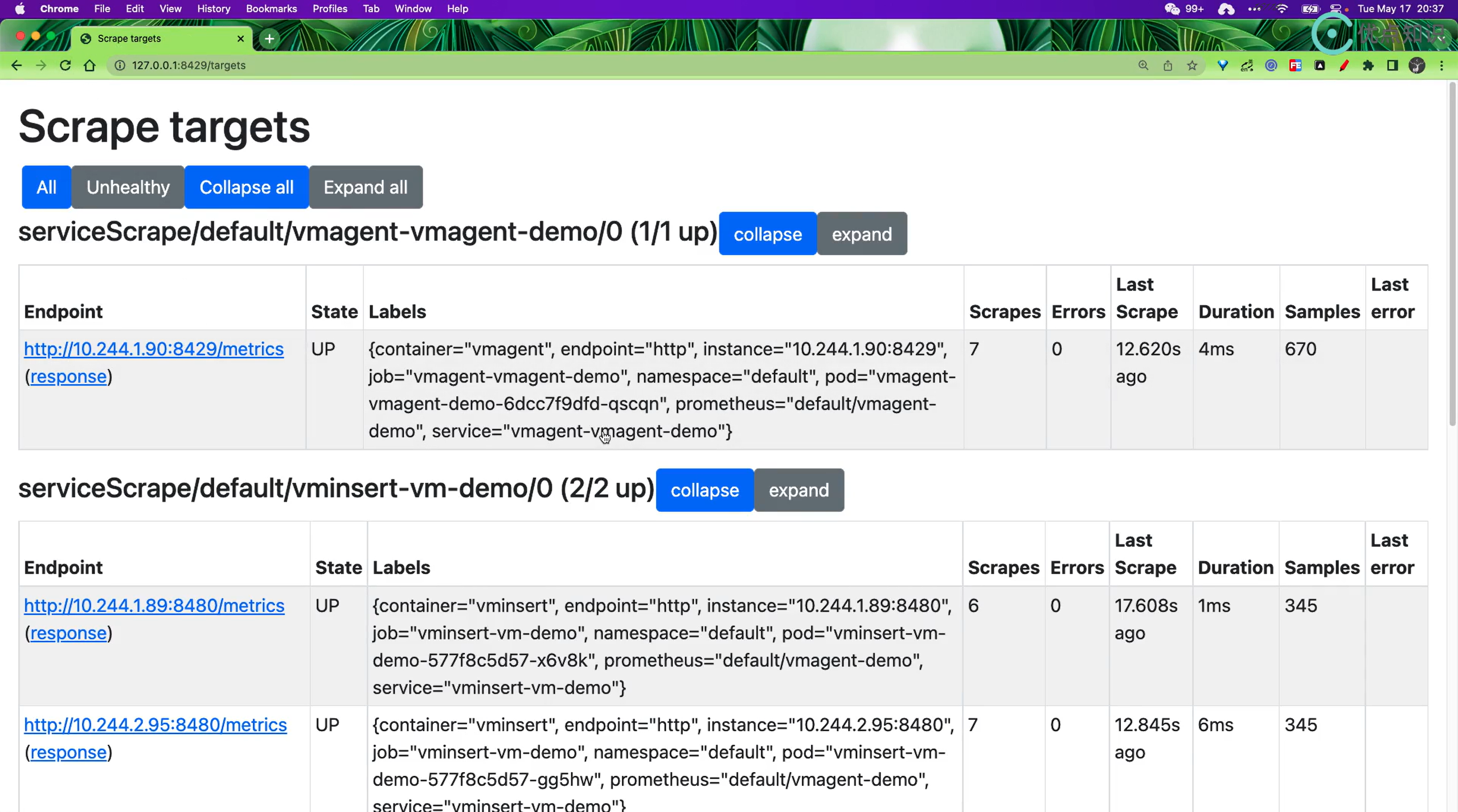
我这里的现象:
127.0.0.1链接访问不行:
但是用curl命令访问就可以,这是为什么呢?
