
1、文件管理
文件类

目录
[toc]
tree命令
tree命令可以以目录树的形式显示指定(默认显示这个文件系统)目录的所有文件夹和文件。
- 安装:
yuminstall-ytree- 使用方法
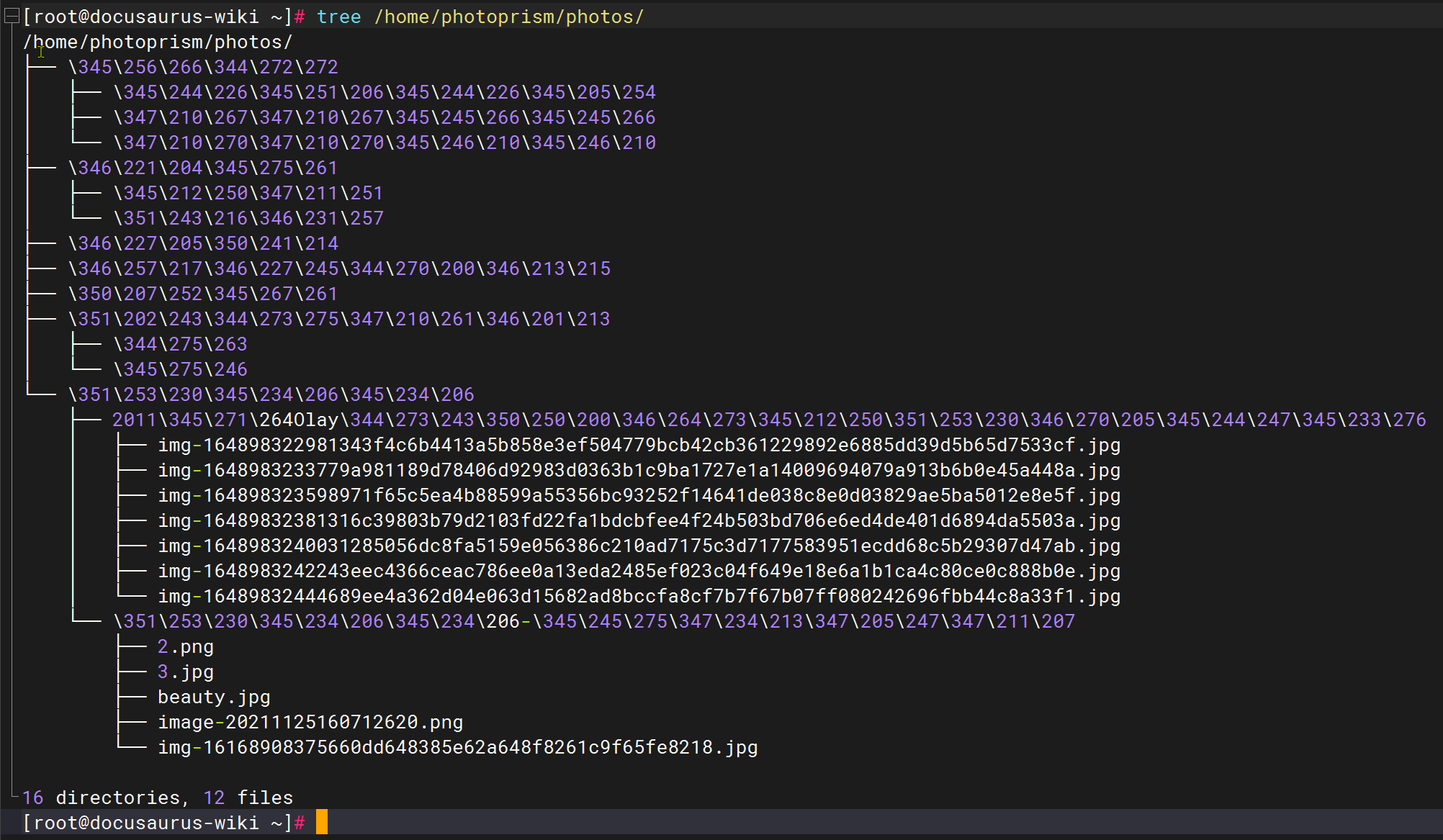
$treefolder案例:tree命令测试
[root@hg-linux-test ~]# tree testtest├──1.txt├──2.txt└──test1directory,2files[root@hg-linux-test ~]#案例:解决tree命令显示中文乱码问题 -N
2023年12月16日(已解决)
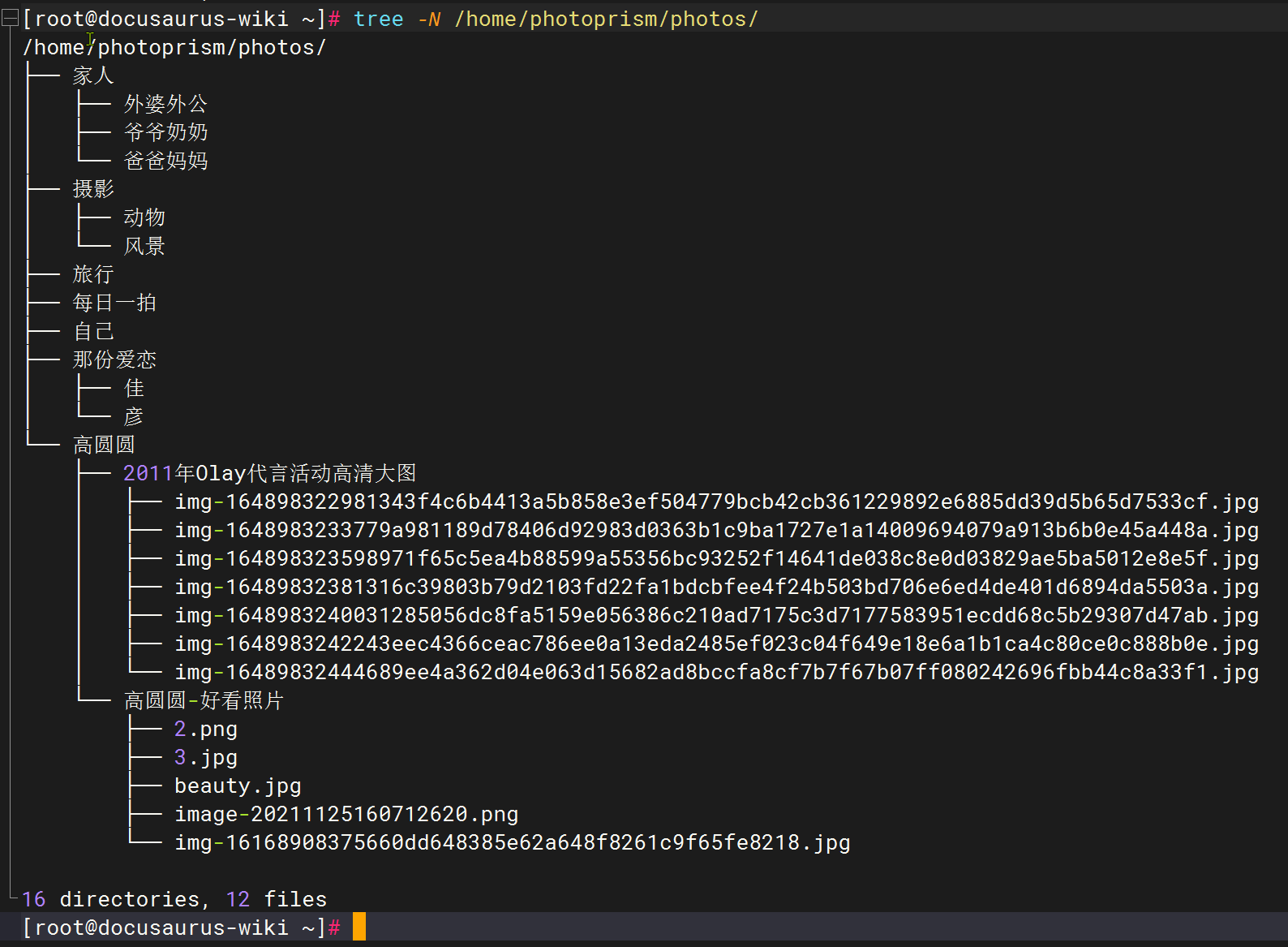
但是,默认情况下,tree命令无法显示中文文件或文件夹名,。这时可以用选项-N来显示中文文件名:
$tree-Nfolder- 测试过程
默认情况下,tree命令无法显示中文文件或文件夹名,。
这时可以用选项-N来显示中文文件名:
find命令查找文件命令
linux find命令使用案例?
