
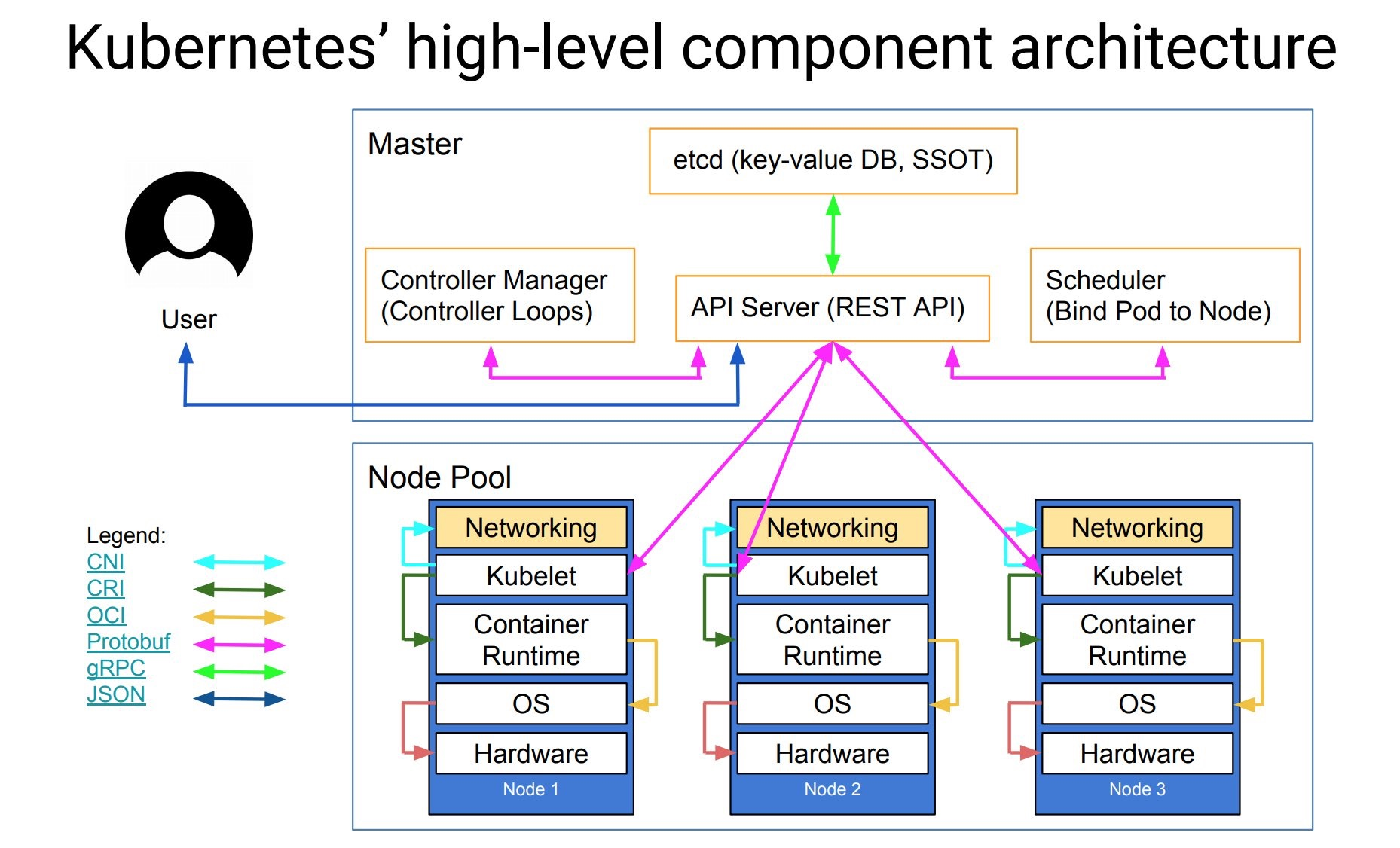
定义了这样一个资源清单文件后,我们就可以利用上面我们提到的 Kubectl 工具将这个 Pod 创建到 Kubernetes 集群中:
kubectlapply-fnginx-pod.yamlPod 在 Kubernetes 集群中被创建的基本流程如下所示:
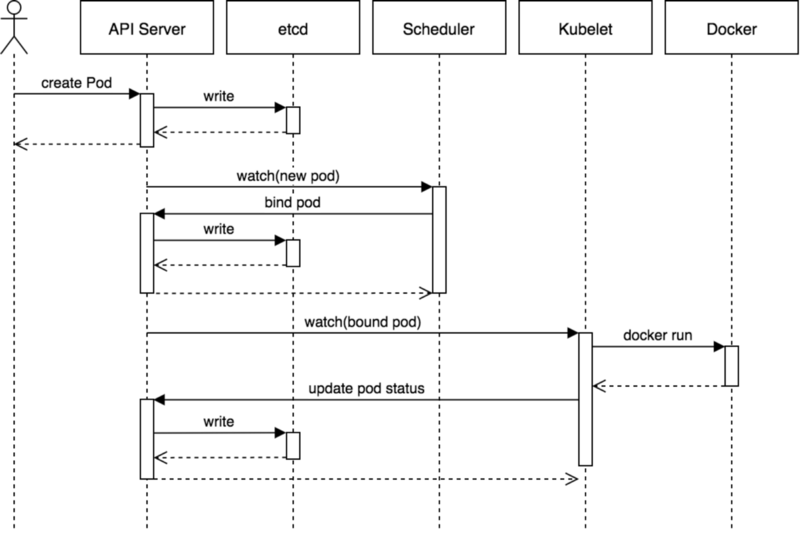
- 用户通过 REST API 创建一个 Pod
- apiserver 将其写入 etcd
- scheduluer 检测到未绑定 Node 的 Pod,开始调度并更新 Pod 的 Node 绑定
- kubelet 检测到有新的 Pod 调度过来,通过 container runtime 运行该 Pod
- kubelet 通过 container runtime 取到 Pod 状态,并更新到 apiserver 中
🚩 sandbox容器
我们的定义了一个pod,比如说是nginx的pod,那么这个pod里面只有一个image,这个image就是nginx的image,但事实上,kubernetes 在起这个pod的时候,它并不是只起一个容器的,它是起2个容器的,其中一个容器叫sandbox。
比如说CRI的接口,事实上都是2部分,一部分是对sandox的操作,一部分是对user container的操作。那这个容器相当于kubernetes出厂自带了一个叫做pase的这样一个image,它起sandbox container的时候就是去先起那个image的pause,这个pause里面就1条命令叫sleep infality,就是说这个镜像一旦运行起来,它不做任何事情,就直接sleep掉了。那sleep掉了,就意味着这个镜像非常小,而且它不需要cpu资源,而且极度稳定,它不会crash,不会oom,也不会有空指针。
所以这样的话,它的目的是什么呢?就需要一个非常稳定而精简的,小而精的这样一个不消耗资源的基础镜像,那么这个基础镜像是干什么的呢?
