
Linux磁盘阵列-RAID
Linux磁盘阵列(RAID)(&软raid)

目录
[toc]
一、什么是磁盘阵列(RAID)
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意(其中一块盘坏了,数据不丢失)。
磁盘阵列是由很多价格较便宜的磁盘,以硬件(RAID卡)或软件(MDADM)形式组合成一个容量巨大的磁盘组,利用多个磁盘组合在一起,提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
磁盘阵列还能利用同位检查(Parity Check)的观念,在阵列中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中(也就是坏了一块盘,拔掉,插入新盘,数据还能恢复到新盘,利用奇偶校验)
注:RAID可以预防数据丢失,但是它并不能完全保证你的数据不会丢失,所以大家使用RAID的同时还是注意备份重要的数据;
二、RAID的创建有两种方式
软RAID(通过操作系统软件来实现)和硬RAID(使用硬件阵列卡);
在企业中用的最多的是:raid1、raid5和raid10。不过随着云的高速发展,阿里云,腾讯云等供应商一般可以把硬件问题解决掉。(你在用云的时候,会关注供应商底层是用什么raid类型吗)
三、RAID几种常见的类型
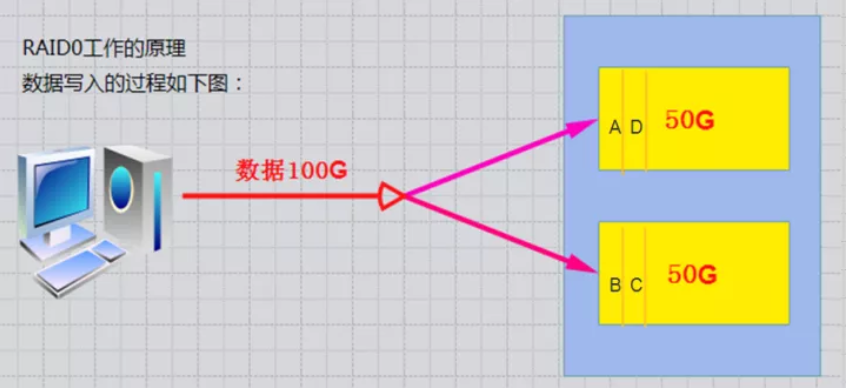
1、RAID-0工作原理
条带 (strping),也是我们最早出现的RAID模式;
需磁盘数量:2块以上(大小最好相同),是组建磁盘阵列中最简单的一种形式,只需要2块以上的硬盘即可;
特点:成本低,可以提高整个磁盘的性能和吞吐量。RAID 0没有提供冗余或错误修复能力,速度快;
任何一个磁盘的损坏将损坏全部数据;磁盘利用率为100%。
这里需要特别注意:只要是其中一个硬盘发生故障,这个机器上的所有数据应该都是读取不了的,因为数据是分层存放的,我这样理解没错吧,因为所有单盘raid0做成了一个raid组;
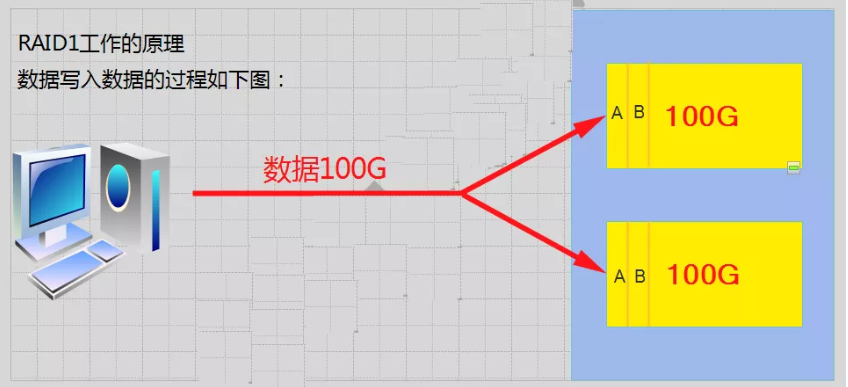
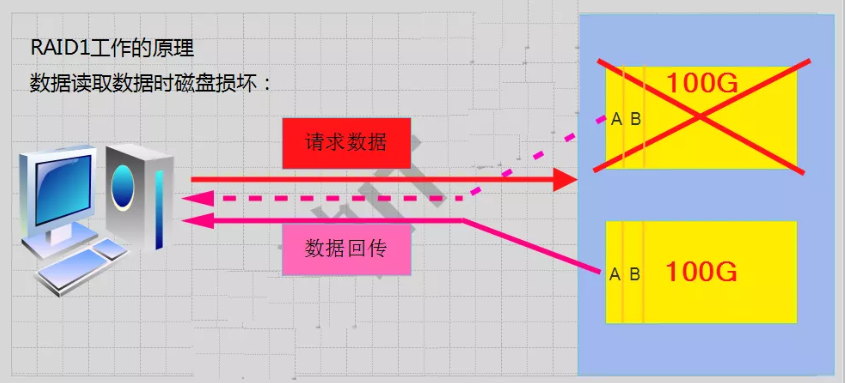
2、RAID-1工作原理
mirroring(镜像卷),需要磁盘两块以上;
原理:是把一个磁盘的数据镜像到另一个磁盘上,也就是说数据在写入一块磁盘的同时,会在另一块闲置的磁盘上生成镜像文件,(同步)
RAID 1 mirroring(镜像卷),至少需要两块硬盘,raid大小等于两个raid分区中最小的容量(最好将分区大小分为一样),数据有冗余,在存储时同时写入两块硬盘,实现了数据备份;
磁盘利用率为50%,即2块100G的磁盘构成RAID1只能提供100G的可用空间。如下图
3、RAID-5工作原理
需要三块或以上硬盘,可以提供热备盘实现故障的恢复;只损坏一块,没有问题。但如果同时损坏两块磁盘,则数据将都会损坏。
空间利用率: (n-1)/n
如下图所示
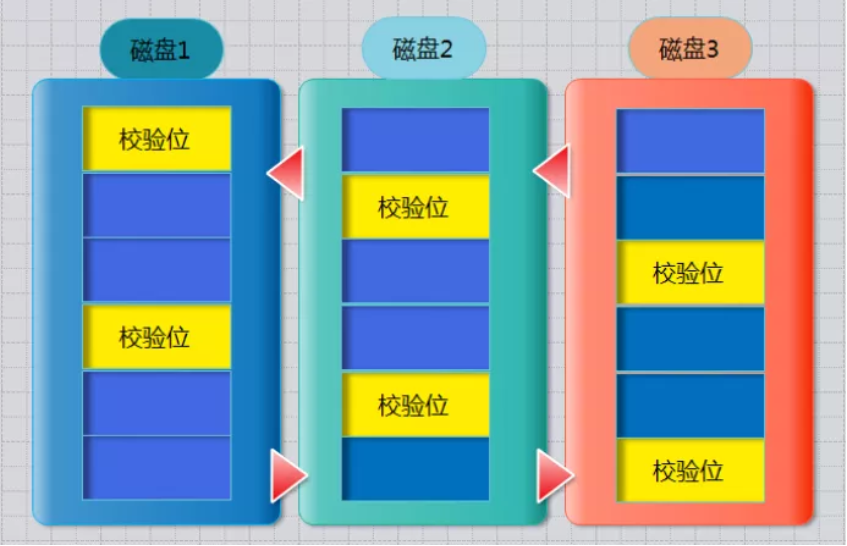
**奇偶校验信息的作用:**当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
扩展:异或运算 是用相对简单的异或逻辑运算(相同为0,相异为1)
| A值 | B值 | Xor结果 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
注意:
raid5需要3块硬盘。 那么使用4块硬盘,可以做raid5吗?