find是Linux中强大且广泛使用的命令,用于在指定目录及其子目录中搜索文件和目录。以下是一些find命令的使用案例:
查找特定文件名:
在当前目录及其子目录中查找名为 “filename.txt” 的文件:
find . -name "filename.txt"==在指定目录 (“/path/to/dir”) 及其子目录中查找名为 “filename.txt” 的文件:==
find /path/to/dir -name "filename.txt"
根据文件类型进行查找:
查找所有普通文件(非目录、链接等):
find . -type f查找所有目录:
find . -type d查找所有符号链接文件:
find . -type l
根据文件大小进行查找:
查找大于100MB的文件:
find . -size +100M查找小于1KB的文件:
find . -size -1k
结合多个条件进行查找:
查找名为 “filename.txt” 并且文件大小大于1MB的文件:
find . -name "filename.txt"-size +1M查找以 “.txt” 结尾的文件并且最近7天内修改过的文件:
find . -name "*.txt"-mtime -7
执行操作:
对查找到的文件执行特定的操作,如打印文件名:
find . -type f -exec echo {} \;删除所有以 “.txt” 结尾的文件:
find . -name "*.txt"-delete
这些只是find命令的一些常见用例,实际上它还有更多的选项和功能。您可以通过运行man find命令来查阅完整的find命令的文档和更多的示例。
find里可以使用通配符,例如*吗?
是的,find命令支持使用通配符(如星号 “*”) 进行模式匹配,以便更灵活地搜索文件和目录。下面是几个示例:
查找以 “.txt” 结尾的文件:
find . -name "*.txt"查找以 “file” 开头并以 “.csv” 结尾的文件:
find . -name "file*.csv"查找名称中包含 “keyword” 的文件:
find . -name "*keyword*"
需要注意的是,在使用通配符进行模式匹配时,确保通配符被引号括起来,以确保通配符在运行之前被find命令解释,而不是由shell解释。
另外,find命令也支持其他模式匹配选项,如?表示匹配单个字符,[]表示匹配字符集合等。您可以参考find命令的文档或使用man find命令了解更多关于模式匹配的详细信息和示例。
案例:在指定目录查找特定文件名
==在指定目录 (“/path/to/dir”) 及其子目录中查找名为 “filename.txt” 的文件:==
find /path/to/dir -name "filename.txt"案例:在指定目录查找某类型的文件
查找以 “.txt” 结尾的文件:
find . -name "*.txt"案例:在指定目录查找某类型的文件(==或功能==)
find里通配符可以使用或吗?
在find命令中,通配符本身是不能用于表示逻辑 “或” 的,但您可以使用 -o选项来实现类似的功能。下面是一个示例:
假设您想要查找以 “.txt” 或 “.csv” 结尾的文件,您可以使用 -name选项和 -o选项结合起来使用:
find . \(-name "*.txt"-o -name "*.csv"\)上述命令中,使用圆括号 \(和 \)来分组两个条件,然后使用 -o表示逻辑 “或”。
请注意,在使用 \(和 \)进行分组时,需要对它们进行转义,以防止它们被shell解释。同样,通配符也需要用引号括起来,以避免被shell提前展开。
希望这个解释能够帮助到您!如果您还有其他问题,请随时提问。
案例:对如何find命令找出的文件执行特定的操作?