curl http://127.0.0.1:8429/targets
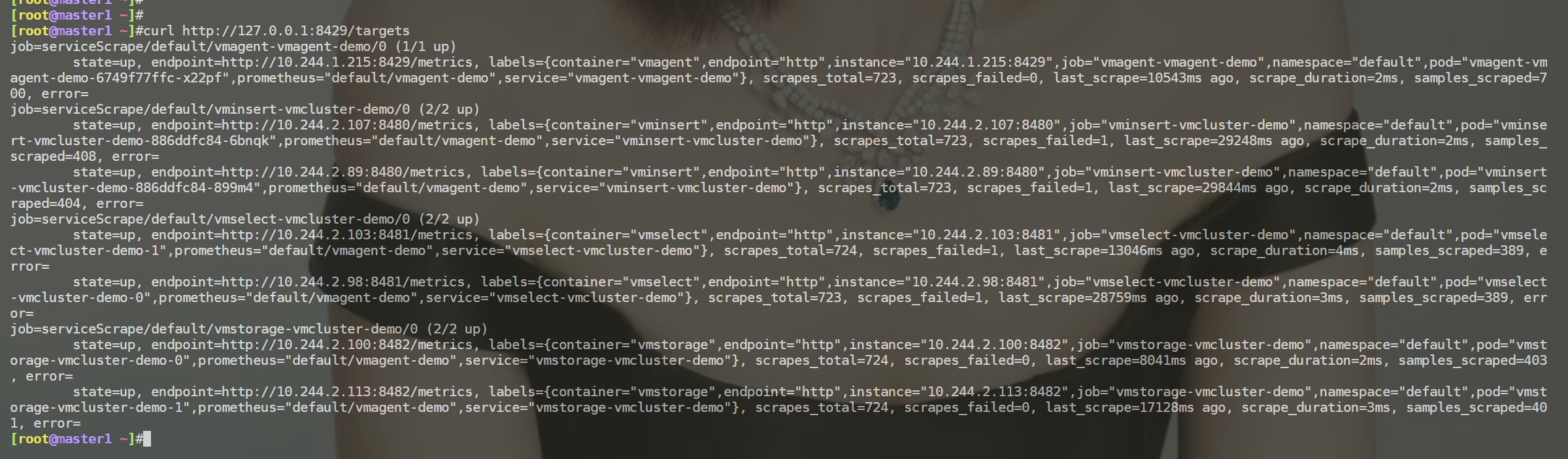
我这里将svc的模式从ClusterIP模式改为NodePort,再次测试下:
[root@master1 vm-operator]#kubectl edit svc vmagent-vmagent-demo
……
type: NodePort
……奇怪呀……这里一直修改完不生效的。。。。(估计是有crd在生效)

这里先暂时搁置吧……。。。。。
难道说老师这个界面也是在虚机那里打开的,也不是呀。。。。应该是在自己的mac上打开的。。。。。
3、验证 VM 集群
1.安装 Grafana
- 接下来我们安装 Grafana 来验证 VM 集群,这里为了简单我们就直接使用 Helm Chart 进行安装:
[root@master1 vm-operator]#helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
[root@master1 vm-operator]#helm repo update- 我们可以在 values 中提前定义数据源和内置一些 dashboard,如下所示:
cat <<EOF | helm install grafana grafana/grafana -f -
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: victoriametrics
type: prometheus
orgId: 1
url: http://vmselect-vmcluster-demo.default.svc.cluster.local:8481/select/0/prometheus/
access: proxy
isDefault: true
updateIntervalSeconds: 10
editable: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
victoriametrics:
gnetId: 11176
revision: 18
datasource: victoriametrics
vmagent:
gnetId: 12683
revision: 7
datasource: victoriametrics
kubernetes:
gnetId: 14205