可以的
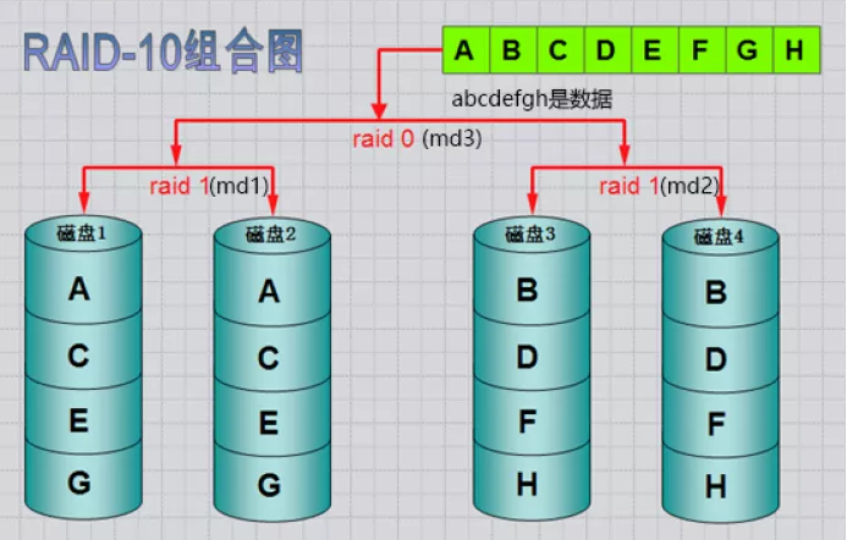
4、RAID10工作原理
嵌套RAID级别
RAID-10镜像+条带
RAID 10是将镜像和条带进行两级组合的RAID级别,第一级是RAID1镜像对,第二级为RAID 0。比如我们有8块盘,它是先两两做镜像,形成了新的4块盘,然后对这4块盘做RAID0;当RAID10有一个硬盘受损其余硬盘会继续工作,这个时候受影响的硬盘只有2块。(原来是这样哦,终于明白了)
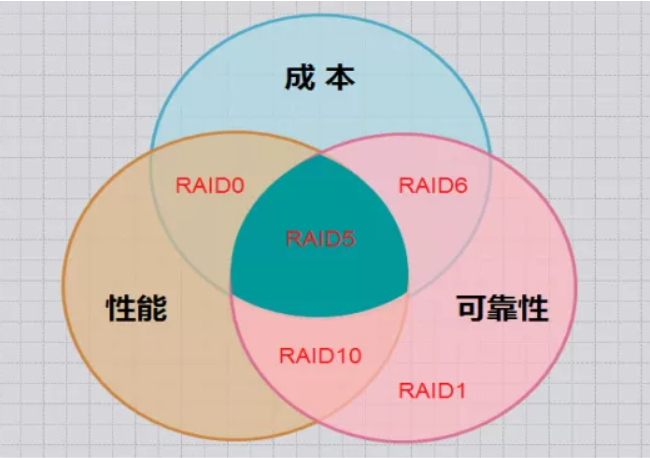
几个方案对比下来, RAID5是最适合的,如下图
总结
以下是常见 RAID 方案之间的区别,以列表形式展示,并包含每个方案最多能坏几块数据盘:
| RAID 级别 | 描述 | 最少磁盘数 | 冗余性 | 性能 | 存储利用率 | 最多能坏几块数据盘 | 适用场景 |
|---|---|---|---|---|---|---|---|
| RAID 0 | 数据条带化,无冗余 | 2 | 无 | 读写性能高(并行操作) | 100% | 0 | 需要高性能但不需要冗余的场景,如临时数据存储、缓存等。 |
| RAID 1 | 数据镜像,完全冗余 | 2 | 高 | 读性能高,写性能较低(需写入多份数据) | 50% | 1(每组镜像中最多坏 1 块) | 需要高可用性和数据冗余的场景,如关键数据存储、数据库等。 |
| RAID 5 | 数据条带化 + 分布式奇偶校验 | 3 | 有 | 读性能高,写性能较低(需计算奇偶校验) | (n-1)/n | 1 | 需要兼顾性能和冗余的场景,如文件服务器、中小型数据库等。 |
| RAID 6 | 数据条带化 + 双重分布式奇偶校验 | 4 | 高 | 读性能高,写性能较低(需计算双重奇偶校验) | (n-2)/n | 2 | 需要更高冗余的场景,如大型数据库、关键数据存储等。 |
| RAID 10 | RAID 1 + RAID 0,镜像 + 条带化 | 4 | 高 | 读写性能高(并行操作 + 镜像) | 50% | 1(每组镜像中最多坏 1 块) | 需要高性能和高冗余的场景,如高负载数据库、虚拟化平台等。 |
| RAID 50 | RAID 5 + RAID 0,条带化 + 分布式奇偶校验 + 条带化 | 6 | 有 | 读性能高,写性能中等(需计算奇偶校验) | (n-2)/n | 1(每个 RAID 5 组最多坏 1 块) | 需要高性能和中等冗余的场景,如大型文件服务器、数据仓库等。 |
| RAID 60 | RAID 6 + RAID 0,双重分布式奇偶校验 + 条带化 | 8 | 高 | 读性能高,写性能较低(需计算双重奇偶校验) | (n-4)/n | 2(每个 RAID 6 组最多坏 2 块) | 需要高性能和高冗余的场景,如超大规模数据存储、关键业务系统等。 |
关键点说明
最多能坏几块数据盘:
- RAID 0:无冗余,任何一块磁盘损坏都会导致数据丢失。
- RAID 1:每组镜像中最多坏 1 块磁盘。
- RAID 5:最多坏 1 块磁盘。
- RAID 6:最多坏 2 块磁盘。
- RAID 10:每组镜像中最多坏 1 块磁盘。
- RAID 50:每个 RAID 5 组最多坏 1 块磁盘。
- RAID 60:每个 RAID 6 组最多坏 2 块磁盘。
冗余性:
- RAID 0 无冗余,RAID 1 和 RAID 10 提供完全冗余,RAID 5 和 RAID 6 提供部分冗余。
性能:
- RAID 0 和 RAID 10 提供最高的读写性能,RAID 5 和 RAID 6 在写性能上有所降低。
存储利用率:
- RAID 0 和 RAID 1 的存储利用率分别为 100% 和 50%,RAID 5 和 RAID 6 的存储利用率随着磁盘数量增加而提高。
适用场景:
- 根据性能、冗余和存储利用率的需求选择适合的 RAID 方案。例如,RAID 10 适合高负载数据库,RAID 5 适合中小型文件服务器。
总结
不同的 RAID 方案在性能、冗余和存储利用率上各有优劣,选择时需要根据实际需求进行权衡。如果需要高性能且不关心冗余,可以选择 RAID 0;如果需要高冗余和高可用性,可以选择 RAID 1 或 RAID 10;如果需要兼顾性能和冗余,可以选择 RAID 5 或 RAID 6。
四、RAID硬盘失效处理
一般两种处理方法:热备和热插拔
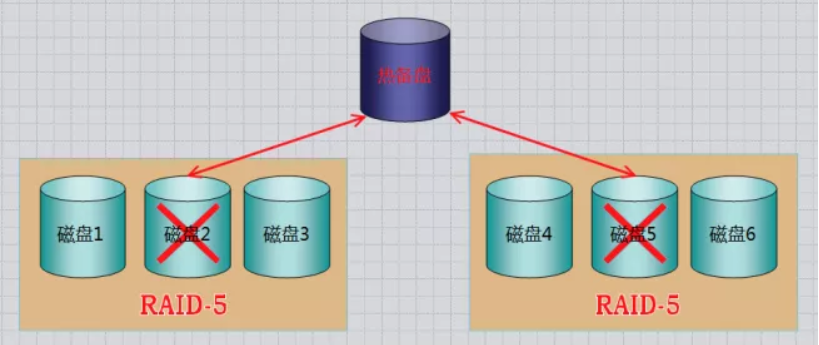
1、热备:HotSpare
定义:当冗余的RAID组中某个硬盘失效时,在不干扰当前RAID系统的正常使用的情况下,用RAID系统中另外一个正常的备用硬盘自动顶替失效硬盘,及时保证RAID系统的冗余性(就像汽车上的备胎)
**全局式:**备用硬盘为系统中所有的冗余RAID组共享 (多个汽车一个备胎)
**专用式:**备用硬盘为系统中某一组冗余RAID组专用 (一个汽车一个备胎)
如下图所示:是一个全局热备的示例,该热备盘由系统中两个RAID组共享,可自动顶替任何一个RAID中的一个失效硬盘
2、热插拔:HotSwap
定义:在不影响系统正常运转的情况下,用正常的物理硬盘替换RAID系统中失效硬盘。(灯变红了,有硬盘失效了,直接拔掉,插上一块新的,服务器要支持热插拔HotSwap)
五、RAID的实现方式
互动:我们做硬件RAID,是在装系统前还是之后?