find命令是Linux和Unix系统中一个非常强大的工具,用于基于各种条件搜索文件系统中的文件。你可以将find命令的输出与其他命令结合使用,以对找到的文件执行特定的操作。这通常通过使用-exec选项或将find命令的输出通过管道传递给xargs命令来实现。
使用-exec选项
-exec选项允许你为find命令找到的每个文件执行一个命令。命令的语法如下:
find[搜索路径] [选项] -exec [要执行的命令] {} \;这里,{}是一个占位符,代表当前找到的文件名;\;是命令的结束标志。
例如,如果你想要找到当前目录及子目录下所有的.txt文件,并删除它们,你可以使用:
find.-typef-name"*.txt"-execrm{}\;如果你想要为找到的每个文件执行更复杂的命令或多个命令,可以使用sh或bash作为-exec参数。例如,打印每个找到的文件名并删除这些文件:
find.-typef-name"*.txt"-execsh-c'echo "Deleting file:{}";rm {}'\;使用xargs命令
另一种方式是使用xargs命令。xargs可以从标准输入接收数据,并将这些数据作为参数传递给指定的命令,这使得xargs与find命令配合非常有效。
例如,删除当前目录及子目录下所有的.txt文件:
find.-typef-name"*.txt"|xargsrmxargs默认以空格为分隔符将输入分割成多个参数,对于包含空格、引号或其他特殊字符的文件名,可以使用find命令的-print0选项和xargs的-0选项,以null字符作为记录的终止符,从而安全地处理这些文件名:
find.-typef-name"*.txt"-print0|xargs-0rm使用xargs执行复杂命令时,可以结合使用sh或bash:
find.-typef-name"*.txt"-print0|xargs-0-I{}sh-c'echo "Deleting file:{}";rm {}'这里,-I {}选项指定了一个替换字符串,该字符串在xargs将要执行的命令中被每个输入项替换。
不管是使用-exec还是xargs,都能有效地将find命令与其他命令结合起来,对找到的文件执行各种操作。选择哪种方法取决于你的具体需求以及你觉得哪种方法更方便。
实际测试案例
find/root/rsync/site-name"*.html"find/root/rsync/site\(-name"*.html"-o-name"*.png"\)find/root/rsync/site\(-name"*.html"-o-name"*.png"-o-name"*.md"\)du命令显示每个文件和目录的磁盘使用空间
du命令 也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
语法
du[选项][文件]选项
-a或-all显示目录中个别文件的大小。-b或-bytes显示目录或文件大小时,以byte为单位。-c或--total除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。(常用)-k或--kilobytes以KB(1024bytes)为单位输出。(常用)-m或--megabytes以MB为单位输出。-s或--summarize仅显示总计,只列出最后加总的值。(常用)-h或--human-readable以K,M,G为单位,提高信息的可读性。(常用)-x或--one-file-xystem以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。-L<符号链接>或--dereference<符号链接>显示选项中所指定符号链接的源文件大小。-S或--separate-dirs显示个别目录的大小时,并不含其子目录的大小。-X<文件>或--exclude-from=<文件>在<文件>指定目录或文件。--exclude=<目录或文件>略过指定的目录或文件。-D或--dereference-args显示指定符号链接的源文件大小。-H或--si与-h参数相同,但是K,M,G是以1000为换算单位。-l或--count-links重复计算硬件链接的文件。-d或者--max-depth通过du的-d参数,或--max-depth,设置查询的目录深度案例:显示目录或者文件所占空间
1.root@localhost[test]# du2.608./test63.308./test44.4./scf/lib5.4./scf/service/deploy/product6.4./scf/service/deploy/info7.12./scf/service/deploy8.16./scf/service9.4./scf/doc10.4./scf/bin11.32./scf12.8./test313.1288.只显示当前目录下面的子目录的目录大小和当前目录的总的大小,最下面的1288为当前目录的总大小。