revision: 1
datasource: victoriametrics
EOF
NAME: grafana
LAST DEPLOYED: Tue May 17 17:13:14 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
######################################################################################################
######## WARNING: Persistence is disabled!!! You will lose your data when ######
######## the Grafana pod is terminated. ######
######################################################################################################
#本次log
W0818 12:14:16.833439 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:16.835043 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:17.014946 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:17.015087 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: grafana
LAST DEPLOYED: Thu Aug 18 12:14:16 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
######################################################################################################
######## WARNING: Persistence is disabled!!! You will lose your data when ######
######## the Grafana pod is terminated. ######
######################################################################################################2.查看victoriametrics cluster 的 dashboard
- 安装完成后可以使用上面提示的命令在本地暴露 Grafana 服务:
☸ ➜ export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000登录的用户名为 admin,密码可以通过下面的命令获取:
[root@master1 ~]#kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
GcVlzxMsneJoa8PDBeDMHHQmUeAfA9zAWRLmAM7i我们可以查看下 victoriametrics cluster 的 dashboard:
127.0.0.1:3000/dashboards
正常可以看到如下所示的页面:
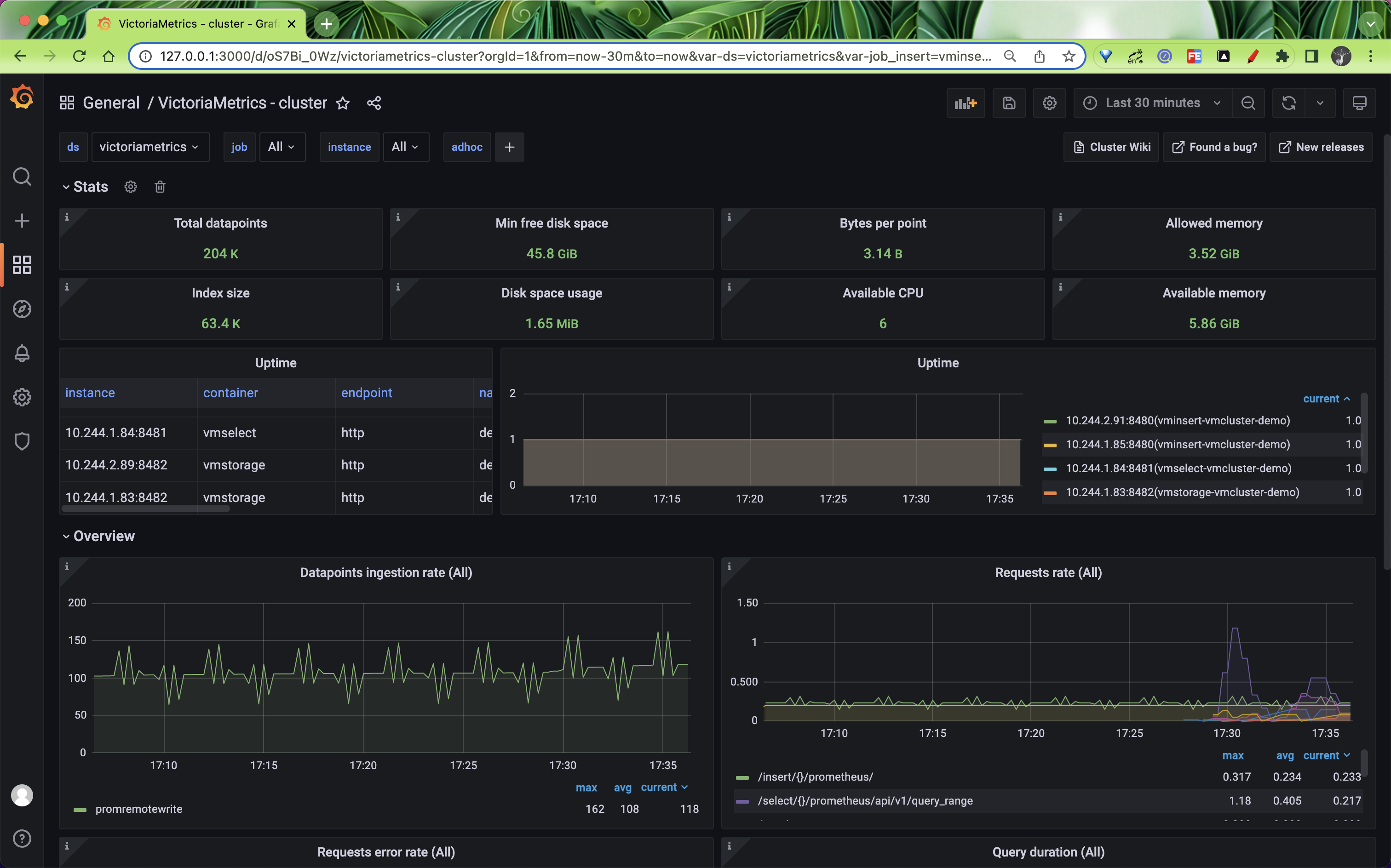
这是因为默认情况下 VMAgent 会采集 VM 集群相关组件的指标,包括 vmagent 本身的,所以我们可以正常看到 VM 集群的 Dashboard。
注意:这里又和之前一样的现象……
利用kubectl --namespace default port-forward $POD_NAME 3000命令后,依然无法在本地用127.0.0.1:3000来访问
于是自己将grafana这个svc的类型变为NodePort,再访问就正常了:
kubectl edit svc grafana
……
type: NodePort
……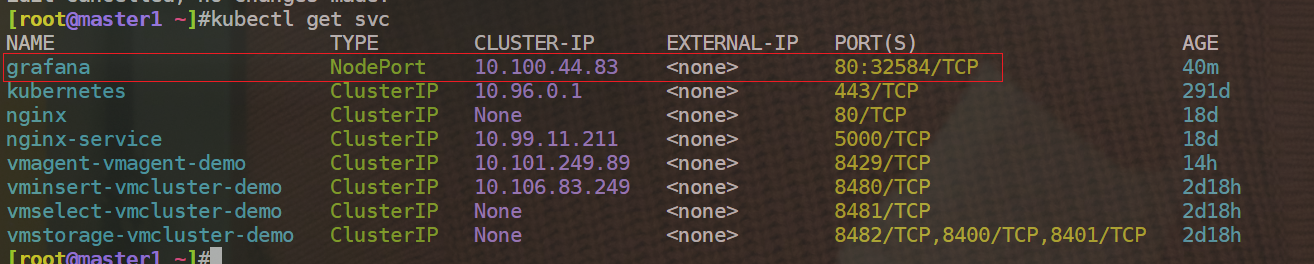
自己本次现象:
3.创建VMNodeScrape 对象
- 但是缺没有采集其他的指标,比如 node-exporter,我们可以在 Grafana 中导入
16098这个 dashboard:
- 这个时候我们可以通过
VMNodeScrape这个 CRD 对象来进行定义,VMNodeScrape对象可以用来自动发现 Kubernetes 节点,创建如下所示的资源对象来采集 node-exporter 指标:
[root@master1 ~]#kubectl get crd|grep victoriametrics
vmagents.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmalertmanagerconfigs.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmalertmanagers.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmalerts.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmauths.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmclusters.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmnodescrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmpodscrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmprobes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmrules.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmservicescrapes.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmsingles.operator.victoriametrics.com 2022-08-15T09:25:21Z
vmstaticscrapes.operator.victoriametrics.com 2022-08-15T09:25:22Z
vmusers.operator.victoriametrics.com 2022-08-15T09:25:21Zvim vmnode-exporter-scrape.yaml
# vmnode-exporter-scrape.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMNodeScrape
metadata:
name: node-exporter
spec:
path: /metrics
port: "9111" # 指定 node-exporter 的端口
scrape_interval: 15s
# relabelConfigs: # relabel配置
# selector: # 过滤节点- 直接应用上面的对象即可:
[root@master1 vm-operator]#kubectl apply -f vmnode-exporter-scrape.yaml
vmnodescrape.operator.victoriametrics.com/node-exporter created
[root@master1 vm-operator]#kubectl get vmnodescrape
NAME AGE
node-exporter 5s- 创建后 vmagent 就会自动去识别该对象去对 node-exporter 进行抓取了:
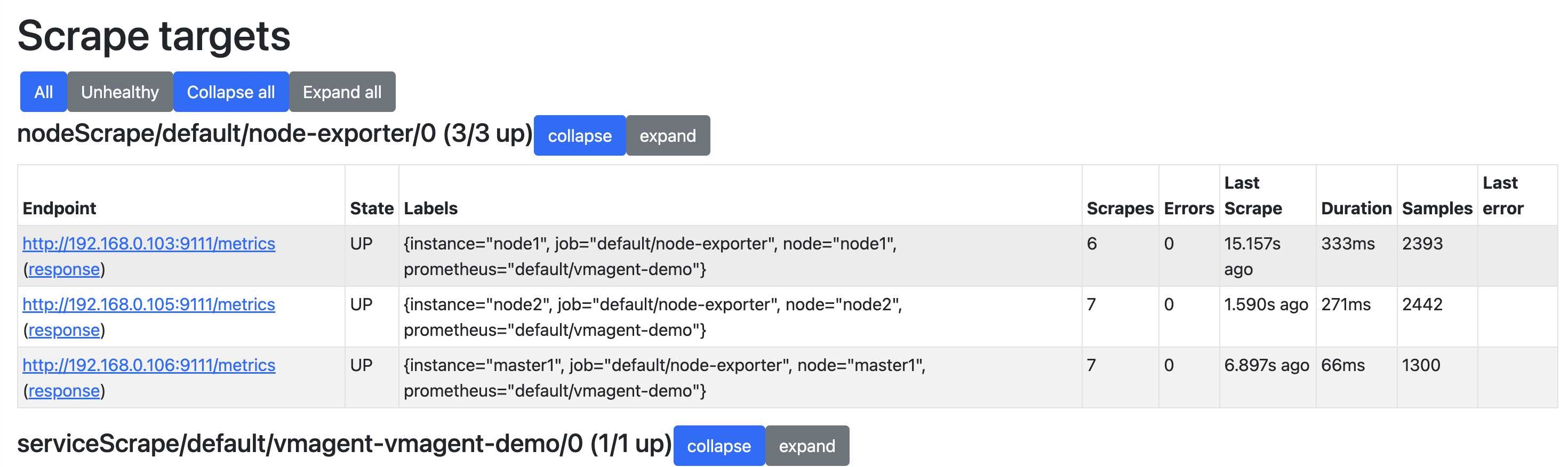
[root@master1 vm-operator]#kubectl port-forward svc/vmagent-vmagent-demo 8429:8429
Forwarding from 127.0.0.1:8429 -> 8429
Forwarding from [::1]:8429 -> 8429
Handling connection for 8429
[root@master1 ~]#curl http://127.0.0.1:8429/targets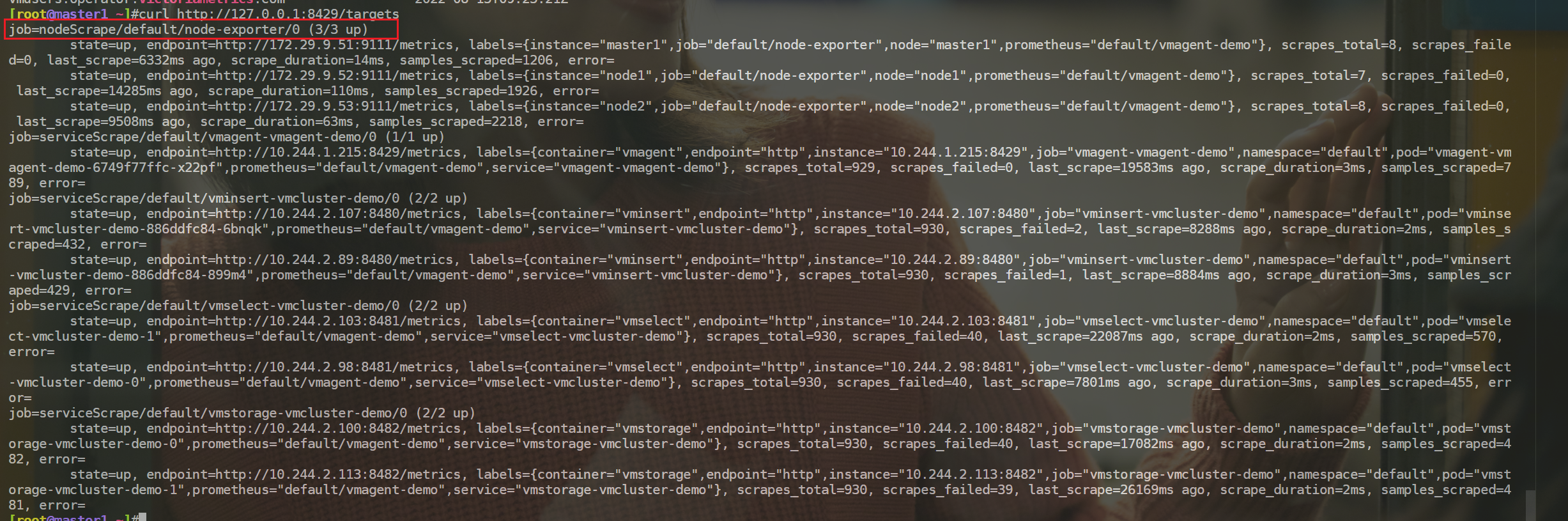
- 这个时候再去查看 node-exporter 的 dashboard 就正常了:
4.抓取其他对象
此外还可以通过 VMServiceScrape 去定义要抓取的 Service 服务(Endpoints),它基于选择器为 vmagent 生成抓取配置,如果想要抓取没有定义 Service 的 Pod 的指标,则可以通过 VMPodScrape 来进行定义,同样还有报警相关的也都有相应的 CRD 来进行管理。
vm-operator 大大降低了我们对 VM 集群的管理,非常推荐使用。
测试结束。😘
FAQ
vm本身就可以去重的,也就不需要通thanos了。
downsample


问题:vm单节点,如何做高可用呢?且数据只有一份?
问题:vm单节点,如何做高可用呢?且数据只有一份?