答:先做阵列才装系统 ,一般服务器启动时,有显示进入配置Riad的提示,比如:按下CTRL+L/H/M进入配置raid界面
(1)硬RAID:需要RAID卡,我们的磁盘是接在RAID卡的,由它统一管理和控制。数据也由它来进行分配和维护;它有自己的cpu,处理速度快;
**(2)RAID:**通过操作系统实现
Linux内核中有一个md(multiple devices)模块在底层管理RAID设备,它会在应用层给我们提供一个应用程序的工具mdadm ,mdadm是linux下用于创建和管理软件RAID的命令。
mdadm命令常见参数解释:
| 命令 | 说明 | 命令 | 说明 |
|---|---|---|---|
| -C或--creat | 建立一个新阵列 | -r | 移除设备 |
| -A | 激活磁盘阵列 | -l 或--level= | 设定磁盘阵列的级别 |
| -D或--detail | 打印阵列设备的详细信息 | -n或--raid-devices= | 指定阵列成员(分区/磁盘)的数量 |
| -s或--scan | 扫描配置文件或/proc/mdstat得到阵列缺失信息 | -x或--spare-devicds= | 指定阵列中备用盘的数量 |
| -f | 将设备状态定为故障 | -c或--chunk= | 设定阵列的块chunk块大小 ,单位为KB |
| -a或--add | 添加设备到阵列 | -G或--grow | 改变阵列大小或形态 |
| -v | --verbose 显示详细信息 | -S | 停止阵列 |
六、软raid实验完整过程
实验环境:新添加11块硬盘,每块磁盘的作用如下
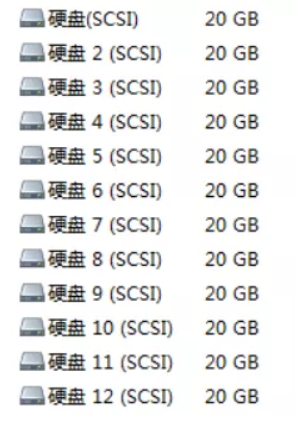
实验环境:
raid种类 磁盘 热备盘
raid0 sdb、sdc
raid1 sdd、sde sdf
raid5 sdg、sdh、sdi sdj
raid10 分区:sdk1、sdk2、sdk3、sdk4注:工作作中正常做raid全部是使用独立的磁盘来做的。为了节约资源,raid10以一块磁盘上多个分区来代替多个独立的磁盘做raid,但是这样做出来的raid没有备份数据的作用,因为一块磁盘坏了,这个磁盘上所做的raid也就都坏了。
软raid常用命令
创建RAID设备:
mdadm --create /dev/md0 --level=RAID级别 --raid-devices=磁盘数量 磁盘列表
其中,/dev/md0是要创建的RAID设备名称,RAID级别可以是0、1、4、5、6等,磁盘数量是参与RAID的磁盘个数,磁盘列表包含了要用于创建RAID的磁盘设备名称。
查看RAID设备详情:
mdadm --detail /dev/md0
该命令将显示关于RAID设备的详细信息,如RAID级别、磁盘状态、重建进度等。
添加磁盘到RAID设备:
mdadm --manage /dev/md0 --add /dev/sdX
其中,/dev/md0是RAID设备的名称,/dev/sdX是要添加的磁盘设备名称。
从RAID设备中移除磁盘:
mdadm --manage /dev/md0 --remove /dev/sdX
其中,/dev/md0是RAID设备的名称,/dev/sdX是要移除的磁盘设备名称。
监视RAID设备状态:
cat /proc/mdstat
该命令将实时显示RAID设备的状态,包括磁盘状态和重建进度等。
关闭RAID设备:
mdadm --stop /dev/md0
其中,/dev/md0是要关闭的RAID设备名称。mdadm --detail /dev/md0命令用于显示指定RAID设备(/dev/md0)的详细信息。以下是命令返回的一些重要信息:
RAID设备名称:显示设备的名称,例如"/dev/md0"。
RAID级别:指示RAID的级别,例如RAID 0、RAID 1、RAID 5等。
RAID设备状态:描述设备当前的状态,通常有以下几种可能:
“clean”:所有成员磁盘都正常。
“active”:RAID设备处于活动状态。
“degraded”:至少一个磁盘故障,RAID设备处于降级状态。
“inactive”:RAID设备当前处于非活动状态。
RAID成员磁盘信息:显示每个成员磁盘的详细信息,包括设备名称、RAID级别、当前状态、槽位号等。
RAID设备容量:显示RAID设备总容量。
重建进度:如果RAID设备正在重建过程中,命令将显示重建的进度。
RAID设备的冗余:如果使用的是具有冗余功能的RAID级别(如RAID 1、RAID 5等),命令将显示冗余信息。
RAID设备的校验值:如果启用了数据校验功能(如RAID 1、RAID 5等),命令将显示校验值的相关信息。创建RAID0
实验环境:
raid种类 磁盘 热备盘
raid0 sdb、sdc
1.创建raid0
[root@test ~]# yum -y install mdadm
[root@test ~]# mdadm -C -v /dev/md0 -l 0 -n 2 /dev/sdb /dev/sdc #-C 创建 -v 详细信息 -l阵列级别 -n 阵列成员数量
mdadm: chunk size defaults to 512K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@test ~]#
[root@test ~]# mdadm -Ds #-D 打印阵列设备详细信息 s得到阵列缺失信息
ARRAY /dev/md0 metadata=1.2 name=test:0 UUID=ed190f40:e8a3d2e2:785e8733:10c4837f
[root@test ~]#2. 查看阵列信息
[root@test ~]# mdadm -Ds #-D 打印阵列设备详细信息 s得到阵列缺失信息
ARRAY /dev/md0 metadata=1.2 name=test:0 UUID=ed190f40:e8a3d2e2:785e8733:10c4837f
[root@test ~]#
[root@test ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 3 20:58:14 2021
Raid Level : raid0 #raid级别
Array Size : 41908224 (39.97 GiB 42.91 GB) #39.97按照1024计算,42.92按照1000计算
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Feb 3 20:58:14 2021
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 512K #chunk是raid中最小的存储单位
Consistency Policy : none
Name : test:0 (local to host test)
UUID : ed190f40:e8a3d2e2:785e8733:10c4837f
Events : 0
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc #active sync:动态同步
[root@test ~]#
[root@test ~]# mdadm -Dsv > /etc/mdadm.conf #保存配置信息
[root@test ~]# cat /proc/mdstat #从内存中查看,重启后,信息丢失,所以要保存
Personalities : [raid0]
md0 : active raid0 sdc[1] sdb[0]
41908224 blocks super 1.2 512k chunks
unused devices: <none>
[root@test ~]#3. 对创建的RAID0进行文件系统创建并挂载
[root@test ~]# mkfs.xfs /dev/md0
meta-data=/dev/md0 isize=512 agcount=16, agsize=654720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10475520, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5120, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@test ~]# mkdir /raid0
[root@test ~]# mount /dev/md0 /raid0/
