k8s调度器
k8s调度器
目录
[TOC]
前言
实验环境
实验环境:1、win10,vmwrokstation虚机;2、k8s集群:3台centos7.61810虚机,1个master节点,2个node节点k8sversion:v1.22.2containerd:$kubectlgetpoapisix-etcd-0-napisix-oyaml……schedulerName:default-scheduler……#也就是k8s集群默认使用的:$kubectlgetpo-A……kube-systemkube-scheduler-master11/1Running3(27d ago) 108dkube-scheduler的主要作用就是根据特定的调度算法和调度策略将 Pod 调度到合适的 Node 节点上去,是一个独立的二进制程序,启动之后会一直监听 API Server,获取到 **PodSpec.NodeName**为空的 Pod,对每个 Pod 都会创建一个 binding。
这个过程在我们看来好像比较简单,但在实际的生产环境中,需要考虑的问题就有很多了:
- 如何保证全部的节点调度的公平性?要知道并不是所有节点资源配置一定都是一样的
- 如何保证每个节点都能被分配资源?
- 集群资源如何能够被高效利用?
- 集群资源如何才能被最大化使用?
- 如何保证 Pod 调度的性能和效率?(假设说有1w个节点,我是否可以在其中1k个节点上进行筛选呢,这样就可以大幅度提高调度效率了😀)
- 用户是否可以根据自己的实际需求定制自己的调度策略?
🍂 调度主要分为以下几个部分:
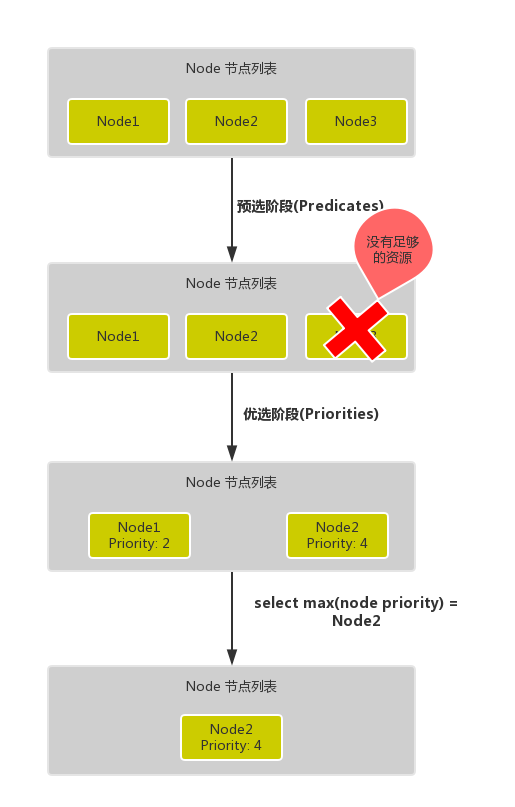
- 首先是预选过程,过滤掉不满足条件的节点,这个过程称为
Predicates(过滤) - 然后是优选过程,对通过的节点按照优先级排序,称之为
Priorities(打分) - 最后从中选择优先级最高的节点,如果中间任何一步骤有错误,就直接返回错误
Predicates阶段首先遍历全部节点,过滤掉不满足条件的节点,属于强制性规则,这一阶段输出的所有满足要求的节点将被记录并作为第二阶段的输入,如果所有的节点都不满足条件,那么 Pod 将会一直处于 Pending 状态,直到有节点满足条件,在这期间调度器会不断的重试。
所以我们在部署应用的时候,如果发现有 Pod 一直处于 Pending 状态,那么就是没有满足调度条件的节点,这个时候可以去检查下节点资源是否可用。
Priorities阶段即再次对节点进行筛选,如果有多个节点都满足条件的话,那么系统会按照节点的优先级(priorites)大小对节点进行排序,最后选择优先级最高的节点来部署 Pod 应用。
01、如果你的pod处于pending状态,那么一定就是调度器出现了问题,那么原因会很多,有可能是你的node资源不足,有可能是你的节点已经被占用了……(因此需要使用kubectl describle pod xxx来查看原因)
02、所谓的bing操作就是如下: $ kubectl get po apisix-etcd-0 -napisix -oyaml …… nodeName:node2 #将pod的配置清单的nodeName字段补充完成。 ……
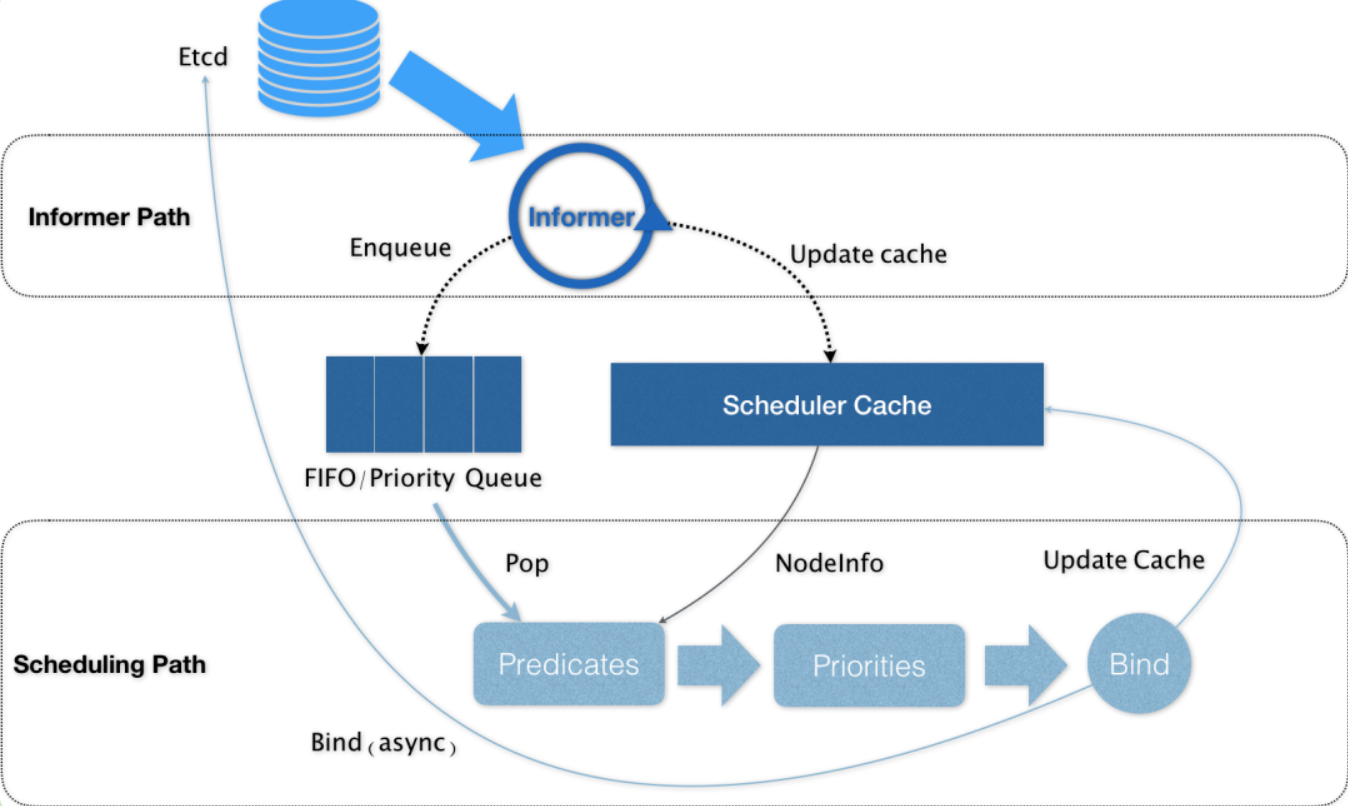
🍂 下面是调度过程的简单示意图:
更详细的流程是这样的:
- 首先,客户端通过 API Server 的 REST API 或者 kubectl 工具创建 Pod 资源
- API Server 收到用户请求后,存储相关数据到 etcd 数据库中
- 调度器监听 API Server 查看到还未被调度(bind)的 Pod 列表,循环遍历地为每个 Pod 尝试分配节点,这个分配过程就是我们上面提到的两个阶段:
- 预选阶段(Predicates),过滤节点,调度器用一组规则过滤掉不符合要求的 Node 节点,比如 Pod 设置了资源的 request,那么可用资源比 Pod 需要的资源少的主机显然就会被过滤掉。
- 优选阶段(Priorities),为节点的优先级打分,将上一阶段过滤出来的 Node 列表进行打分,调度器会考虑一些整体的优化策略,比如把 Deployment 控制的多个 Pod 副本尽量分布到不同的主机上,使用最低负载的主机等等策略。
- 经过上面的阶段过滤后选择打分最高的 Node 节点和 Pod 进行
binding操作,然后将结果存储到 etcd 中, 最后被选择出来的 Node 节点对应的 kubelet 去执行创建 Pod 的相关操作(当然也是 watch APIServer 发现的)。
🍂 Predicates plugin工作原理
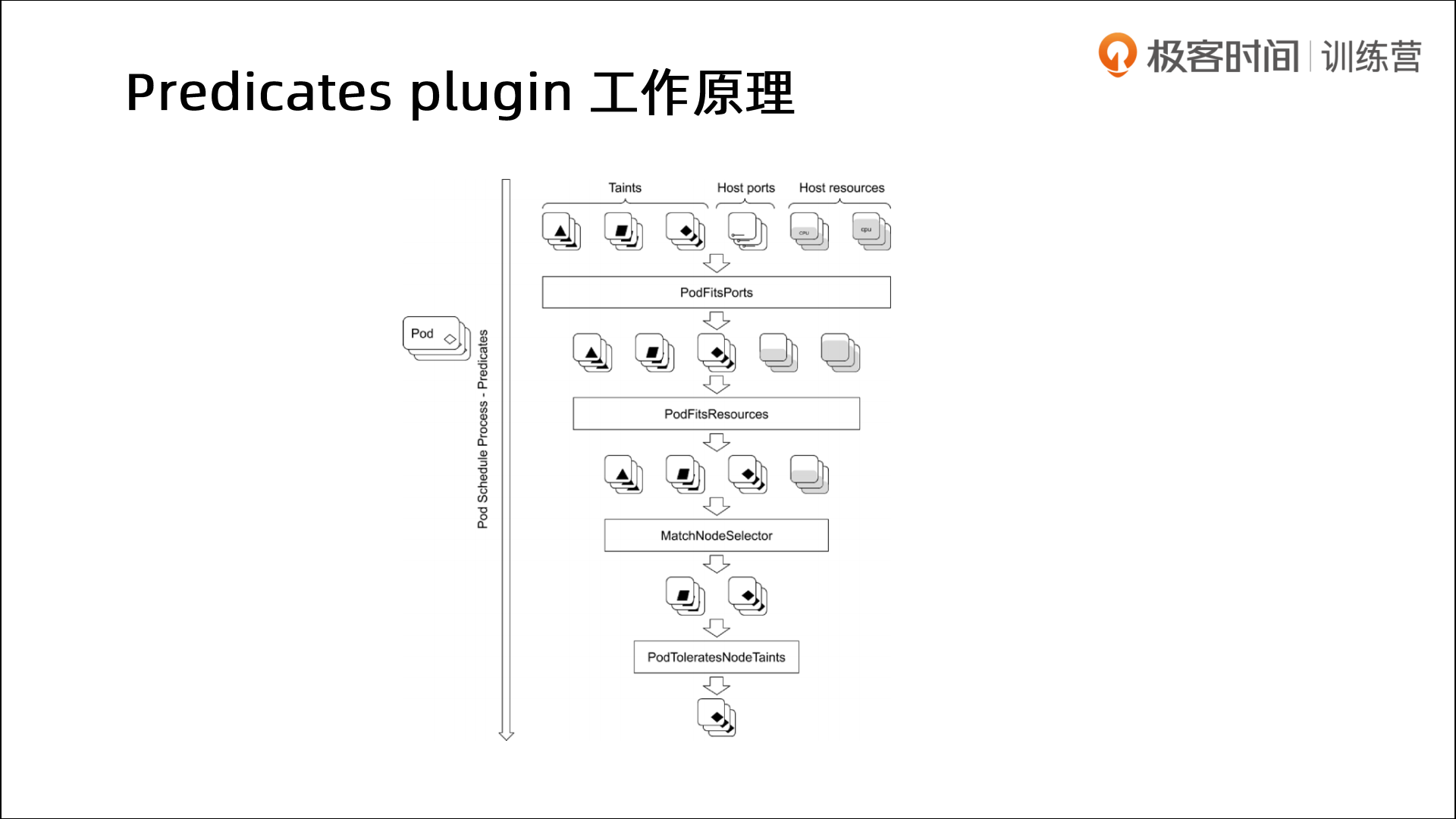 链式过滤器
链式过滤器
🍂 调度插件
 LeastAllocated:空闲资源多的分高 --使的node上的负载比较合理一点! MostAllocated:空闲资源少的分高 -- 可以退回Node资源!
LeastAllocated:空闲资源多的分高 --使的node上的负载比较合理一点! MostAllocated:空闲资源少的分高 -- 可以退回Node资源!
🍀 最简单的Scheduler实现
 k8s 0.2版本的一个架构图,基本调度方式就是随机,轮询会稍微复杂一些;
k8s 0.2版本的一个架构图,基本调度方式就是随机,轮询会稍微复杂一些;
随机 
2.扩展调度器(extender)
包括很多时候,默认的调度器已经不能满足业务需求,需要对它做自定义的扩展和实现,具体该怎么做,背后的原理又是什么样的,业界有没有优秀案例可供参考,这些都是非常令人头疼的问题。(extender本身就是一个拉低性能的因素。)