回答:
一般,对vm单节点,数据是存在云盘上的,而云盘本身对数据是做了高可用的。或者就使用vm集群版。
方法:中间可以加个kafaka
如果有些原因,数据是到不了那里的话,中间可以加个kafaka,这样也是可以支持大规模监控的。
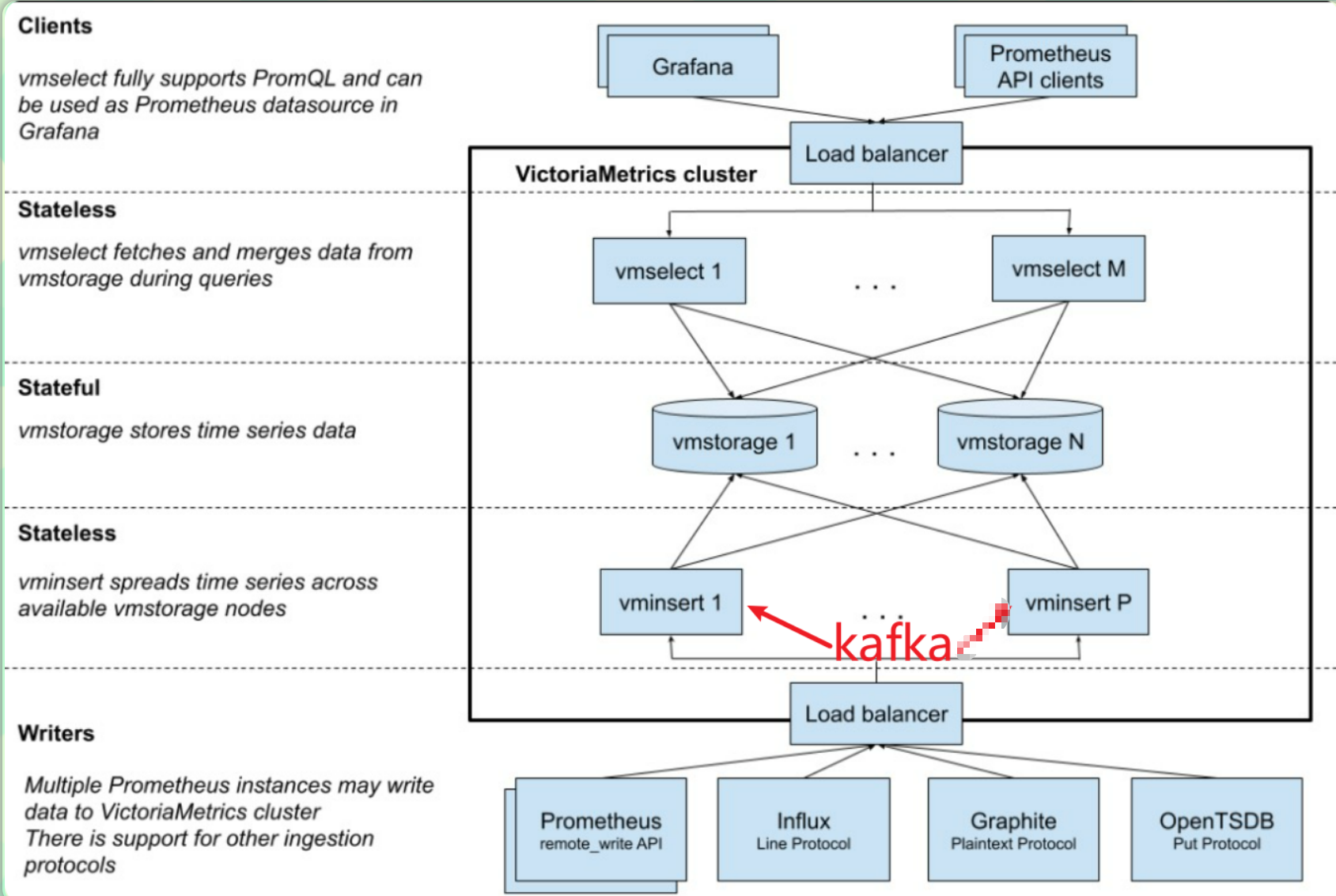
问题:vm稳定性如何?