[root@test ~]# df -Th /raid0/
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 40G 33M 40G 1% /raid0
[root@test ~]#
[root@test ~]# echo 324 > /raid0/a.txt
[root@test ~]#4. 开机自动挂载
[root@test ~]# blkid /dev/md0
/dev/md0: UUID="0b5f7d62-d05b-41b5-8729-f6a094053b53" TYPE="xfs"
[root@test ~]# echo "UUID=0b5f7d62-d05b-41b5-8729-f6a094053b53 /raid0 xfs defaults 0 0" >> /etc/fstab
[root@test ~]#创建RAID1
实验内容如下:
raid种类 磁盘 热备盘
raid1 sdd、sde sdf
1)创建RAID1
2)添加1个热备盘
3)模拟磁盘故障,自动顶替故障盘
4)从raid1中移出故障盘
[root@test ~]# mdadm -C -v /dev/md1 -l 1 -n 2 -x 1 /dev/sd[d,e,f]
#-C 创建 -v 详细信息 -l阵列级别 -n 阵列成员数量 -x阵列备用盘数量
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 20954112K
Continue creating array?
Continue creating array? (y/n) y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md1 started.
[root@test ~]#
# 将RADI信息保存到配置文件
[root@test ~]# mdadm -Dsv > /etc/mdadm.conf
#查看 RAID 阵列信息:
[root@test ~]# mdadm -D /dev/md1
/dev/md1:
Version : 1.2
Creation Time : Wed Feb 3 21:09:10 2021
Raid Level : raid1 #raid级别
Array Size : 20954112 (19.98 GiB 21.46 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 2
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Wed Feb 3 21:10:55 2021
State : clean
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Consistency Policy : resync
Name : test:1 (local to host test)
UUID : 4a0dcf2d:012bff95:b381f67b:166c777d
Events : 17
Number Major Minor RaidDevice State
0 8 48 0 active sync /dev/sdd
1 8 64 1 active sync /dev/sde
2 8 80 - spare /dev/sdf #spare:备用
[root@test ~]#
#在RAID设备上创建文件系统
[root@test ~]# mkfs.xfs /dev/md1
meta-data=/dev/md1 isize=512 agcount=4, agsize=1309632 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5238528, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@test ~]# mkdir /raid1
[root@test ~]#
[root@test ~]# mount /dev/md1 /raid1/
#准备测试文件
[root@test ~]# cp /etc/passwd /raid1/
[root@test ~]#
#模拟损坏
下面模拟RAID1中数据盘/dev/sde出现故障,观察/dev/sdf备用盘能否自动顶替故障盘
先确定已经同步成功
[root@test ~]# mdadm -D /dev/md1
Consistency Policy : resync
[root@test ~]# mdadm /dev/md1 -f /dev/sde
#-f 将设备状态设为故障
mdadm: set /dev/sde faulty in /dev/md1
[root@test ~]#
#查看一下阵列状态信息
[root@test ~]# mdadm -D /dev/md1
Rebuild Status : 27% complete
Name : test:1 (local to host test)
UUID : 4a0dcf2d:012bff95:b381f67b:166c777d
Events : 25
Number Major Minor RaidDevice State
0 8 48 0 active sync /dev/sdd
2 8 80 1 spare rebuilding /dev/sdf
1 8 64 - faulty /dev/sde
[root@test ~]#
#spare rebuilding 热备重建中,也就是 sdd会把自己的数据同步到sdf
#rebuild Status : 27% complete 同步状态 (此时md1中的文件依然正常使用,因为sdd在工作)
#faulty 错误
#更新配置文件
[root@test ~]# mdadm -Dsv > /etc/mdadm.conf
[root@test ~]#
#
查看数据是否丢失
[root@test ~]# ls /raid1/ #数据正常,没有丢失
passwd
#重要的数据如:数据库 ; 系统盘 (把系统安装到raid1的md1设备上,然后对md1做分区)
#移除损坏的设备:
[root@test ~]# mdadm -r /dev/md1 /dev/sde #-r 移除设备
mdadm: hot removed /dev/sde from /dev/md1
[root@test ~]#
#查看信息:
[root@test ~]# mdadm -D /dev/md1
/dev/md1:
Number Major Minor RaidDevice State
0 8 48 0 active sync /dev/sdd
2 8 80 1 active sync /dev/sdf
[root@test ~]#
#已经没有热备盘了,添加一块新热备盘。
[root@test ~]# mdadm -a /dev/md1 /dev/sde #-a 添加设备到阵列
mdadm: added /dev/sde
[root@test ~]#
#再次查看:
[root@test ~]# mdadm -D /dev/md1
Number Major Minor RaidDevice State
0 8 48 0 active sync /dev/sdd
2 8 80 1 active sync /dev/sdf
3 8 64 - spare /dev/sde
[root@test ~]#创建RAID5
实验环境:
raid 种类 磁盘 热备盘
raid5 sdg、sdh、sdi sdj
1)创建RAID5, 添加1个热备盘,指定chunk大小为32K
-x 指定阵列中备用盘的数量
-c或--chunk= 设定阵列的块chunk块大小 ,单位为KB (普通文件就默认就可以,如果存储大文件就调大些,如果存储小文件就调小些,这里chunk就类似簇,块一样的概念,是阵列的最小存储单位)
2)停止阵列,重新激活阵列
3)使用热备盘,扩展阵列容量,从3个磁盘扩展到4个
(1) 创建RAID-5
[root@test ~]# mdadm -C -v /dev/md5 -l 5 -n 3 -x 1 -c 32 /dev/sd{g,h,i,j}
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: size set to 20954112K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md5 started.