任何的容器在运行的时候,必须要有一个独立的网络namesapce,所以它会先起sandbox container,这个sandbox container,你可以把它理解为一个永远不会退出的进程。然后接下来它会creat network namespace,然后把这个sandbox进程和这个namespace进程相关,然后所有的网络配置都是配置在sandbox container的namespace的,那么当所有的网路setup完成的时候,它才会去起主container。
那起主container的时候,为什么需要这样呢?因为你想:
第一点:你的主container启动的时候就需要网络,你可能要去拉一些包,那么就意味着你的主container启动之前网络一定是要先配好的,所以一定要有个网路的预加载; 第二点:网络的这个namesapce是要和跟进程绑定的,那么假设说你主container 绑了网络namseapce,那么你主container有可能panic,你写代码有可能空指针啊,有可能内存泄露啊,那么一重启,整个网络的setup都丢了,那么这个pod就不通了,有可能你要重新setup网络。
所以基于这个考虑,kubernrtes在起pod的时候,它会先起一个sandbox,沙箱。


Label
Label 标签在 Kubernetes 资源对象中使用很多,也是非常重要的一个属性,Label 是识别 Kubernetes 对象的标签,以 key/value的方式附加到对象上(key最长不能超过63字节,value 可以为空,也可以是不超过253字节的字符串)。
上面我们定义的 Nginx 的 Pod 就添加了一个 app=nginx的 Label 标签。Label 不提供唯一性,并且实际上经常是很多对象(如Pods)都使用相同的 Label 来标志具体的应用。Label 定义好后其他对象可以使用 Label Selector来选择一组相同 Label 的对象(比如 Service 用 Label 来选择一组 Pod)。Label Selector 支持以下几种方式:
- 等式,如
app=nginx和env!=production - 集合,如
env in (production,qa) - 多个 Label(它们之间是
AND关系),如app=nginx,env=test
Namespace
Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。 常见的 Pods、Services、Deployments 等都是属于某一个 Namespace 的(默认是 default),比如上面我们的 Nginx Pod 没有指定 namespace,则默认就在 default 命名空间下面,而 Node,PersistentVolumes 等资源则不属于任何 Namespace,是全局的。
注意:它并不是 Linux Namespace,二者没有任何关系,它只是 Kubernetes 划分不同工作空间的一个逻辑单位。
Deployment
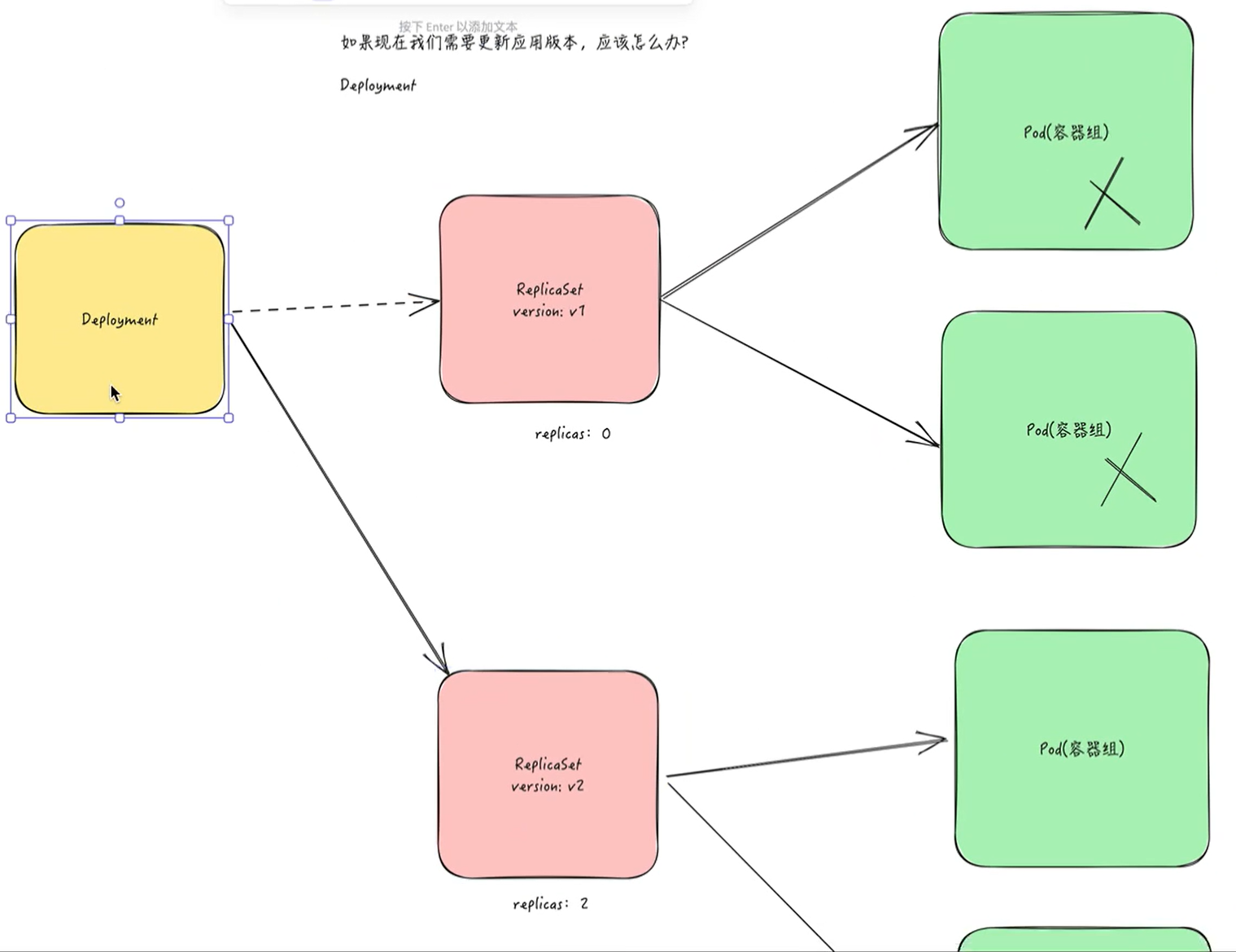
我们说了 Pod 是 Kubernetes 集群中的最基本的调度单元,但是如果想要创建同一个容器的多份拷贝,需要一个一个分别创建出来么,那么能否将 Pods 划到一个逻辑组里面呢?Deployment 就是来管理 Pod 的资源对象。
**Deployment 确保任意时间都有指定数量的 Pod“副本”在运行。**如果为某个 Pod 创建了 Deployment 并且指定3个副本,它会创建3个 Pod,并且持续监控它们。如果某个 Pod 不响应,那么 Deployment 会替换它,始终保持总数为3。
如果之前不响应的 Pod 恢复了,现在就有4个 Pod 了,那么 Deployment 会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Deployment 会立刻启动2个新 Pod,保证总数为5。
当创建 Deployment 时,需要指定两个东西:
- Pod 模板:用来创建 Pod 副本的模板
- Label 标签:Deployment 需要监控的 Pod 的标签。
现在已经创建了 Pod 的一些副本,那么这些副本上如何进行负载呢?如何把这些 Pod 暴露出去呢?这个时候我们就需要用到 Service 这种资源对象了。
注意:
- Deployment表示用户对 Kubernetes 集群的一次更新操作。
- Deployment是一个比 RS 应用模式更广的 API 对象,可以是创建一个新的应用,更新一个已存在的应用,也可以是滚动升级一个应用。
- 滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的复合操作。这样一个复合操作用一个 RS 是不太好描述的,所以用一个更通用的 Deployment 来描述。以 Kubernetes 的发展方向,未来对所有长期伺服型的的业务的管理,都会通过 Deployment 来管理。
对于无状态应用,我们最常用的对象就是deployment对象了。
它确保了: 第一:我定义好了滚动升级的策略,那么你在做版本升级的时候,我可以做一个对用户没有影响,不会让service宕机的这样一个滚动升级。 第二:它会建一个副本集(replicaset),然后确保说我一个应用一定要有多少个实例。那么当某些实例被删掉的时候,我会补一个新的出来,那么这是deployment的一个作用。
🚩 Deployment->ReplicaSet->Pod
🚩
deployment对象属性
你可以看到,kubernetes给我们添加了很多很多附加的属性。那么这些属性都是默认值。就是有些东西你不填的话,那么kubernetes就会帮你填上默认值。所以我们来理解下,deployment做了些什么。
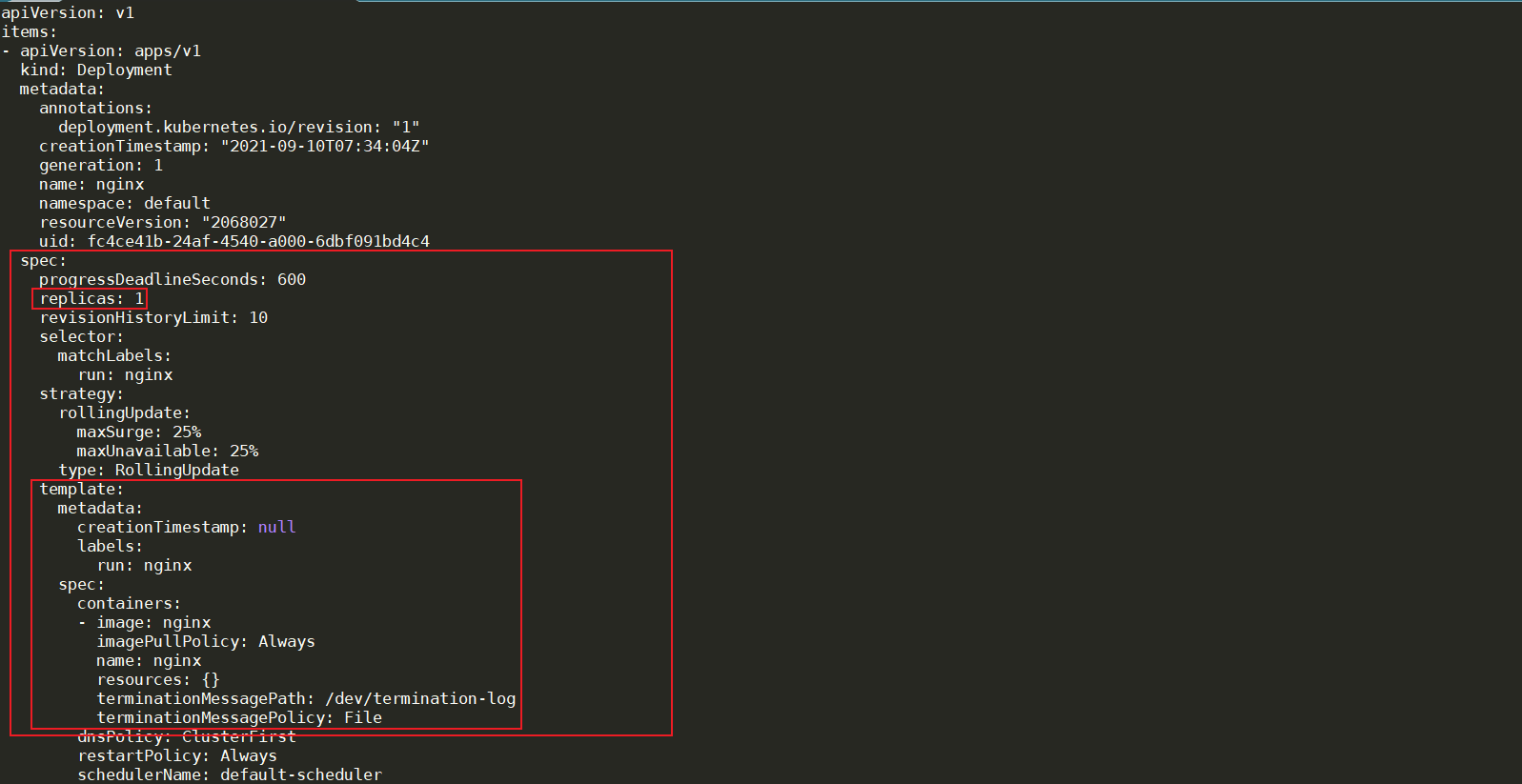
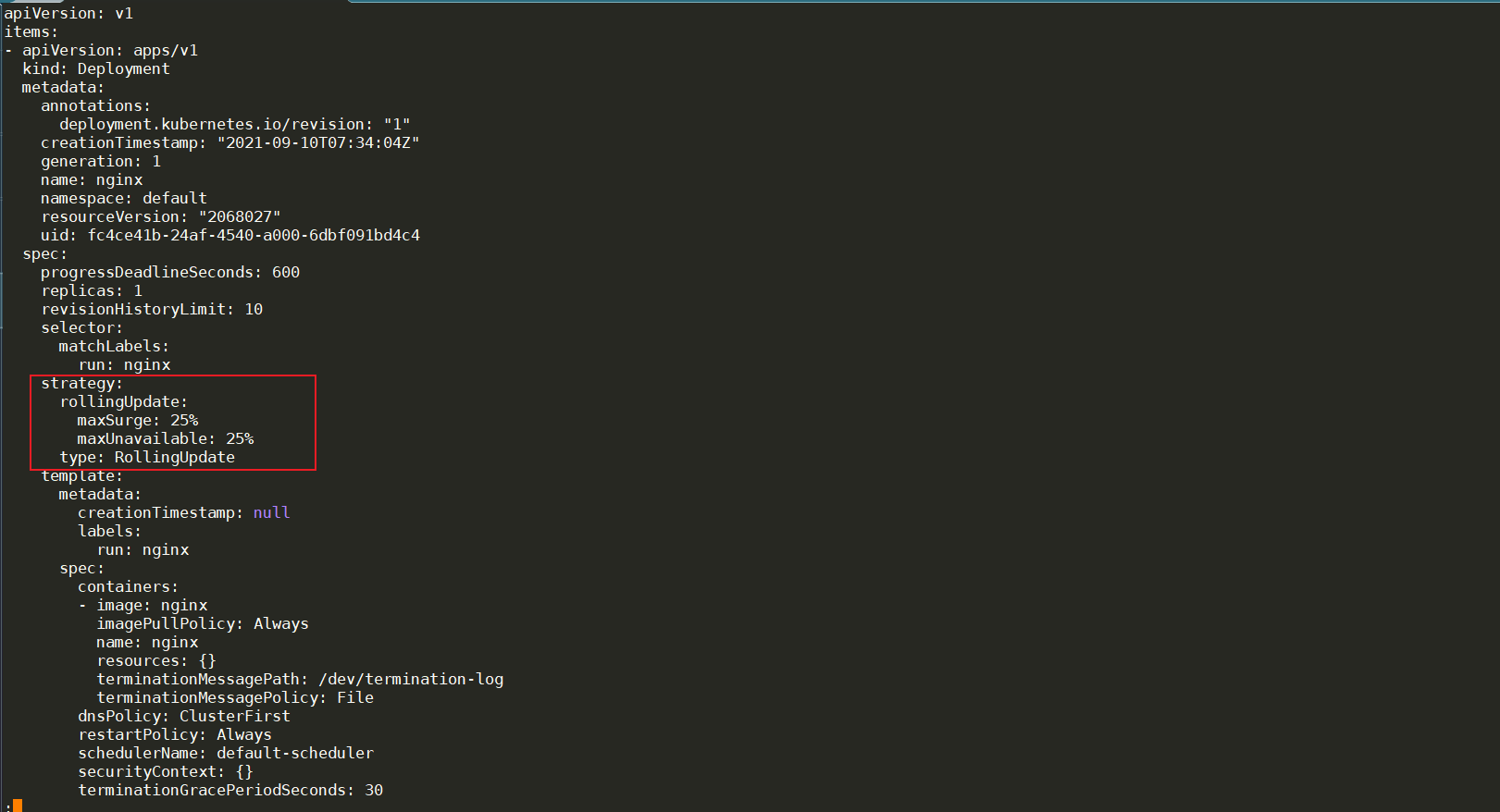