🍂 考虑到实际环境中的各种复杂情况,kubernetes 的调度器采用插件化的形式实现,可以方便用户进行定制或者二次开发,我们可以自定义一个调度器并以插件形式和 kubernetes 进行集成。
开发人员注意即可:
kubernetes 调度器的源码位于
kubernetes/pkg/scheduler中,其中 Scheduler 创建和运行的核心程序,对应的代码在pkg/scheduler/scheduler.go,如果要查看kube-scheduler的入口程序,对应的代码在cmd/kube-scheduler/scheduler.go。
从上面我们可以看出调度器的一系列算法由各种插件在调度的不同阶段来完成,下面我们就先来了解下调度框架。
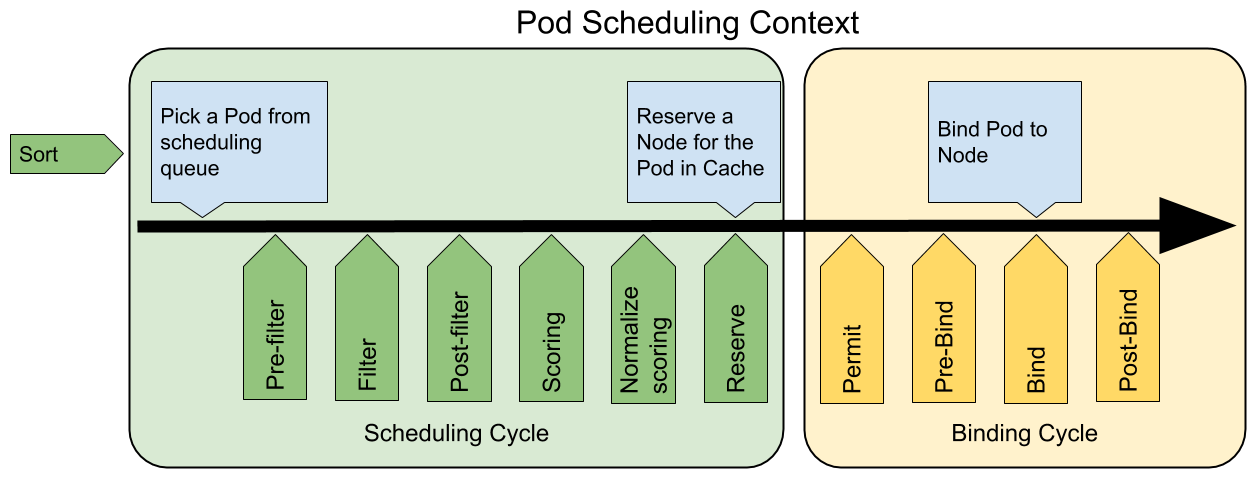
调度框架定义了一组扩展点,用户可以实现扩展点定义的接口来定义自己的调度逻辑(我们称之为扩展),并将扩展注册到扩展点上,调度框架在执行调度工作流时,遇到对应的扩展点时,将调用用户注册的扩展。调度框架在预留扩展点时,都是有特定的目的,有些扩展点上的扩展可以改变调度程序的决策方法,有些扩展点上的扩展只是发送一个通知。
我们知道每当调度一个 Pod 时,都会按照两个过程来执行:调度过程和绑定过程。
调度过程为 Pod 选择一个合适的节点,绑定过程则将调度过程的决策应用到集群中(也就是在被选定的节点上运行 Pod),将调度过程和绑定过程合在一起,称之为调度上下文(scheduling context)。需要注意的是调度过程是**同步**运行的(同一时间点只为一个 Pod 进行调度),绑定过程可异步运行(同一时间点可并发为多个 Pod 执行绑定)。
调度过程和绑定过程遇到如下情况时会中途退出:
- 调度程序认为当前没有该 Pod 的可选节点
- 内部错误
这个时候,该 Pod 将被放回到 待调度队列,并等待下次重试。
1.扩展点(Extension Points)
下图展示了调度框架中的调度上下文及其中的扩展点,一个扩展可以注册多个扩展点,以便可以执行更复杂的有状态的任务。
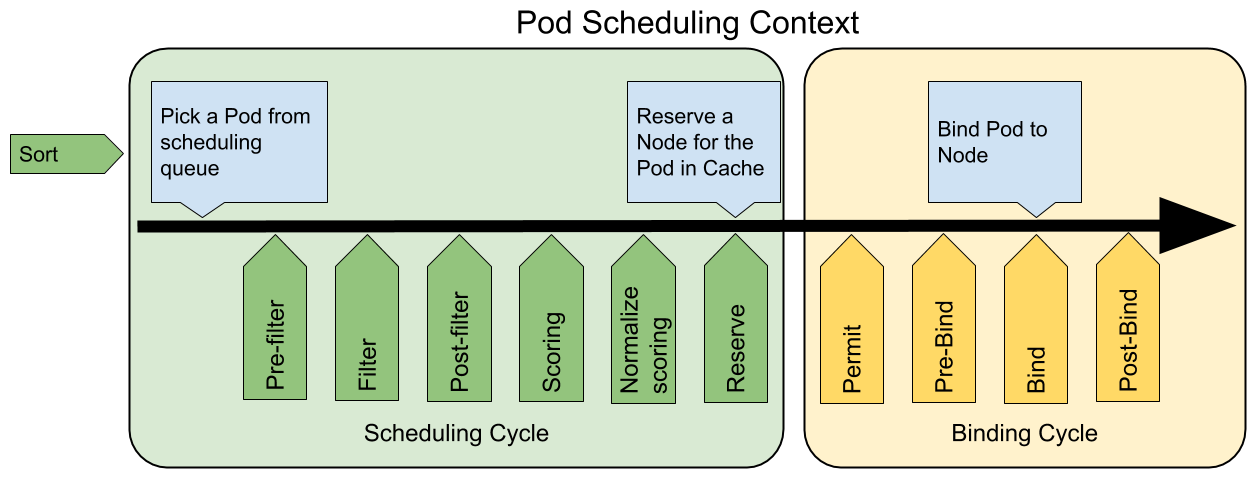
调度阶段: 1.predicate(预选): 2.priority/score(优选): 绑定阶段:
🍂 详细过程:
QueueSort扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,QueueSort扩展本质上只需要实现一个方法Less(Pod1,Pod2)用于比较两个 Pod 谁更优先获得调度即可,同一时间点只能有一个QueueSort插件生效。Pre-filter扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,如果pre-filter返回了 error,则调度过程终止。Filter扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器将按顺序执行filter扩展;如果任何一个filter将节点标记为不可选,则余下的filter扩展将不会被执行。调度器可以同时对多个节点执行**filter**扩展。Post-filter是一个通知类型的扩展点,调用该扩展的参数是filter阶段结束后被筛选为可选节点的节点列表,可以在扩展中使用这些信息更新内部状态,或者产生日志或 metrics 信息。Scoring扩展用于为所有可选节点进行打分,调度器将针对每一个节点调用Soring扩展,评分结果是一个范围内的整数。在normalize scoring阶段,调度器将会把每个scoring扩展对具体某个节点的评分结果和该扩展的权重合并起来,作为最终评分结果。Normalize scoring扩展在调度器对节点进行最终排序之前修改每个节点的评分结果,注册到该扩展点的扩展在被调用时,将获得同一个插件中的scoring扩展的评分结果作为参数,调度框架每执行一次调度,都将调用所有插件中的一个normalize scoring扩展一次。Reserve是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用资源超出可用资源的情况(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。Permit扩展用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:- approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程
- deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发
Unreserve扩展。 - wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
Pre-bind扩展用于在 Pod 绑定之前执行某些逻辑。例如,pre-bind 扩展可以将一个基于网络的数据卷挂载到节点上,以便 Pod 可以使用。如果任何一个pre-bind扩展返回错误,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展。Bind扩展用于将 Pod 绑定到节点上:
- 只有所有的 pre-bind 扩展都成功执行了,bind 扩展才会执行
- 调度框架按照 bind 扩展注册的顺序逐个调用 bind 扩展
- 具体某个 bind 扩展可以选择处理或者不处理该 Pod
- 如果某个 bind 扩展处理了该 Pod 与节点的绑定,余下的 bind 扩展将被忽略
Post-bind是一个通知性质的扩展:
- Post-bind 扩展在 Pod 成功绑定到节点上之后被动调用
- Post-bind 扩展是绑定过程的最后一个步骤,可以用来执行资源清理的动作
Unreserve是一个通知性质的扩展,如果为 Pod 预留了资源,Pod 又在被绑定过程中被拒绝绑定,则 unreserve 扩展将被调用。Unreserve 扩展应该释放已经为 Pod 预留的节点上的计算资源。在一个插件中,reserve 扩展和 unreserve 扩展应该成对出现。
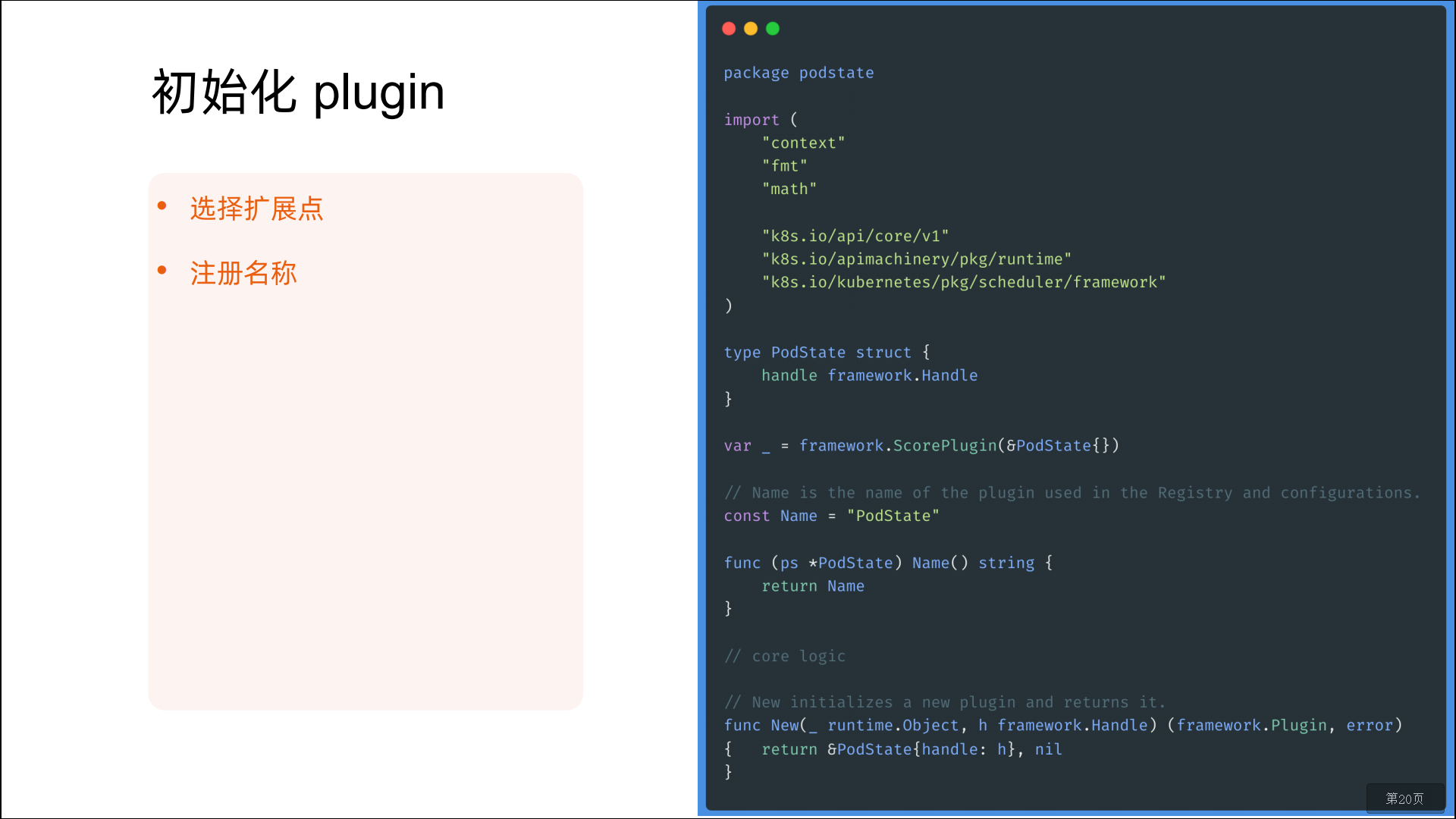
🍂 如果我们要实现自己的插件,必须向调度框架注册插件并完成配置,另外还必须实现扩展点接口,对应的扩展点接口我们可以在源码 pkg/scheduler/framework/v1alpha1/interface.go文件中找到,如下所示:
typePlugininterface{Name() string}typeQueueSortPlugininterface{PluginLess(*PodInfo,*PodInfo) bool}typePreFilterPlugininterface{PluginPreFilter(pc*PluginContext,p*v1.Pod) *Status}typeFilterPlugininterface{PluginFilter(pc*PluginContext,pod*v1.Pod,nodeNamestring) *Status}typePostFilterPlugininterface{PluginPostFilter(pc*PluginContext,pod*v1.Pod,nodes[]*v1.Node,filteredNodesStatusesNodeToStatusMap) *Status}typeScorePlugininterface{PluginScore(pc*PluginContext,p*v1.Pod,nodeNamestring) (int,*Status)}typeScoreWithNormalizePlugininterface{ScorePluginNormalizeScore(pc*PluginContext,p*v1.Pod,scoresNodeScoreList) *Status}typeReservePlugininterface{PluginReserve(pc*PluginContext,p*v1.Pod,nodeNamestring) *Status}typePreBindPlugininterface{PluginPreBind(pc*PluginContext,p*v1.Pod,nodeNamestring) *Status}typePostBindPlugininterface{PluginPostBind(pc*PluginContext,p*v1.Pod,nodeNamestring)}typeUnreservePlugininterface{PluginUnreserve(pc*PluginContext,p*v1.Pod,nodeNamestring)}typePermitPlugininterface{PluginPermit(pc*PluginContext,p*v1.Pod,nodeNamestring) (*Status,time.Duration)}typeBindPlugininterface{PluginBind(pc*PluginContext,p*v1.Pod,nodeNamestring) *Status}🍂 对于调度框架插件的启用或者禁用,我们可以使用安装集群时的 KubeSchedulerConfiguration资源对象来进行配置。下面的例子中的配置启用了一个实现了 reserve和 preBind扩展点的插件,并且禁用了另外一个插件,同时为插件 foo 提供了一些配置信息:
apiVersion:kubescheduler.config.k8s.io/v1alpha1kind:KubeSchedulerConfiguration...plugins:reserve:enabled:- name:foo- name:bardisabled:- name:bazpreBind:enabled:- name:foodisabled:- name:bazpluginConfig:- name:fooargs:>foo插件可以解析的任意内容🍂 扩展的调用顺序如下:
- 如果某个扩展点没有配置对应的扩展,调度框架将使用默认插件中的扩展
- 如果为某个扩展点配置且激活了扩展,则调度框架将先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照
KubeSchedulerConfiguration中扩展的激活enabled顺序逐个调用扩展点的扩展 - 可以先禁用默认插件的扩展,然后在
enabled列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
假设默认插件 foo 实现了 reserve扩展点,此时我们要添加一个插件 bar,想要在 foo 之前被调用,则应该先禁用 foo 再按照 bar foo 的顺序激活。示例配置如下所示:
apiVersion:kubescheduler.config.k8s.io/v1beta1kind:KubeSchedulerConfiguration...plugins:reserve:enabled:- name:bar- name:foodisabled:- name:foo在源码目录 pkg/scheduler/framework/plugins/examples中有几个示范插件,我们可以参照其实现方式。
2.示例(代码部分)
因为涉及到代码部分,本次这里不做演示,看下就好。
其实要实现一个调度框架的插件,并不难,我们只要实现对应的扩展点,然后将插件注册到调度器中即可,下面是默认调度器在初始化的时候注册的插件:
funcNewRegistry() Registry{returnRegistry{}}但是可以看到默认并没有注册一些插件,所以要想让调度器能够识别我们的插件代码,就需要自己来实现一个调度器了,当然这个调度器我们完全没必要完全自己实现,直接调用默认的调度器,然后在上面的 NewRegistry()函数中将我们的插件注册进去即可。在 kube-scheduler的源码文件 kubernetes/cmd/kube-scheduler/app/server.go中有一个 NewSchedulerCommand入口函数,其中的参数是一个类型为 Option的列表,而这个 Option恰好就是一个插件配置的定义:
typeOptionfunc(framework.Registry) errorfuncNewSchedulerCommand(registryOptions...Option) *cobra.Command{......}所以我们完全就可以直接调用这个函数来作为我们的函数入口,并且传入我们自己实现的插件作为参数即可,而且该文件下面还有一个名为 WithPlugin的函数可以来创建一个 Option实例:
funcWithPlugin(namestring,factoryframework.PluginFactory) Option{returnfunc(registryframework.Registry) error{returnregistry.Register(name,factory)}}所以最终我们的入口函数如下所示:
funcmain() {rand.Seed(time.Now().UTC().UnixNano())command :=app.NewSchedulerCommand(app.WithPlugin(sample.Name,sample.New),)logs.InitLogs()deferlogs.FlushLogs()iferr :=command.Execute();err !=nil{_,_ =fmt.Fprintf(os.Stderr,"%v\n",err)os.Exit(1)}}其中 app.WithPlugin(sample.Name,sample.New)就是我们接下来要实现的插件,从 WithPlugin函数的参数也可以看出我们这里的 sample.New必须是一个 framework.PluginFactory类型的值,而 PluginFactory的定义就是一个函数:
type PluginFactory =func(configuration *runtime.Unknown,f FrameworkHandle) (Plugin,error)所以 sample.New实际上就是上面的这个函数,在这个函数中我们可以获取到插件中的一些数据然后进行逻辑处理即可,插件实现如下所示,我们这里只是简单获取下数据打印日志,如果你有实际需求的可以根据获取的数据就行处理即可,我们这里只是实现了 PreFilter、Filter、PreBind三个扩展点,其他的可以用同样的方式来扩展即可:
constName="sample-plugin"typeArgsstruct{FavoriteColor string`json:"favorite_color,omitempty"`FavoriteNumber int`json:"favorite_number,omitempty"`ThanksTo string`json:"thanks_to,omitempty"`}typeSamplestruct{args *Argshandle framework.FrameworkHandle}func(s *Sample) Name() string{returnName}func(s *Sample) PreFilter(pc*framework.PluginContext,pod*v1.Pod) *framework.Status{klog.V(3).Infof("prefilter pod:%v",pod.Name)returnframework.NewStatus(framework.Success,"")}func(s *Sample) Filter(pc*framework.PluginContext,pod*v1.Pod,nodeNamestring) *framework.Status{klog.V(3).Infof("filter pod:%v,node:%v",pod.Name,nodeName)returnframework.NewStatus(framework.Success,"")}func(s *Sample) PreBind(pc*framework.PluginContext,pod*v1.Pod,nodeNamestring) *framework.Status{ifnodeInfo,ok :=s.handle.NodeInfoSnapshot().NodeInfoMap[nodeName];!ok {returnframework.NewStatus(framework.Error,fmt.Sprintf("prebind get node info error:%+v",nodeName))} else{klog.V(3).Infof("prebind node info:%+v",nodeInfo.Node())returnframework.NewStatus(framework.Success,"")}}funcNew(configuration*runtime.Unknown,fframework.FrameworkHandle) (framework.Plugin,error) {args :=&Args{}iferr :=framework.DecodeInto(configuration,args);err !=nil{returnnil,err}klog.V(3).Infof("get plugin config args:%+v",args)return&Sample{args:args,handle:f,},nil}直接部署上面的资源对象即可,这样我们就部署了一个名为 sample-scheduler的调度器了,接下来我们可以部署一个应用来使用这个调度器进行调度:
apiVersion:apps/v1kind:Deploymentmetadata:name:test-schedulerspec:selector:matchLabels:app:test-schedulertemplate:metadata:labels:app:test-schedulerspec:schedulerName:sample-scheduler# 指定使用的调度器,不指定使用默认的default-schedulercontainers:- image:nginx:1.7.9imagePullPolicy:IfNotPresentname:nginxports:- containerPort:80这里需要注意的是我们现在手动指定了一个 schedulerName的字段,将其设置成上面我们自定义的调度器名称 sample-scheduler。
我们直接创建这个资源对象,创建完成后查看我们自定义调度器的日志信息:
➜kubectlgetpods-nkube-system-lcomponent=sample-schedulerNAMEREADYSTATUSRESTARTSAGEsample-scheduler-896658cd7-k7vcl1/1Running057s➜kubectllogs-fsample-scheduler-896658cd7-k7vcl-nkube-systemI011409:14:18.8786131eventhandlers.go:173]addeventforunscheduledpoddefault/test-scheduler-6486fd49fc-zjhcxI011409:14:18.8786701scheduler.go:464]Attemptingtoschedulepod:default/test-scheduler-6486fd49fc-zjhcxI011409:14:18.8787061sample.go:77]"Start PreFilter Pod"pod="test-scheduler-6486fd49fc-zjhcx"I011409:14:18.8788021sample.go:93]"Start Filter Pod"pod="test-scheduler-6486fd49fc-zjhcx"node="node2"preFilterState=&{Resource:{MilliCPU:0 Memory:0 EphemeralStorage:0 AllowedPodNumber:0 ScalarResources:map[]}}I011409:14:18.8788351sample.go:93]"Start Filter Pod"pod="test-scheduler-6486fd49fc-zjhcx"node="node1"preFilterState=&{Resource:{MilliCPU:0 Memory:0 EphemeralStorage:0 AllowedPodNumber:0 ScalarResources:map[]}}I011409:14:18.8790431default_binder.go:51]Attemptingtobinddefault/test-scheduler-6486fd49fc-zjhcxtonode1I011409:14:18.8863601scheduler.go:609]"Successfully bound pod to node"pod="default/test-scheduler-6486fd49fc-zjhcx"node="node1"evaluatedNodes=3feasibleNodes=2I011409:14:18.8874261eventhandlers.go:205]deleteeventforunscheduledpoddefault/test-scheduler-6486fd49fc-zjhcxI011409:14:18.8874751eventhandlers.go:225]addeventforscheduledpoddefault/test-scheduler-6486fd49fc-zjhcx可以看到当我们创建完 Pod 后,在我们自定义的调度器中就出现了对应的日志,并且在我们定义的扩展点上面都出现了对应的日志,证明我们的示例成功了,也可以通过查看 Pod 的 schedulerName来验证:
➜kubectlgetpodsNAMEREADYSTATUSRESTARTSAGEtest-scheduler-6486fd49fc-zjhcx1/1Running035s➜kubectlgetpodtest-scheduler-6486fd49fc-zjhcx-oyaml......restartPolicy:AlwaysschedulerName:sample-schedulersecurityContext:{}serviceAccount:default......从 Kubernetes v1.17 版本开始,Scheduler Framework内置的预选和优选函数已经全部插件化,所以要扩展调度器我们应该掌握并理解调度框架这种方式。
2、调度器调优
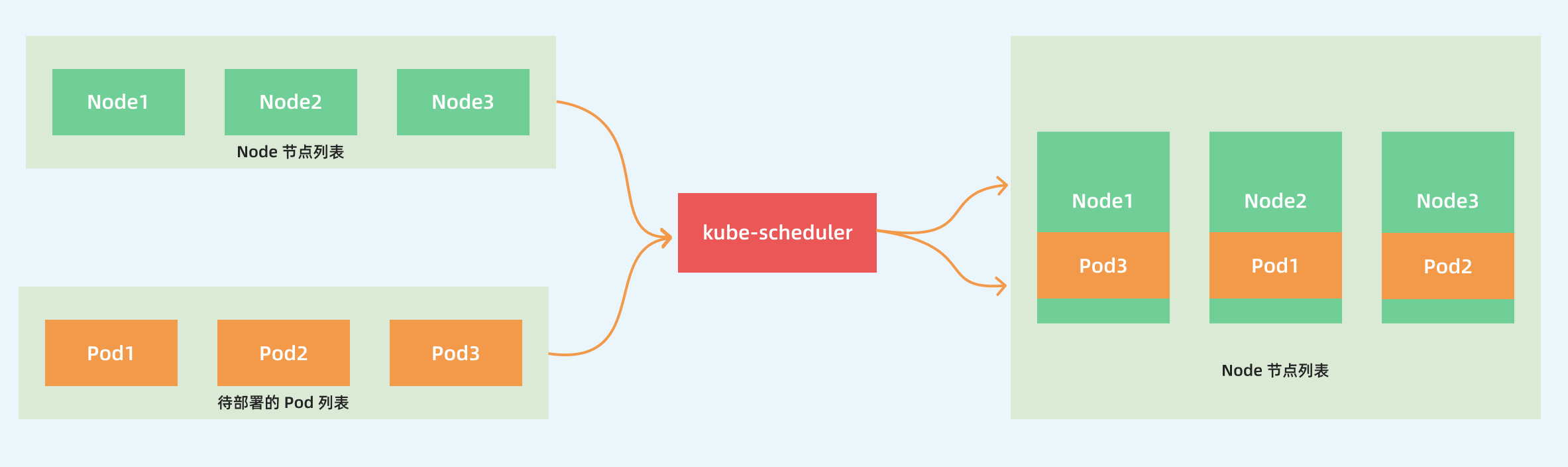
作为 kubernetes 集群的默认调度器,kube-scheduler 主要负责将 Pod 调度到集群的 Node 上。在一个集群中,满足一个 Pod 调度请求的所有节点称之为 可调度 Node,调度器先在集群中找到一个 Pod 的可调度 Node,然后根据一系列函数对这些可调度 Node 进行打分,之后选出其中得分最高的 Node 来运行 Pod,最后,调度器将这个调度决定告知 kube-apiserver,这个过程叫做绑定。
在 Kubernetes 1.12 版本之前,kube-scheduler 会检查集群中所有节点的可调度性,并且给可调度节点打分。Kubernetes 1.12 版本添加了一个新的功能,允许调度器在找到一定数量的可调度节点之后就停止继续寻找可调度节点。该功能能提高调度器在大规模集群下的调度性能,这个数值是集群规模的百分比,这个百分比通过 percentageOfNodesToScore参数来进行配置,其值的范围在 1 到 100 之间,最大值就是 100%,如果设置为 0 就代表没有提供这个参数配置。
Kubernetes 1.14 版本又加入了一个特性,在该参数没有被用户配置的情况下,调度器会根据集群的规模自动设置一个集群比例,然后通过这个比例筛选一定数量的可调度节点进入打分阶段。该特性使用线性公式计算出集群比例,比如100个节点的集群下会取 50%,在 5000节点的集群下取 10%,这个自动设置的参数的最低值是 5%,换句话说,调度器至少会对集群中 5% 的节点进行打分,除非用户将该参数设置的低于 5。
注意
当集群中的可调度节点少于 50 个时,调度器仍然会去检查所有节点,因为可调度节点太少,不足以停止调度器最初的过滤选择。如果我们想要关掉这个范围参数,可以将
percentageOfNodesToScore值设置成 100。
percentageOfNodesToScore的值必须在 1 到 100 之间,而且其默认值是通过集群的规模计算得来的,另外 50个 Node 的数值是硬编码在程序里面的,设置这个值的作用在于:当集群的规模是数百个节点并且 percentageOfNodesToScore 参数设置的过低的时候,调度器筛选到的可调度节点数目基本不会受到该参数影响。当集群规模较小时,这个设置对调度器性能提升并不明显,但是在超过 1000 个 Node 的集群中,将调优参数设置为一个较低的值可以很明显的提升调度器性能。
不过值得注意的是,该参数设置后可能会导致只有集群中少数节点被选为可调度节点,很多 Node 都没有进入到打分阶段,这样就会造成一种后果,一个本来可以在打分阶段得分很高的 Node 甚至都不能进入打分阶段。由于这个原因,所以这个参数不应该被设置成一个很低的值,通常的做法是不会将这个参数的值设置的低于 10,很低的参数值一般在调度器的吞吐量很高且对 Node 的打分不重要的情况下才使用。换句话说,只有当你更倾向于在可调度节点中任意选择一个 Node 来运行这个 Pod 时,才使用很低的参数设置。
如果你的集群规模只有数百个节点或者更少,实际上并不推荐你将这个参数设置得比默认值更低,因为这种情况下不太会有效的提高调度器性能。
3、创建一个Pod的工作流程
一般情况下我们部署的 Pod 是通过集群的自动调度策略来选择节点的,默认情况下调度器考虑的是资源足够,并且负载尽量平均。但是有的时候我们需要能够更加细粒度的去控制 Pod 的调度,比如我们希望一些机器学习的应用只跑在有 GPU 的节点上;但是有的时候我们的服务之间交流比较频繁,又希望能够将这服务的 Pod 都调度到同一个的节点上。这就需要使用一些调度方式来控制 Pod 的调度了,主要有两个概念:亲和性和反亲和性,亲和性又分成节点亲和性(nodeAffinity)和 Pod 亲和性(podAffinity)。
1.架构图
Kubernetes基于list-watch机制的控制器架构,实现组件间交互的解耦。 其他组件监控自己负责的资源,当这些资源发生变化时,kube-apiserver会通知这些组件,这个过程类似于发布与订阅。
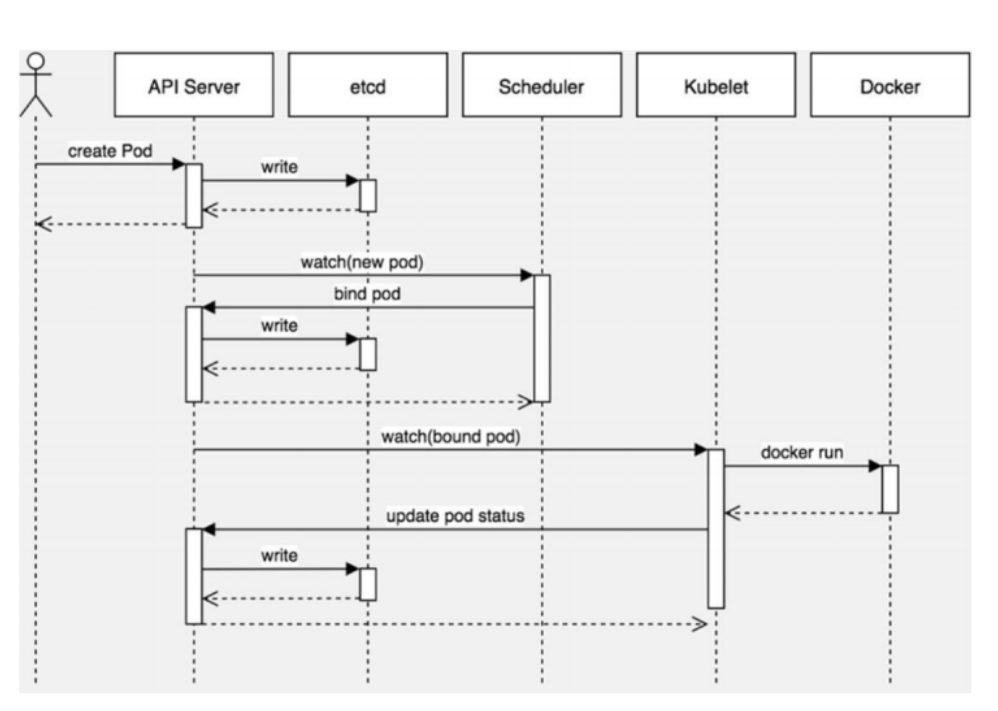
2.剖析过程
- 我们通过命令行创建一个pod:
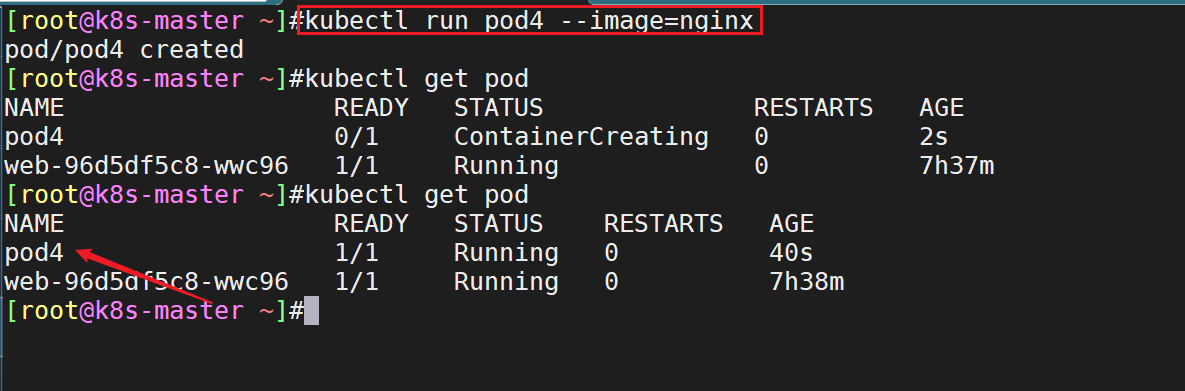
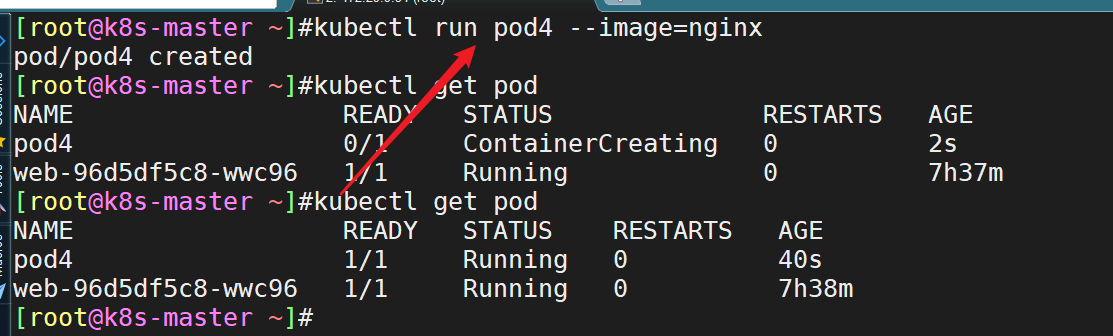
- 当我们在执行命令
kubectl run pod4 --image=nginx后,各组件之间的调用流程是如何的呢?
1、kubectl向apiserver发送一个创建pod的请求2、apiserver接收到并向etcd写入存储,写入成功返回一个提示#这个过程类似于老板和顾客之间的关系:api-server:开店老板etcd:仓库其他组件:顾客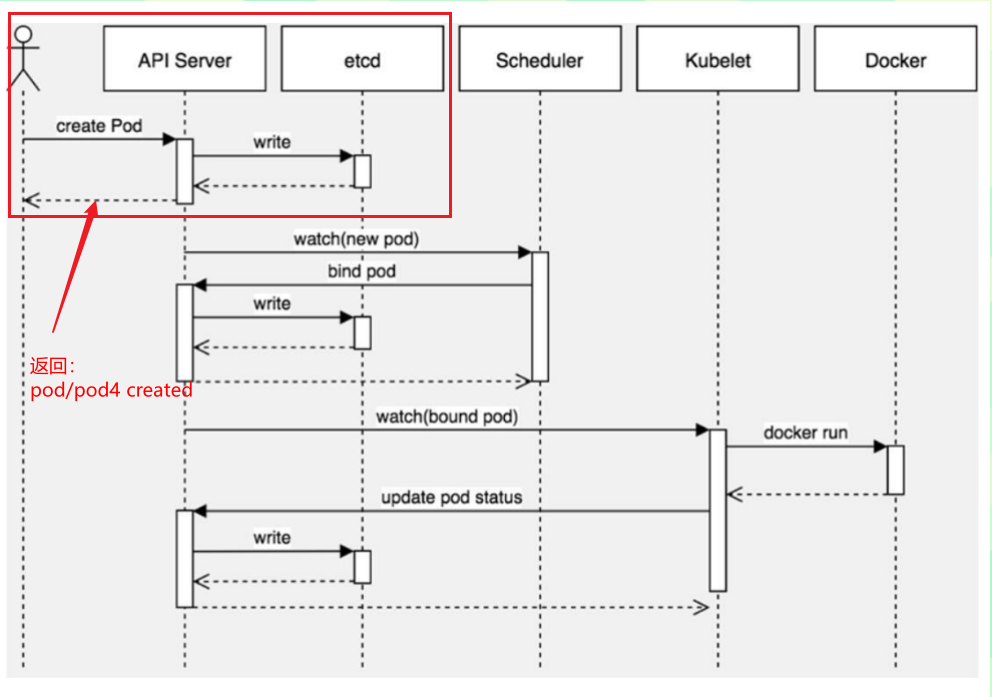
- 注意:如果在执行如下
kubectl run pod4 --image=nginx命令时,卡着了,说明什么问题呢?
-->说明: etcd数据库写入有问题/达到性能瓶颈,或者,api-server和etcd 2者总有一个有问题:
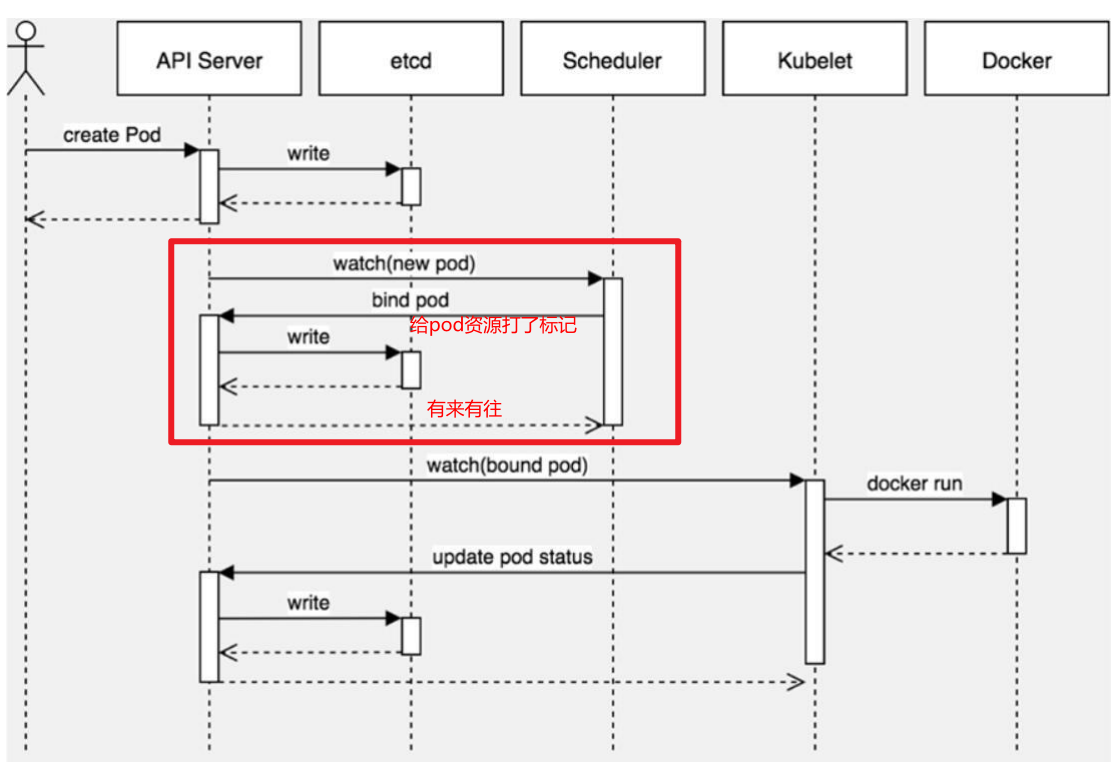
- 继续:scheduler向apiserver查询未分配的pod资源,通过自身调度算法选择一个合适的node进行绑定(给这个pod资源打一个标记,标记分配到node1)注意:它这个调度算法还是比较复杂、均匀一点的,它会考虑到你的机器的硬件配置,pod属性等等一些综合的属性;
- 问题:如果scheduler组件有问题,那么此时pod会出现什么状态?
答:pod会出现通过kubectl get pod根本看不到你刚创建的pod信息的,更别说它的状态了,因为它根本没分配。
因此,如果你创建的pod信息根本看不到,那么会是哪个组件可能有问题?-->scheduler组件可能出在问题。
- 如果是pending状态:pod是已经绑定到某个节点了。
- 继续流程讲解:
4、kubelet向apiserver查询分配到自己节点的pod,调用dockerapi(/var/run/docker.sock)创建容器5、kubelet获取docker创建容器的状态,并汇报给apiserver,apiserver更新状态到etcd存储6、kubectlgetpods就能查看pod状态备注:kubelet的功能主要是管理容器:这个是默认调用的dockerapi接口[root@k8s-master ~]#ll /var/run/docker.socksrw-rw----1rootdocker0Jun1411:46/var/run/docker.sock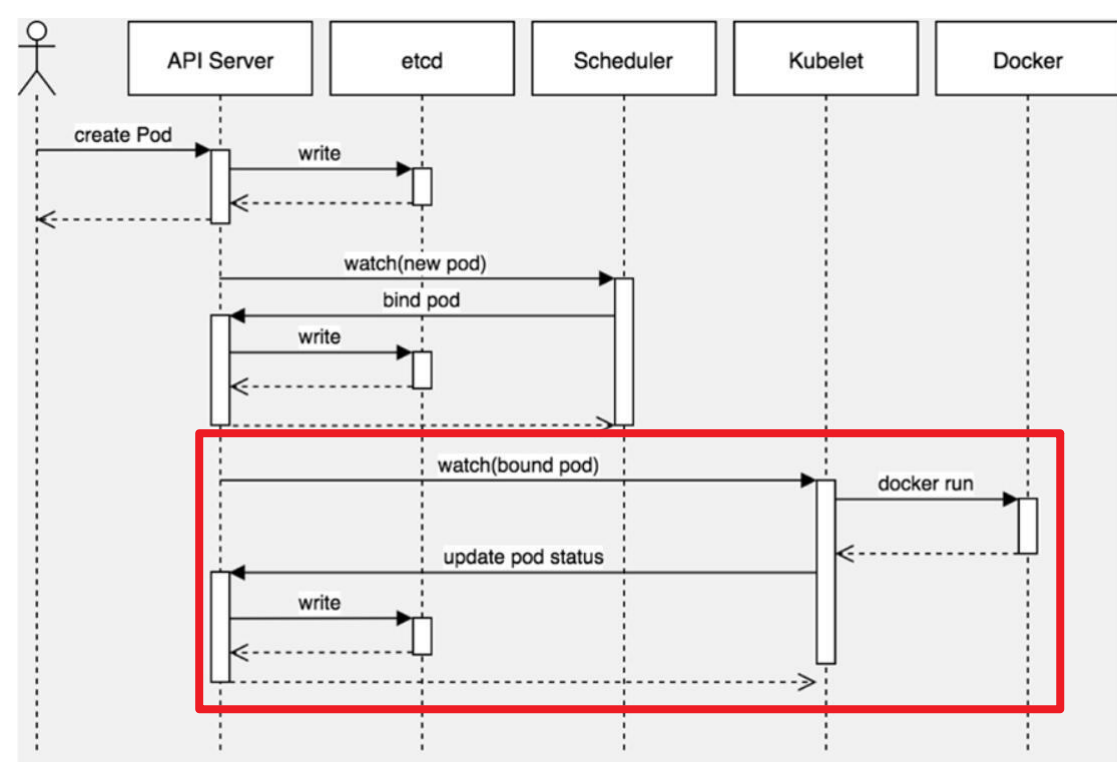
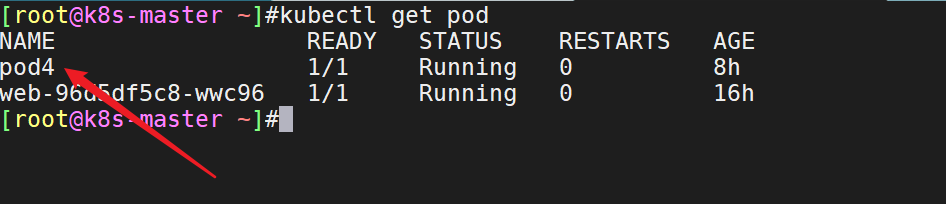
- 问题:controller-manager为什么没用到?
controller-manager是用于管理控制器,例如deployment(rs)、service,因为创建的是一个pod,不受它管理。
如果controller-manager要放在这里,一般是放在etcd后面的:
- kube-proxy为什么没用到?
proxy是用于管理pod网络,例如service,因为没创建service。
kube-proxy的主要功能就是维护好service,service是k8s的抽象资源;
- 扩展
比如,这个容器创建的时候创建失败了,不是一个running状态,也不是一个pending状态。可能就是docker在启动容器时,用你那个镜像启动容器失败了。所以这是你需要用docker去run一个镜像看能不能起来。
3.Pod中影响调度的主要属性
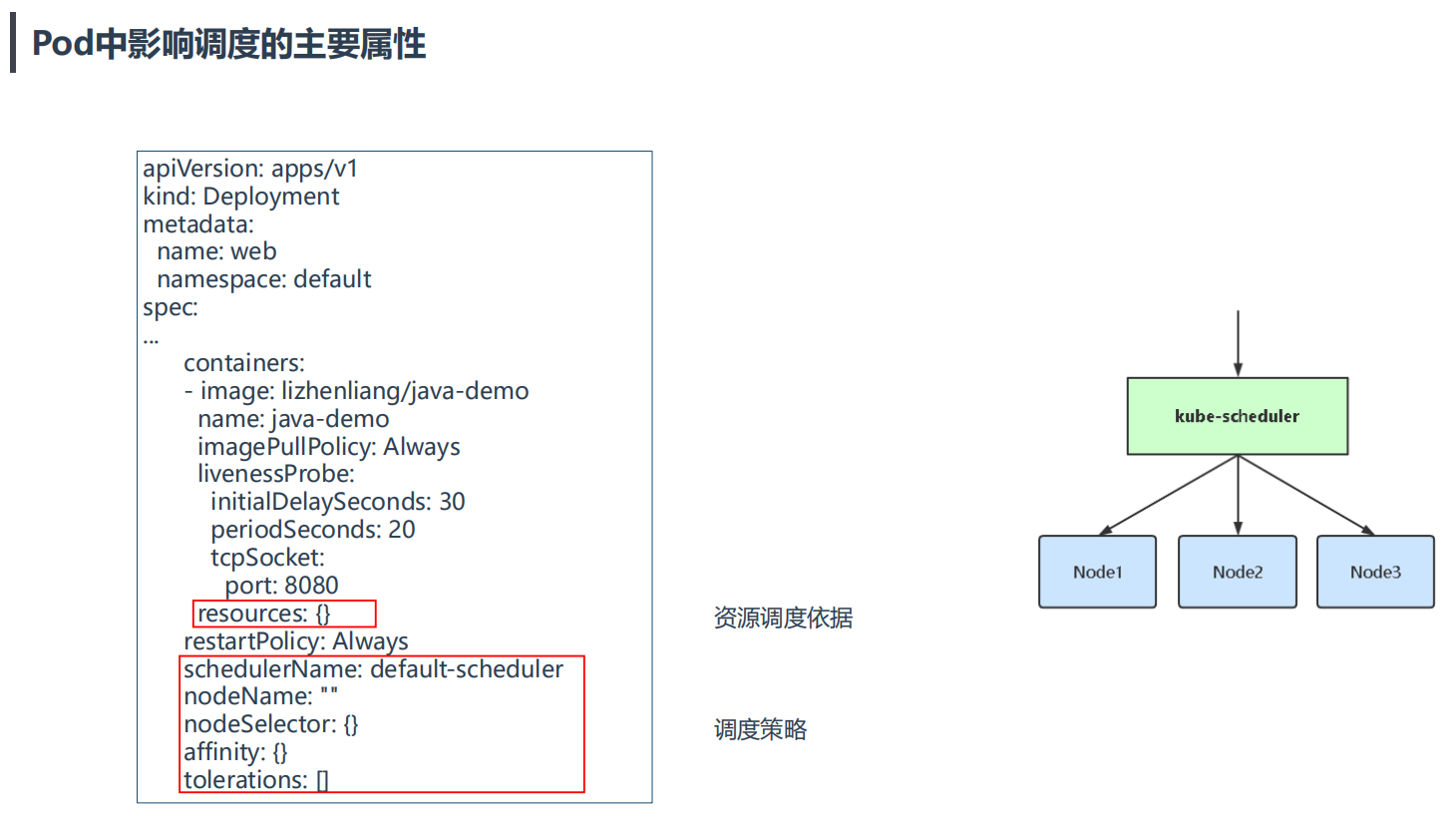
注意
resources:{} 资源调度依据这个,挺重要的; 很多大厂都会去二开"schedulerName:default-scheduler"这个调度器的,会去加一些调度策略,进而完成他们的需求;
🍂 调度原因失败分析
kubectlgetpod<NAME>-owide查看调度失败原因:kubectldescribepod<NAME>•节点CPU/内存不足•有污点,没容忍(tolerations)•没有匹配到节点标签(n)4.调度器需要充分考虑诸多的因素
 资源高效利用:装箱率要高! afinity:微服务,分步式系统,网络调用,本机调用,排除了网络调用,额外的传输时间,物理网卡带宽限制! anti-affinity:某个业务的不同副本,不能让其跑在一台机器上,一个机架上,一个地域里,使其分布在不同的故障域。 locality:数据本地化,是一个很重要的概念,哪里有数据,我的作业就去哪里,这样可以减少数据拷贝的开销。k8s里的拉取镜像。
资源高效利用:装箱率要高! afinity:微服务,分步式系统,网络调用,本机调用,排除了网络调用,额外的传输时间,物理网卡带宽限制! anti-affinity:某个业务的不同副本,不能让其跑在一台机器上,一个机架上,一个地域里,使其分布在不同的故障域。 locality:数据本地化,是一个很重要的概念,哪里有数据,我的作业就去哪里,这样可以减少数据拷贝的开销。k8s里的拉取镜像。
🍂
听起来很简单,但这个过程中会涉及Predicate、Priority等各种调度算法,还有优先级(Priority )、**抢占(Preemption)**等各种机制。在实际的调度设计中,有非常多需要考虑的问题,比如:
1. 公平:如何保证每个节点都能被分配资源
2. 资源高效利用:怎样压榨集群的资源能力,让资源被最大化使用
3. 效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
4. 灵活:允许用户根据自己的需求控制调度的逻辑
5.Kubernetes中的资源分配
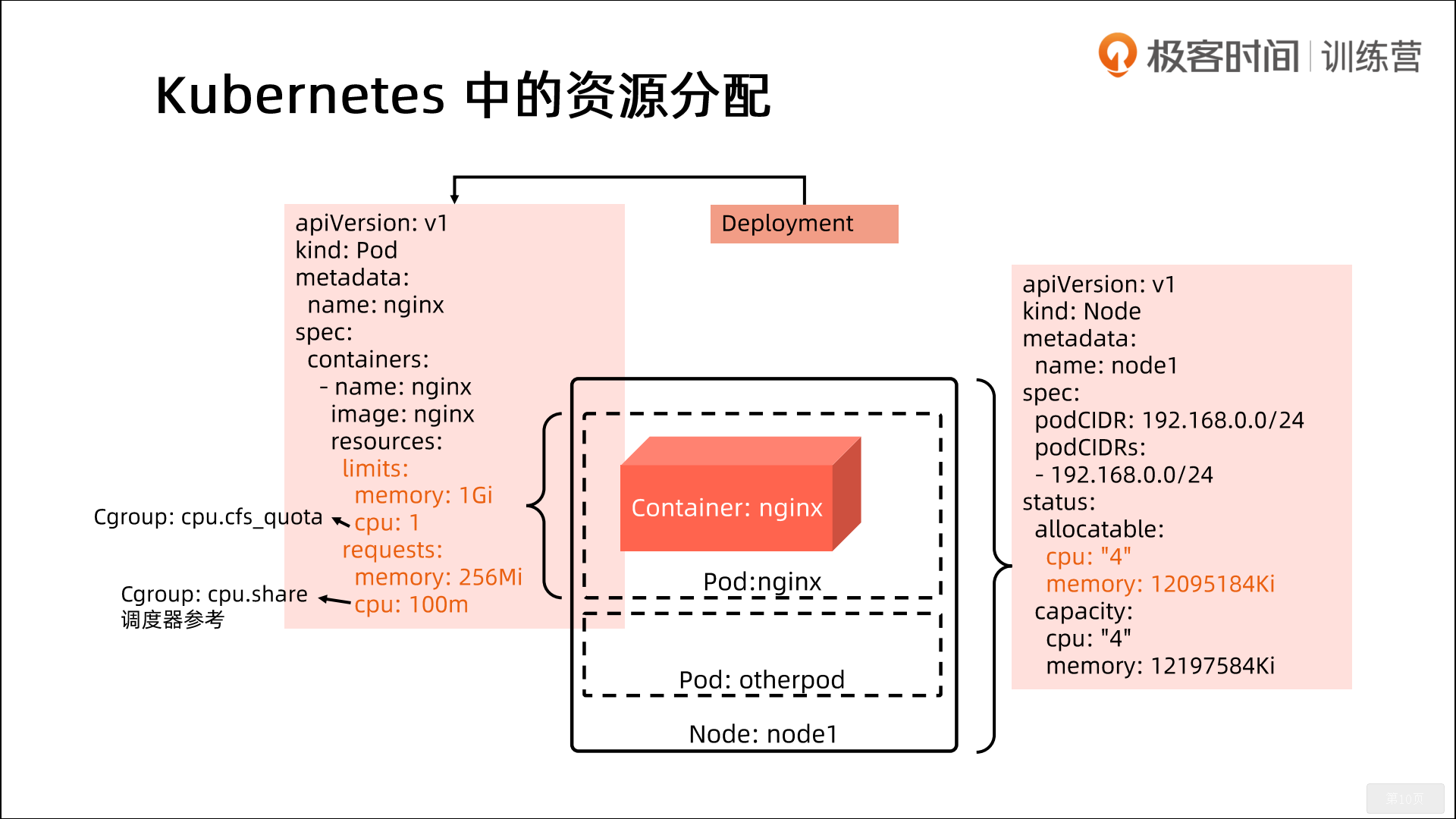
1.limits:在Cgroups里使用;cpu.cfs_quota/cpu.cfs_period(10w)=1 2.requests:cpu这个requests其实在Cgroup里也起作用。当你多个应用发生资源抢占时,他们抢占的cpu时间比较是多少呢?是通过cpu.share去调节的。k8s是如何实现的呢?这里如果设置的是一个cpu,request是1的话,那么cpu.share是1024。 如果你设置的是100m,相当于是0.1个cpu,那么cpu.share就是0.1*1024=102. 也就是cpu.requests也是最终会体现到Cgroups里面去的。
6.Init container的资源需求