[root@test ~]#
[root@test ~]# mdadm -D /dev/md5
/dev/md5:
Version : 1.2
Creation Time : Wed Feb 3 21:28:04 2021
Raid Level : raid5 #raid5
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 3 #
Total Devices : 4 #
Persistence : Superblock is persistent
Update Time : Wed Feb 3 21:28:25 2021
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 4
Failed Devices : 0
Spare Devices : 2
Layout : left-symmetric
Chunk Size : 32K #
Consistency Policy : resync
Rebuild Status : 24% complete #同步状态,同步完,此行消失。
Name : test:5 (local to host test)
UUID : 8e924bbf:062d6aa0:73e496c1:ccf7c384
Events : 4
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
1 8 112 1 active sync /dev/sdh
4 8 128 2 spare rebuilding /dev/sdi
3 8 144 - spare /dev/sdj #热备盘
[root@test ~]#
(2) 扩展RAID5磁盘阵列
将热备盘增加到md5中,使用md5中可以使用的磁盘数量为4块
[root@test ~]# mdadm -G /dev/md5 -n 4 -c 32
-G或--grow 改变阵列大小或形态
[root@test ~]# mdadm -Dsv > /etc/mdadm.conf #保存配置文件备注:阵列只有在正常状态下,才能扩容,降级及重构时不允许扩容。对于raid5来说,只能增加成员盘,不能减少。而对于raid1来说,可以增加成员盘,也可以减少。
[root@test ~]# mdadm -D /dev/md5 #查看状态
/dev/md5:
Version : 1.2
Creation Time : Wed Feb 3 21:28:04 2021
Raid Level : raid5
Array Size : 41908224 (39.97 GiB 42.91 GB) #发现新增加硬盘后空间没有变大,为什么?
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Wed Feb 3 21:32:56 2021
State : clean, reshaping
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 32K
Consistency Policy : resync
Reshape Status : 81% complete
Delta Devices : 1, (3->4)
Name : test:5 (local to host test)
UUID : 8e924bbf:062d6aa0:73e496c1:ccf7c384
Events : 60
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