它加了一个最重要的部分叫做strategy,那么这个strategy叫做type:RollingUpdate的strategy。其实这个strategy就是kubernetes为deployment定义的默认升级策略,升级策略的类型是:滚动升级(RollingUpdate)
如何滚动升级呢?maxSurge:25%一次升级25%,maxUnavailable:25%最多不可用25%。(也就是说如果他发现有25%的实例已经not ready了,不能用了,那么它的这个升级就要停在那里)。这个目的是什么呢?就是说有时候我们升级版本的时候,新版本可能有bug,你可能跑起来以后,出问题了,跑着跑着它变的不能接收流量了,已经不能提供服务了。那么你不能继续升级了,继续升级整个业务就故障了。那通过这种方式就如果有25%的实例都不能提供服务了,那么它就会暂停升级。
好,这是第一个部分。
第二个部分,pod template也加了很多属性。

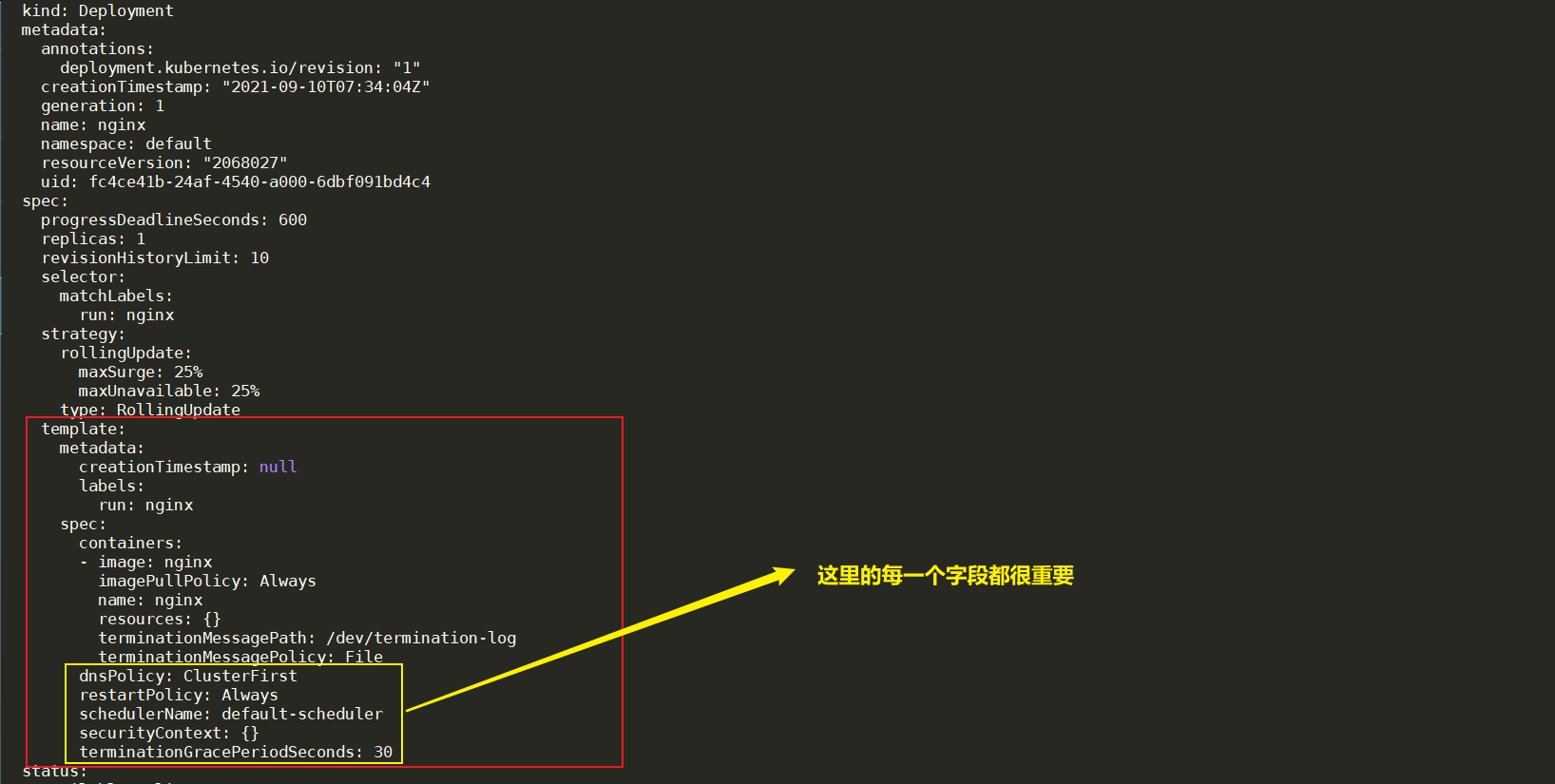
刚才是spec部分,我们可以看到一个简单的spec被添加了很多另外的属性。
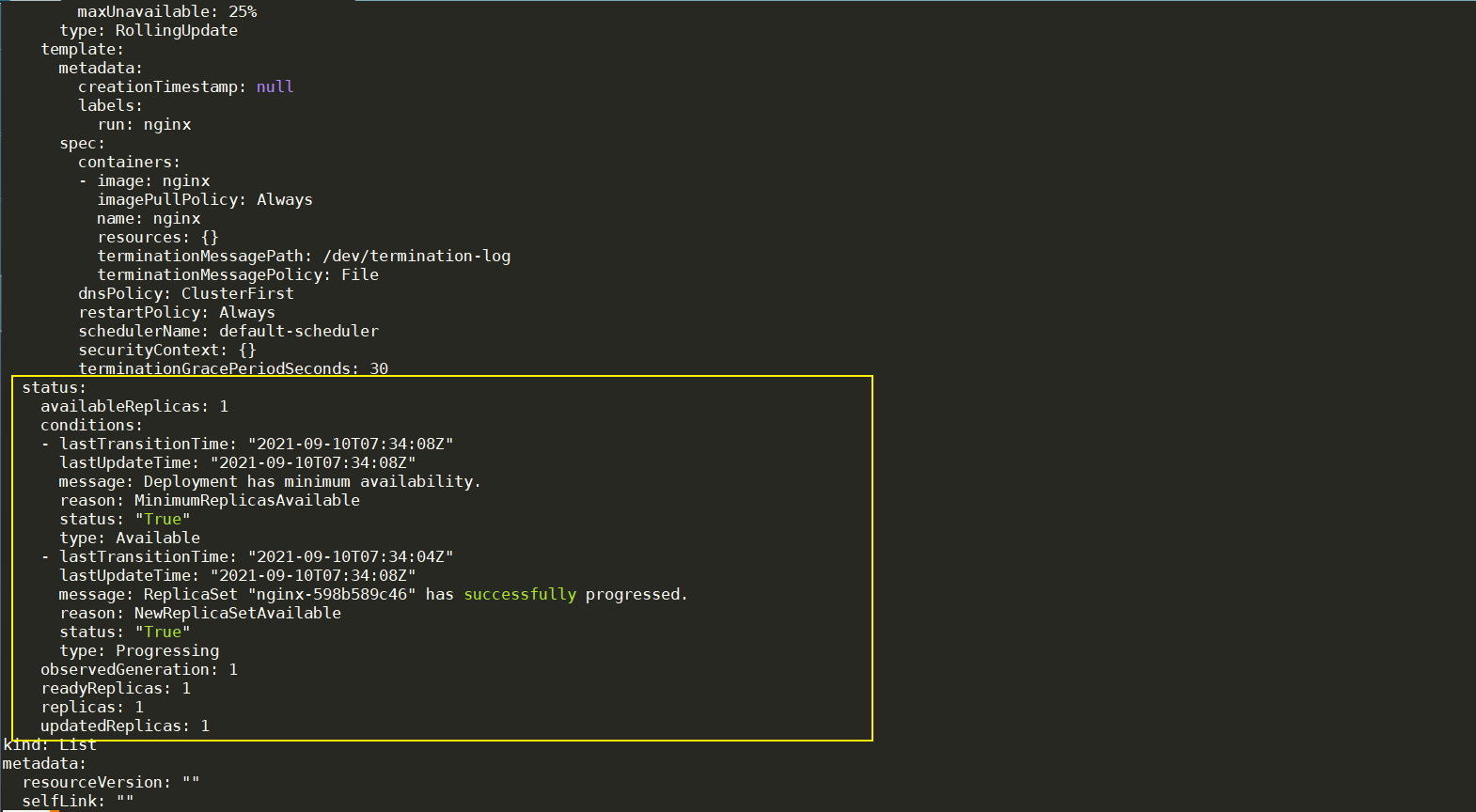
之前讲过,任何对象都是有status,status是controller干完活,然后controller填上去的,这是这个对象的真实状态。
所以我们接下来看一下status这部分,可以看到,status里面有个conditions。conditions相当于是这个对象的状态的一些细节。
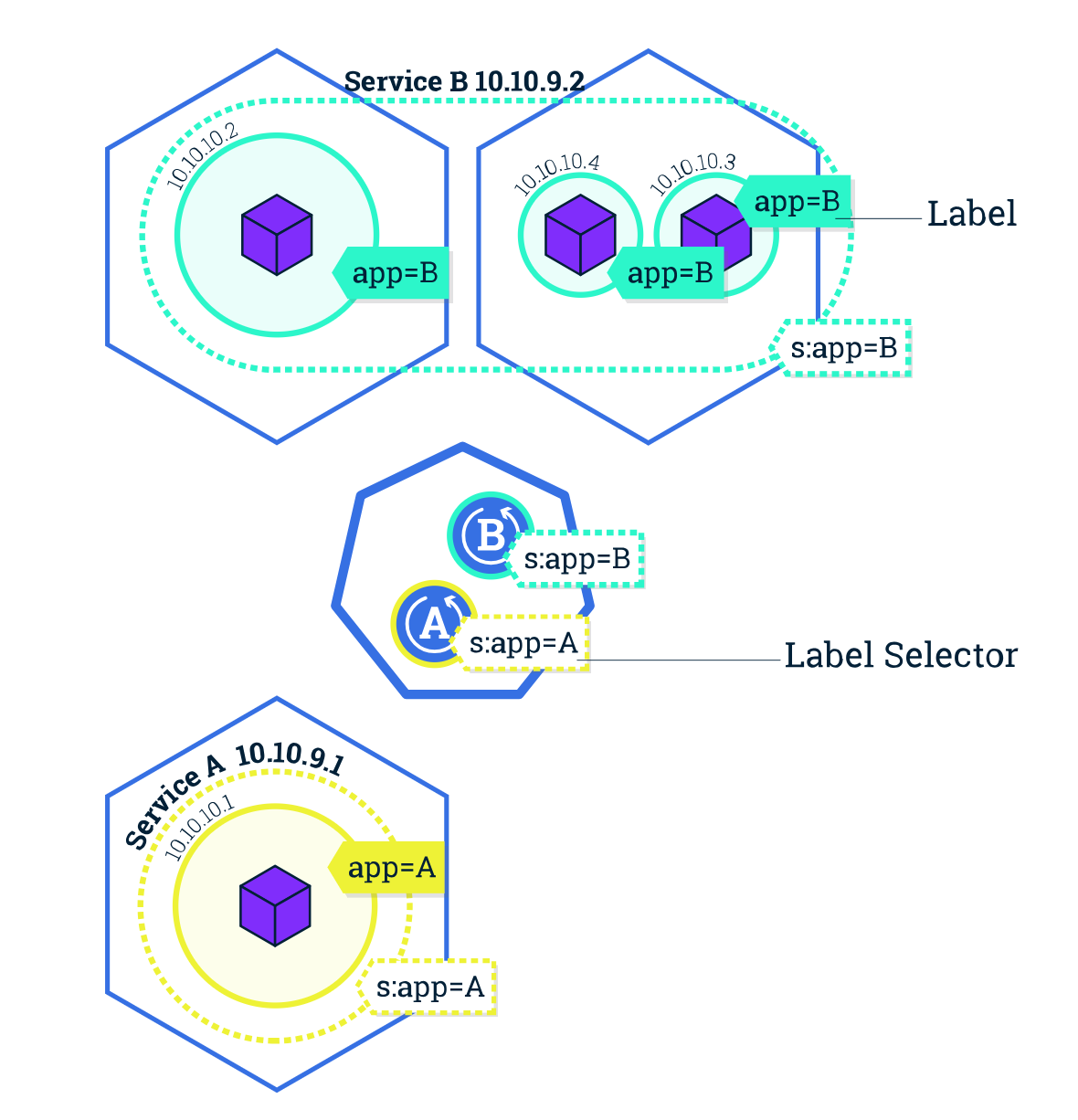
Service
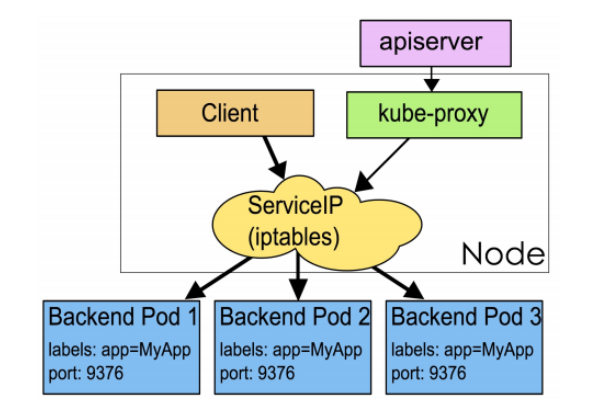
Service 是应用服务的抽象,通过 labels 为应用提供负载均衡和服务发现。匹配 labels的 Pod IP和端口列表组成 endpoints,由 Kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上。