回答:
vm稳定性没有问题,现在很多大公司把它用在生产环境了。
它现在主要还是在性能上存在一些问题。
它自己本身也会做一些反向索引之类的来提高查询速度,但是在查询索引过程中,这个性能就比较低了,这个是他做索引时可能有的一些问题。
k8s多集群的话,用vm肯定是很方便的。
如果VM把自己的告警模块做的好一些,那么就没有p8s什么事儿了,因为它比p8s要优秀好多的呀。
vm还支持安装方式哦
vm底层存储的原理
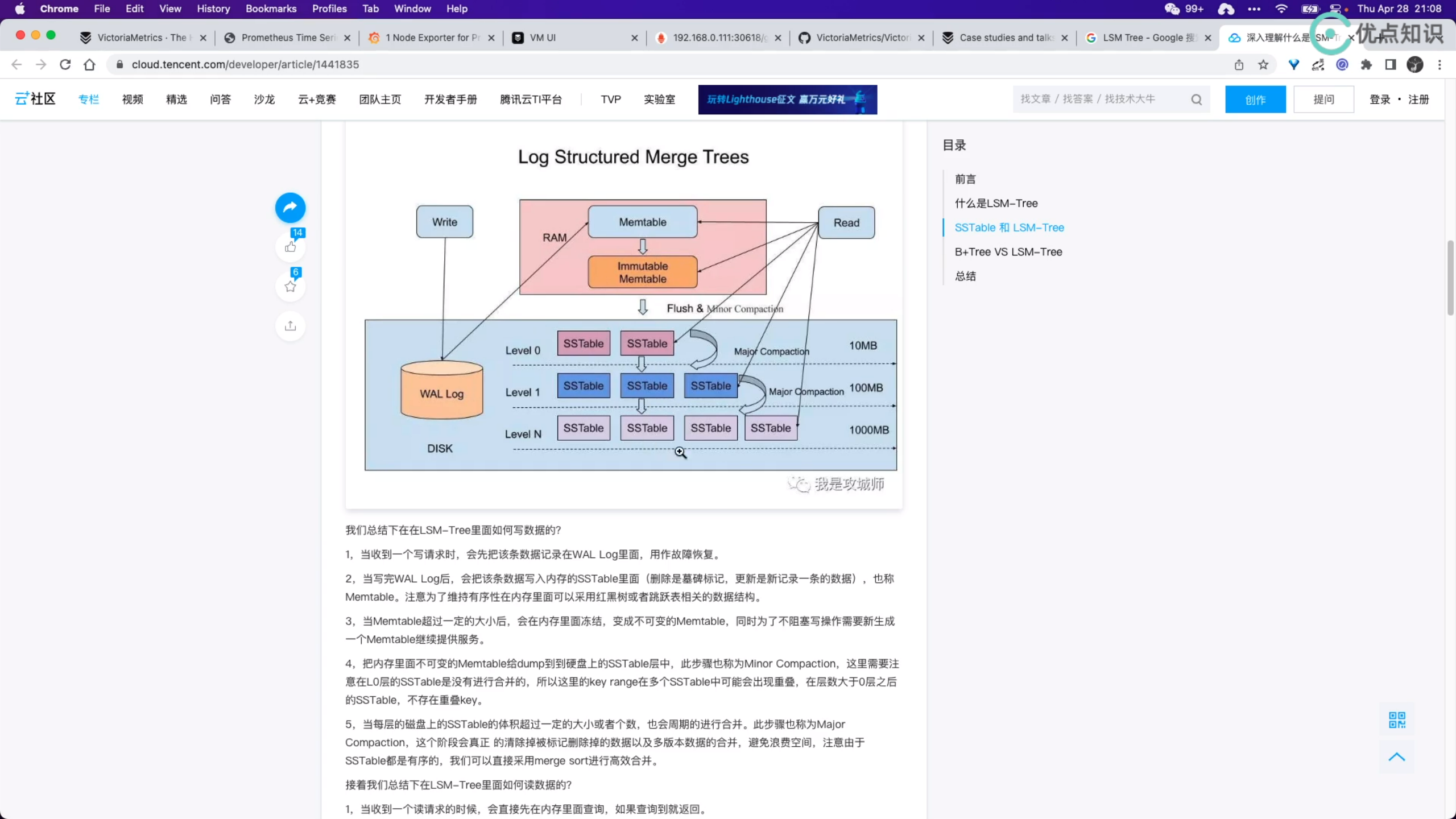
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 博客
🍀 知乎
https://www.zhihu.com/people/foryouone
🍀 语雀
https://www.yuque.com/books/share/34a34d43-b80d-47f7-972e-24a888a8fc5e?# 《云笔记最佳实践》
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!

1