1、nodeSelector
nodeSelector:用于将Pod调度到匹配Label的Node上,如果没有匹配的标签会调度失败。
作用:
- 约束Pod到特定的节点运行
- 完全匹配节点标签
应用场景:
- 专用节点:根据业务线将Node分组管理
- 配备特殊硬件:部分Node配有SSD硬盘、GPU
| 💘 实践:nodeSelector测试(测试成功)-2022.5.16 |
|---|
在了解亲和性之前,我们先来了解一个非常常用的调度方式:nodeSelector。我们知道 label 标签是 kubernetes 中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,比如最常见的 Service 对象通过 label 去匹配 Pod 资源,而 Pod 的调度也可以根据节点的 label 来进行调度。
- 我们可以通过下面的命令查看我们的 node 的 label:
[root@master1 ~]#kubectl get node --show-labels NAMESTATUSROLESAGEVERSIONLABELSmaster1Readycontrol-plane,master109dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=node1Ready<none>109dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linuxnode2Ready<none>109dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux- 现在我们先给节点 node2 增加一个
com=youdianzhishi的标签,命令如下:
[root@master1 ~]#kubectl label nodes node2 com=youdianzhishinode/node2labeled我们可以通过上面的 --show-labels参数可以查看上述标签是否生效。
[root@master1 ~]#kubectl get node node2 --show-labels NAMESTATUSROLESAGEVERSIONLABELSnode2Ready<none>109dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,com=youdianzhishi,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux- Pod里配置nodeSelector字段:
当节点被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在 Pod 的 spec 字段中添加 nodeSelector字段,里面是我们需要被调度的节点的 label 标签,比如,下面的 Pod 我们要强制调度到 node2 这个节点上去,我们就可以使用 nodeSelector 来表示了:
$ vim 01-node-selector-demo.yaml
# 01-node-selector-demo.yamlapiVersion:v1kind:Podmetadata:labels:app:busybox-podname:test-busyboxspec:containers:- command:- sleep- "3600"image:busyboximagePullPolicy:Alwaysname:test-busyboxnodeSelector:#注意:nodeSelector是和containers同级的;注意,这个放的顺序一定要放在containers后面。不然会报错的!com:youdianzhishi- 部署后,我们就可以通过 describe 命令查看调度结果:
hg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml$kubectlapply-f01-node-selector-demo.yamlpod/test-busyboxcreatedhg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml$kubectlgetpo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATEStest-busybox1/1Running078s10.244.2.210node2<none><none>[root@master1 ~]#kubectl describe po test-busybox Name:test-busyboxNamespace:defaultPriority:0Node:node2/172.29.9.53StartTime:Thu,17Feb202219:45:11+0800Labels:app=busybox-podAnnotations:<none>Status:RunningIP:10.244.2.210IPs:IP:10.244.2.210Containers:test-busybox:ContainerID:containerd:Image:busyboxImageID:docker.io/library/busybox@sha256:5acba83a746c7608ed544dc1533b87c737a0b0fb730301639a0179f9344b1678Port:<none>HostPort:<none>Command:sleep3600State:RunningStarted:Thu,17Feb202219:45:31+0800Ready:TrueRestartCount:0Environment:<none>Mounts:/var/run/secrets/kubernetes.io/serviceaccountfromkube-api-access-p5z6t(ro)Conditions:TypeStatusInitializedTrueReadyTrueContainersReadyTruePodScheduledTrueVolumes:kube-api-access-p5z6t:Type:Projected(a volumethatcontainsinjecteddatafrommultiplesources)TokenExpirationSeconds:3607ConfigMapName:kube-root-ca.crtConfigMapOptional:<nil>DownwardAPI:trueQoSClass:BestEffortNode-Selectors:com=youdianzhishiTolerations:node.kubernetes.io/not-ready:NoExecuteop=Existsfor300snode.kubernetes.io/unreachable:NoExecuteop=Existsfor300sEvents:TypeReasonAgeFromMessage-------------------------NormalScheduled2m45sdefault-schedulerSuccessfullyassigneddefault/test-busyboxtonode2NormalPulling2m43skubeletPullingimage"busybox"NormalPulled2m26skubeletSuccessfullypulledimage"busybox"in17.583571931sNormalCreated2m26skubeletCreatedcontainertest-busyboxNormalStarted2m25skubeletStartedcontainertest-busybox[root@master1 ~]#我们可以看到 Events 下面的信息,我们的 Pod 通过默认的 default-scheduler调度器被绑定到了 node2 节点。不过需要注意的是nodeSelector属于强制性的,如果我们的目标节点没有可用的资源,我们的 Pod 就会一直处于 Pending状态。
通过上面的例子我们可以感受到 nodeSelector的方式比较直观,但是还不够灵活,控制粒度偏大。接下来我们再和大家了解下更加灵活的方式:节点亲和性(nodeAffinity)。
测试结束。😘
🍂 问题:
因pod中nodeSelector里的标签未出现在all node节点,但后续给node打好符合要求的标签,原来处于pending状态的pod会自动迁移过去的吗?-->会的。
2、亲和性和反亲和性调度
前面我们了解了 kubernetes 调度器的调度流程,我们知道默认的调度器在使用的时候,经过了 predicates和 priorities两个阶段。但是在实际的生产环境中,往往我们需要根据自己的一些实际需求来控制 Pod 的调度,这就需要用到 nodeAffinity(节点亲和性)、podAffinity(pod 亲和性)以及 podAntiAffinity(pod 反亲和性)。
亲和性调度可以分成软策略和硬策略两种方式:
软策略就是如果现在没有满足调度要求的节点的话,Pod 就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有的话也无所谓硬策略就比较强硬了,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然就不干了
对于亲和性和反亲和性都有这两种规则可以设置: preferredDuringSchedulingIgnoredDuringExecution和requiredDuringSchedulingIgnoredDuringExecution,前面的就是软策略,后面的就是硬策略。
1.节点亲和性
节点亲和性(nodeAffinity)主要是用来控制 Pod 要部署在哪些节点上,以及不能部署在哪些节点上的,它可以进行一些简单的逻辑组合了,不只是简单的相等匹配(比如前面的nodeSelector就是标签的)。
nodeAffinity:节点亲和类似于nodeSelector,可以根据节点上的标签来约束Pod可以调度到哪些节点。
相比nodeSelector:
- 匹配有更多的逻辑组合,不只是字符串的完全相等,支持的操作符有:
In、NotIn、Exists、DoesNotExist、Gt、Lt - 调度分为软策略和硬策略,而不是硬性要求
- 硬(required):必须满足
- 软(preferred):尝试满足,但不保证
这里的匹配逻辑是 label 标签的值在某个列表中,现在 Kubernetes 提供的操作符有下面的几种:
- In:label 的值在某个列表中 (这里的操作符,我们一般只用到in就足够了;)
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
注意:
但是需要注意的是如果
nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了;如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod。
比nodeSelector更高级的一个! matchExpressions比selector更加灵活。
==💘 实践:节点亲和性测试-2022.5.16(测试成功)==
- 比如现在我们用一个 Deployment 来管理8个 Pod 副本,现在我们来控制下这些 Pod 的调度,如下例子:
# 02-node-affinity-demo.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:node-affinitylabels:app:node-affinityspec:replicas:8selector:matchLabels:app:node-affinitytemplate:metadata:labels:app:node-affinityspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80name:nginxwebaffinity:#定义亲和性nodeAffinity:#节点亲和性 requiredDuringSchedulingIgnoredDuringExecution:# 硬策略nodeSelectorTerms:- matchExpressions:- key:kubernetes.io/hostnameoperator:NotInvalues:- master1#相当于只能调度到node1和node2节点。默认就不会调度到master1节点preferredDuringSchedulingIgnoredDuringExecution:# 软策略(尽可能调度到node2节点)- weight:1preference:matchExpressions:- key:comoperator:Invalues:- youdianzhishi上面这个 Pod 首先是要求不能运行在 master1 这个节点上,如果有个节点满足 com=youdianzhishi的话就优先调度到这个节点上。
由于上面 node02 节点我们打上了 com=youdianzhishi这样的 label 标签,所以按要求会优先调度到这个节点来的。
- 现在我们来创建这个 Pod,然后查看具体的调度情况是否满足我们的要求。
➜kubectlapply-fnode-affinty-demo.yamldeployment.apps/node-affinitycreated➜kubectlgetpods-lapp=node-affinity-owide#老师这个有部分pod被调度到node1节点NAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESnode-affinity-cdd9d54d9-bgbbh1/1Running02m28s10.244.2.247node2<none><none>node-affinity-cdd9d54d9-dlbck1/1Running02m28s10.244.4.16node1<none><none>node-affinity-cdd9d54d9-g2jr61/1Running02m28s10.244.4.17node1<none><none>node-affinity-cdd9d54d9-gzr581/1Running02m28s10.244.1.118node1<none><none>node-affinity-cdd9d54d9-hcv7r1/1Running02m28s10.244.2.246node2<none><none>node-affinity-cdd9d54d9-kvxw41/1Running02m28s10.244.2.245node2<none><none>node-affinity-cdd9d54d9-p4mmk1/1Running02m28s10.244.2.244node2<none><none>node-affinity-cdd9d54d9-t5mff1/1Running02m28s10.244.1.117node2<none><none>从结果可以看出有5个 Pod 被部署到了 node2 节点上,但是可以看到并没有一个 Pod 被部署到 master1 这个节点上,因为我们的硬策略就是不允许部署到该节点上,而 node2 是软策略,所以会尽量满足。
测试结束。😘
2.pod 亲和性和pod 反亲和性
Pod 亲和性(podAffinity)主要解决 Pod 可以和哪些 Pod 部署在同一个拓扑域中的问题(其中拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成的 cluster、zone 等等),而 Pod 反亲和性主要是解决 Pod 不能和哪些 Pod 部署在同一个拓扑域中的问题,它们都是处理的 Pod 与 Pod 之间的关系。比如一个 Pod 在一个节点上了,那么我这个也得在这个节点,或者你这个 Pod 在节点上了,那么我就不想和你待在同一个节点上。
这个是很重要的,线上业务基本要配置这种podAntiAffinity。
拓扑域
这里要重点理解下什么是拓扑域?-->你可以把它看成为一个分组。
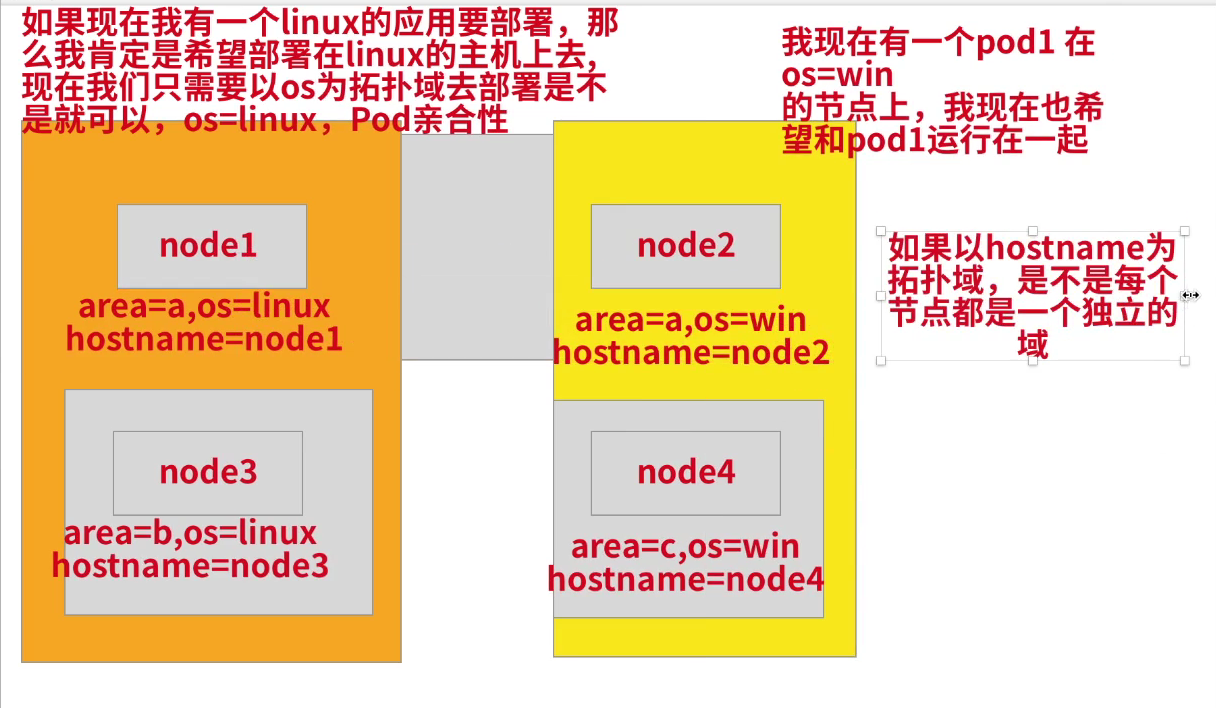
Pod亲和性
==💘 实验:pod亲和性-2022.5.16(测试成功)==
- 由于我们这里只有一个集群,并没有区域或者机房的概念,所以我们这里直接使用主机名来作为拓扑域,把 Pod 创建在同一个主机上面。
[root@master1 ~]# kubectl get node --show-labels NAMESTATUSROLESAGEVERSIONLABELSmaster1Readycontrol-plane,master110dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=node1Ready<none>110dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linuxnode2Ready<none>110dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,com=youdianzhishi,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux- 同样,还是针对上面的资源对象,我们来测试下 Pod 的亲和性:
# 03-pod-affinity-demo.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:pod-affinitylabels:app:pod-affinityspec:replicas:3selector:matchLabels:app:pod-affinitytemplate:metadata:labels:app:pod-affinityspec:containers:- name:nginximage:nginxports:- containerPort:80name:nginxwebaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:# 硬策略- labelSelector:#去选择具有app in ["busybox-pod"]的pod所在的hostname这个域。matchExpressions:- key:appoperator:Invalues:- busybox-podtopologyKey:kubernetes.io/hostname上面这个例子中的 Pod 需要调度到某个指定的节点上,并且该节点上运行了一个带有 app=busybox-pod标签的 Pod。我们可以查看有标签 app=busybox-pod的 pod 列表:
[root@master1 ~]#kubectl get pods -l app=busybox-pod-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATEStest-busybox1/1Running5(23m ago) 18h 10.244.2.210 node2 <none><none>- 我们看到这个 Pod 运行在了 node2 的节点上面,所以按照上面的亲和性来说,上面我们部署的3个 Pod 副本也应该运行在 node2 节点上:
$kubectlapply-f03-pod-affinity-demo.yamldeployment.apps/pod-affinitycreated$kubectlgetpods-owide-lapp=pod-affinityNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESpod-affinity-785f687c5-52t541/1Running060s10.244.2.228node2<none><none>pod-affinity-785f687c5-g594p1/1Running060s10.244.2.229node2<none><none>pod-affinity-785f687c5-s6j7h1/1Running060s10.244.2.227node2<none><none>- 如果我们把上面的 test-busybox 和 pod-affinity 这个 Deployment 都删除,然后重新创建 pod-affinity 这个资源,看看能不能正常调度呢:
$kubectldelete-f01-node-selector-demo.yamlpod"test-busybox"deleted$kubectldelete-f03-pod-affinity-demo.yamldeployment.apps"pod-affinity"deleted$kubectlapply-f03-pod-affinity-demo.yamldeployment.apps/pod-affinitycreated$kubectlgetpoNAMEREADYSTATUSRESTARTSAGEpod-affinity-785f687c5-2256q0/1Pending080spod-affinity-785f687c5-7gpz50/1Pending080spod-affinity-785f687c5-97gpj0/1Pending080s我们可以看到都处于 Pending状态了,这是因为现在没有一个节点上面拥有 app=busybox-pod这个标签的 Pod,而上面我们的调度使用的是硬策略,所以就没办法进行调度了,大家可以去尝试下重新将 test-busybox 这个 Pod 调度到其他节点上,观察下上面的3个副本会不会也被调度到对应的节点上去。(这里可以自己测试下,可以利用node1的kubernetes.io/hostname:node1标签用nodeSelector来实现)
- 我们这个地方使用的是
kubernetes.io/hostname这个拓扑域,意思就是我们当前调度的 Pod 要和目标的 Pod 处于同一个主机上面,因为要处于同一个拓扑域下面。为了说明这个问题,我们把拓扑域改成beta.kubernetes.io/os,同样的我们当前调度的 Pod 要和目标的 Pod 处于同一个拓扑域中,目标的 Pod 是拥有beta.kubernetes.io/os=linux的标签,而我们这里所有节点都有这样的标签,这也就意味着我们所有节点都在同一个拓扑域中,所以我们这里的 Pod 可以被调度到任何一个节点,重新运行上面的app=busybox-pod的 Pod,然后再更新下我们这里的资源对象:
$kubectlgetpo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESpod-affinity-6bf5bb4fc4-j6ctw1/1Running022s10.244.2.230node2<none><none>pod-affinity-6bf5bb4fc4-xb7tr1/1Running022s10.244.2.231node2<none><none>pod-affinity-6bf5bb4fc4-xl6pn1/1Running022s10.244.1.97node1<none><none>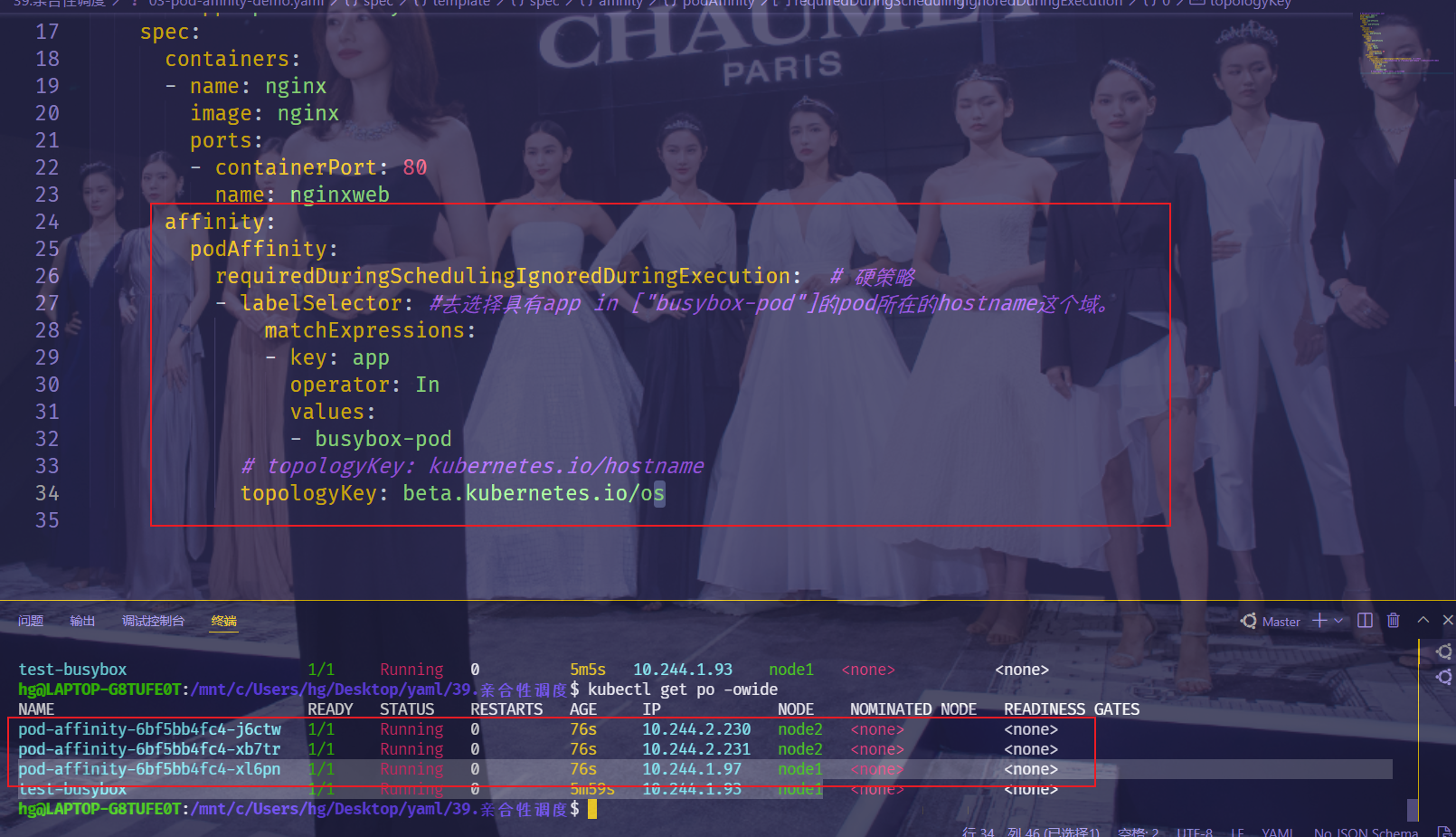
可以看到现在是分别运行在2个节点下面的,因为他们都属于 beta.kubernetes.io/os这个拓扑域(而busybox-pod也刚好在这个域下,因此符合硬策略要求)。
这里需要注意下:通过上面这个实验可以看到,这2个node节点都属于
beta.kubernetes.io/os这个拓扑域,但只有node1上有app=pod-affitity这个标签的pod,从结果可以看到也是可以调度到node2上的。
实验结束。😘
Pod反亲和性
pod 反亲和性(podAntiAffinity)
Pod 反亲和性(podAntiAffinity)则是反着来的,比如一个节点上运行了某个 Pod,那么我们的模板 Pod 则不希望被调度到这个节点上面去了。
Pod反亲和性可避免单点故障。
- Pod 反亲和性(podAntiAffinity)里的硬策略和软策略:
# 软策略,本次后面测试就用软策略了哈。affinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:# 软策略- weight:1podAffinityTerm:topologyKey:kubernetes.io/hostnamelabelSelector:matchExpressions:- key:appoperator:Invalues:- wordpress……# 硬策略affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:# 硬策略- labelSelector:matchExpressions:- key:appoperator:Invalues:- wordpresstopologyKey:kubernetes.io/hostname注意:层级关系deployment.spec.template.spec.affinity
==💘 实验:pod反亲和性(测试成功)-2022.5.16==
- 我们把上面的
podAffinity直接改成podAntiAffinity:
# 04-pod-antiaffinity-demo.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:pod-antiaffinitylabels:app:pod-antiaffinityspec:replicas:3selector:matchLabels:app:pod-antiaffinitytemplate:metadata:labels:app:pod-antiaffinityspec:containers:- name:nginximage:nginxports:- containerPort:80name:nginxwebaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:# 硬策略- labelSelector:#3个pod副本不会调度到具有app=busybox-pod所在的hostanme这个域(节点)上面matchExpressions:- key:appoperator:Invalues:- busybox-podtopologyKey:kubernetes.io/hostname#注意:pod反亲和性是直接不往这个域里直接调度pod的!!!这里的意思就是如果一个节点上面有一个 app=busybox-pod这样的 Pod 的话,那么我们的 Pod 就别调度到这个节点上面来,上面我们把app=busybox-pod这个 Pod 固定到了 node2 这个节点上面的,所以正常来说我们这里的 Pod 不会出现在该节点上:
$kubectlapply-f04-pod-antiaffinity-demo.yamldeployment.apps/pod-antiaffinitycreated$kubectlgetpo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESpod-antiaffinity-57c57dd9f7-jspkt1/1Running025s10.244.1.100node1<none><none>pod-antiaffinity-57c57dd9f7-mm78w1/1Running025s10.244.1.99node1<none><none>pod-antiaffinity-57c57dd9f7-x9mft1/1Running025s10.244.1.98node1<none><none>我们可以看到没有被调度到 node2 节点上,因为我们这里使用的是 Pod 反亲和性。
- 大家可以思考下,如果这里我们将拓扑域更改成
beta.kubernetes.io/os会怎么样呢?可以自己去测试下看看。
$kubectlapply-f04-pod-antiaffinity-demo.yamldeployment.apps/pod-antiaffinitycreated$kubectlgetpoNAMEREADYSTATUSRESTARTSAGEpod-antiaffinity-c5fb4db4d-jj5j70/1Pending04spod-antiaffinity-c5fb4db4d-xxnhg0/1Pending04spod-antiaffinity-c5fb4db4d-zkbgp0/1Pending04s实验结束。😘
注意:Pod反亲和性里标签问题
- 故障案例
k8s train5的 应用案例一节,在做wordpress的Pod反亲和性时,我这里报错了,一个pod一直处于pending,集群资源也够,这个是啥问题,知道不。
k8s里,可调度节点数为2,pod的副本数为2,如果设置了pod反亲和性的硬策略,其中拓扑域为节点名称,那么2个pod的副本应该是可以正常调度的。
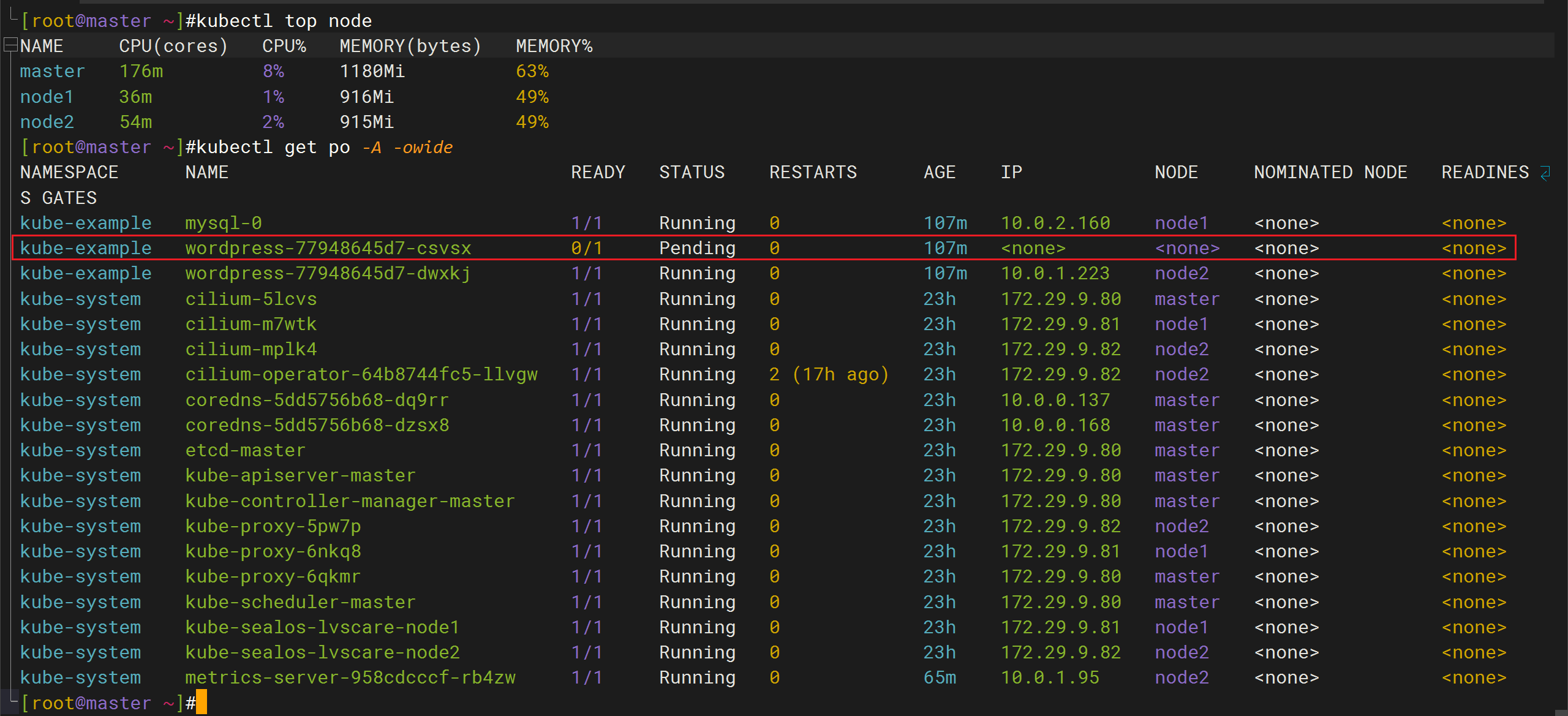
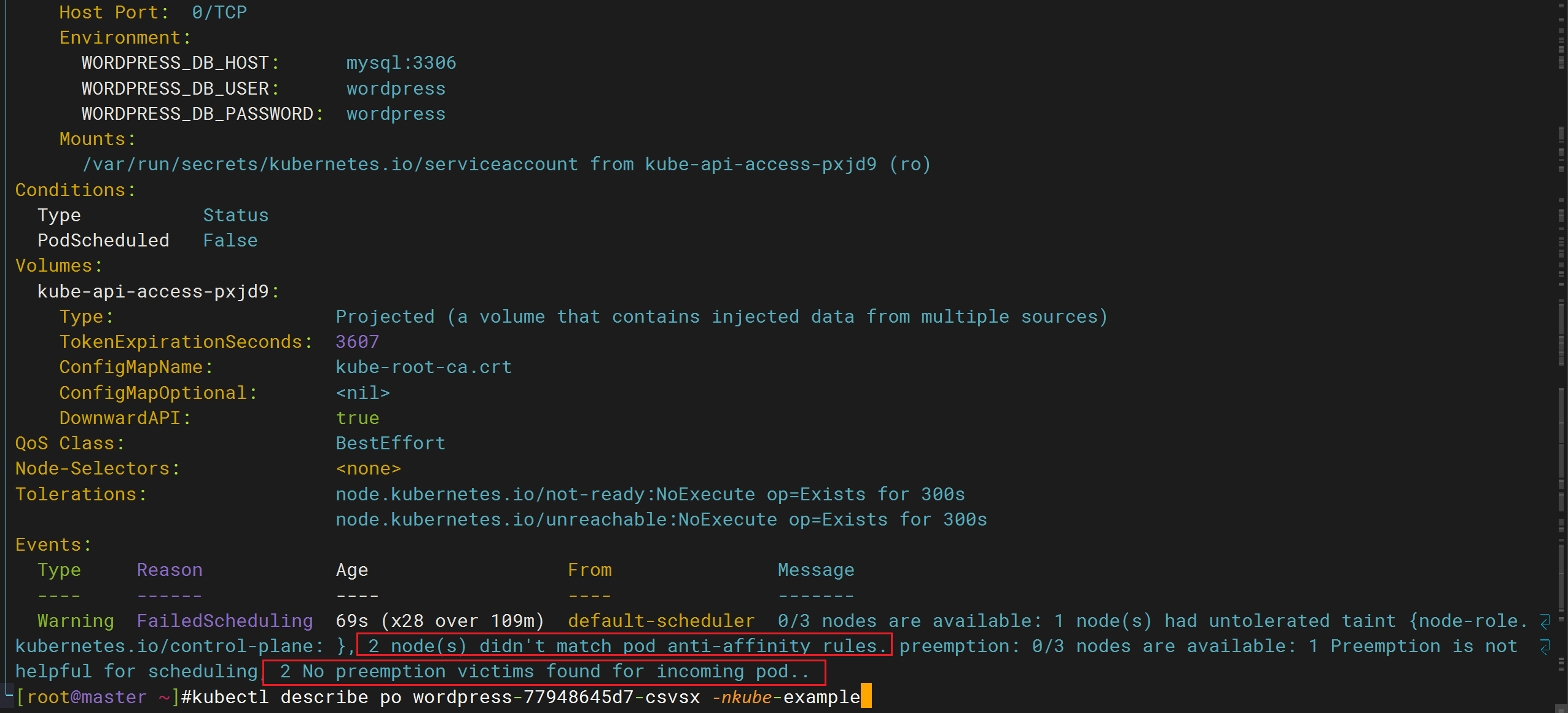
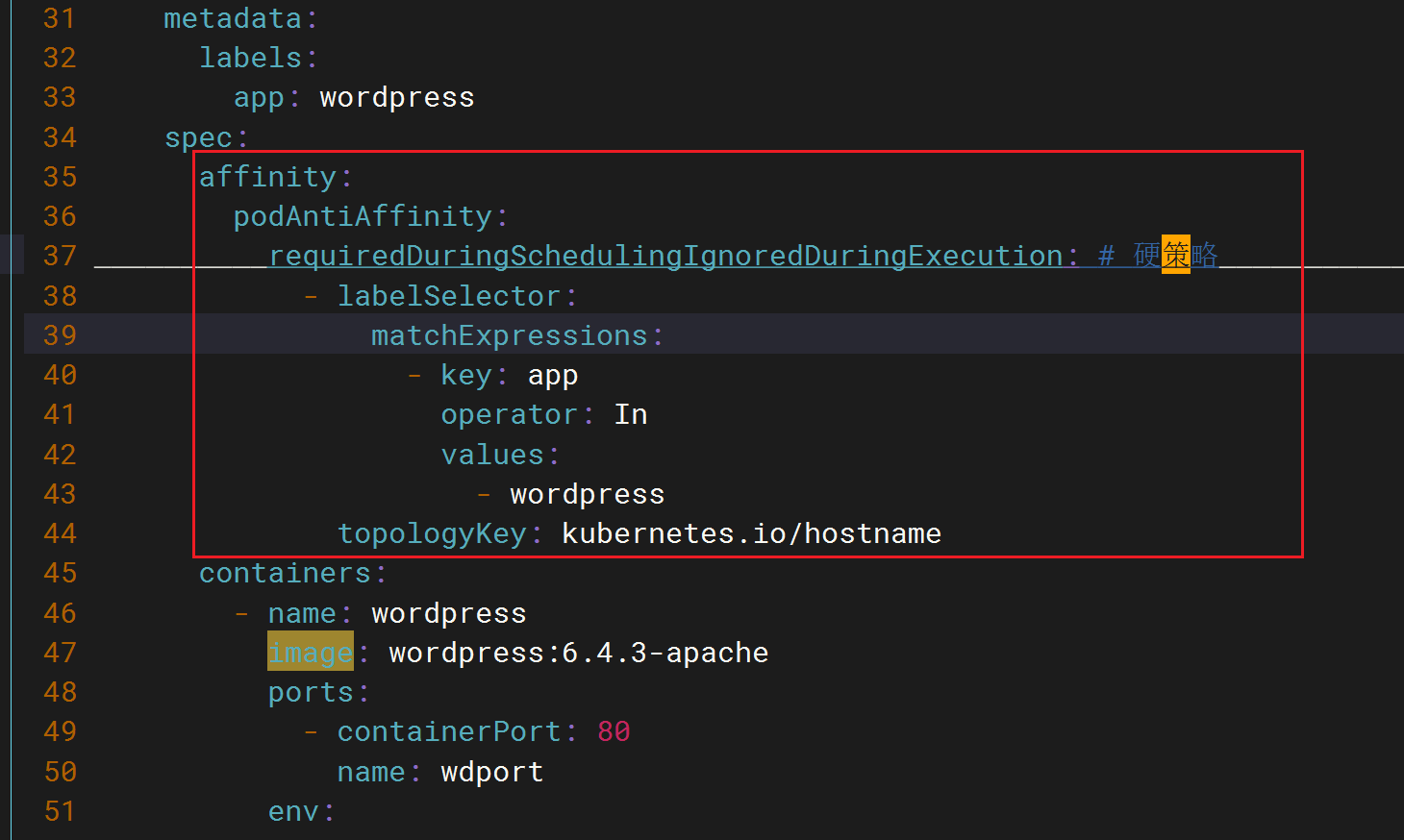
- 故障解决
是因为mysql的标签也是app:wordpress,这样导致wordpress的一个副本无法被调度。
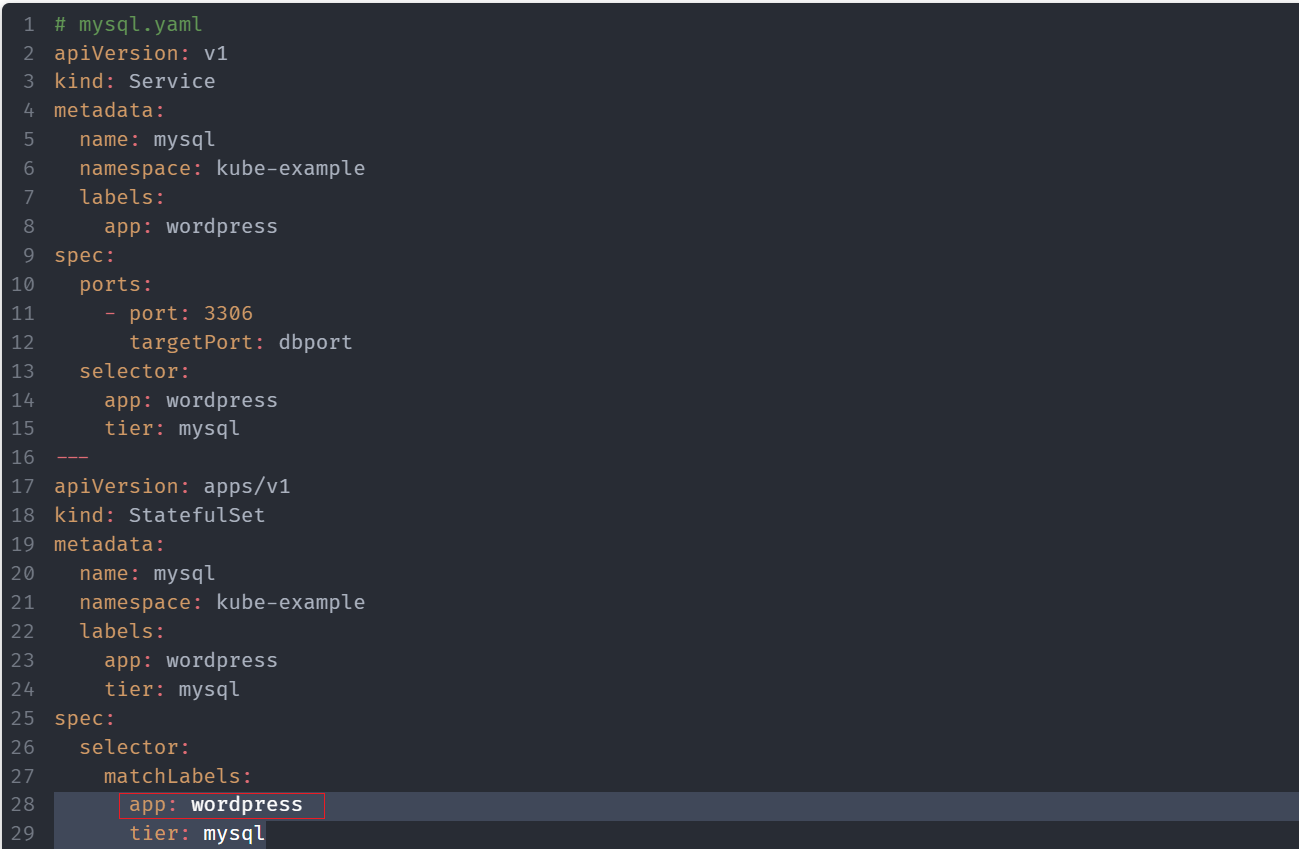
更改标签后,就可以被调度了:
3、污点与容忍
污点与容忍概念
Taint(污点)与Tolerations(污点容忍)
Taints:避免Pod调度到特定Node上
Tolerations:允许Pod调度到持有Taints的Node上
应用场景:
- 专用节点:根据业务线将Node分组管理,希望在默认情况下不调度该节点,只有配置了污点容忍才允许分配
- 配备特殊硬件:部分Node配有SSD硬盘、GPU,希望在默认情况下不调度该节点,只有配置了污点容忍才允许分配
- 基于Taint的驱逐
对于 nodeAffinity无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上。而污点(Taints)恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度 Pod。
比如用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。我们使用 kubeadm 搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 Pod 都没有被调度到 master 上去。
污点:其实是一个label标签,只不过它是一个特殊的label标签。
[root@master1 ~]#kubectl get node master1 --show-labels NAMESTATUSROLESAGEVERSIONLABELSmaster1Readycontrol-plane,master110dv1.22.2beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=(注意,这个是一个空标签),node.kubernetes.io/exclude-from-external-load-balancers=[root@master1 ~]#kubectl describe node master1Name:master1Roles:masterLabels:beta.kubernetes.io/arch=amd64beta.kubernetes.io/os=linuxkubernetes.io/arch=amd64kubernetes.io/hostname=master1kubernetes.io/os=linuxnode-role.kubernetes.io/master=......Taints:node-role.kubernetes.io/master:NoScheduleUnschedulable:false......我们可以使用上面的命令查看 master 节点的信息,其中有一条关于 Taints 的信息:node-role.kubernetes.io/master:NoSchedule,就表示master 节点打了一个污点的标记,其中影响的参数是 NoSchedule,表示 Pod 不会被调度到标记为 taints 的节点。除了 NoSchedule外,还有另外两个选项:
- PreferNoSchedule:NoSchedule 的软策略版本,表示尽量不调度到污点节点上去
- NoExecute:该选项意味着一旦 Taint 生效(被打上taint),如该节点内正在运行的 Pod 没有对应容忍(Tolerate)设置,则会直接被逐出。 哈哈😂这个命令也是够狠。。。
kubectl taint node k8s-node1 disktype=ssd:NoExecute