每个默认类型 Service 都会自动分配一个 cluster IP(仅在集群内部可访问的虚拟地址)和 DNS名,其他容器可以通过该地址或 DNS 来访问服务,而不需要了解后端容器的运行。
RC、RS 和 Deployment 只是保证了支撑服务的微服务 Pod 的数量,但是没有解决如何访问这些服务的问题。一个 Pod 只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的 IP 启动一个新的Pod,因此不能以确定的 IP 和端口号提供服务。
要稳定地提供服务需要服务发现和负载均衡能力。
服务发现完成的工作,是针对客户端访问的服务,找到对应的的后端服务实例。在 Kubernetes 集群中,客户端需要访问的服务就是 Service 对象。每个 Service 会对应一个集群内部有效的虚拟 IP,集群内部通过虚拟 IP 访问一个服务。
在Kubernetes 集群中微服务的负载均衡是由 Kube-proxy 实现的。Kube-proxy 是 Kubernetes 集群内部的负载均衡器。它是一个分布式代理服务器,在 Kubernetes 的每个节点上都有一个,这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的 Kube-proxy 就越多,高可用节点也随之增多。与之相比,我们平时在服务器端使用反向代理作负载均衡,还要进一步解决反向代理的高可用问题。

🚩 QA
==Q :对运维来讲,部署了2个服务以后,他们之间可以直接通信吗?==
A:可以直接通信。service本身从模型上来讲,它就是描述一个负载均衡的,就相当于我刚才给大家展示过一点点,你通过service selector来决定说我select哪一堆pod,我可以定义说我在哪个端口上expose哪个service。那最终的实现是通过比如说对labels本身来讲,它是配了ipvs,iptable,或者通过ebpf去配了这个负载均衡的规则,那么2个服务之间直接通信,A服务要调用B服务的时候,就走了这些转发规则,然后请求就过去了。