1 8 112 1 active sync /dev/sdh
4 8 128 2 active sync /dev/sdi
3 8 144 3 active sync /dev/sdj
# Reshape Status : 81% complete
#重塑状态:81%完成 ,等到100%, 数据才同步完,同步完后会变成成:Consistency Policy : resync
#一致性策略:再同步,表示已经同步完
#等一会,等所有数据同步完成后,查看md5空间大小:
[root@test ~]# mdadm -D /dev/md5
Array Size : 62862336 (59.95 GiB 64.37 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
1 8 112 1 active sync /dev/sdh
4 8 128 2 active sync /dev/sdi
3 8 144 3 active sync /dev/sdj
[root@test ~]#(3) 停止MD5阵列
[root@test ~]# mdadm -Dsv > /etc/mdadm.conf #停止前,一定要先保存配置文件
[root@test ~]# mdadm -D /dev/md5 #停止前,请确认数据已经同步完(同步不完成,有时会无法激活)
Consistency Policy : resync #数据已经同步完
[root@test ~]# mdadm -S /dev/md5 #-S 停止阵列
mdadm: stopped /dev/md5
[root@test ~]#
(4) 激活MD5阵列
[root@test ~]# mdadm -As #-A 激活磁盘阵列 s扫描配置文件得到阵列信息
mdadm: /dev/md5 has been started with 4 drives.
[root@test ~]#👀 注意:
如果使用软RAID5的物理机遇到一块硬盘损坏的情况,以下是一些处理步骤:
确认磁盘状态:首先,使用RAID管理工具(例如mdadm)检查磁盘状态。运行命令mdadm --detail /dev/md0 (根据你的实际情况,/dev/md0可能会有所不同)来查看RAID设备的详细信息,包括磁盘状态。
磁盘故障确认:确认哪一块磁盘出现了故障。通常,RAID管理工具会显示该磁盘的状态为"failed"或者"degraded"。
更换故障磁盘:将故障的磁盘从物理机中拔掉,并使用一个新的硬盘来替换。确保新硬盘与旧硬盘的容量、速度和接口类型相同。
重新建立RAID设备:在更换磁盘后,运行命令mdadm --manage /dev/md0 --remove /dev/sdX(/dev/sdX是故障磁盘的设备名称)来移除故障磁盘。然后,运行命令mdadm --manage /dev/md0 --add /dev/sdY(/dev/sdY是新磁盘的设备名称)来添加新磁盘到RAID设备中。
等待重建:RAID设备会开始进行重建过程,即将数据从其余的磁盘复制到新添加的磁盘上。这个过程可能需要一些时间,具体时间取决于磁盘大小和系统负载。
监控重建过程:使用RAID管理工具监视重建过程。例如,运行命令cat /proc/mdstat可以实时显示重建进度。
完成重建:一旦重建过程完成,RAID设备将返回到正常状态。你可以再次运行mdadm --detail /dev/md0来确认设备状态。
mdadm --manage /dev/md0 --add /dev/sde1
cat /proc/mdstat创建RAID10
实验环境:
raid10 分区:sdk1,sdk2,sdk3.sdk4
#fdisk /dev/sdk #分4个主分区,每个分区1G大小
[root@test ~]# ls /dev/sdk*
/dev/sdk /dev/sdk1 /dev/sdk2 /dev/sdk3 /dev/sdk4
[root@test ~]#
[root@test ~]# mdadm -C -v /dev/md10 -l 10 -n 4 /dev/sdk[1-4]
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 1046528K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md10 started.
[root@test ~]#
[root@test ~]# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md10 : active raid10 sdk4[3] sdk3[2] sdk2[1] sdk1[0]
2093056 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]
[==================>..] resync = 94.6% (1982720/2093056) finish=0.0min speed=198272K/sec
md5 : active raid5 sdg[0] sdj[3] sdi[4] sdh[1]
62862336 blocks super 1.2 level 5, 32k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sde[3](S) sdf[2] sdd[0]
20954112 blocks super 1.2 [2/2] [UU]
md0 : active raid0 sdc[1] sdb[0]
41908224 blocks super 1.2 512k chunks
unused devices: <none>
[root@test ~]#删除RAID所有信息及注意事项
[root@test ~]# umount /dev/md0 #如果你已经挂载raid,就先卸载。
[root@test ~]# mdadm -Ss #停止raid设备,千万注意,这个命令会直接删除掉软raid的。。。。
[root@test ~]# rm -rf /etc/mdadm.conf #删除raid配置文件
[root@test ~]# mdadm --zero-superblock /dev/sdb #清除物理磁盘中的raid标识 ,MD超级块
[root@test ~]# mdadm --zero-superblock /dev/sdb
mdadm: Unrecognised md component device - /dev/sdb #代表已经擦除掉MD超级块,找不到raid标识的信息了,擦除MD超级快,执行两次会报这个信息。
#参数:--zero-superblock : #擦除设备中的MD超级块七、实战:企业中硬件raid5的配置
这个自己工作中做过好多次了;
联想(ThinkServer) RD650做Raid
联想(ThinkServer) RD650(640升级)2U机架式 服务器2.5‘’盘位 2*E5-2609V4/双电源 升级至32G内存3个300G硬盘
https://item.jd.com/10502926632.html?jd_pop=eef9047a-999c-421a-8f04-fd4678c9cd4c#crumb-wrap