🍂 污点 taint 标记节点的命令如下:
➜kubectltaintnodesnode2test=node2:NoSchedulenode"node2"tainted上面的命名将 node2 节点标记为了污点,影响策略是 NoSchedule,只会影响新的 Pod 调度,如果仍然希望某个 Pod 调度到 taint 节点上,则必须在 Spec 中做出 Toleration 定义,才能调度到该节点。
🍂 最后如果我们要取消节点的污点标记,可以使用下面的命令:
➜kubectltaintnodesnode2test-node"node2"untainted🍂
Taints和Tolerations用于保证Pod 不被调度到不合适的Node上,其中Taint应用于Node上,而Toleration则应用于Pod上。
🍂 nodeSelector/nodeAffinity与Taint/Tolerations区别
nodeSelector/nodeAffinity--一种主观意识,我要分配在哪个node节点上去;而Taint/Tolerations:是一种排斥行为,在node上排斥pod分配到自己身上;nodeSelector/nodeAffinity--管理员强迫nodetaint/toleration--node主动的一脸嫌弃tolerations 属性的写法

对于 tolerations属性的写法,其中的 key、value、effect 与 Node 的 Taint 设置需保持一致, 还有以下几点说明:
- 如果 operator 的值是
Exists,则 value 属性可省略 - 如果 operator 的值是
Equal,则表示其 key 与 value 之间的关系是 equal(等于) - 如果不指定 operator 属性,则默认值为
Equal
另外,还有两个特殊值:
- **空的 key 如果再配合 **
Exists就能匹配所有的 key 与 value,也就是是能容忍所有节点的所有 Taints !!!😋 - 空的 effect 匹配所有的 effect
🍀 例子
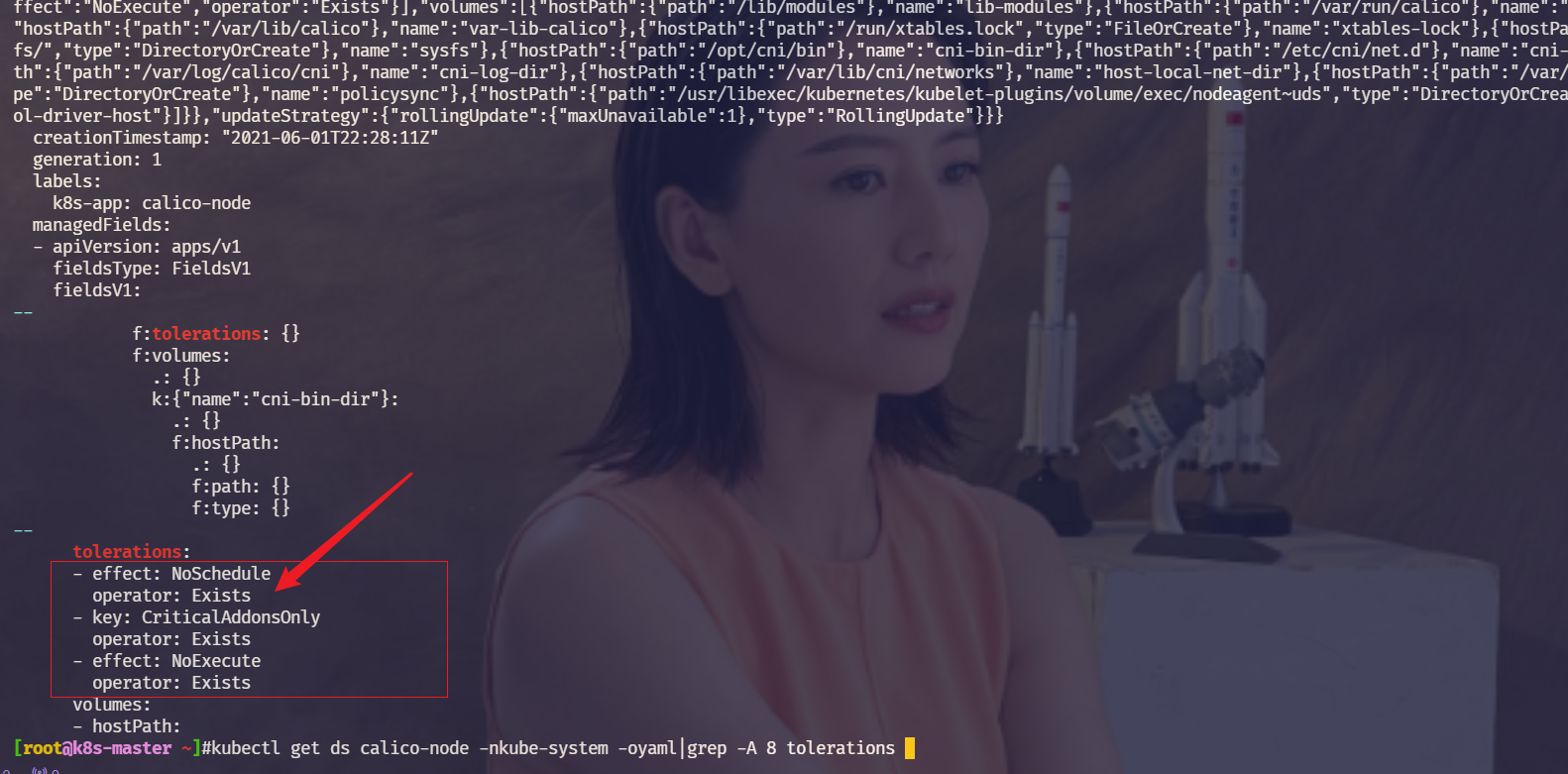
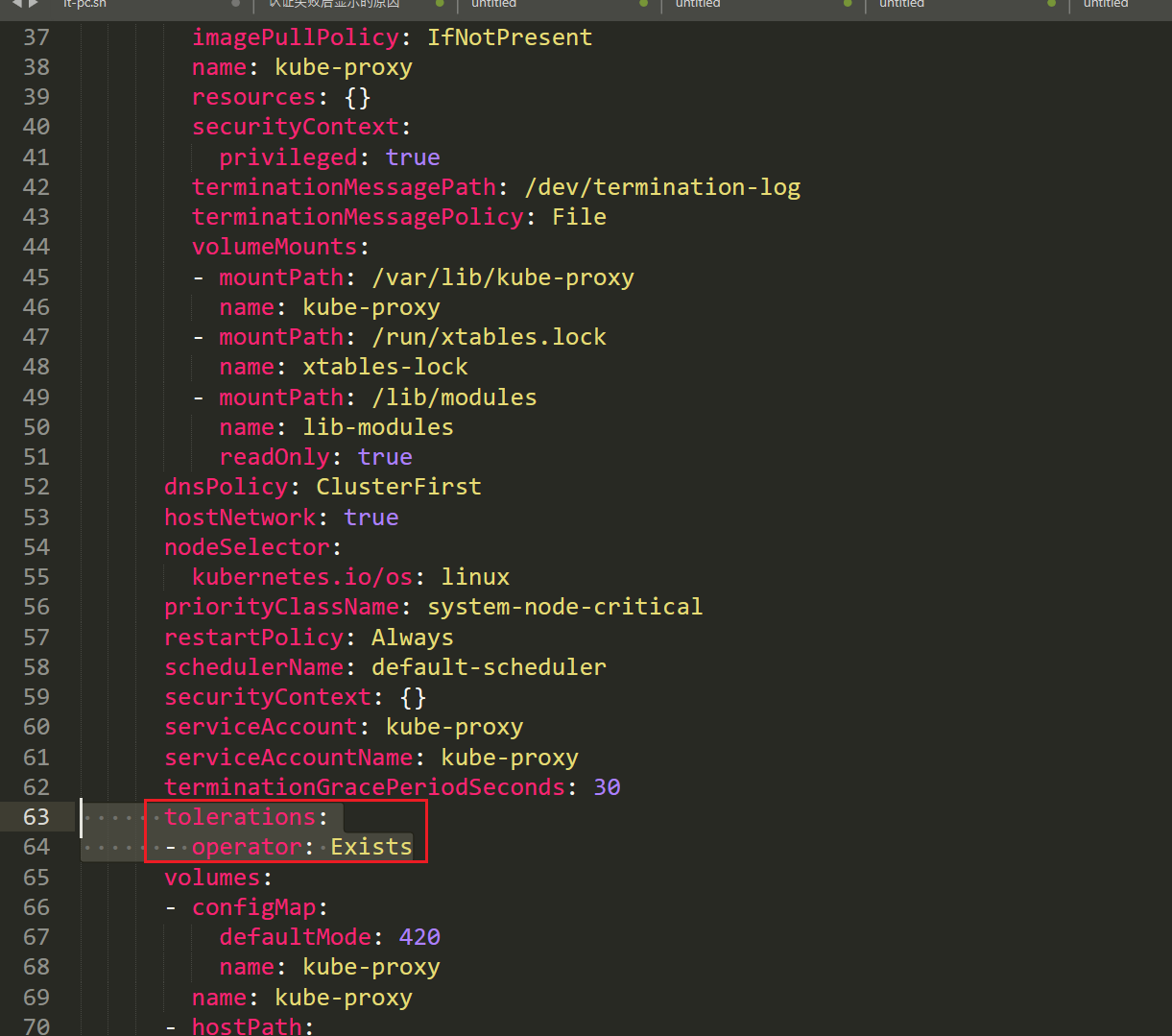
master节点上,为什么除了静态pod之外,上面还有calico/kube-proxy组件可以运行。
为什么呢?原因在这里:污点容忍是可以直接放宽条件写的,例如calico,不分什么key什么value,符合带有污点是NoSchedule都可以允许分配。