==Q:service的 ip是某个机器的ip吗?外部可访问吗?会不会和其中一个xx重复?==
A:pod的ip和service的ip是不同的range。
1、那pod的ip是通过你的CNI的pliugin去配置的,CNI的plugin在setup的时候会去配说我的xxxx是什么。 2、那么service ip或者叫cluster ip,就是这里说的虚ip,它是怎么分配的呢?是apiserver在启动的时候,它会配一个cluster ip range,那所有service ip都是从那个range里面去配的。
那么它是某个机器的ip吗?这个 其实要去看你是什么样的plugin。
那么如果是iptables的plugin,那么这个ip是不配置在任何device上的。它其实就是配linux kernel里的一些转发规则,所以这一块又涉及到Linux kernel这一块的讲解了,就是要去将linux内核协议栈处理。
那么如果是ipvs的话,它是要绑定到本机的一个xxx device上面的,叫ipvs里面的一个xx device。
但是这些ip对外都是不可路由的,也就是数说你从外部是不可访问的。
那么外部想如何访问集群内的一个服务呢?有两种方法:
一种方式:比方说你有一个成熟的cloud,比如说很多企业都有自己的负载均衡器,那么这些复杂均衡器要跟kubernetes做集成,那么怎么集成呢?如果你是一个标准的cloud,那么cloud provide就提供了一个这样的集成。有可能你不是一个标准的cloud,那么你可能自己要写service controller。
另一种方式:就是通过NodePort,就是节点端口,service有多种类型。这个我们会在服务发现的时候讲。那么,NodePort就相当于在起一个service的时候,它会在一个机器上开一个端口,那么你在访问这个端口的时候,它就会把这个请求转到backend pod里面去。
其它资源对象
Node