 操作步骤:
操作步骤:
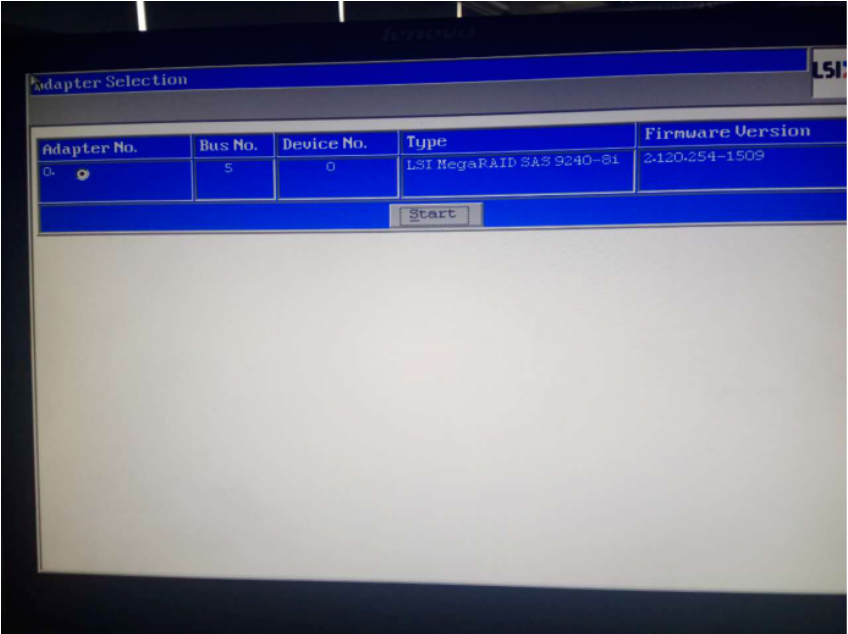
开机后,进入raid配置界面有提示,按ctrl +h进入raid配置界面:
连接服务器以后,显示以下界面,单击start进入配置页面:
单机Configuration Wizard (配置向导)进行配置:
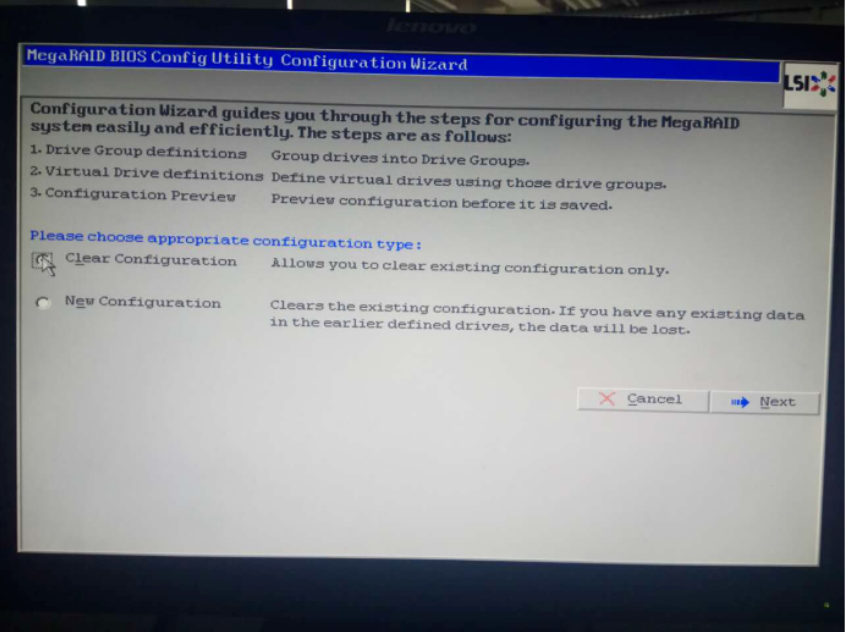
单机Clear Configuration(清除配置)清除旧的配置:
清除以后,显示如下图,再次单机Configuration Wizard进行配置,:
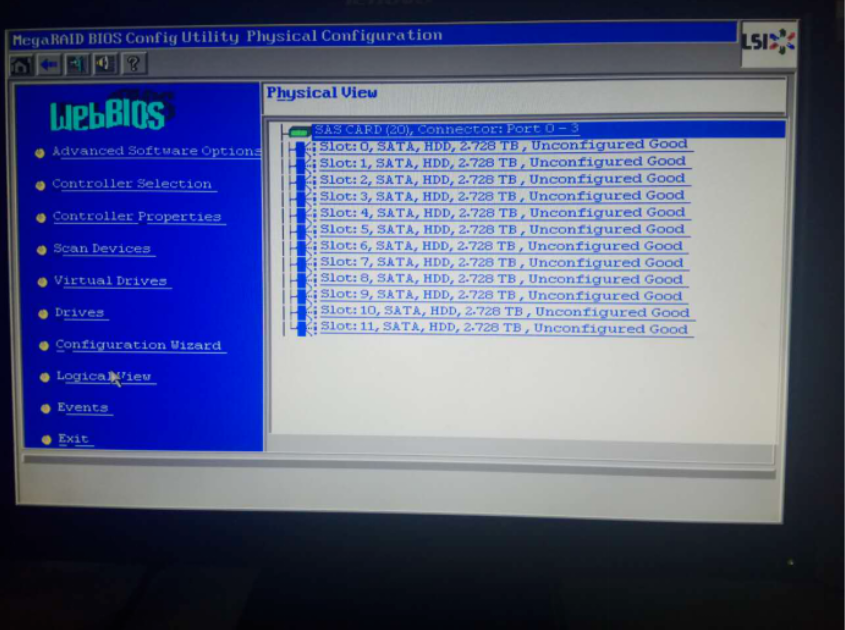
单机new Configuration 进行新的配置:
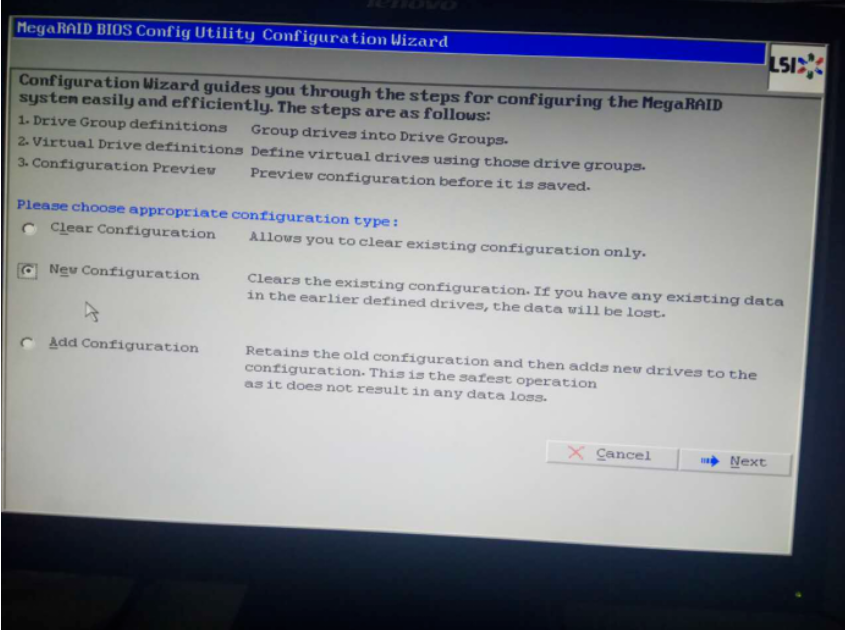
进入如下页面,单击Manual Configuration(配置手册):
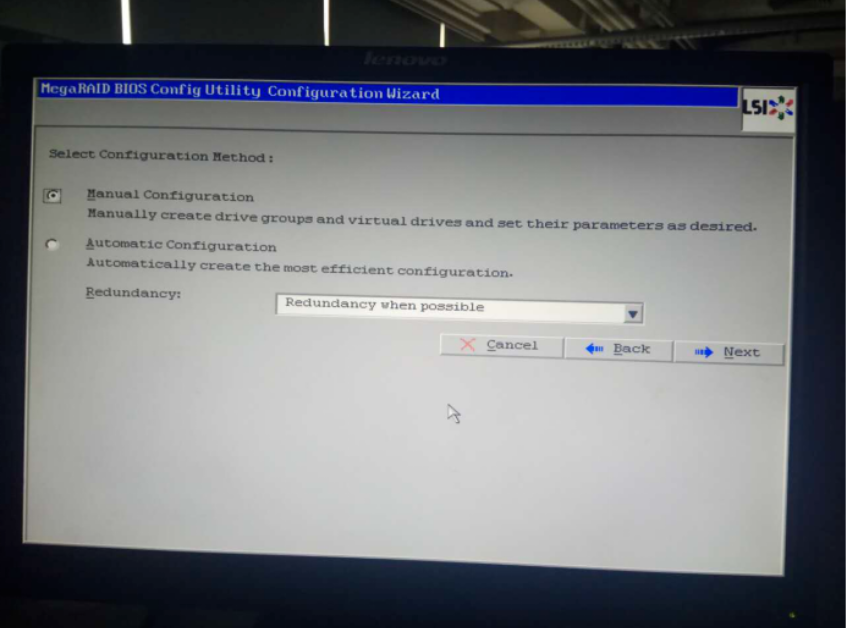
选择左侧两块磁盘,做个raid1,单机 Add To Array(加入阵列):
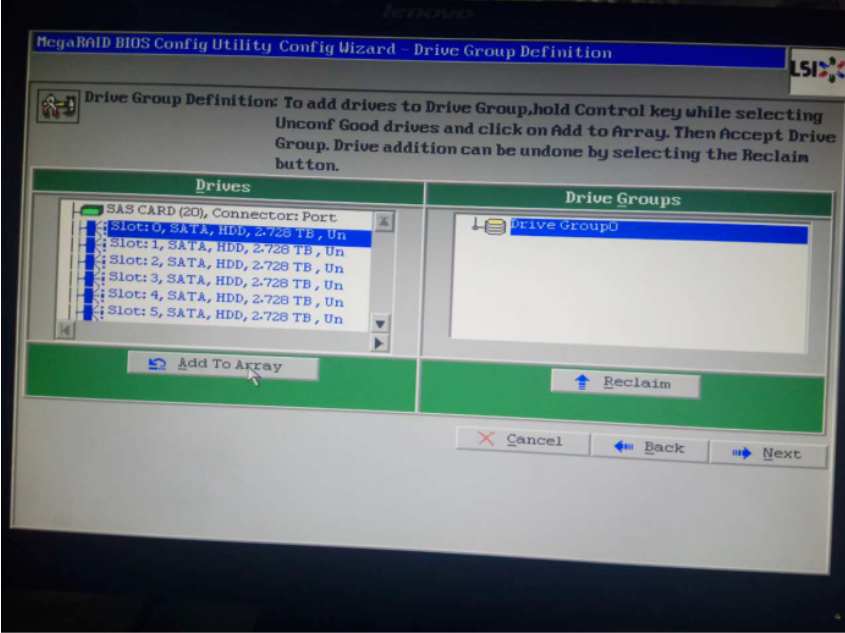
此处我们把两块盘做raid1,单机Accept DG(接受磁盘组,DG为disk groups的缩写):
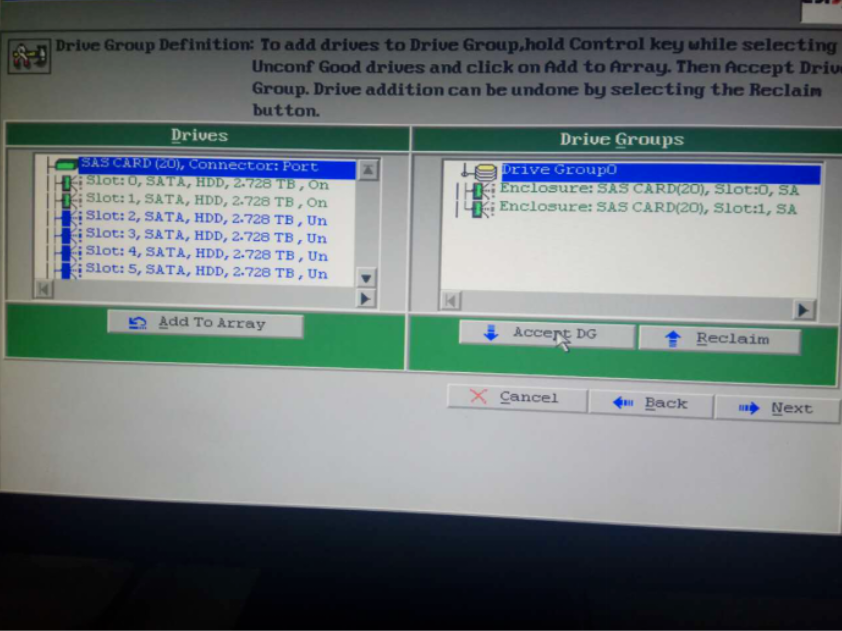
然后单机next,会进入如下页面,单机Add to SPAN(缚住或扎牢的意思,理解为将两块盘捆绑到一起),单机next:
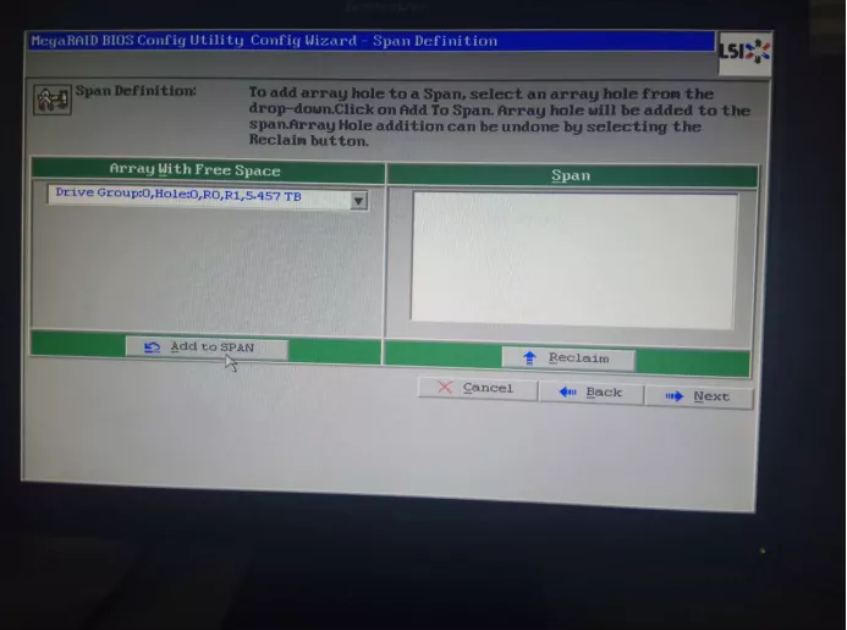
进入如下页面,可以选择raid(我们做的而是raid1),然后单机Update Size,accept,直接next就可以:
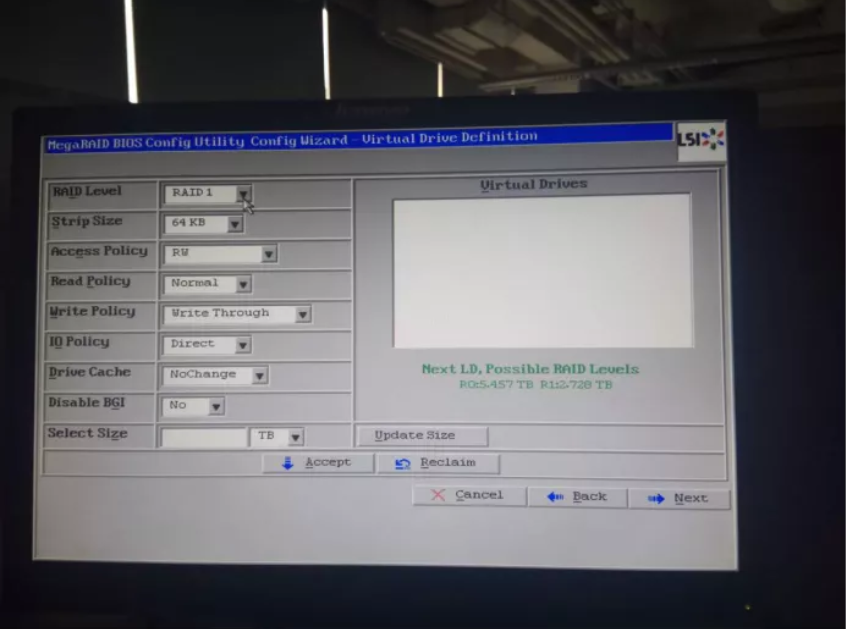
后面全部选next或者yes,当碰到下面这步骤时,可以忽略,直接点back:
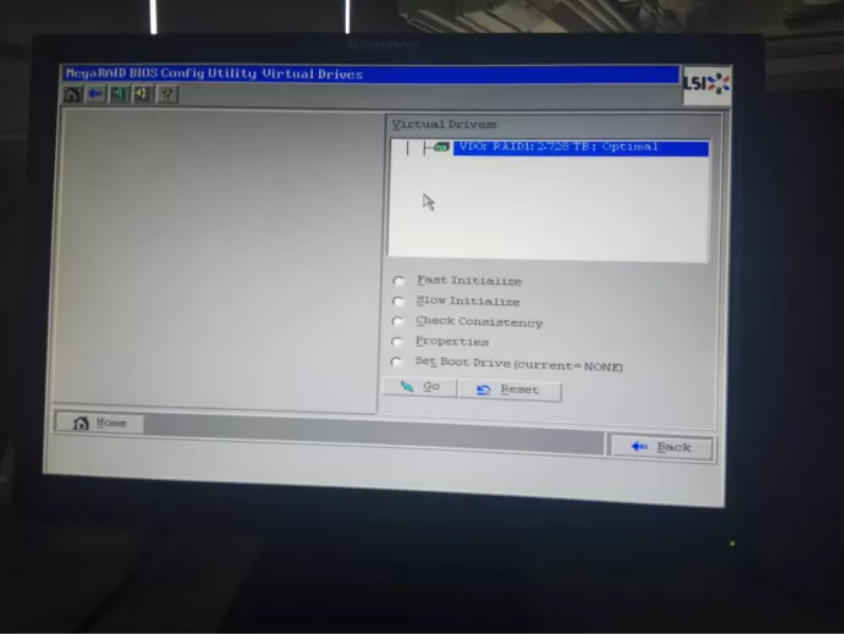
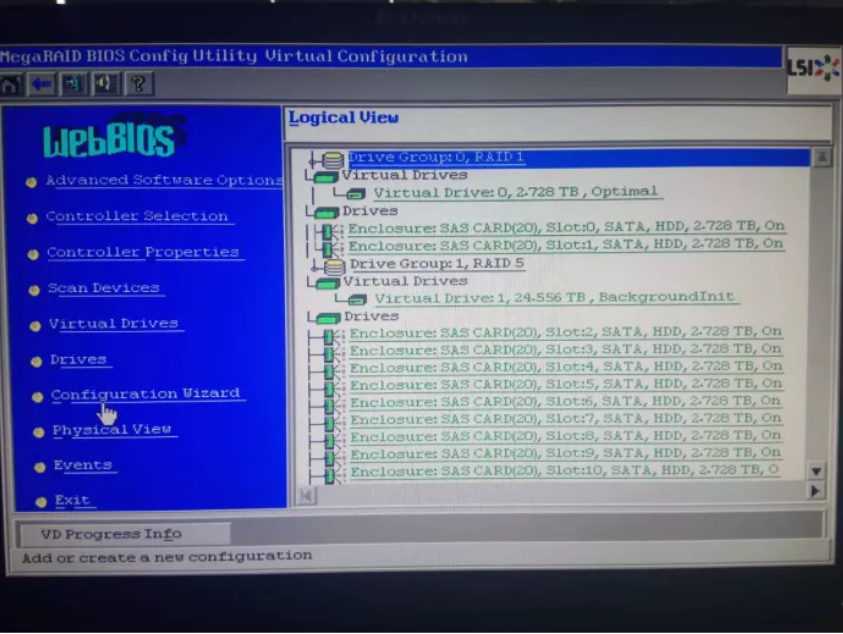
会回到之前的Configuration Wizard配置向导页面, 后面选择add Configuration(添加配置),后面做raid5的10块盘操作步骤和之前相同。最后配置完成的结果如下:
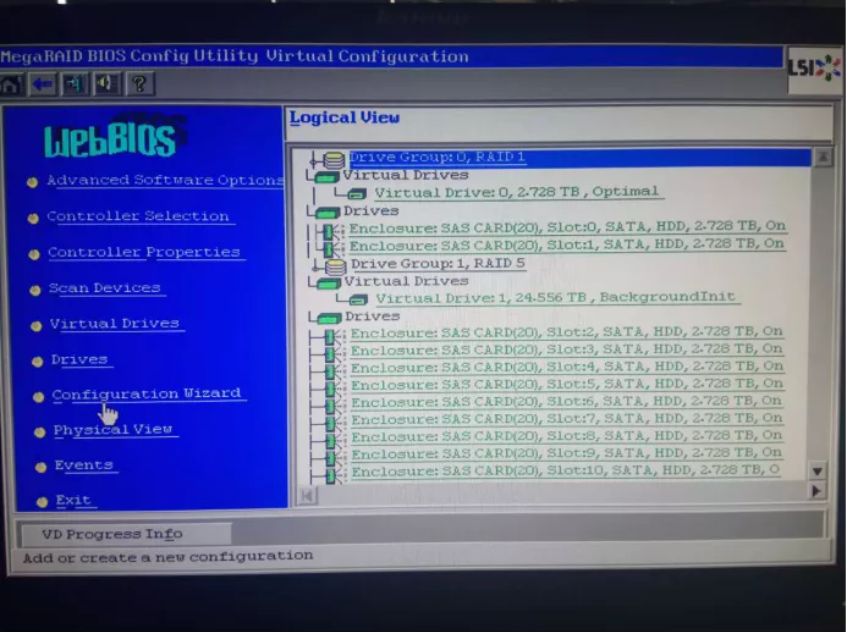
八、其它
1、磁盘达到sdz以后,名字应该如何排?
sdaa 、 sdab 。。。

2、为什么先把两块磁盘做raid1,然后把后面的磁盘都做成raid5
raid1是镜像卷,安装系统用,一块坏了,不影响系统运行。
raid5存数据;
3、如果服务器主板不支持硬raid , 可以用raid卡。
扩展:常见raid卡:
戴尔(DELL) 服务器RAID阵列卡 H730P 大卡 2G缓存+后备电池保障数据读写不受断电影响


关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码 x2675263825 (舍得), qq:2675263825。

🍀 微信公众号 《云原生架构师实战》

🍀 csdn https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 知乎 https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