💘 实战:污点与容忍-2022.5.16(测试成功)
- 比如现在我们想要将一个 Pod 调度到 master 节点:
# 05-taint-demo.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:taintlabels:app:taintspec:replicas:3selector:matchLabels:app:tainttemplate:metadata:labels:app:taintspec:containers:- name:nginximage:nginxports:- name:httpcontainerPort:80tolerations:- key:"node-role.kubernetes.io/master"operator:"Exists"effect:"NoSchedule"由于 master 节点被标记为了污点,所以我们这里要想 Pod 能够调度到改节点去,就需要增加容忍的声明:
tolerations:- key:"node-role.kubernetes.io/master"operator:"Exists"effect:"NoSchedule"- 然后创建上面的资源,查看结果:
➜kubectlapply-ftaint-demo.yamldeployment.apps"taint"created➜kubectlgetpods-owideNAMEREADYSTATUSRESTARTSAGEIPNODE......taint-845d8bb4fb-57mhm1/1Running01m10.244.4.247node2taint-845d8bb4fb-bbvmp1/1Running01m10.244.0.33master1taint-845d8bb4fb-zb78x1/1Running01m10.244.4.246node2......我们可以看到有一个 Pod 副本被调度到了 master 节点,这就是容忍的使用方法。
那么问题来了:我这个pod可以调度到没打这个污点的node上去吗?还是说会优先调度到这个打了污点的节点上去呢?。。。
-->经测试:是可以调度上去的。pod配置了容忍之后,原来打了污点的node就可以和其他节点一样去负载pod了,具体调度策略是看调度器的。
- 最后如果我们要取消节点的污点标记,可以使用下面的命令:
➜kubectltaintnodesnode2test-node"node2"untainted实验结束。😘
4、nodeName
nodeName:指定节点名称,用于将Pod调度到指定的Node上,不经过调度器 (nodeName指哪打哪😂,nodeName一般在测试中用,但工作中根本没怎么用到)
| 💘 实践:nodeName测试(测试成功)-2022.5.16 |
|---|
- 创建pod的yaml并修改
[root@k8s-master ~]#kubectl run pod6 --image=nginx --dry-run=client -o yaml >pod6.yaml[root@k8s-master ~]#vim pod6.yamlapiVersion:v1kind:Podmetadata:name:pod-examplelabels:app:nginxspec:nodeName:k8s-node1containers:- name:nginximage:nginx:1.15- 注意:原来k8s-node1节点是已经打好污点了的。
[root@k8s-master ~]#kubectl describe nodes |grepTaintTaints:node-role.kubernetes.io/master:NoScheduleTaints:ssd=ok:NoScheduleTaints:<none>[root@k8s-master ~]#kubectl describe nodes k8s-node1 |grepTaintTaints:ssd=ok:NoSchedule[root@k8s-master ~]#- apply并查看效果
[root@k8s-master ~]#kubectl apply -f pod6.yamlpod/pod6created[root@k8s-master ~]#kubectl get pod -o wide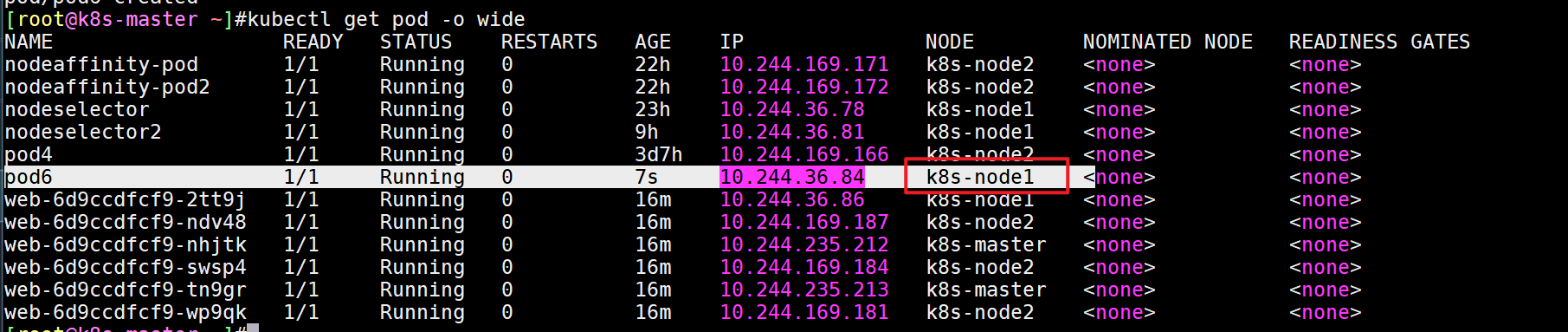
- 结论
如果在pod里指定了
nodeName字段,那么即使该pod没有配置污点容忍,也会被强制开通的指定的节点上去的。
测试结束。😘
5、优先级调度
与前面所讲的**调度优选策略中的优先级(Priorities)**不同,前面所讲的优先级指的是节点优先级,而我们这里所说的优先级指的是 Pod 的优先级,高优先级的 Pod 会优先被调度,或者在资源不足的情况牺牲低优先级的 Pod,以便于重要的 Pod 能够得到资源部署。
🍂 要定义 Pod 优先级,就需要先定义 PriorityClass对象,该对象没有 Namespace 的限制:
apiVersion:v1kind:PriorityClassmetadata:name:high-priorityvalue:1000000globalDefault:falsedescription:"This priority class should be used for XYZ service pods only."其中:
- value 为 32 位整数的优先级,该值越大,优先级越高
- globalDefault 用于未配置 PriorityClassName 的 Pod,整个集群中应该只有一个
PriorityClass将其设置为 true
🍂 然后通过在 Pod 的 spec.priorityClassName中指定已定义的 PriorityClass名称即可:
apiVersion:v1kind:Podmetadata:name:nginxlabels:app:nginxspec:containers:- name:nginximage:nginximagePullPolicy:IfNotPresentpriorityClassName:high-priority另外一个值得注意的是当节点没有足够的资源供调度器调度 Pod,导致 Pod 处于 pending 时,抢占(preemption)逻辑就会被触发,抢占会尝试从一个节点删除低优先级的 Pod,从而释放资源使高优先级的 Pod 得到节点资源进行部署。
6、服务质量(QOS)
QoS是 Quality of Service的缩写,即服务质量,为了实现资源被有效调度和分配的同时提高资源利用率,Kubernetes 针对不同服务质量的预期,通过 QoS 来对 pod 进行服务质量管理。对于一个 pod 来说,服务质量体现在两个具体的指标:CPU 和内存。当节点上内存资源紧张时,Kubernetes 会根据预先设置的不同 QoS 类别进行相应处理。
QoS主要分为 Guaranteed、Burstable和 Best-Effort三类,优先级从高到低。我们先分别来介绍下这三种服务类型的定义。
资源限制
如果未做过节点 nodeSelector、节点亲和性(node affinity)或 pod 亲和、反亲和性等高级调度策略设置,我们没有办法指定服务部署到指定节点上,这样就可能会造成 CPU 或内存等密集型的 pod同时分配到相同节点上,造成资源竞争。
另一方面,如果未对资源进行限制,一些关键的服务可能会因为资源竞争因 OOM等原因被 kill 掉,或者被限制 CPU 使用。
我们知道对于每一个资源,container 可以指定具体的资源需求(requests)和限制(limits),requests 申请范围是0到节点的最大配置,而 limits 申请范围是 requests 到无限,即 0 <=requests <=Node Allocatable,requests <=limits <=Infinity。
==🚩 可压缩资源和不可压缩资源==
1、CPU特性
CPU 是一种可压缩的资源,这意味着它可以被拉伸,以满足所有的需求。
如果进程要求太多的 CPU,其中一些将被节制。
对于 CPU,如果 pod 中服务使用的 CPU 超过设置的 limits,pod 不会被 kill 掉但会被限制,因为 CPU 是可压缩资源,如果没有设置 limits,pod 可以使用全部空闲的 CPU 资源。
主机cpu资源利用率满时,机器出现的现象-->卡顿。
问题:默认情况下,宿主机和容器都没做资源限制的话,容器理论上是可以无限制获取到主机的计算资源(如cpu和内存)。如果某个容器应用特别耗cpu,当它把主机cpu耗尽时(资源利用率超高,达到98,99%以上),问主机会出现什么现象?
答:会出现卡顿现象,执行一条命令,老半天才出来,像老年痴呆一样;
是因为cpu是按时间片来分配的,cpu的分配原则:为了尽可能地公平地给大家一个分配,但cpu没有特别硬性的限制;
2、内存特性
内存是一种不可压缩的资源,意味着它不能像 CPU 那样被拉伸。如果一个进程没有得到足够的内存来工作,这个进程就会被杀死。
对于内存,当一个 pod 使用内存超过了设置的 limits,pod 中容器的进程会被 kernel 因 OOM kill 掉,当 container 因为 OOM 被 kill 掉时,系统倾向于在其原所在的机器上重启该 container 或本机或其他重新创建一个 pod。(包括我们的磁盘也是一个不可压缩资源)。
==🚩 单位换算==
1.cpu(可压缩资源)
在 Kubernetes 中,CPU 资源的单位是被指定为核数(cores)或者 CPU 时间片(millicores)。当你在 Kubernetes Pod 的配置文件中定义 CPU 资源时,可以使用整数或小数来表示核数,也可以使用带有“m”后缀的整数来表示千分之一的核数。
1表示1个核的 CPU。0.5表示半个核的 CPU,也可以写作500m,因为 1000m(milli)相等于 1 核心。
例如,如果你将一个容器的 CPU 请求设置为 100m,那么意味着你请求为该容器保留 0.1 核的 CPU 时间片。如果你把容器的 CPU 限制设置为 1,那意味着该容器最多可以使用 1 个核的 CPU 时间。
这里是一个配置CPU资源请求和限制的例子:
apiVersion:v1kind:Podmetadata:name:cpu-demonamespace:cpu-examplespec:containers:- name:cpu-demo-ctrimage:vish/stressresources:limits:cpu:"1"requests:cpu:"500m"在这个例子中,容器cpu-demo-ctr启动时会请求至少有半核 CPU 可用(500m),而且该容器使用的 CPU 资源会被限制在最多1个核。如果在集群中没有足够的 CPU 资源来满足请求量,Pod 会等待直到有足够的资源可用。通过这种配置方式,Kubernetes 能够更有效地管理资源,确保在多租户或资源受限的环境中合理分配 CPU 使用权。
2.内存(不可压缩资源)
在 Kubernetes 中,内存的单位是字节。
你可以用,**E,P,T,**G,M,k 来代表 Exabyte,Petabyte,Terabyte,Gigabyte,Megabyte 和 kilobyte,尽管只有最后四个是常用的。(例如,500M,4G)
警告:不要用小写的 m 表示内存(这代表 Millibytes,低得离谱)
你可以用 Mi 来定义 Mebibytes,其余的也可以用 Ei、Pi、Ti 来定义(例如,500Mi)
一个 Mebibyte(以及它们的类似物 Kibibyte、Gibibyte...)是 20 字节的 2 次方。它的出现是为了避免与公制中的 Kilo、Mega 定义相混淆。你应该使用这个符号,因为它是字节的典型定义,而 Kilo 和 Mega 是 1000 的倍数。
==🚩 yaml案例==
Kubernetes 将 Limits 定义为一个容器使用的最大资源量,这意味着容器的消耗量永远不能超过所显示的内存量或 CPU 量。
另一方面,Requests 是指为容器保留的资源的最小保证量。
容器资源限制: • resources.limits.cpu • resources.limits.memory
容器使用的最小资源需求,作为容器调度时资源分配的依据: • resources.requests.cpu • resources.requests.memory
apiVersion:v1kind:Podmetadata:name:webspec:containers:- name:webimage:nginxresources:requests:memory:"64Mi"#特别注意:内存的单位是Mi,cpu的单位是m或者整数cpu:"250m"limits:memory:"128Mi"cpu:"500m"#cpu:"0.5"#K8s会根据Request的值去查找有足够资源的Node来调度此PodQoS 分类
Kubelet 提供 QoS 服务质量管理,支持系统级别的 OOM 控制。
QoS 分类并不是通过一个配置项来直接配置的,而是通过配置 CPU/内存的 limits 与 requests 值的大小来确认服务质量等级的,我们通过使用 kubectl get pod xxx -o yaml可以看到 pod 的配置输出中有 qosClass一项,该配置的作用是为了给资源调度提供策略支持,调度算法根据不同的服务质量等级可以确定将 pod 调度到哪些节点上。
| 名称 | 优先级 | 匹配条件 |
|---|---|---|
| 1、Guaranteed(有保证的) | 最高 | 1.pod里所有容器只配置了内存和cpu的limit; 2.pod里所有容器配置了内存和cpu的limit、requests,且limits==requests; |
| 2、Burstable(不稳定的) | 高 | 1.pod里部分容器配置了resources,但部分容器没配置; 2.pod里部分容器只配置了cpu的resources,部分容器只配置了内存的resources; |
| 3、Best-Effort(尽最大努力) | 低 | 1.pod里所有容器都没配置 内存和cpu的limit、requests; |
==1.Guaranteed(有保证的)==
系统用完了全部内存,且没有其他类型的容器可以被 kill 时,该类型的 pods 会被 kill 掉,也就是说最后才会被考虑 kill 掉,属于该级别的 pod 有以下两种情况:
- pod 中的所有容器都且仅设置了 CPU 和内存的 limits
- pod 中的所有容器都设置了 CPU 和内存的 requests 和 limits ,且单个容器内的
requests==limits(requests不等于0)
1️⃣ pod 中的所有容器都且仅设置了 limits:
containers:name:fooresources:limits:cpu:10mmemory:1Giname:barresources:limits:cpu:100mmemory:100Mi因为如果一个容器只指明 limit 而未设定 requests,则 requests 的值等于 limit 值,所以上面 pod 的 QoS 级别属于 Guaranteed。
⚠️ 另外需要注意若容器指定了 requests 而未指定 limits,则 limits 的值等于节点资源的最大值;若容器指定了 limits 而未指定 requests,则 requests 的值等于 limits。
2️⃣ 另外一个就是 pod 中的所有容器都明确设置了 requests 和 limits,且单个容器内的 requests==limits:
containers:name:fooresources:limits:cpu:10mmemory:1Girequests:cpu:10mmemory:1Giname:barresources:limits:cpu:100mmemory:100Mirequests:cpu:100mmemory:100Mi容器 foo 和 bar 内 resources 的 requests 和 limits 均相等,该 pod 的 QoS 级别属于 Guaranteed。
==2.Burstable(不稳定的)==
系统用完了全部内存,且没有 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被 kill 掉。pod 中只要有一个容器的 requests 和 limits 的设置不相同,该 pod 的 QoS 即为 Burstable。
1️⃣ 比如容器 foo 指定了 resource,而容器 bar 未指定:
containers:name:fooresources:limits:cpu:10mmemory:1Girequests:cpu:10mmemory:1Giname:bar2️⃣ 或者容器 foo 设置了内存 limits,而容器 bar 设置了 CPU limits:
containers:name:fooresources:limits:memory:1Giname:barresources:limits:cpu:100m上面两种情况定义的 pod 都属于 Burstable 类别的 QoS。
==3.Best-Effort(尽最大努力)==
系统用完了全部内存时,该类型 pods 会最先被 kill 掉。如果 pod 中所有容器的 resources 均未设置 requests 与 limits,那么该 pod 的 QoS 即为 Best-Effort。
1️⃣ 比如容器 foo 和容器 bar 均未设置 requests 和 limits:
containers:name:fooresources:name:barresources:资源回收策略
Kubernetes 通过 CGroup 给 Pod 设置 QoS 级别,当资源不足时会优先 kill 掉优先级低的 Pod。在实际使用过程中,通过 OOM分数值来实现,OOM 分数值范围为 0-1000,OOM 分数值根据 OOM_ADJ参数计算得出。
对于 Guaranteed级别的 Pod,OOM_ADJ 参数设置成了-998,对于 Best-Effort级别的 Pod,OOM_ADJ 参数设置成了1000,对于 Burstable级别的 Pod,OOM_ADJ 参数取值从 2 到 999。(可以使用 cat /proc/$PID/oom_score命令查看进程的 OOMScore。)
QoS Pods 被 kill 掉的场景和顺序如下所示:
- Best-Effort Pods:系统用完了全部内存时,该类型 Pods 会最先被 kill 掉
- Burstable Pods:系统用完了全部内存,且没有 Best-Effort 类型的容器可以被 kill 时,该类型的 Pods 会被 kill 掉
- Guaranteed Pods:系统用完了全部内存,且没有 Burstable 与 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被 kill 掉
所以如果资源充足,可将 QoS Pods 类型设置为 Guaranteed,用计算资源换业务性能和稳定性,减少排查问题时间和成本。如果想更好的提高资源利用率,业务服务可以设置为 Guaranteed,而其他服务根据重要程度可分别设置为 Burstable 或 Best-Effort,这就要看具体的场景了。
比如我们这里如果想要尽可能提高 Wordpress 应用的稳定性,我们可以将其设置为 Guaranteed类型的 Pod,我们现在没有设置 resources 资源,所以现在是 Best-Effort类型的 Pod。
==扩展:==
Kubernetes 是通过 cgroup 给 pod 设置 QoS 级别的,kubelet 中有一个 --cgroups-per-qos参数(默认启用),启用后 kubelet 会为不同 QoS 创建对应的 level cgroups,在 Qos level cgroups 下也会为 pod 下的容器创建对应的 level cgroups,从 Qos –>pod –>container,层层限制每个 level cgroups 的资源使用量。
由于我们这里使用的是 containerd 这种容器运行时,则 cgroup 的路径与之前的 docker 不太一样:
- Guaranteed 类型的 cgroup level 会直接创建在
RootCgroup/system.slice/containerd.service/kubepods-pod<uid>.slice:cri-containerd:<container-id>下 - Burstable 的创建在
RootCgroup/system.slice/containerd.service/kubepods-burstable-pod<uid>.slice:cri-containerd:<container-id>下 - BestEffort 类型的创建在
RootCgroup/system.slice/containerd.service/kubepods-besteffort-pod<uid>.slice:cri-containerd:<container-id>下
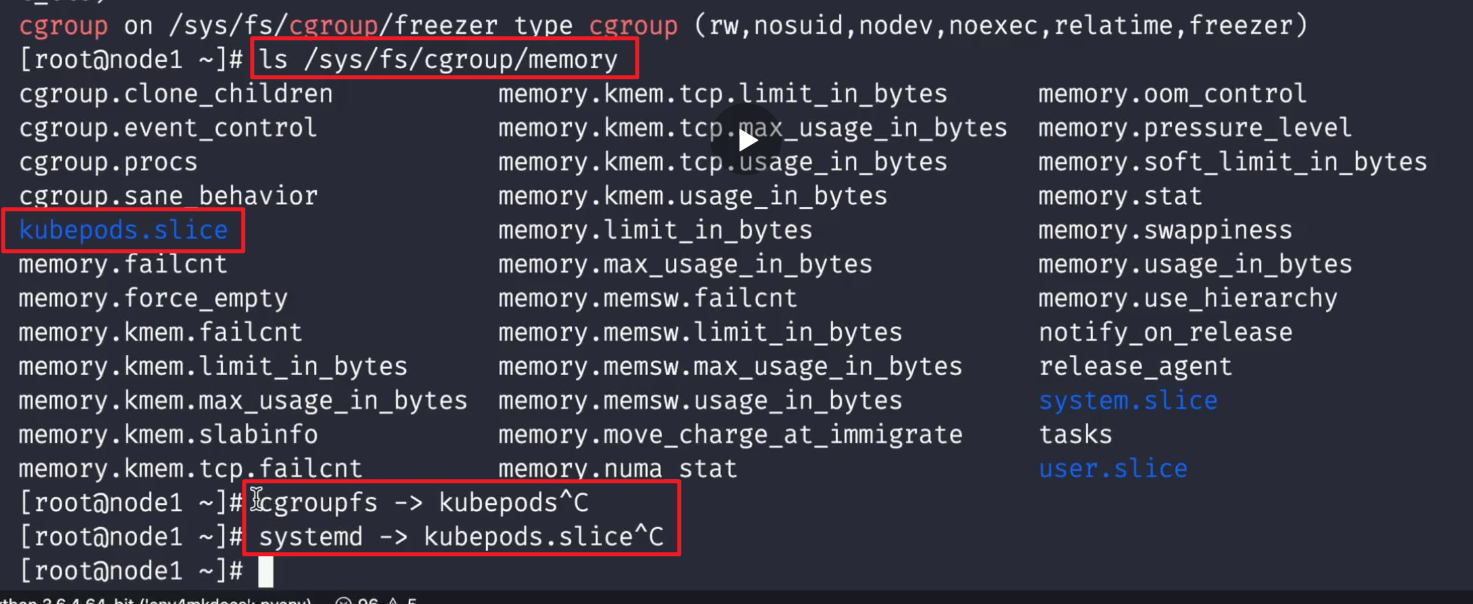
这里的路径和底层容器运行时及是否使用systemd还是cgroupfs都是不一样的。
如何给容器设置合适的资源大小
当在 Kubernetes 中使用容器时,重要的是要知道所涉及的资源是什么以及如何需要它们。有些进程比其他进程需要更多的 CPU 或内存。有些是关键的,不应该被饿死。 知道了这一点,我们应该正确配置我们的容器和 Pod,以获得两者的最佳效果。
关键是你作为运维,你要大概清楚每个服务消耗资源的情况
我们知道,tomcat一般是比较耗费资源的,起码需要1c以上;(java应用特别消耗cpu资源、内存资源)
如果你的pod里的requests配置为0.5c,而limits就配置为了0.8c,那么有可能你的容器都启动不起来;不像nginx,你给它个100m,200m,它都能起来。
现在如果要想给应用设置资源大小,就又有一个问题了,应该如何设置合适的资源大小呢?其实这就需要我们对自己的应用非常了解才行了,一般情况下我们可以先不设置资源,然后可以根据我们的应用的并发和访问量来进行压力测试,基本上可以大概计算出应用的资源使用量。
可以利用fortio工具来进行压力测试。
下面是一个示例:
我们这里使用 Apache Bench(AB Test)或者 Fortio(Istio 测试工具)这样的测试工具来测试,我们这里使用 Fortio 这个测试工具,比如每秒 1000 个请求和 8 个并发的连接的测试命令如下所示:
$fortioload-a-c5-qps1000-t60s"http:16:42:13Iscli.go:88>StartingΦορτίο1.53.1h1:aeAWrnkXIBEdhueQLRwvaM5INulybDP+ZgOChgKz/NQ=go1.19.1arm64darwinFortio1.53.1runningat1000queriespersecond,10->10procs,for1m0s:http:16:42:13Ihttprunner.go:99>Startinghttptestforhttp:Startingat1000qpswith5thread(s) [gomax 10]for1m0s:12000callseach(total 60000)# ......Socketsused:19(for perfectkeepalive,wouldbe5)Uniform:false,Jitter:false,Catchupallowed:trueIPaddressesdistribution:43.137.1.207:32411:19Code-1:14(8.4 %)Code200:153(91.6 %)ResponseHeaderSizes:count167avg290.86228+/-45.56min0max298sum48574ResponseBody/TotalSizes:count167avg50216.443+/-9456min0max52409sum8386146Alldone167calls(plus 5warmup) 1837.452 ms avg,2.7 qpsSuccessfullywrote6213bytesofJsondatato2023-03-14-164213_k8s_youdianzhishi_com_32411_bogon.json也可以通过浏览器(执行 fortio server命令)查看到最终测试结果:
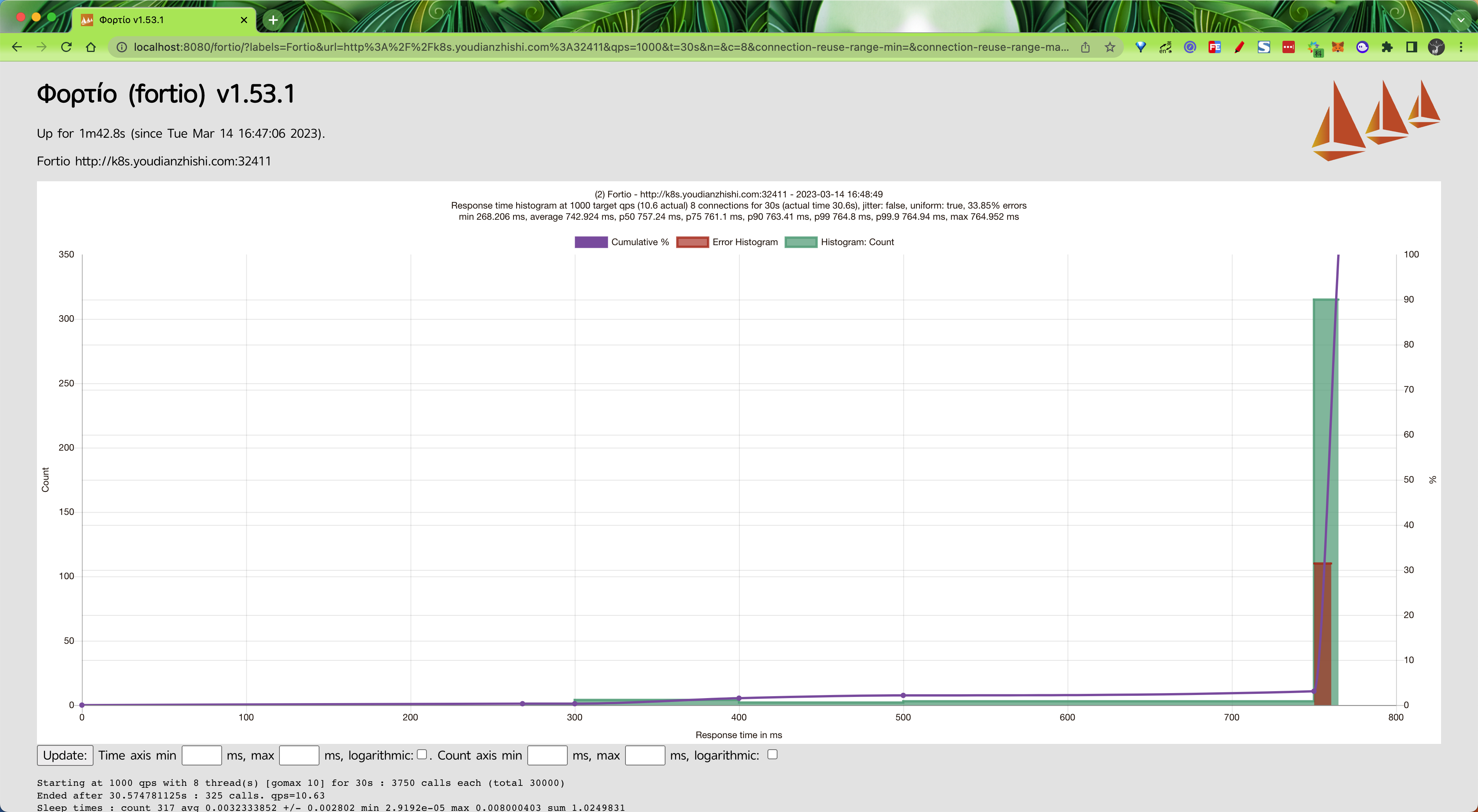
在测试期间我们可以用如下所示的命令查看应用的资源使用情况:
$kubectltoppods-lapp=wordpress-nkube-exampleNAMECPU(cores) MEMORY(bytes)mysql-015m213Miwordpress-55b57b745f-f28tr88m95Miwordpress-55b57b745f-gn8jc89m90Miwordpress-55b57b745f-r7x2w90m94Mi我们可以看到内存基本上都是处于 100Mi 以内,CPU 消耗也很小,但是由于 CPU 是可压缩资源,也就是说超过了限制应用也不会挂掉的,只是会变慢而已。所以我们这里可以给 Wordpress 应用添加如下所示的资源配置,如果你集群资源足够的话可以适当多分配一些资源:
resources:limits:cpu:150mmemory:150Mirequests:cpu:150mmemory:150Mi
配置后更新应用。
案例
resources.requests测试
==💘 实践:resources.requests测试(测试成功)-2022.5.17==
- 创建yaml
[root@k8s-master ~]#kubectl run pod6 --image=nginx --dry-run=client -o yaml >resources.yamlroot@k8s-master ~]#vim resources.yamlapiVersion:v1kind:Podmetadata:labels:run:pod6name:pod6spec:containers:- image:nginxname:pod6部署并查看:
[root@k8s-master ~]#kubectl apply -f resources.yaml[root@k8s-master ~]#kubectl get pod
- 拷贝刚才创建的那个yaml文件并修改配置
[root@k8s-master ~]#cp resources.yaml resources2.yaml[root@k8s-master ~]#vim resources2.yamlapiVersion:v1kind:Podmetadata:labels:run:resource-2name:resource-2spec:containers:- image:nginxname:resource-2resources:#最小资源requests:cpu:1500mmemory:512Mi#这里的单位写错了,应该是Mi才对的。。。部署并查看,resource-2也起来了:
- 再次拷贝刚才创建的那个yaml文件并修改配置
[root@k8s-master ~]#cp resources2.yaml resources3.yaml[root@k8s-master ~]#vim resources3.yaml[root@k8s-master ~]#kubectl apply -f resources3.yamlpod/resource-3created[root@k8s-master ~]#
部署并查看效果:
此时发现最后创建的那个pod 一直是pending状态:
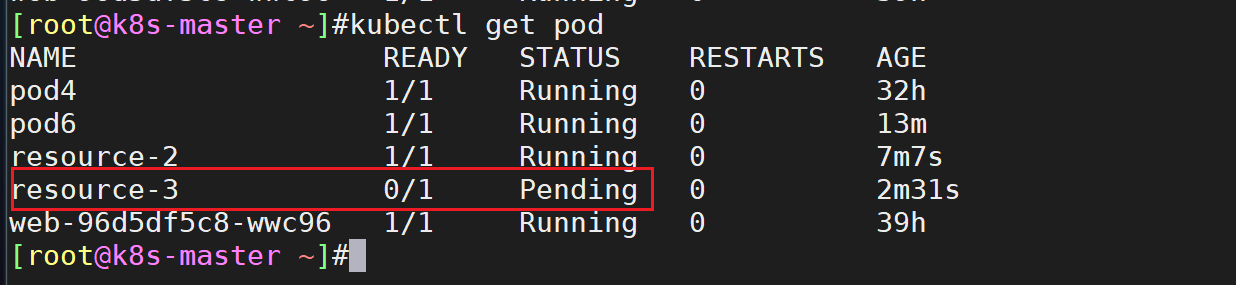
- 为什么呢?我们查看一下它的描述:
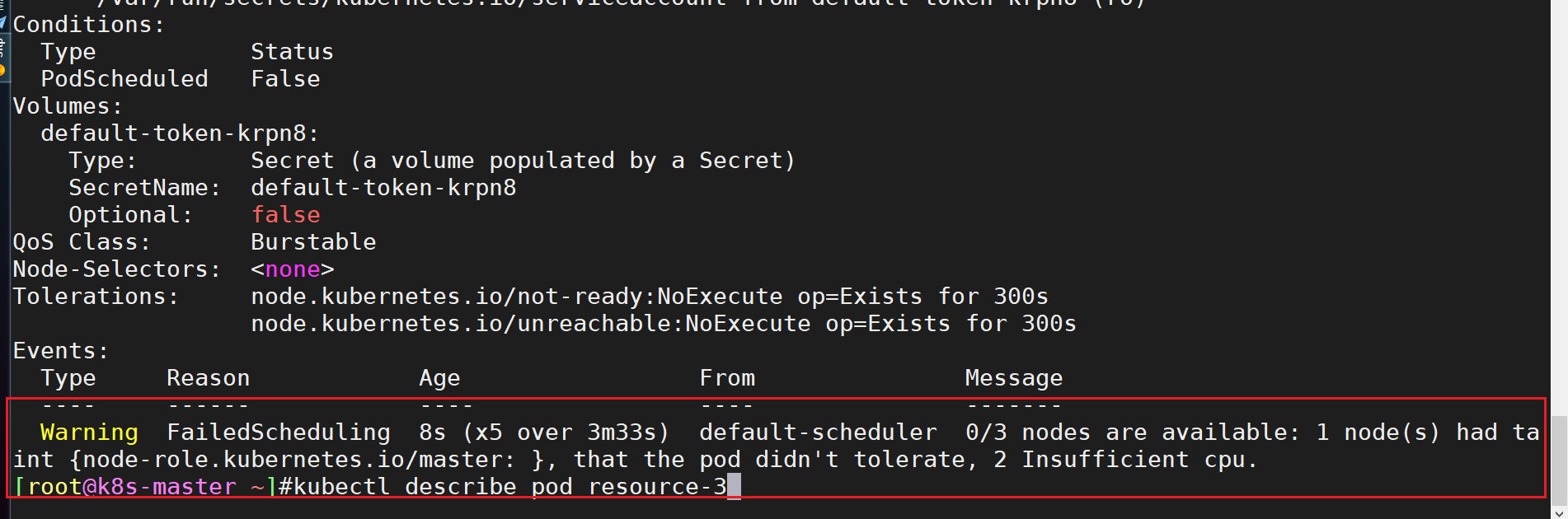
是因为node节点的cpu不足,导致pod调度失败的;
sufficient adj.充足的,足够的 insufficient adj.不充足的,不足够的
- 自己机器计算配置大小:
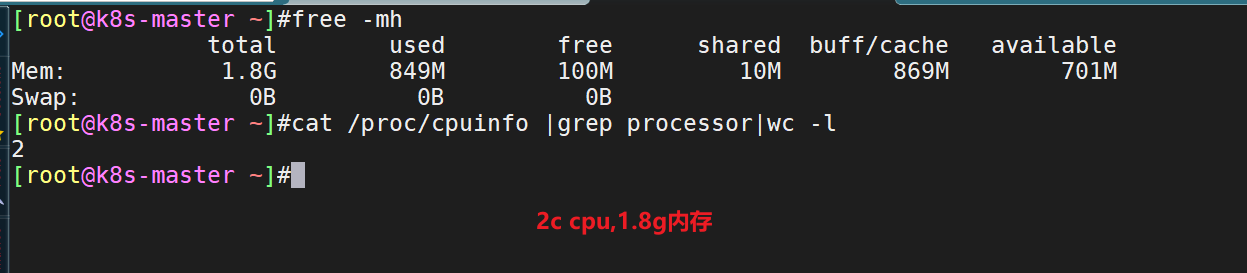
查看宿主机的资源使用率情况:
[root@k8s-master ~]#kubectl describe node k8s-node1可分配的:
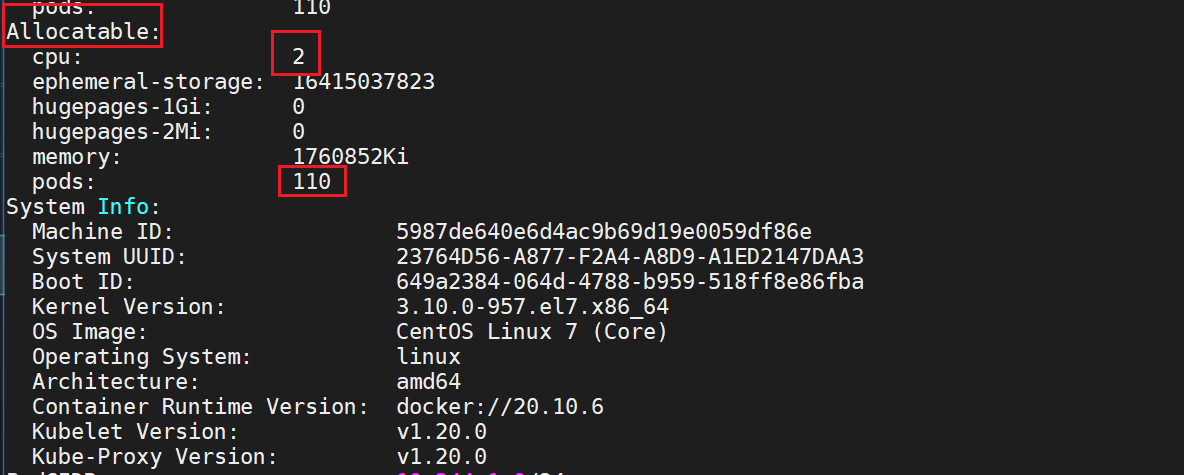
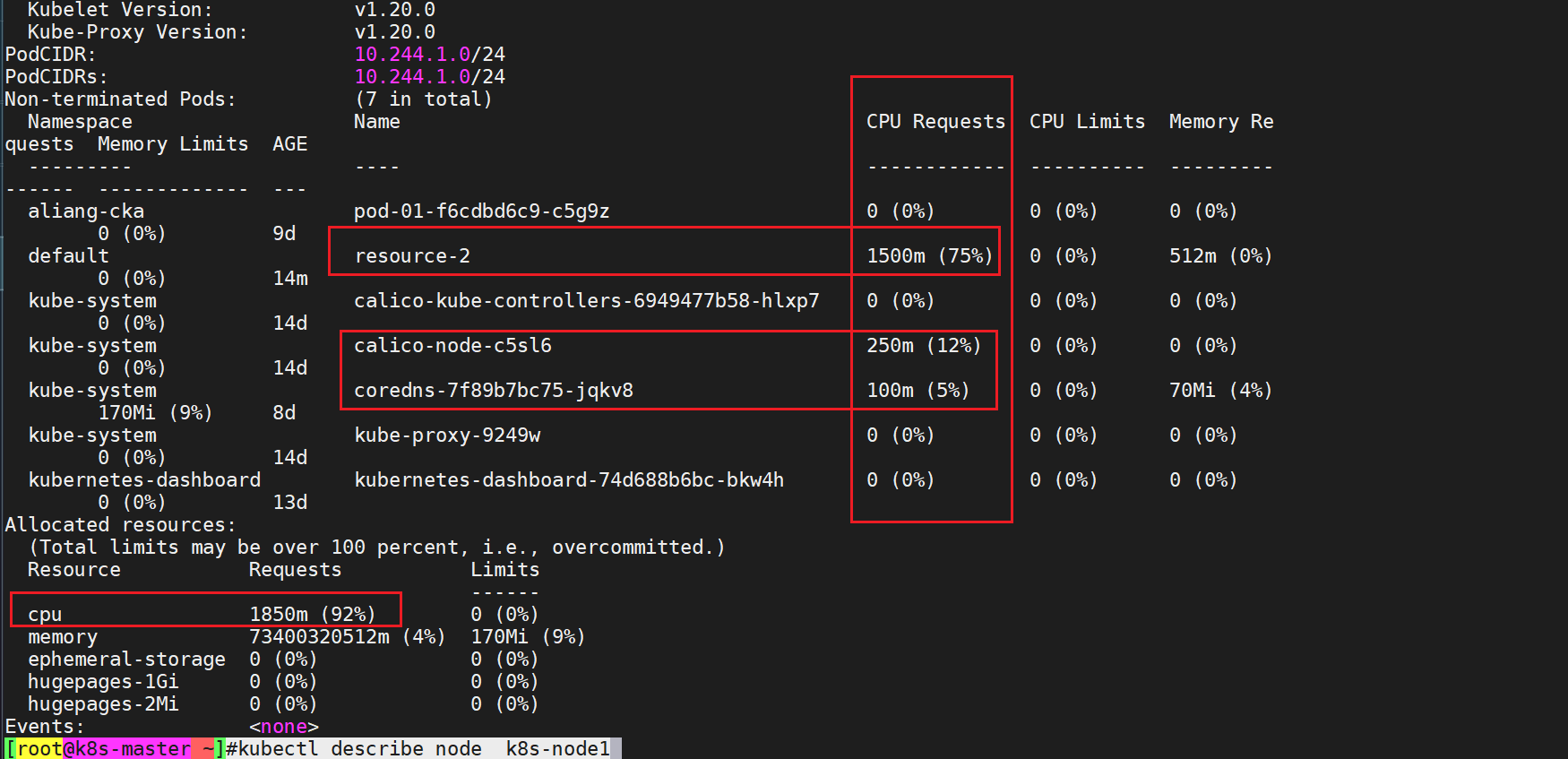
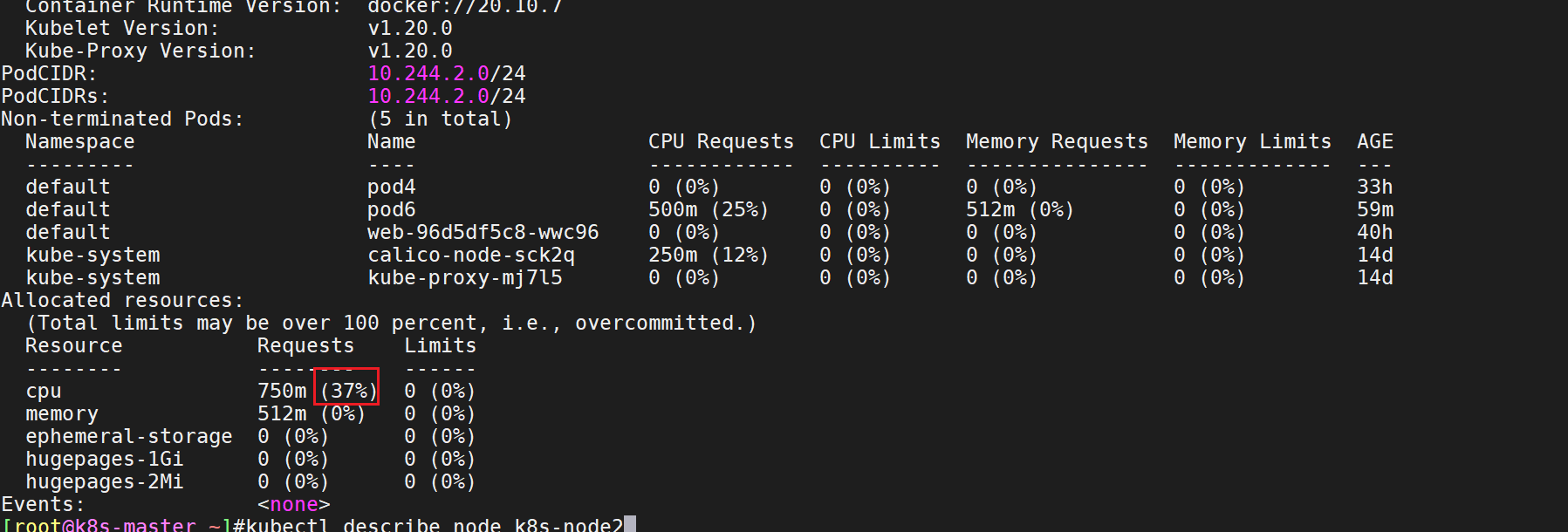
- 此时,node1可用cpu容量为:8%m node2可用总量为:63%m
而此时resource3.yaml里的pod需求为1900m,很明显以上2个node均无法满足其需求,因此和这个pod将无法被分配,一直处于pending状态。
实验结束。😘
resources.limits测试
==💘 实践:resources.limits测试(测试成功)-2022.5.17==
- 创建yaml并修改
[root@k8s-master ~]#cp resources3.yaml resources4.yaml[root@k8s-master ~]#vim resources4.yamlapiVersion:v1kind:Podmetadata:labels:run:resource-4name:resource-4spec:containers:- image:nginxname:resource-4resources:#最小资源requests:cpu:500mmemory:512Mi#最大资源,一般是requests 20%左右limits:cpu:600mmemory:612Mi最大资源,一般是requests 20%左右
- apply下并查看
[root@k8s-master ~]#kubectl apply -f resources4.yaml #这个是不会用影响调度的pod/resource-4created[root@k8s-master ~]#kubectl get podNAMEREADYSTATUSRESTARTSAGEpod41/1Running033hpod61/1Running081mresource-21/1Running075mresource-30/1Pending070mresource-41/1Running06s#已成功启动podweb-96d5df5c8-wwc961/1Running041h[root@k8s-master ~]#- pod 里容器的最大使用上线是可以查看的
[root@k8s-master ~]#kubectl describe pod resource-4
- 我们再次测试下:把limits对应值改大,会不会影响pod开通?=>不会。
[root@k8s-master ~]#cp resources4.yaml resources5.yaml[root@k8s-master ~]#vim resources5.yamlapiVersion:v1kind:Podmetadata:labels:run:resource-5name:resource-5spec:containers:- image:nginxname:resource-5resources:#最小资源requests:cpu:500mmemory:512Mi#最大资源,一般是requests 20%左右limits:cpu:1900m#把这个改成1900m,看会不会影响它开通memory:612Mi[root@k8s-master ~]#kubectl apply -f resources5.yamlpod/resource-5created[root@k8s-master ~]#kubectl get podNAMEREADYSTATUSRESTARTSAGEpod41/1Running033hpod61/1Running088mresource-21/1Running081mresource-30/1Pending077mresource-41/1Running06m45sresource-51/1Running06s#可正常web-96d5df5c8-wwc961/1Running041h[root@k8s-master ~]#是不会受影响的,就可以正常开通。
- 因此,最终yaml文件标准输出:
[root@k8s-master ~]#vim resources5.yamlapiVersion:v1kind:Podmetadata:labels:run:resource-5name:resource-5spec:containers:- image:nginxname:resource-5resources:#最小资源requests:cpu:500mmemory:512Mi#最大资源,一般是requests 20%左右limits:cpu:600mmemory:612Mi实验结束。😘
resources.limits/request测试
让我们来看看下面这个 deployment,我们需要为两个不同的容器在 CPU 和内存上设置 Limits 和 Requests。
kind: DeploymentapiVersion: extensions/v1beta1…template: spec: containers: - name: redis image: redis:5.0.3-alpine resources: limits: memory: 600Mi cpu: 1 requests: memory: 300Mi cpu: 500m - name: busybox image: busybox:1.28 resources: limits: memory: 200Mi cpu: 300m requests: memory: 100Mi cpu: 100m假如,我们要把该 deployment 部署到 4C16G 配置的节点上,可以得到如下信息。