- Node 是 Pod 真正运行的主机,可以是物理机,也可以是虚拟机。
- Node 对象用来描述节点的计算资源:
- Capacity:计算能力,代表当前节点的所有资源;
- Allocatable:可分配资源,代表当前节点的可分配资源,通常是所有资源-预留资源-已分配资源;那么这个信息是给谁消费的呢?是scheduler消费的。scheduler会读取这个信息,然后知道每个节点的资源使用情况,那它做调度的时候就可以做正确决策。
- Kubelet 会按固定频率检查节点健康状态并上报给 APIServer,该状态会记录在 Node 对象的status 中。
ReplicaSet
- Pod 描述的是具体的应用实例,当 Pod 被删除后,就彻底消失了;
- 为保证应用的高可用,引入副本集来确保应用的总副本数永远与期望一致;
- 若某个 Pod 隶属于某个副本集,若该 Pod 被删除,则 ReplicaSet Controller 会发现当前运行的副本数量与用户的期望不一致,则会创建新的 Pod。
那你想,如果我是一个服务的提供商,万一我的pod被建出来后,被别人给误删了,那我的服务就宕了。所以,这个时候,我的应用要确保高可用的,那确保高可用,要怎么保证呢?我要去定义另外一个对象。为了应对不同的业务场景,我们应该组合不同的对象来完成这一目标,那我就通过副本集。
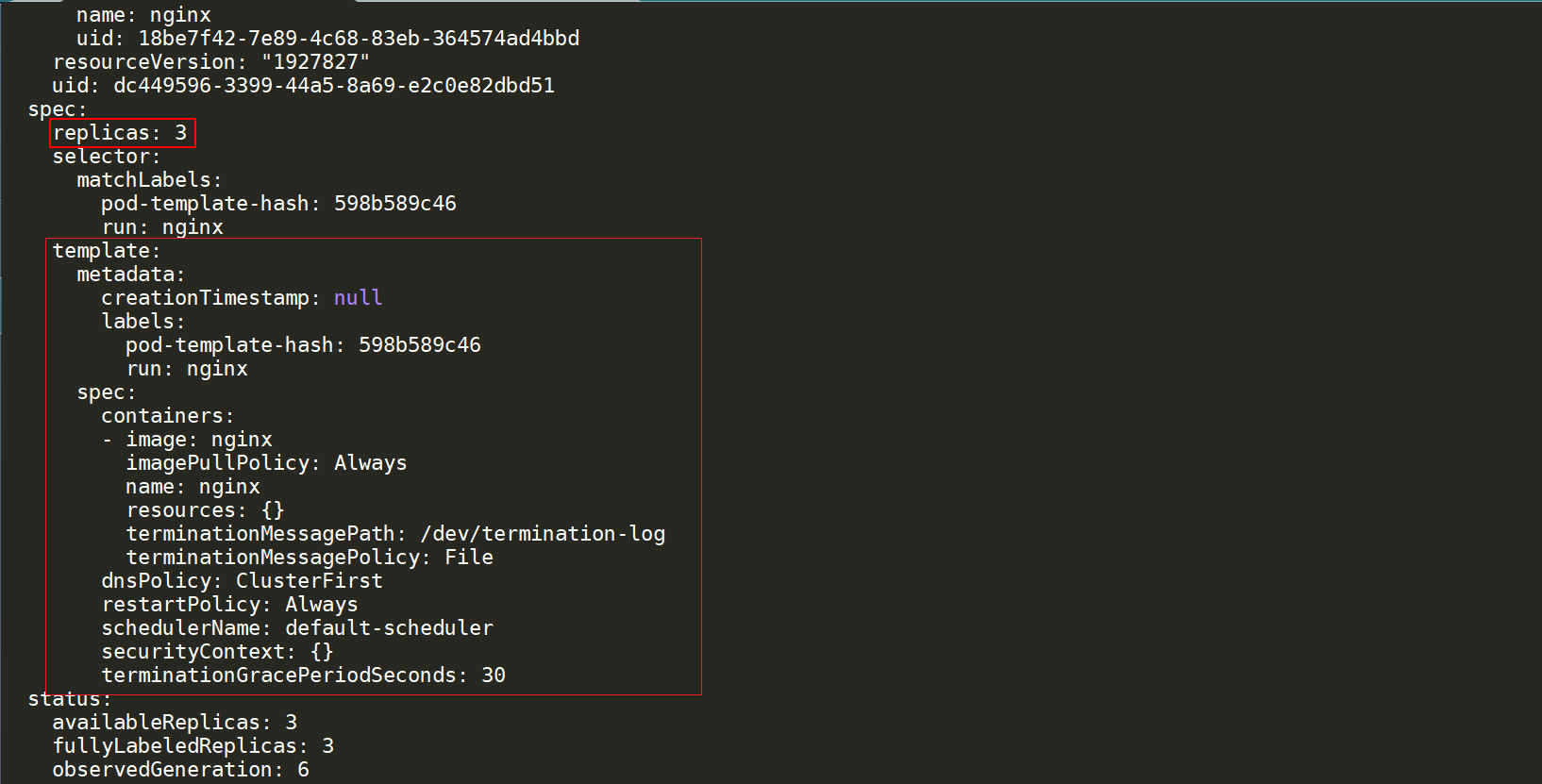
所谓的副本集,其实它本质上就是在pod的spec上面包了一层,它把pod的spec做为template的spec,作为一个pod的模板,在上面就定义了一下我要几个replicaset。那么kubernetes会去确保说,总会有那么多副本,能够满足你的需求。
kgetrs-oyaml|less
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码 x2675263825 (舍得), qq:2675263825。

🍀 微信公众号 《云原生架构师实战》

🍀 个人博客站点