Pod 的有效请求是 400 MiB 的内存和 600 millicores 的 CPU,你需要一个有足够自由可分配空间的节点来安排 pod。
Redis 容器的 CPU 份额将是 512,而 busybox 容器是 102,==Kubernetes 总是为每个核心分配 1024 个份额==,因此 redis:1024 *0.5 cores ≅ 512 和 busybox:1024 *0.1 核 ≅ 102
如果 Redis 容器试图分配超过 600MB 的 RAM,它将被 ==OOM==杀死,很可能使 pod 失败。
如果 Redis 试图在每 100ms 内使用超过 100ms 的 CPU,(因为我们有 4 个核心,可用时间为每 100ms 400ms),它将遭受 CPU 节流,导致性能下降。
如果 Busybox 容器试图分配超过 200MB 的 RAM,它将被 OOM 杀死,导致一个失败的 Pod。
如果 Busybox 试图每 100ms 使用超过 30ms 的 CPU,它将遭受 CPU 节流,导致性能下降。
cgroup控制pod里容器resource.limit测试
==💘 实践:Qos解析(测试成功)-2022.5.17==
- 我们可以通过
mount |grep cgroup命令查看 RootCgroup:
➜mount|grepcgrouptmpfson/sys/fs/cgrouptypetmpfs(ro,nosuid,nodev,noexec,mode=755)cgroupon/sys/fs/cgroup/systemdtypecgroup(rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)cgroupon/sys/fs/cgroup/blkiotypecgroup(rw,nosuid,nodev,noexec,relatime,blkio)cgroupon/sys/fs/cgroup/cpusettypecgroup(rw,nosuid,nodev,noexec,relatime,cpuset)cgroupon/sys/fs/cgroup/cpu,cpuaccttypecgroup(rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)cgroupon/sys/fs/cgroup/memorytypecgroup(rw,nosuid,nodev,noexec,relatime,memory)cgroupon/sys/fs/cgroup/perf_eventtypecgroup(rw,nosuid,nodev,noexec,relatime,perf_event)cgroupon/sys/fs/cgroup/devicestypecgroup(rw,nosuid,nodev,noexec,relatime,devices)cgroupon/sys/fs/cgroup/pidstypecgroup(rw,nosuid,nodev,noexec,relatime,pids)cgroupon/sys/fs/cgroup/hugetlbtypecgroup(rw,nosuid,nodev,noexec,relatime,hugetlb)cgroupon/sys/fs/cgroup/net_cls,net_priotypecgroup(rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)cgroupon/sys/fs/cgroup/freezertypecgroup(rw,nosuid,nodev,noexec,relatime,freezer)在 cgroup 的每个子系统下都会创建 QoS level cgroups, 此外在对应的 QoS level cgroups 还会为 pod 创建 Pod level cgroups。
- 比如我们创建一个如下所示的 Pod:
# 01-qos-demo.yamlapiVersion:v1kind:Podmetadata:name:qos-demospec:containers:- name:nginximage:nginx:latestresources:requests:cpu:250mmemory:1Gilimits:cpu:500mmemory:2Gi直接创建上面的资源对象即可:
$kubectlapply-f01-qos-demo.yamlpod/qos-democreated$kubectlgetpoqos-demo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESqos-demo1/1Running027s10.244.1.241node1<none><none>$kubectlgetpoqos-demo-owide-oyaml|grepqosClassqosClass:Burstable$kubectlgetpoqos-demo-owide-oyaml|grepuiduid:562d098f-8346-4e8f-b23d-9d8c24b75b6a由于该 pod 的设置的资源 requests !=limits,所以其属于 Burstable 类别的 pod。
kubelet 会在其所属 QoS 下创建 RootCgroup/system.slice/containerd.service/kubepods-burstable-pod<uid>.slice:cri-containerd:<container-id>这个 cgroup level,比如我们查看内存这个子系统的 cgroup:
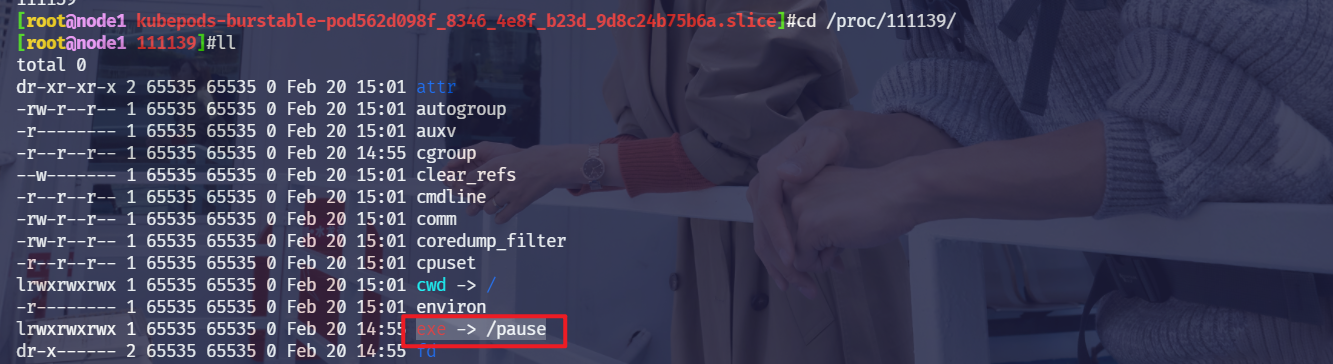
# 还有一个 pause 容器的 cgroup level➜ls/sys/fs/cgroup/memory/system.slice/containerd.service/kubepods-burstable-pod489a19f2_8d75_474c_988f_5854b61b839f.slice:cri-containerd:4782243ba3260125513af20689fcea31b52eae1cbabeafeb1f7a52bcdcd5b44bcgroup.clone_childrenmemory.kmem.tcp.max_usage_in_bytesmemory.oom_controlcgroup.event_controlmemory.kmem.tcp.usage_in_bytesmemory.pressure_levelcgroup.procsmemory.kmem.usage_in_bytesmemory.soft_limit_in_bytesmemory.failcntmemory.limit_in_bytesmemory.statmemory.force_emptymemory.max_usage_in_bytesmemory.swappinessmemory.kmem.failcntmemory.memsw.failcntmemory.usage_in_bytesmemory.kmem.limit_in_bytesmemory.memsw.limit_in_bytesmemory.use_hierarchymemory.kmem.max_usage_in_bytesmemory.memsw.max_usage_in_bytesnotify_on_releasememory.kmem.slabinfomemory.memsw.usage_in_bytestasksmemory.kmem.tcp.failcntmemory.move_charge_at_immigratememory.kmem.tcp.limit_in_bytesmemory.numa_stat上面创建的应用容器进程 ID 会被写入到上面的 tasks 文件中:
➜cattasks6413364170641716417264173➜ps-aux|grepnginxroot641330.00.088403488?Ss15:560:00nginx:masterprocessnginx-gdaemonoff;101641700.00.092281532?S15:560:00nginx:workerprocess101641710.00.092281532?S15:560:00nginx:workerprocess101641720.00.092281532?S15:560:00nginx:workerprocess101641730.00.092281532?S15:560:00nginx:workerprocess这样我们的容器进程就会受到该 cgroup 的限制了,在 pod 的资源清单中我们设置了 memory 的 limits 值为 2Gi,kubelet 则会将该限制值写入到 memory.limit_in_bytes中去:
➜catmemory.limit_in_bytes2147483648# 2147483648 / 1024 / 1024 / 1024 =2- 同样对于 cpu 资源一样可以在对应的子系统中找到创建的对应 cgroup:
➜ls/sys/fs/cgroup/cpu/system.slice/containerd.service/kubepods-burstable-pod489a19f2_8d75_474c_988f_5854b61b839f.slice:cri-containerd:4782243ba3260125513af20689fcea31b52eae1cbabeafeb1f7a52bcdcd5b44bcgroup.clone_childrencpuacct.statcpu.cfs_period_uscpu.rt_runtime_usnotify_on_releasecgroup.event_controlcpuacct.usagecpu.cfs_quota_uscpu.sharestaskscgroup.procscpuacct.usage_percpucpu.rt_period_uscpu.stat➜cattasks6413364170641716417264173➜catcpu.cfs_quota_us50000# 500m cpu.cfs_quota_us/100us实验结束。😘
总结
我们要明确在调度时调度器只会根据 requests 值进行调度。
在 Kubernetes 中:
如果你想避免饥饿(确保每个重要的进程都能得到它的份额),你应该首先使用请求。
通过设置限制,你只是防止进程在特殊情况下检索额外的资源,在内存方面造成 ==OOM 杀戮==,在 CPU 方面造成 ==Throttling==(进程将需要等待 CPU 可以再次使用)。
所以,我们工作中,一定要配置requests和limits,来解决资源争抢问题;
**如前所述,除非在非常特殊的情况下,否则不应该使用 Kubernetes 限制,因为它们可能会造成更大的伤害。**在内存不足的情况下,容器有可能被杀死,在 CPU 不足的情况下,容器有可能被节流。
对于请求,当你需要确保一个进程获得一个有保障的资源份额时,可以使用它们。
如果你在一个 Pod 的所有容器中设置一个等于限制的请求值,该 Pod 将获得保证的(最高优先级)服务质量。
还需要注意的是,==资源使用量高于请求的 Pod 更有可能被驱逐,所以设置非常低的请求会造成弊大于利==。
宿主机只有2c,这里的limits可以设置为100c,但是毫无意义,只是可以这样设置。limits是最大可用资源,一般是requests的20%左右,不太超出太多,否则limits限制就没多少意义了;
limits不能小于requests;
reqeusts只是一个预留性质,不是pod配置写多少,宿主机就会占用多少资源;
资源配额 &资源限制
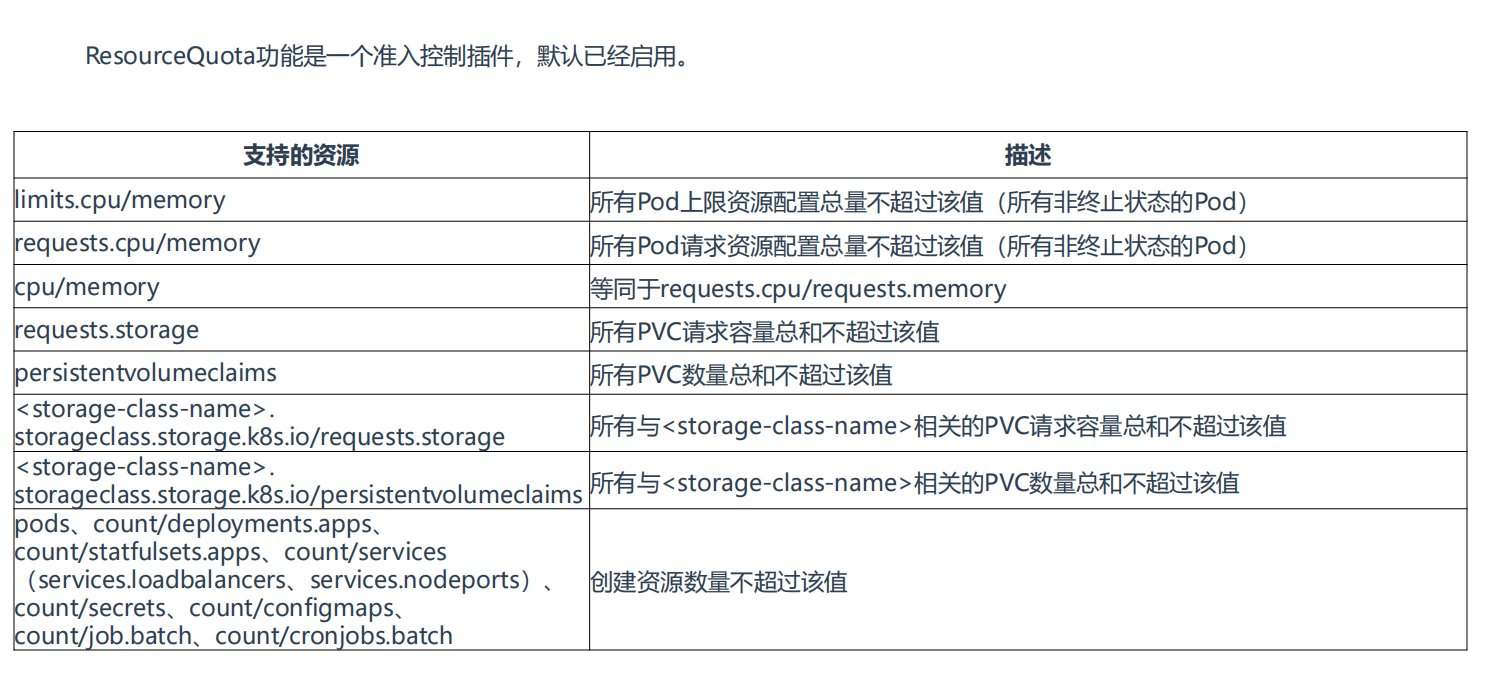
1、资源配额(ResourceQuota)
==Namespace ResourceQuata==
介绍
资源配额 ResourceQuota:限制命名空间总容量。
由于命名空间的存在,我们可以将 Kubernetes 资源隔离到不同的组,也称为租户。
当多个团队、多个用户共享使用K8s集群时,会出现不均匀资源使用,默认情况下先到先得,这时可以通过ResourceQuota来对命名空间资源使用总量做限制,从而解决这个问题。
通过 ResourceQuota,你可以为整个命名空间设置一个内存或 CPU 限制,确保其中的实体不能消耗超过这个数量。
apiVersion:v1kind:ResourceQuotametadata:name:mem-cpu-demospec:hard:requests.cpu:2requests.memory:1Gilimits.cpu:3limits.memory:2Girequests.cpu:这个命名空间中所有请求的最大 CPU 数量。
requests.memory:这个命名空间中所有请求的最大内存量。
limits.cpu:这个命名空间中所有限制的最大 CPU 数量。
limits.memory:这个命名空间中所有限制的总和的最大内存量。
然后,将其应用于你的命名空间:
kubectlapply-fresourcequota.yaml--namespace=mynamespace你可以用以下方法列出一个命名空间的当前 ResourceQuota:
kubectlgetresourcequota-nmynamespace🚩 注意:
注意,如果你为命名空间中的特定资源设置了 ResourceQuota,那么你就需要为该命名空间中的每个 Pod 指定相应的限制或请求。否则,Kubernetes 将返回一个 "failed quota"的错误。
Error from server (Forbidden):error when creating "mypod.yaml":pods "mypod"is forbidden:failed quota:mem-cpu-demo:must specify limits.cpu,limits.memory,requests.cpu,requests.memory如果你试图添加一个新的 Pod,其容器限制或请求超过了当前的 ResourceQuota,Kubernetes 将返回一个 "exceeded quota"的错误。
Error from server (Forbidden):error when creating "mypod.yaml":pods "mypod"is forbidden:exceeded quota:mem-cpu-demo,requested:limits.memory=2Gi,requests.memory=2Gi,used:limits.memory=1Gi,requests.memory=1Gi,limited:limits.memory=2Gi,requests.memory=1Gi使用流程:k8s管理员为每个命名空间创建一个或多个ResourceQuota对象,定义资源使用总量,K8s会跟踪命名空间资源使用情况,当超过定义的资源配额会返回拒绝。
案例
==💘 实战:资源配额 ResourceQuota-2023.5.25(测试成功)==

- 实验环境
实验环境:1、win10,vmwrokstation虚机;2、k8s集群:3台centos7.61810虚机,1个master节点,2个node节点k8sversion:v1.20.0docker:namespace/testcreated- 创建ResourceQuota资源
[root@k8s-master1 ~]#mkdir ResourceQuota[root@k8s-master1 ~]#cd ResourceQuota/[root@k8s-master1 ResourceQuota]#vim compute-resources.yamlapiVersion:v1kind:ResourceQuotametadata:name:compute-resourcesnamespace:testspec:hard:requests.cpu:"1"requests.memory:1Gilimits.cpu:"2"limits.memory:2Gi#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f compute-resources.yamlresourcequota/compute-resources configured#查看当前配置的ResourceQuota[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 2m37s requests.cpu:0/1,requests.memory:0/1Gi limits.cpu:0/2,limits.memory:0/2Gi- 部署一个pod应用
[root@k8s-master1 ResourceQuota]#kubectl run web --image=nginx --dry-run=client -oyaml >pod.yaml[root@k8s-master1 ResourceQuota]#vim pod.yaml#删除没用的配置,并配置上resourcesapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:webresources:requests:cpu:0.5memory:0.5Gilimits:cpu:1memory:1Gi#部署pod[root@k8s-master1 ResourceQuota]#kubectl apply -f pod.yamlError from server (Forbidden):error when creating "pod.yaml":pods "web"is forbidden:failed quota:compute-resources:must specify limits.cpu,limits.memory#注意:在部署pod时会看到报错,提示"pods "web"is forbidden:failed quota:compute-resources:must specify limits.cpu,limits.memory",因为test命名空间配置了ResourceQuota,pod里只配置requests会报错;#测试:如果不配置resource,看会否会报错?cat pod.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:web#resources:# requests:# cpu:0.5# memory:0.5Gi[root@k8s-master1 ResourceQuota]#kubectl apply -f pod.yamlError from server (Forbidden):error when creating "pod.yaml":pods "web"is forbidden:failed quota:compute-resources:must specify limits.cpu,limits.memory,requests.cpu,requests.memory[root@k8s-master1 ResourceQuota]#kubectl get po -ntestNo resources found in test namespace.#现象:也是会报错的!!!#结论:只要是配置了ResourceQuota的命名空间,pod里必须要配置上limits.cpu,limits.memory,requests.cpu,requests.memory,否则`会返回拒绝`,无法成功创建资源的。#重新配置pod:补加limits配置[root@k8s-master1 ResourceQuota]#vim pod.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:webresources:requests:cpu:0.5memory:0.5Gilimits:cpu:1memory:1Gi#重新部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f pod.yamlpod/web created- 查看
#查看:[root@k8s-master1 ResourceQuota]#kubectl get po -ntestNAMEREADYSTATUSRESTARTSAGEweb1/1Running026s[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAMEAGEREQUESTLIMITcompute-resources8hrequests.cpu:500m/1,requests.memory:512Mi/1Gilimits.cpu:1/2,limits.memory:1Gi/2Gi#可以看到,此时ResourceQuota下可以清楚地看到requests.cpu,requests.memory,limits.cpu,limits.memory的当前使用量/总使用量。- 这里测试下,若继续在test命名空间下新建pod,如果pod里cpu或者memory的requests值之和超过ResourceQuota里定义的,预计会报错。当然,pod里cpu或者memory的limits值之和超过ResourceQuota里定义的,同理也会报错。接下来,我们测试下看看。
测试:如果pod里cpu或者memory的requests值之和超过ResourceQuota里定义的,预计会报错。
[root@k8s-master1 ResourceQuota]#cp pod.yaml pod1.yaml[root@k8s-master1 ResourceQuota]#vim pod1.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:web2namespace:testspec:containers:- image:nginxname:webresources:requests:cpu:0.6memory:0.5Gilimits:cpu:1memory:1Gi#部署,并观察现象:[root@k8s-master1 ResourceQuota]#kubectl apply -f pod1.yamlError from server (Forbidden):error when creating "pod1.yaml":pods "web2"is forbidden:exceeded quota:compute-resources,requested:requests.cpu=600m,used:requests.cpu=500m,limited:requests.cpu=1[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:500m/1,requests.memory:512Mi/1Gi limits.cpu:1/2,limits.memory:1Gi/2Gi结论:如果pod里cpu或者memory的requests值之和超过ResourceQuota里定义的,创建新的pod会报错。
测试:如果pod里cpu或者memory的limits值之和超过ResourceQuota里定义的,预计会报错。
[root@k8s-master1 ResourceQuota]#cp pod.yaml pod2.yaml[root@k8s-master1 ResourceQuota]#vim pod2.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:web3namespace:testspec:containers:- image:nginxname:webresources:requests:cpu:0.5memory:0.5Gilimits:cpu:1.1memory:1Gi#部署,并观察现象:[root@k8s-master1 ResourceQuota]#kubectl apply -f pod2.yamlError from server (Forbidden):error when creating "pod2.yaml":pods "web3"is forbidden:exceeded quota:compute-resources,requested:limits.cpu=1100m,used:limits.cpu=1,limited:limits.cpu=2[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:500m/1,requests.memory:512Mi/1Gi limits.cpu:1/2,limits.memory:1Gi/2Gi结论:如果pod里cpu或者memory的limits值之和超过ResourceQuota里定义的,创建新的pod会报错。
因此:
如果某个命名空间下配置了ResourceQuota,pod里必须要配置上limits.cpu,limits.memory,requests.cpu,requests.memory,否则
会返回拒绝,无法成功创建资源的。另外,如果pod里cpu或者memory的requests&limits值之和超过ResourceQuota里定义的requests&limits,则
会返回拒绝,无法成功创建资源的。
[root@k8s-master1 ResourceQuota]#cp pod.yaml pod3.yaml[root@k8s-master1 ResourceQuota]#vim pod3.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:web3namespace:testspec:containers:- image:nginxname:webresources:requests:cpu:0.5memory:0.5Gilimits:cpu:1memory:1Gi#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f pod3.yamlpod/web3 created#查看:[root@k8s-master1 ResourceQuota]#kubectl get po -ntestNAME READY STATUS RESTARTS AGEweb 1/1 Running 0 16mweb3 1/1 Running 0 27s[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gi测试结束。😘
2.存储资源配额

- 部署ResourceQuota
[root@k8s-master1 ResourceQuota]#vim storage-resources.yamlapiVersion:v1kind:ResourceQuotametadata:name:storage-resourcesnamespace:testspec:hard:requests.storage:"10G"#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f storage-resources.yamlresourcequota/storage-resources created#查看[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gistorage-resources 8s requests.storage:0/10G- 创建pvc测试
[root@k8s-master1 ResourceQuota]#vim pvc.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvcnamespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:8Gi#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f pvc.yamlpersistentvolumeclaim/pvc created#查看:[root@k8s-master1 ResourceQuota]#kubectl get pvc -ntestNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEpvc Pending#这个pending不影响实验,这里是没有pv才导致pvc处于Pending状态 #部署成功后,可以看到ResourceQuota requests.storage这里已经发生了变化[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gistorage-resources 117s requests.storage:8Gi/10G- 我们继续在创建一个pvc,此时如果requests.storage之和超过ResourceQuota里定义的话,那么预计会报错的
[root@k8s-master1 ResourceQuota]#cp pvc.yaml pvc1.yaml[root@k8s-master1 ResourceQuota]#vim pvc1.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc1namespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:2.1Gi#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f pvc1.yamlError from server (Forbidden):error when creating "pvc1.yaml":persistentvolumeclaims "pvc1"is forbidden:exceeded quota:storage-resources,requested:requests.storage=2254857831,used:requests.storage=8Gi,limited:requests.storage=10G[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gistorage-resources 6m29s requests.storage:8Gi/10G#可以看到,此时报错了,意料之中。#我们重新部署一个pvc看看:[root@k8s-master1 ResourceQuota]#cp pvc.yaml pvc2.yaml[root@k8s-master1 ResourceQuota]#vim pvc2.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc2namespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:2Gi#部署:注意,存储这里不能使用满!!![root@k8s-master1 ResourceQuota]#kubectl apply -f pvc2.yamlError from server (Forbidden):error when creating "pvc2.yaml":persistentvolumeclaims "pvc2"is forbidden:exceeded quota:storage-resources,requested:requests.storage=2Gi,used:requests.storage=8Gi,limited:requests.storage=10G[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gistorage-resources 6m29s requests.storage:8Gi/10G#我们再次创建下pvc3.yaml看下[root@k8s-master1 ResourceQuota]#cp pvc.yaml pvc3.yaml[root@k8s-master1 ResourceQuota]#vim pvc3.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc3namespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:1Gi#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f pvc3.yamlpersistentvolumeclaim/pvc3 created#查看:符合预期,可以正常部署pvc。[root@k8s-master1 ResourceQuota]#kubectl get pvc -ntestNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEpvc Pending 9m27spvc3 Pending 9s[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 8h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Gistorage-resources 11m requests.storage:9Gi/10G[root@k8s-master1 ResourceQuota]#测试结束。😘
3.对象数量配额

- 我们来看下当前环境
[root@k8s-master1 ResourceQuota]#kubectl get po -ntestNAMEREADYSTATUSRESTARTSAGEweb1/1Running041mweb31/1Running025m- 部署ResourceQuota
[root@k8s-master1 ResourceQuota]#vim object-counts.yamlapiVersion:v1kind:ResourceQuotametadata:name:object-countsnamespace:testspec:hard:pods:"4"count/deployments.apps:"3"count/services:"3"#部署:[root@k8s-master1 ResourceQuota]#kubectl apply -f object-counts.yamlresourcequota/object-counts created#查看:[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAME AGE REQUEST LIMITcompute-resources 9h requests.cpu:1/1,requests.memory:1Gi/1Gi limits.cpu:2/2,limits.memory:2Gi/2Giobject-counts 15s count/deployments.apps:0/3,count/services:0/3,pods:2/4storage-resources 16m requests.storage:9Gi/10G[root@k8s-master1 ResourceQuota]#- 测试
#此时已经存在2个pod了,ResourceQuota里限制的pod最大数量为4,那我们接下来创建下测试pod看下#但此时为了测试方方便,我删除下前面的compute-resources.yaml,不然创建pod会报错的[root@k8s-master1 ResourceQuota]#kubectl delete -f compute-resources.yaml resourcequota"compute-resources"deleted[root@k8s-master1 ResourceQuota]#kubectl get quota -ntestNAMEAGEREQUESTLIMITobject-counts3m23scount/deployments.apps:0/3,count/services:0/3,pods:2/4storage-resources19mrequests.storage:9Gi/10G#创建3个测试pod看下[root@k8s-master1 ResourceQuota]#kubectl get po -ntestNAMEREADYSTATUSRESTARTSAGEweb1/1Running047mweb31/1Running032m[root@k8s-master1 ResourceQuota]#kubectl run web4 --image=nginx-ntestpod/web4created[root@k8s-master1 ResourceQuota]#kubectl run web5 --image=nginx-ntestErrorfromserver(Forbidden):pods "web5"is forbidden:exceeded quota:object-counts,requested:pods=1,used:pods=4,limited:pods=4#可以看到,这里报错了。测试结束。😘
汇总
- 注意事项:
- 如果某个命名空间下配置了ResourceQuota,pod里必须要配置上limits.cpu,limits.memory,requests.cpu,requests.memory,否则
会返回拒绝,无法成功创建资源的。- 如果pod里cpu或者memory的requests&limits值之和超过ResourceQuota里定义的requests&limits,则
会返回拒绝,无法成功创建资源的。(需要注意:实际创建的request和limits pod之和是可以等于这个ResourceQuota定义的数值的,但是存储资源配额:requests.storage、对象数量配额是不能超过(必须小于)ResourceQuota定义的数值,否则会报错的。)
- 这些字段是可以写在一起的

2、资源限制(LimitRange)
==Namespace LimitRange==
介绍
资源限制 LimitRange:限制容器的最大最小。(使用LimitRange定义容器默认CPU和内存请求值或者最大上限/最小上限)
如果我们想限制一个命名空间可分配的资源总量,ResourceQuotas 很有用。但如果我们想给里面的元素提供默认值,会发生什么?
LimitRanges 是一种 Kubernetes 策略,它限制了命名空间中每个实体的资源设置。
apiVersion:v1kind:LimitRangemetadata:name:cpu-resource-constraintspec:limits:- default:cpu:500mdefaultRequest:cpu:500mmin:cpu:100mmax:cpu:"1"type:Containerdefault。如果没有指定,创建的容器将有这个值。
min:创建的容器不能有比这更小的限制或请求。
max:创建的容器不能有大于此值的限制或请求。
以后,如果你创建一个没有设置请求或限制的新 Pod,LimitRange 会自动为其所有的容器设置这些值。
Limits:cpu:500mRequests:cpu:100m现在,想象一下,你添加一个新的 Pod,以 1200M 为限。你会收到以下错误。
Errorfromserver(Forbidden):error when creating "pods/mypod.yaml":pods "mypod"is forbidden:maximum cpu usage per Container is 1,but limit is 1200m请注意,默认情况下,Pod 中的所有容器将有效地拥有 100m CPU 的请求,即使没有设置 LimitRanges。
默认情况下,K8s集群上的容器对计算资源没有任何限制,可能会导致个别容器资源过大导致影响其他容器正常工作,这时可以使用LimitRange定义容器默认CPU和内存请求值或者最大上限。 LimitRange限制维度: • 限制容器配置requests.cpu/memory,limits.cpu/memory的最小、最大值 • 限制容器配置requests.cpu/memory,limits.cpu/memory的默认值 • 限制PVC配置requests.storage的最小、最大值
案例
==💘 实战:资源限制 LimitRange-2023.5.25(测试成功)==

- 实验环境
实验环境:1、win10,vmwrokstation虚机;2、k8s集群:3台centos7.61810虚机,1个master节点,2个node节点k8sversion:v1.20.0docker:[root@k8s-master1 ResourceQuota]#lscompute-resources.yamlobject-counts.yamlpod1.yamlpod2.yamlpod3.yamlpod.yamlpvc1.yamlpvc2.yamlpvc3.yamlpvc.yamlstorage-resources.yaml[root@k8s-master1 ResourceQuota]#kubectl delete -f .resourcequota"object-counts"deletedpod"web"deletedpod"web3"deletedpod"web3"deletedpersistentvolumeclaim"pvc"deletedpersistentvolumeclaim"pvc3"deletedresourcequota"storage-resources"deletedErrorfromserver(NotFound):error when deleting "compute-resources.yaml":resourcequotas "compute-resources"not foundErrorfromserver(NotFound):error when deleting "pod1.yaml":pods "web2"not foundErrorfromserver(NotFound):error when deleting "pvc1.yaml":persistentvolumeclaims "pvc1"not foundErrorfromserver(NotFound):error when deleting "pvc2.yaml":persistentvolumeclaims "pvc2"not found[root@k8s-master1 ResourceQuota]#1.计算资源最大、最小限制

- 结论:
如果命名空间里配置了LimitRange,那么后续创建的pod里容器的request值不能小于LimitRange里定义的min(request的最小值),limits值不能大于LimitRange里定义的max(limits的最大值),否则会报错的。
接下来,我们验证下上面的结论。
- 部署LimitRange
[root@k8s-master1 ~]#mkdir LimitRange[root@k8s-master1 ~]#cd LimitRange/[root@k8s-master1 LimitRange]#vim cpu-memory-min-max.yamlapiVersion:v1kind:LimitRangemetadata:name:cpu-memory-min-maxnamespace:testspec:limits:- max:# 容器能设置limit的最大值cpu:1memory:1Gimin:# 容器能设置request的最小值cpu:200mmemory:200Mitype:Container#部署[root@k8s-master1 LimitRange]#kubectl apply -f cpu-memory-min-max.yamllimitrange/cpu-memory-min-max created#查看[root@k8s-master1 LimitRange]#kubectl get limits -n testNAME CREATED ATcpu-memory-min-max 2023-05-24T23:26:13Z[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container memory 200Mi 1Gi 1Gi 1Gi -Container cpu 200m 1 1 1 -#注意:这里是有request和limit默认值的- 我们来创建一个小于request最小值,创建一个大于limit最大值的pod看下情况
创建一个小于request最小值:
[root@k8s-master1 LimitRange]#vim pod.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:webresources:requests:cpu:100mmemory:200Milimits:cpu:1memory:1Gi#部署:(符合预期效果)[root@k8s-master1 LimitRange]#kubectl apply -f pod.yamlError from server (Forbidden):error when creating "pod.yaml":pods "web"is forbidden:minimum cpu usage per Container is 200m,but request is 100m[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu 200m 1 1 1 -Container memory 200Mi 1Gi 1Gi 1Gi -创建一个大于limit最大值:
[root@k8s-master1 LimitRange]#cp pod.yaml pod1.yaml[root@k8s-master1 LimitRange]#vim pod1.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:webresources:requests:cpu:200mmemory:200Milimits:cpu:1.1memory:1Gi#部署:(符合预期效果)[root@k8s-master1 LimitRange]#kubectl apply -f pod1.yamlError from server (Forbidden):error when creating "pod1.yaml":pods "web"is forbidden:maximum cpu usage per Container is 1,but limit is 1100m[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container memory 200Mi 1Gi 1Gi 1Gi -Container cpu 200m 1 1 1 -创建一个合适的pod:
[root@k8s-master1 LimitRange]#cp pod.yaml pod2.yaml[root@k8s-master1 LimitRange]#vim pod2.yamlapiVersion:v1kind:Podmetadata:labels:run:webname:webnamespace:testspec:containers:- image:nginxname:webresources:requests:cpu:250mmemory:200Milimits:cpu:0.9memory:1Gi#部署:[root@k8s-master1 LimitRange]#kubectl apply -f pod2.yamlpod/web created#查看:[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu 200m 1 1 1 -Container memory 200Mi 1Gi 1Gi 1Gi -[root@k8s-master1 LimitRange]#kubectl get po -ntestNAME READY STATUS RESTARTS AGEweb 1/1 Running 0 20sweb4 1/1 Running 0 52m测试结束。😘
2.计算资源默认值限制

- 结论:
只要给某个命名空间配置了LimitRange,如果你的pod里不配置request、limit,也是可以创建成功pod的,则k8s会默认分配一个request、limit值的。
- 我们来看下default命名空间下的pod是否有默认request、limit值
root@k8s-master1LimitRange]#kubectlgetlimitsNoresourcesfoundindefaultnamespace.[root@k8s-master1 LimitRange]#kubectl get poNAMEREADYSTATUSRESTARTSAGEbusybox1/1Running63d10hbusybox21/1Running63d10hpy-k8s1/1Running124h[root@k8s-master1 LimitRange]#kubectl describe po busybox Name:busyboxNamespace:defaultPriority:0Node:k8s-node2/172.29.9.33StartTime:Sun,21May202320:44:21+0800Labels:run=busyboxAnnotations:cni.projectcalico.org/podIP:10.244.169.162/32……#可以看到,default命名空间下的pod是没有默认request、limit值的,因此其pod可以用尽宿主机的资源- 我们看下test命令空间下,创建一个新pod,是否会有默认request、limit值
[root@k8s-master1 LimitRange]#kubectl get limits -ntestNAMECREATEDATcpu-memory-min-max2023-05-24T23:26:13Z[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testTypeResourceMinMaxDefaultRequestDefaultLimitMaxLimit/RequestRatio---------------------------------------------------------------------Containercpu200m111-Containermemory200Mi1Gi1Gi1Gi-[root@k8s-master1 LimitRange]#kubectl run web520 --image=nginx-ntestpod/web520created[root@k8s-master1 LimitRange]#kubectl describe pod web520 -ntestName:web520Namespace:testPriority:0Node:k8s-node2/172.29.9.33StartTime:Thu,25May202307:44:16+0800Labels:run=web520Annotations:cni.projectcalico.org/podIP:10.244.169.167/32cni.projectcalico.org/podIPs:10.244.169.167/32kubernetes.io/limit-ranger:LimitRangerpluginset:cpu,memoryrequestforcontainerweb520;cpu,memorylimitforcontainerweb520Status:RunningIP:10.244.169.167IPs:IP:10.244.169.167Containers:web520:ContainerID:docker:Image:nginxImageID:docker-pullable:Port:<none>HostPort:<none>State:RunningStarted:Thu,25May202307:44:26+0800Ready:TrueRestartCount:0Limits:cpu:1memory:1GiRequests:cpu:1memory:1GiEnvironment:<none>#可以看到,是有默认值的- 接下来,我们更改下这个默认值
[root@k8s-master1 LimitRange]#vim default-cpu-memory-min-max.yamlapiVersion:v1kind:LimitRangemetadata:name:default-cpu-memory-min-maxnamespace:testspec:limits:- default:cpu:500mmemory:500MidefaultRequest:cpu:300mmemory:300Mitype:Container#部署:[root@k8s-master1 LimitRange]#kubectl apply -f default-cpu-memory-min-max.yamllimitrange/default-cpu-memory-min-max created[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu 200m 1 1 1 -Container memory 200Mi 1Gi 1Gi 1Gi -Name:default-cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu - - 300m 500m -Container memory - - 300Mi 500Mi -#可以看到,此时的默认值改变了#我们再创建一个pod看下现象[root@k8s-master1 LimitRange]#kubectl run web1314 --image=nginx -ntestpod/web1314 created[root@k8s-master1 LimitRange]#kubectl describe pod web1314 -ntestName:web1314Namespace:testPriority:0Node:k8s-node1/172.29.9.32Start Time:Thu,25 May 2023 07:51:28 +0800Labels:run=web1314Annotations:cni.projectcalico.org/podIP:10.244.36.101/32cni.projectcalico.org/podIPs:10.244.36.101/32kubernetes.io/limit-ranger:LimitRanger plugin set:cpu,memory request for container web1314;cpu,memory limit for container web1314Status:RunningIP:10.244.36.101IPs:IP:10.244.36.101Containers:web1314:Container ID:docker:Image:nginxImage ID:docker-pullable:Port:<none>Host Port:<none>State:RunningStarted:Thu,25 May 2023 07:51:30 +0800Ready:TrueRestart Count:0Limits:cpu:1memory:1GiRequests:cpu:1memory:1GiEnvironment:<none>#注意:测试出现了问题#在test命名空间有2个LimitRange资源,其default配置有冲突,但根据测试现象看,默认匹配第一条规则。#此时,我们直接在第一条规则上直接更改默认值,我们看下现象:[root@k8s-master1 LimitRange]#vim cpu-memory-min-max.yamlapiVersion:v1kind:LimitRangemetadata:name:cpu-memory-min-maxnamespace:testspec:limits:- max:cpu:1memory:1Gimin:cpu:200mmemory:200Midefault:cpu:600mmemory:600MidefaultRequest:cpu:400mmemory:400Mitype:Container#部署并查看:[root@k8s-master1 LimitRange]#kubectl apply -f cpu-memory-min-max.yamllimitrange/cpu-memory-min-max configuredroot@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu 200m 1 400m 600m -Container memory 200Mi 1Gi 400Mi 600Mi -Name:default-cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu - - 300m 500m -Container memory - - 300Mi 500Mi -#再次部署一个新pod[root@k8s-master1 LimitRange]#kubectl run web1315 --image=nginx -ntestpod/web1315 created[root@k8s-master1 LimitRange]#kubectl describe pod web1315 -ntestName:web1315Namespace:testPriority:0Node:k8s-node2/172.29.9.33Start Time:Thu,25 May 2023 07:57:39 +0800Labels:run=web1315Annotations:cni.projectcalico.org/podIP:10.244.169.168/32cni.projectcalico.org/podIPs:10.244.169.168/32kubernetes.io/limit-ranger:LimitRanger plugin set:cpu,memory request for container web1315;cpu,memory limit for container web1315Status:RunningIP:10.244.169.168IPs:IP:10.244.169.168Containers:web1315:Container ID:docker:Image:nginxImage ID:docker-pullable:Port:<none>Host Port:<none>State:RunningStarted:Thu,25 May 2023 07:57:42 +0800Ready:TrueRestart Count:0Limits:cpu:600mmemory:600MiRequests:cpu:400mmemory:400MiEnvironment:<none>Mounts:#此时,新建pod里的默认值被改变过来了,符合预期效果。测试结束。😘
3.存储资源最大、最小限制

- 和前面的计算资源一样,接下来进行测试
[root@k8s-master1 LimitRange]#vim storage-min-max.yamlapiVersion:v1kind:LimitRangemetadata:name:storage-min-maxnamespace:testspec:limits:- type:PersistentVolumeClaimmax:storage:10Gimin:storage:1Gi#部署:[root@k8s-master1 LimitRange]#kubectl apply -f storage-min-max.yamllimitrange/storage-min-max created#创建一个pvc[root@k8s-master1 LimitRange]#vim pvc.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc-storage-testnamespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:11Gi#部署pvc:[root@k8s-master1 LimitRange]#kubectl apply -f pvc.yamlError from server (Forbidden):error when creating "pvc.yaml":persistentvolumeclaims "pvc-storage-test"is forbidden:maximum storage usage per PersistentVolumeClaim is 10Gi,but request is 11Gi[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu 200m 1 400m 600m -Container memory 200Mi 1Gi 400Mi 600Mi -Name:default-cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container cpu - - 300m 500m -Container memory - - 300Mi 500Mi -Name:storage-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------PersistentVolumeClaim storage 1Gi 10Gi - - -#可以看到,自己申请的存储为11Gi,但是LimitRange里max可申请存储为10Gi,因此报错。#重新创建一个pvc[root@k8s-master1 LimitRange]#cp pvc.yaml pvc1.yaml[root@k8s-master1 LimitRange]#vim pvc1.yamlapiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc-storage-testnamespace:testspec:accessModes:- ReadWriteOnceresources:requests:storage:8Gi#部署:[root@k8s-master1 LimitRange]#kubectl apply -f pvc1.yamlpersistentvolumeclaim/pvc-storage-test created[root@k8s-master1 LimitRange]#kubectl get pvc -ntestNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEpvc-storage-test Pending 30s[root@k8s-master1 LimitRange]#kubectl describe limits -ntestName:cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container memory 200Mi 1Gi 400Mi 600Mi -Container cpu 200m 1 400m 600m -Name:default-cpu-memory-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------Container memory - - 300Mi 500Mi -Container cpu - - 300m 500m -Name:storage-min-maxNamespace:testType Resource Min Max Default Request Default Limit Max Limit/Request Ratio---- -------- --- --- --------------- ------------- -----------------------PersistentVolumeClaim storage 1Gi 10Gi - - -#部署成功,符合预期。测试结束。😘
7、拓扑分布约束
1.概念
这个理解起来稍微有些复杂; 这个可能用的不多,但如果你想进行一些细粒度的控制的话,用这个还是很不错的;
在 k8s 集群调度中,亲和性相关的概念本质上都是控制 Pod 如何被调度 -- 堆叠或打散。
podAffinity以及 podAntiAffinity两个特性对 Pod 在不同拓扑域的分布进行了一些控制。
podAffinity可以将无数个 Pod 调度到特定的某一个拓扑域,这是堆叠的体现;
podAntiAffinity则可以控制一个拓扑域只存在一个 Pod,这是打散的体现;
但这两种情况都太极端了,在不少场景下都无法达到理想的效果,例如为了实现容灾和高可用,将业务 Pod 尽可能均匀的分布在不同可用区就很难实现。
PodTopologySpread(Pod 拓扑分布约束)特性的提出正是为了对 Pod 的调度分布提供更精细的控制,以提高服务可用性以及资源利用率。PodTopologySpread由 EvenPodsSpread特性门所控制,在 v1.16 版本第一次发布,并在 v1.18 版本进入 beta 阶段默认启用。
2.使用规范
在 Pod 的 Spec 规范中新增了一个 topologySpreadConstraints字段即可配置拓扑分布约束,如下所示:
spec:topologySpreadConstraints:- maxSkew:<integer>#这个属性理解起来不是那么地直接。。。;倾斜度;topologyKey:<string>whenUnsatisfiable:<string>labelSelector:<object>由于这个新增的字段是在 Pod spec 层面添加,因此更高层级的控制 (Deployment、DaemonSet、StatefulSet) 也能使用 PodTopologySpread功能。
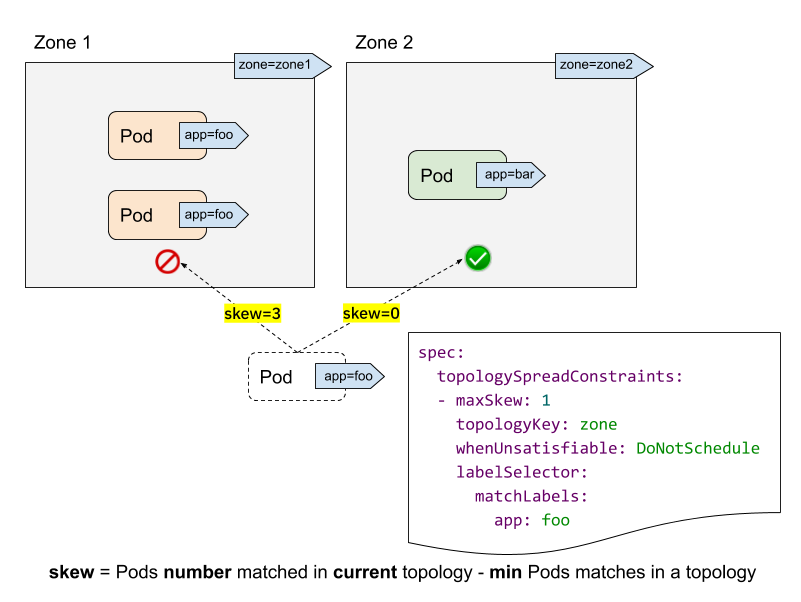
让我们结合上图来理解 topologySpreadConstraints中各个字段的含义和作用:
labelSelector:用来查找匹配的 Pod,我们能够计算出每个拓扑域中匹配该 label selector 的 Pod 数量,在上图中,假如 label selector 是app:foo,那么 zone1 的匹配个数为 2, zone2 的匹配个数为 0。topologyKey:是 Node label 的 key,如果两个 Node 的 label 同时具有该 key 并且值相同,就说它们在同一个拓扑域。在上图中,指定topologyKey为 zone, 则具有zone=zone1标签的 Node 被分在一个拓扑域,具有zone=zone2标签的 Node 被分在另一个拓扑域。maxSkew:这个属性理解起来不是很直接,它描述了 Pod在不同拓扑域中不均匀分布的最大程度(指定拓扑类型中任意两个拓扑域中匹配的 Pod 之间的最大允许差值),它必须大于零。每个拓扑域都有一个 skew 值,计算的公式是:skew[i] =拓扑域[i]中匹配的 Pod 个数 - min{其他拓扑域中匹配的 Pod 个数}。在上图中,我们新建一个带有app=foo标签的 Pod:- 如果该 Pod 被调度到 zone1,那么 zone1 中 Node 的 skew 值变为 3,zone2 中 Node 的 skew 值变为 0 (zone1 有 3 个匹配的 Pod,zone2 有 0 个匹配的 Pod )
- 如果该 Pod 被调度到 zone2,那么 zone1 中 Node 的 skew 值变为 2,zone2 中 Node 的 skew 值变为 1(zone2 有 1 个匹配的 Pod,拥有全局最小匹配 Pod 数的拓扑域正是 zone2 自己 ),则它满足
maxSkew:1的约束(差值为1)
whenUnsatisfiable:描述了如果 Pod 不满足分布约束条件该采取何种策略:- DoNotSchedule(默认) 告诉调度器不要调度该 Pod,因此也可以叫作硬策略;
- ScheduleAnyway告诉调度器根据每个 Node 的 skew 值打分排序后仍然调度,因此也可以叫作软策略。
3.单个拓扑约束
假设你拥有一个 4 节点集群,其中标记为 foo:bar的 3 个 Pod 分别位于 node1、node2 和 node3 中:
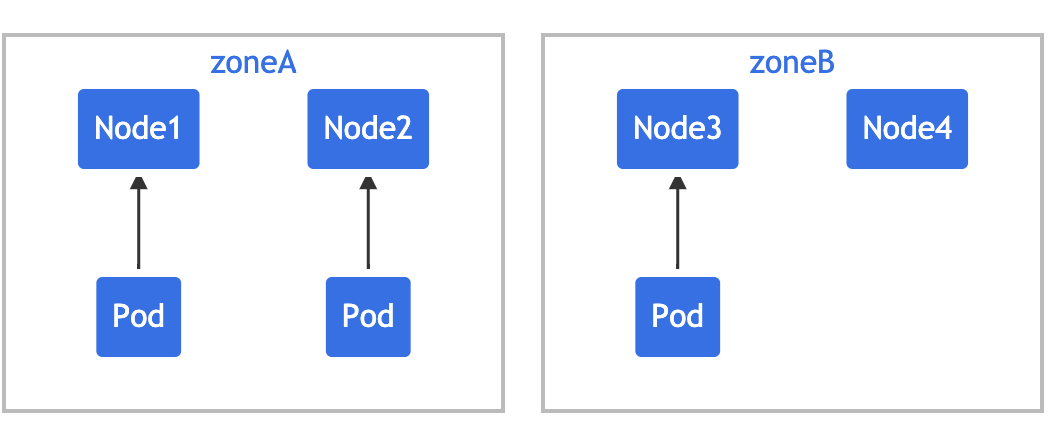
如果希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其约束:
kind:PodapiVersion:v1metadata:name:mypodlabels:foo:barspec:topologySpreadConstraints:- maxSkew:1topologyKey:zonewhenUnsatisfiable:DoNotSchedulelabelSelector:matchLabels:foo:barcontainers:- name:pauseimage:k8s.gcr.io/pause:3.1topologyKey:zone意味着均匀分布将只应用于存在标签键值对为 zone:<any value>的节点。 whenUnsatisfiable:DoNotSchedule告诉调度器如果新的 Pod 不满足约束,则不可调度。如果调度器将新的 Pod 放入 "zoneA",Pods 分布将变为 [3,1],因此实际的偏差为 2(3 - 1),这违反了 maxSkew:1的约定。此示例中,新 Pod 只能放置在 "zoneB"上:
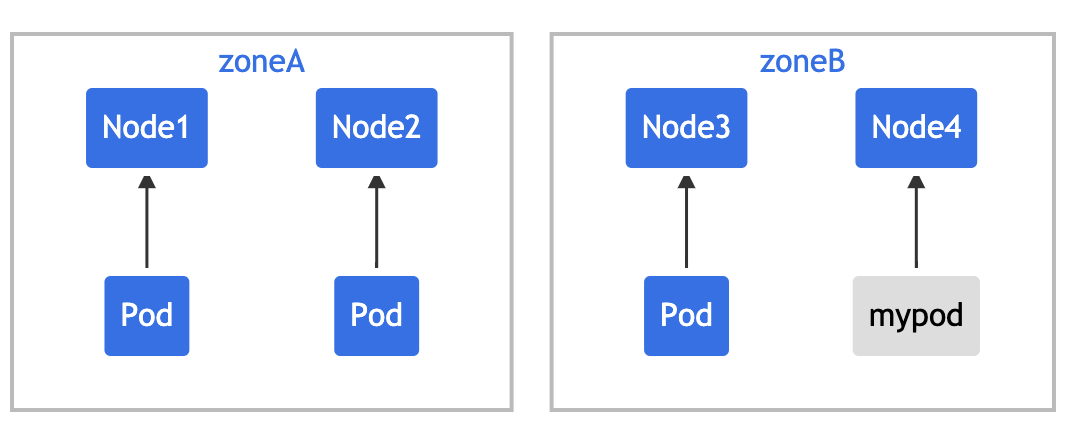
或者
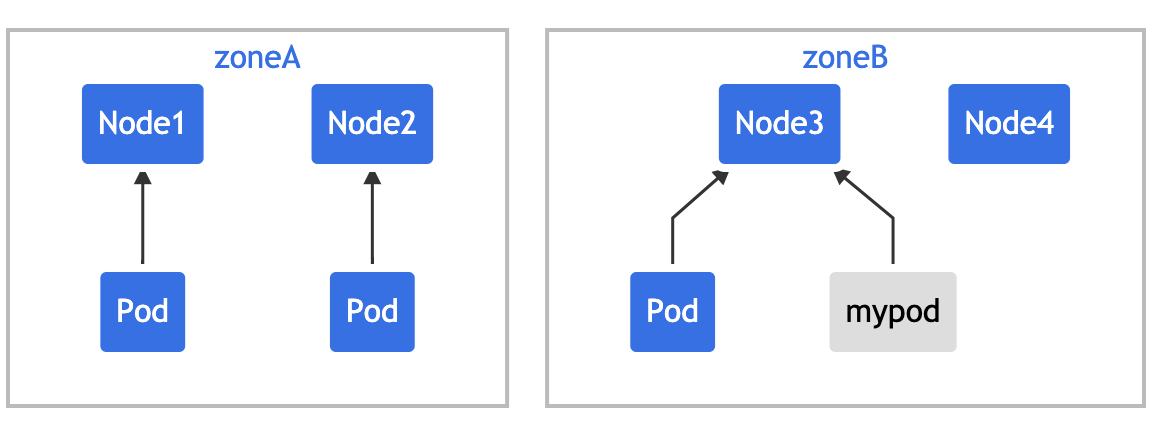
你可以调整 Pod 约束以满足各种要求:
- 将
maxSkew更改为更大的值,比如 "2",这样新的 Pod 也可以放在 "zoneA"上。 - 将
topologyKey更改为 "node",以便将 Pod 均匀分布在节点上而不是区域中。 在上面的例子中,如果maxSkew保持为 "1",那么传入的 Pod 只能放在 "node4"上。 - 将
whenUnsatisfiable:DoNotSchedule更改为whenUnsatisfiable:ScheduleAnyway, 以确保新的 Pod 可以被调度。
4.多个拓扑约束
上面是单个 Pod 拓扑分布约束的情况,下面的例子建立在前面例子的基础上来对多个 Pod 拓扑分布约束进行说明。假设你拥有一个 4 节点集群,其中 3 个标记为 foo:bar的 Pod 分别位于 node1、node2 和 node3 上:
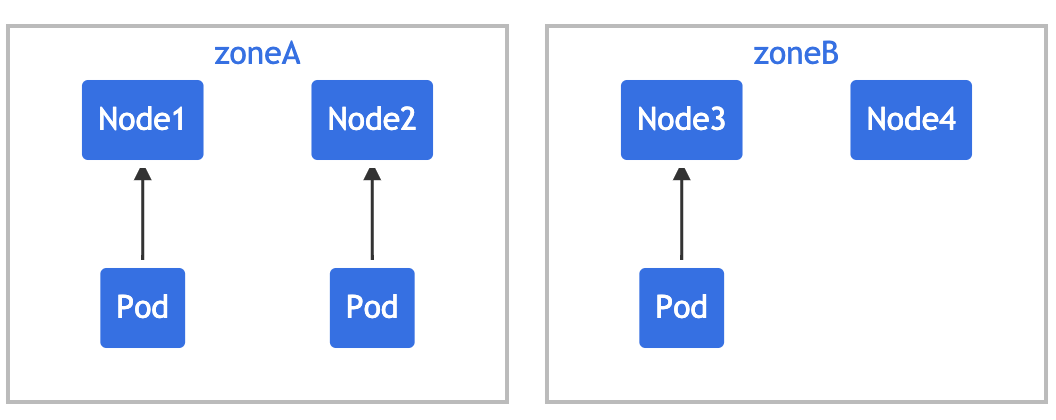
我们可以使用 2 个 TopologySpreadConstraint来控制 Pod 在区域和节点两个维度上的分布:
# two-constraints.yamlkind:PodapiVersion:v1metadata:name:mypodlabels:foo:barspec:topologySpreadConstraints:- maxSkew:1topologyKey:zonewhenUnsatisfiable:DoNotSchedulelabelSelector:matchLabels:foo:bar- maxSkew:1topologyKey:nodewhenUnsatisfiable:DoNotSchedulelabelSelector:matchLabels:foo:barcontainers:- name:pauseimage:k8s.gcr.io/pause:3.1在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在 "zoneB"中;而在第二个约束中, 新的 Pod 只能放置在 "node4"上,最后两个约束的结果加在一起,唯一可行的选择是放置 在 "node4"上。
🍂 多个约束之间是可能存在冲突的,假设有一个跨越 2 个区域的 3 节点集群:
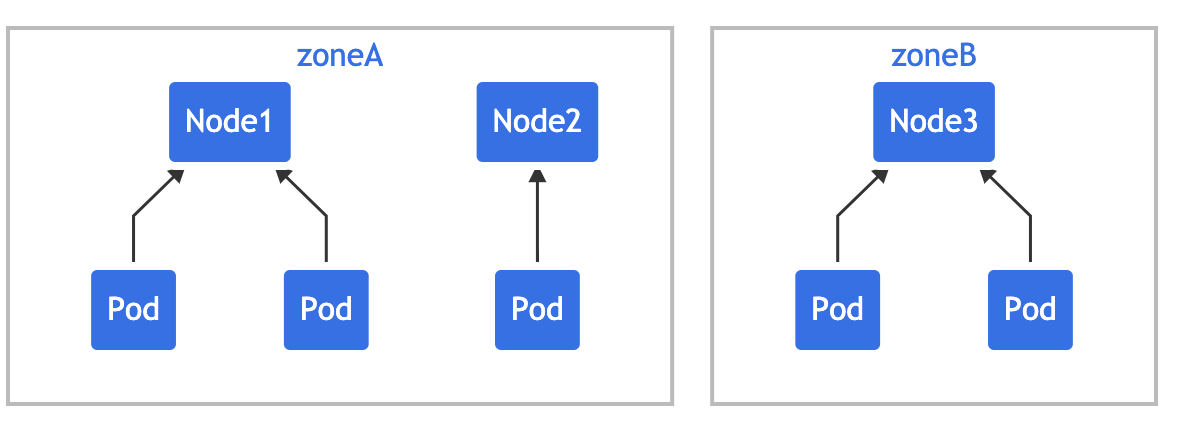
如果对集群应用 two-constraints.yaml,会发现 "mypod"处于 Pending状态,这是因为为了满足第一个约束,"mypod"只能放在 "zoneB"中,而第二个约束要求 "mypod"只能放在 "node2"上,Pod 调度无法满足这两种约束,所以就冲突了。
为了克服这种情况,你可以增加 maxSkew或修改其中一个约束,让其使用 whenUnsatisfiable:ScheduleAnyway。
5.与NodeSelector /NodeAffinity一起使用
仔细观察可能你会发现我们并没有类似于 **topologyValues**的字段来限制 Pod 将被调度到哪些拓扑去,默认情况会搜索所有节点并按 topologyKey对其进行分组。有时这可能不是理想的情况,比如假设有一个集群,其节点标记为 env=prod、env=staging和 env=qa,现在你想跨区域将 Pod 均匀地放置到 qa环境中,是否可行?
答案是肯定的,我们可以结合 NodeSelector或 NodeAffinity一起使用,PodTopologySpread会计算满足选择器的节点之间的传播约束。
如上图所示我们可以通过指定 spec.affinity.nodeAffinity将搜索范围限制为 qa环境,在该范围内 Pod 将被调度到一个满足 topologySpreadConstraints的区域,这里就只能被调度到 zone=zone2的节点上去了。
6.集群默认约束
除了为单个 Pod 设置拓扑分布约束,也可以为集群设置默认的拓扑分布约束,默认拓扑分布约束在且仅在以下条件满足 时才会应用到 Pod 上:
- Pod 没有在其
.spec.topologySpreadConstraints设置任何约束; - Pod 隶属于某个服务、副本控制器、ReplicaSet 或 StatefulSet。
你可以在 调度方案(Schedulingg Profile)中将默认约束作为 PodTopologySpread插件参数的一部分来进行设置。 约束的设置采用和前面 Pod 中的规范一致,只是 labelSelector必须为空。配置的示例可能看起来像下面这个样子:
apiVersion:kubescheduler.config.k8s.io/v1beta1kind:KubeSchedulerConfigurationprofiles:- pluginConfig:- name:PodTopologySpreadargs:defaultConstraints:- maxSkew:1topologyKey:topology.kubernetes.io/zonewhenUnsatisfiable:ScheduleAnywaydefaultingType:List思考1:不用 DaemonSet,如何使用 Deployment 是否实现同样的功能?
我们知道 DaemonSet 控制器的功能就是在每个节点上运行一个 Pod,如何要使用 Deployment 来实现,首先就要设置副本数量为节点数,比如我们这里加上 master 节点一共3个节点,则要设置3个副本,要在 master 节点上执行自然要添加容忍,那么要如何保证一个节点上只运行一个 Pod 呢?是不是前面的提到的 Pod 反亲和性就可以实现,以自己 Pod 的标签来进行过滤校验即可,新的 Pod 不能运行在一个已经具有该 Pod 的节点上,是不是就是一个节点只能运行一个?
- 模拟的资源清单如下所示:
# 06-daemonset-deployment.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:mock-ds-demospec:replicas:3selector:matchLabels:app:mock-ds-demotemplate:metadata:labels:app:mock-ds-demospec:tolerations:#加上容忍,这样才有机会运行在master节点上-key:"node-role.kubernetes.io/master"operator:"Exists"effect:"NoSchedule"containers:-image:nginxname:nginxports:-containerPort:80name:ngptaffinity:podAntiAffinity:# pod反亲合性requiredDuringSchedulingIgnoredDuringExecution:# 硬策略-labelSelector:matchExpressions:-key:app# Pod的标签operator:Invalues:["mock-ds-demo"]topologyKey:kubernetes.io/hostname# 以hostname为拓扑域,相当于每一个节点都是一个拓扑域- 创建上面的资源清单验证:
$kubectlapply-f06-daemonset-deployment.yamldeployment.apps/mock-ds-democreated$kubectlgetpo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATESmock-ds-demo-8694759c69-882fx1/1Running018s10.244.0.15master1<none><none>mock-ds-demo-8694759c69-frfhx1/1Running018s10.244.1.108node1<none><none>mock-ds-demo-8694759c69-p5cjw1/1Running018s10.244.2.235node2<none><none>可以看到我们用 Deployment 部署的服务在每个节点上都运行了一个 Pod,实现的效果和 DaemonSet 是一致的。
思考2:如果想在每个节点(或指定的一些节点)上运行2个(或多个)Pod 副本呢?
🍂 同样的如果想在每个节点(或指定的一些节点)上运行2个(或多个)Pod 副本,如何实现?
DaemonSet 是在每个节点上运行1个 Pod 副本,显然我们去创建2个(或多个)DaemonSet 即可实现该目标,但是这不是一个好的接近方案,而 **PodAntiAffinity**只能将一个 Pod 调度到某个拓扑域中去,所以都不能很好的来解决这个问题。
要实现这种更细粒度的控制,我们可以通过设置拓扑分布约束来进行调度,设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本,具体实现方式请看下文。
| 💘 实践:用拓扑分布约束来扩展daemonset功能(测试成功)-2022.5.17 |
|---|
现在我们再去解决上节课留下的一个问题 - 如果想在每个节点(或指定的一些节点)上运行2个(或多个)Pod 副本,如何实现?
- 这里以我们的集群为例,加上 master 节点一共有3个节点,每个节点运行2个副本,总共就需要6个 Pod 副本,要在 master 节点上运行,则同样需要添加容忍,如果只想在一个节点上运行2个副本,则可以使用我们的拓扑分布约束来进行细粒度控制,对应的资源清单如下所示:
#01-daemonset2.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:topo-demospec:replicas:6selector:matchLabels:app:topotemplate:metadata:labels:app:topospec:tolerations:- key:"node-role.kubernetes.io/master"operator:"Exists"effect:"NoSchedule"containers:- image:nginxname:nginxports:- containerPort:80name:ngpttopologySpreadConstraints:- maxSkew:1topologyKey:kubernetes.io/hostnamewhenUnsatisfiable:DoNotSchedulelabelSelector:matchLabels:app:topo这里我们重点需要关注的就是 topologySpreadConstraints部分的配置,我们选择使用 kubernetes.io/hostname为拓扑域,相当于就是3个节点都是独立的,maxSkew:1表示最大的分布不均匀度为1,所以只能出现的调度结果就是每个节点运行2个 Pod。
maxSkew=2这个相当于是软策略,不可取。

maxSkew=1这个满足需求。
maxSkew=1,这个是一轮轮往下调度的;(那么一般情况,maxSkew=1应该是比较常用的)
- 直接创建上面的资源即可验证:
$kubectlapply-f01-daemonset2.yamldeployment.apps/topo-democreated$kubectlgetpo-lapp=topo-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATEStopo-demo-6bbf65d967-ctf661/1Running043s10.244.1.110node1<none><none>topo-demo-6bbf65d967-gkqpx1/1Running043s10.244.0.16master1<none><none>topo-demo-6bbf65d967-jsj4h1/1Running043s10.244.2.236node2<none><none>topo-demo-6bbf65d967-kc9x81/1Running043s10.244.2.237node2<none><none>topo-demo-6bbf65d967-nr9b91/1Running043s10.244.1.109node1<none><none>topo-demo-6bbf65d967-wfzmf1/1Running043s10.244.0.17master1<none><none>可以看到符合我们的预期,每个节点上运行了2个 Pod 副本。
- 如果是要求每个节点上运行3个 Pod 副本呢?大家也可以尝试去练习下。
#02-daemonset.yamlapiVersion:apps/v1kind:Deploymentmetadata:name:topo-demo2spec:replicas:9selector:matchLabels:app:topo2template:metadata:labels:app:topo2spec:tolerations:- key:"node-role.kubernetes.io/master"operator:"Exists"effect:"NoSchedule"containers:- image:nginxname:nginxports:- containerPort:80name:ngpt1topologySpreadConstraints:- maxSkew:1topologyKey:kubernetes.io/hostnamewhenUnsatisfiable:DoNotSchedulelabelSelector:matchLabels:app:topo2查看现象:
hg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml/2022.2.19-40.拓扑分布约束-实验代码$kubectlapply-f02-daemonset.yamldeployment.apps/topo-demo2createdhg@LAPTOP-G8TUFE0T:/mnt/c/Users/hg/Desktop/yaml/2022.2.19-40.拓扑分布约束-实验代码$kubectlgetpo-lapp=topo2-owideNAMEREADYSTATUSRESTARTSAGEIPNODENOMINATEDNODEREADINESSGATEStopo-demo2-87d77dbbd-25wbw1/1Running053s10.244.2.240node2<none><none>topo-demo2-87d77dbbd-77gm81/1Running053s10.244.1.113node1<none><none>topo-demo2-87d77dbbd-97npc1/1Running053s10.244.0.20master1<none><none>topo-demo2-87d77dbbd-fspcq1/1Running053s10.244.1.111node1<none><none>topo-demo2-87d77dbbd-k5llk1/1Running053s10.244.1.112node1<none><none>topo-demo2-87d77dbbd-pc24x1/1Running053s10.244.2.238node2<none><none>topo-demo2-87d77dbbd-rdmwn1/1Running053s10.244.2.239node2<none><none>topo-demo2-87d77dbbd-s4rjp1/1Running053s10.244.0.18master1<none><none>topo-demo2-87d77dbbd-xrwmk1/1Running053s10.244.0.19master1<none><none>实验结束。😘
8、Descheduler(重调度器)
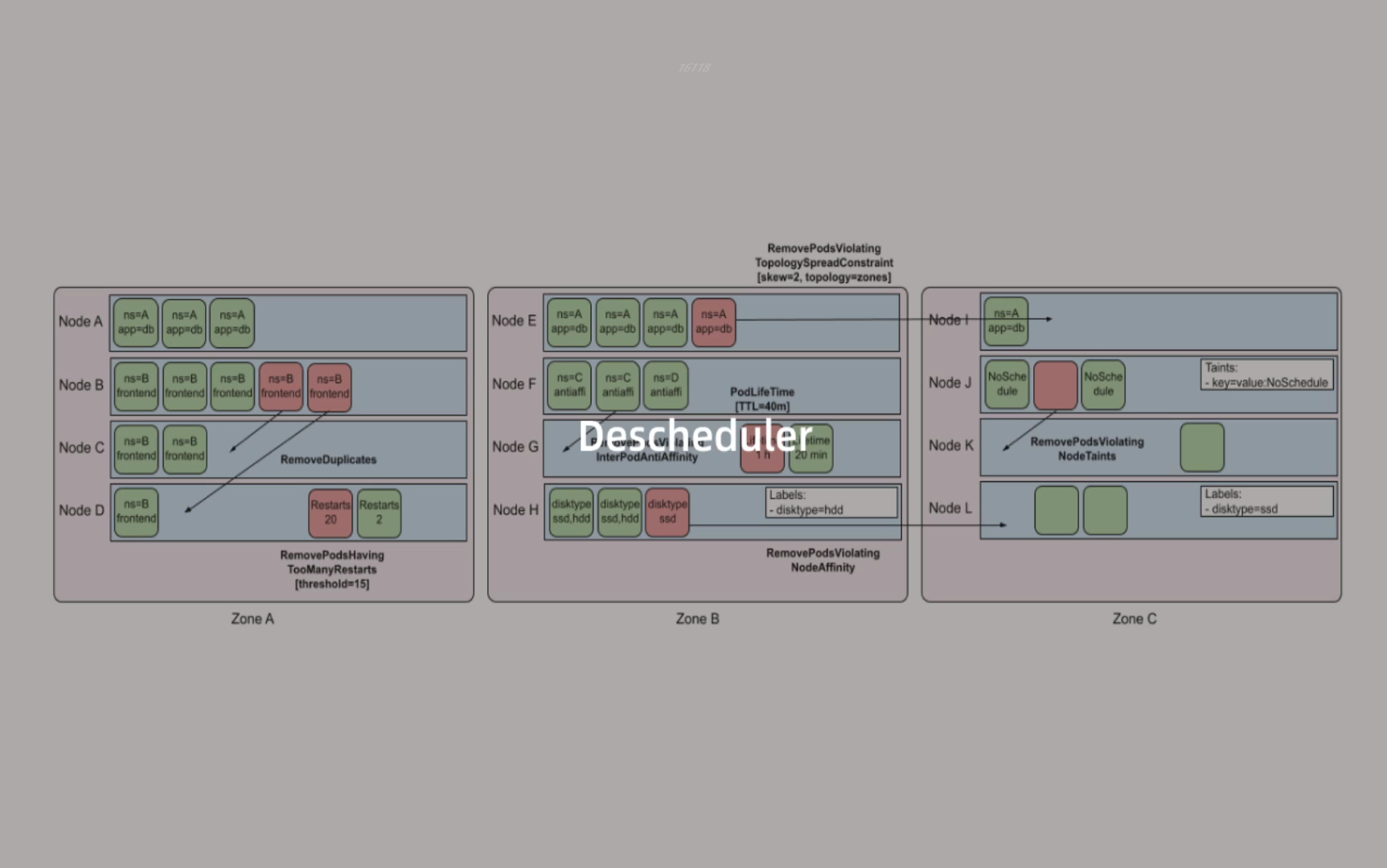
1、Descheduler
从 kube-scheduler 的角度来看,它是通过一系列算法计算出最佳节点运行 Pod,当出现新的 Pod 进行调度时,调度程序会根据其当时对 Kubernetes 集群的资源描述做出最佳调度决定,但是 Kubernetes 集群是非常动态的,由于整个集群范围内的变化,比如一个节点为了维护,我们先执行了驱逐操作,这个节点上的所有 Pod 会被驱逐到其他节点去,但是当我们维护完成后,之前的 Pod 并不会自动回到该节点上来,因为 Pod 一旦被绑定了节点是不会触发重新调度的,由于这些变化,Kubernetes 集群在一段时间内就可能会出现不均衡的状态,所以需要均衡器来重新平衡集群。
当然我们可以去手动做一些集群的平衡,比如手动去删掉某些 Pod,触发重新调度就可以了,但是显然这是一个繁琐的过程,也不是解决问题的方式。为了解决实际运行中集群资源无法充分利用或浪费的问题,可以使用 descheduler组件对集群的 Pod 进行调度优化,descheduler可以根据一些规则和配置策略来帮助我们重新平衡集群状态,其核心原理是根据其策略配置找到可以被移除的 Pod 并驱逐它们,其本身并不会进行调度被驱逐的 Pod,而是依靠默认的调度器来实现,目前支持的策略有:
- RemoveDuplicates
- LowNodeUtilization
- RemovePodsViolatingInterPodAntiAffinity
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingTopologySpreadConstraint
- RemovePodsHavingTooManyRestarts
- PodLifeTime
这些策略都是可以启用或者禁用的,作为策略的一部分,也可以配置与策略相关的一些参数,默认情况下,所有策略都是启用的。另外,还有一些通用配置,如下:
nodeSelector:限制要处理的节点evictLocalStoragePods:驱逐使用 LocalStorage 的 PodsignorePvcPods:是否忽略配置 PVC 的 Pods,默认是 FalsemaxNoOfPodsToEvictPerNode:节点允许的最大驱逐 Pods 数
我们可以通过如下所示的 DeschedulerPolicy来配置:(这里是要用一个configmap来进行使用的。)
apiVersion:"descheduler/v1alpha1"kind:"DeschedulerPolicy"nodeSelector:prod=devevictLocalStoragePods:truemaxNoOfPodsToEvictPerNode:40ignorePvcPods:falsestrategies:# 配置策略...🍂 kubernetes-sigs/descheduler官方网站
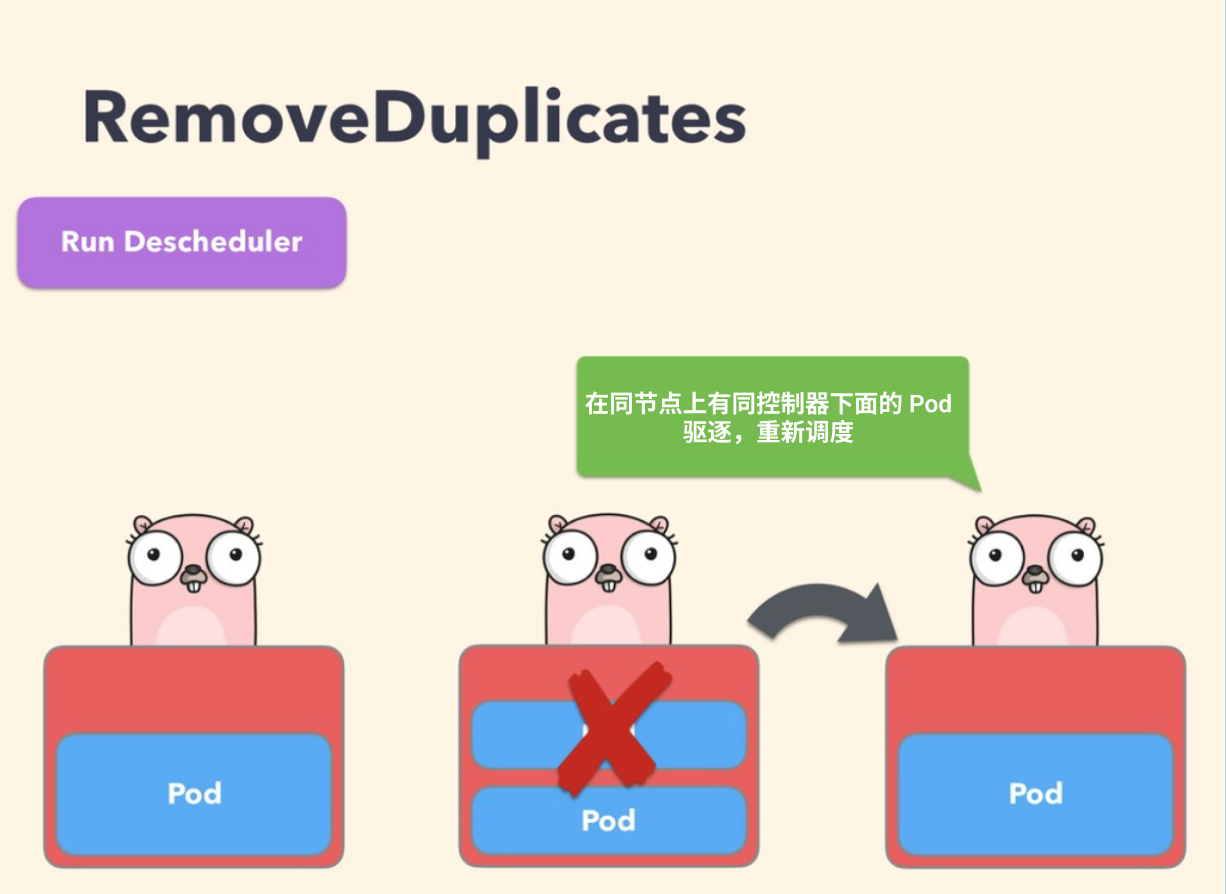
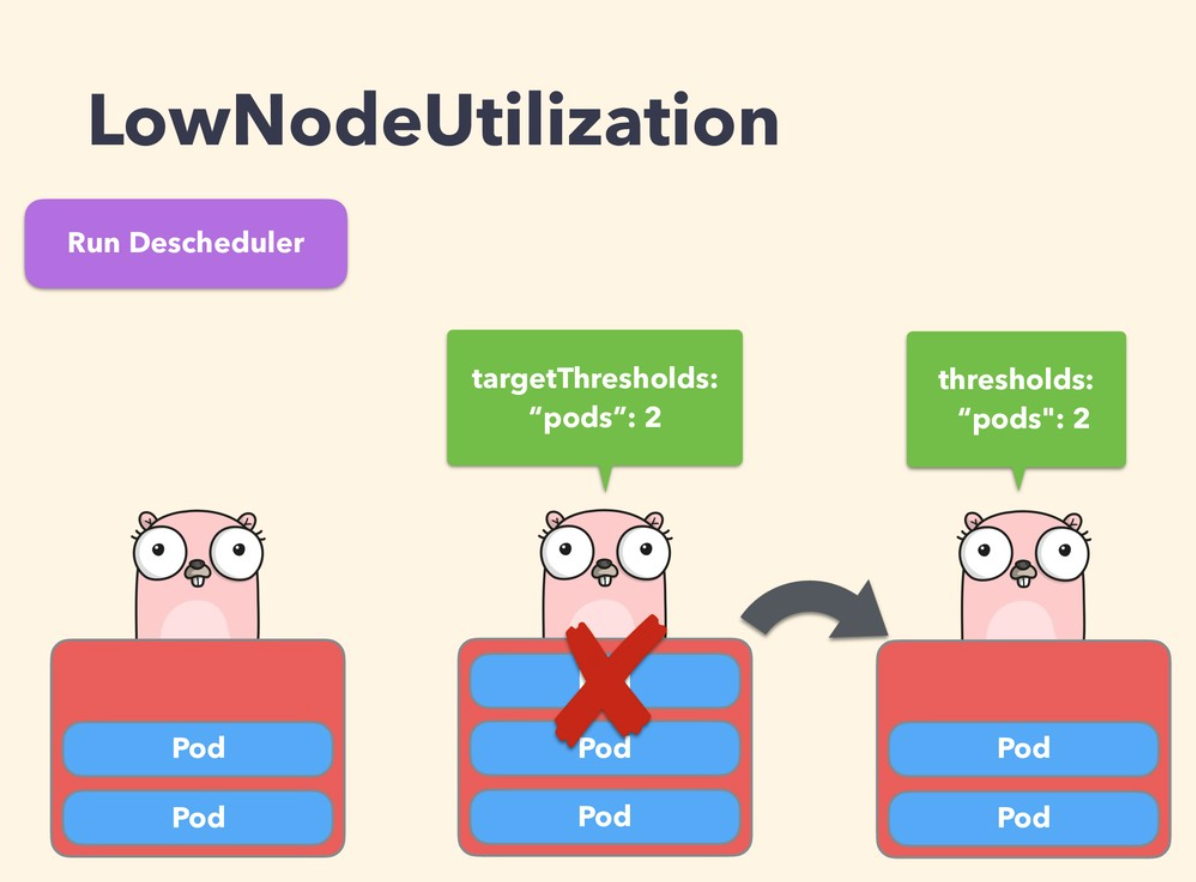
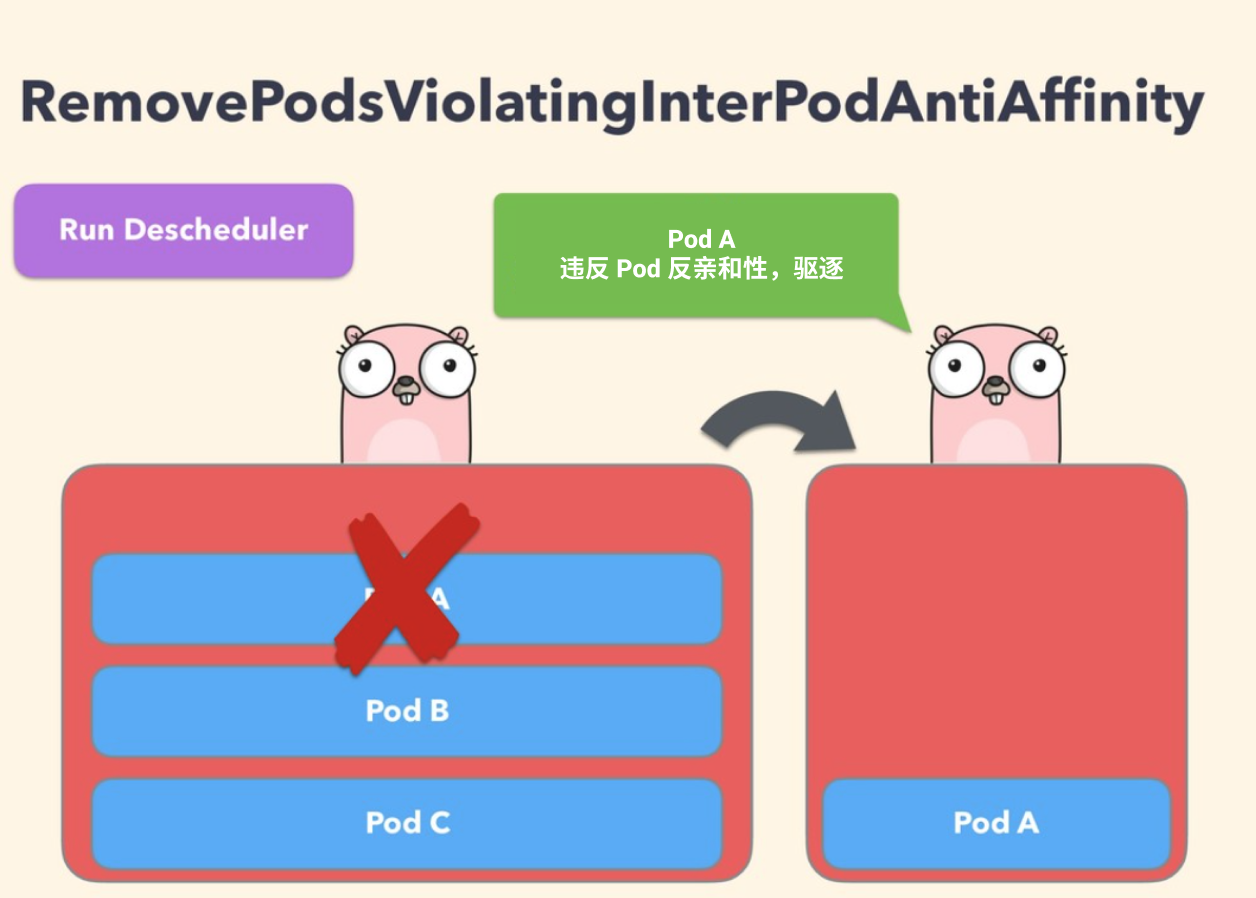

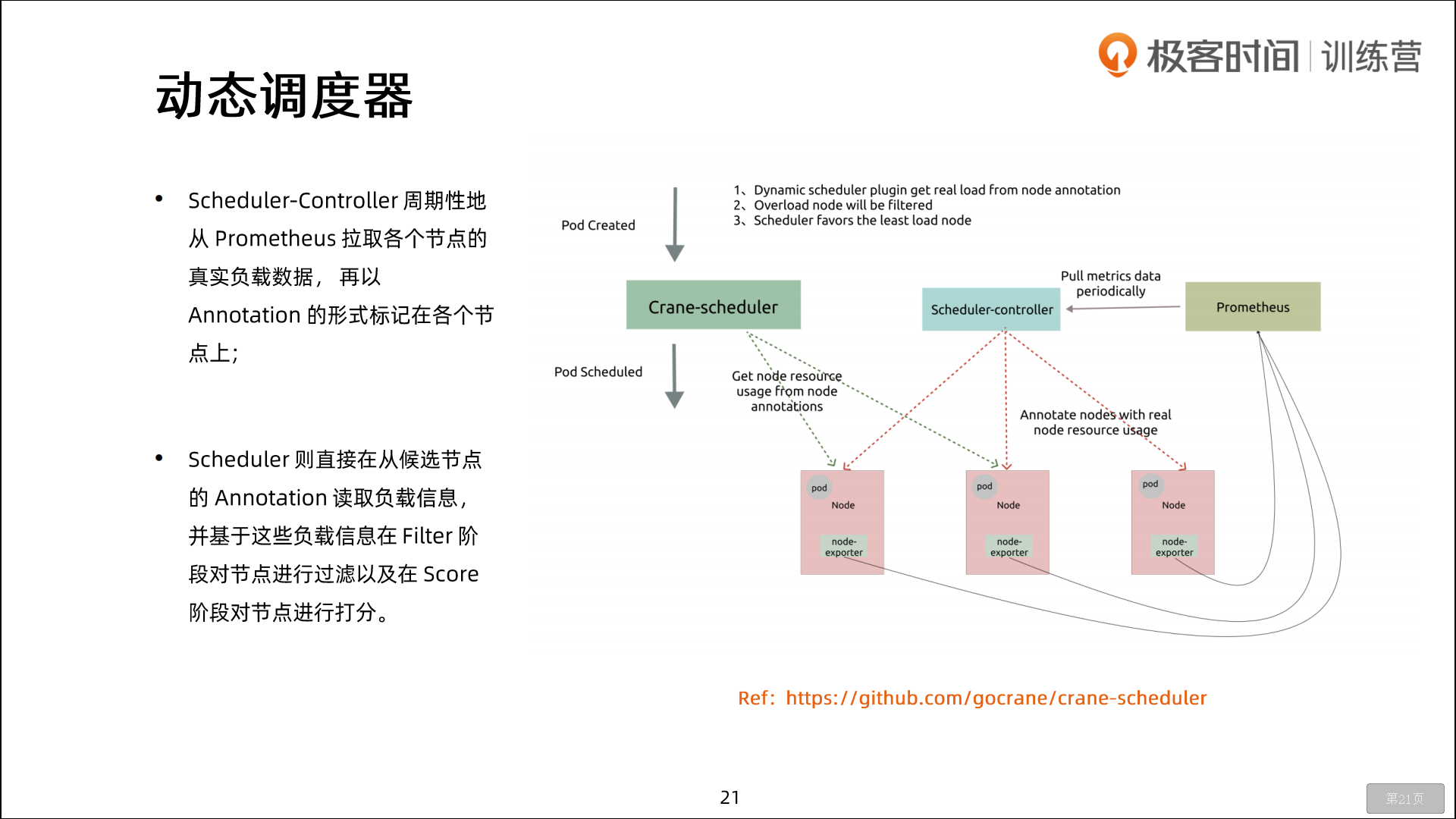 代码的实现而是很简单的。
代码的实现而是很简单的。 p8s基本是k8s的标配! 这个调度插件只一个锦上添花的能力,而不会影响主调度能力的。
p8s基本是k8s的标配! 这个调度插件只一个锦上添花的能力,而不会影响主调度能力的。 webhook,节点超售--实际生产上有大规模使用的!
webhook,节点超售--实际生产上有大规模使用的!

 1.19版本以后:Schedulling Framework,已经达到了stable状态
1.19版本以后:Schedulling Framework,已经达到了stable状态