案例:显示指定文件所占空间
1.[root@localhost test]#dulog2012.log2.300log2012.log案例:查看指定目录的所占空间
1.[root@localhost test]#duscf2.4scf/lib3.4scf/service/deploy/product4.4scf/service/deploy/info5.12scf/service/deploy6.16scf/service7.4scf/doc8.4scf/bin9.32scf案例:显示多个文件所占空间
1.[root@localhost test]#dulog30.tar.gzlog31.tar.gz2.4log30.tar.gz3.4log31.tar.gz案例:只显示总和的大小
1.[root@localhost test]#du-s2.1288.3.4.[root@localhost test]#du-sscf5.32scf案例:显示总和的大小且易读 (常用)
[root@ecs1 ~]# du -sh /var/6.6G/var/[root@ecs1 ~]#案例:设置查询的目录深度
再相对高效一点的方法是通过 du 的 - d 参数,或 --max-depth,设置查询的目录深度,目录深度增加,所查询的目录,展示出来会很多,这个时候可以通过 grep 进行过滤。
du -h -d 2|grep [GT] |sort -nr du -h --max-depth=2|grep [GT] |sort -nr通过这样的方式,可以搜出以 G 或者 T 为单位的占用磁盘空间的大目录,并排序。
cat命令(查看文本文件内容)
显示文本文件中所有数据。
cat 2个重要应用
1.查看小文件内容;
2.配合重定向>实现多个文件内容的合并;
格式:
cat [OPTION]... [FILE]...常见选项:
-n:对显示出的每一行进行编号-b:非空行编号-s:压缩连续的空行成一行-E,--show-ends#-E:显示行结束符$display$ atendofeachline-v,--show-nonprinting#如果里面含有中文,则会出现乱码;use^andM-notation,exceptforLFDandTAB-T,--show-tabs# -T参数会用^I字符组合去替换文中的所有制表符。displayTABcharactersas^I-A,--show-all#-A:显示所有控制符equivalentto-vET案例:cat -/E/T/v/A 用法
结论:
我们每次在linux上执行脚本前,首先要判断一个shell脚本是否存在问题(是否有在windows环境下做过配置,即可能出现过换行操作)可以直接用cat -v shell.sh进行判断?(通过现象可判断,如果是中文格式的话,每行末尾都会出现^M字样!!!)
[root@test ~]# cat -v fa.txt abc123M-fM-^HM-^QM-gM-^HM-1M-dM-8M--M-eM-^[M-=#如果里面含有中文,则会出现乱码;或者直接使用cat -A shell.sh进行判断即可!
特别注意:Linux控制符包括行结束符$和tab符^I。
**测试过程1:**以下为linux格式文件,包含tab键,中文:
[root@test ~]# cat fa.txt abc123我爱中国[root@test ~]# cat -E fa.txt #-E:显示行结束符$abc$123$$$我爱中国$[root@test ~]# cat -T fa.txt # -T参数会用^I字符组合去替换文中的所有制表符。abc123^I^I我爱中国[root@test ~]# cat -v fa.txt abc123M-fM-^HM-^QM-gM-^HM-1M-dM-8M--M-eM-^[M-=#如果里面含有中文,则会出现乱码;[root@test ~]# cat -A fa.txt abc$123^I^I$$$M-fM-^HM-^QM-gM-^HM-1M-dM-8M--M-eM-^[M-=$ #-A:显示所有控制符[root@test ~]# [root@test ~]# ll fa.txt -rw-r--r--.1rootroot25Feb310:09fa.txt[root@test ~]# file fa.txt fa.txt:UTF-8Unicodetext[root@test ~]# hexdump -C fa.txt 000000006162630a31323309090a0a0ae68891e7|abc.123.........|0000001088b1e4b8ade59bbd0a|.........|00000019[root@test ~]#**测试过程2:**以下为lwin格式文件,包含tab键,中文:(在windows上新创建一个文件,编码格式可以设置我ANSCii)
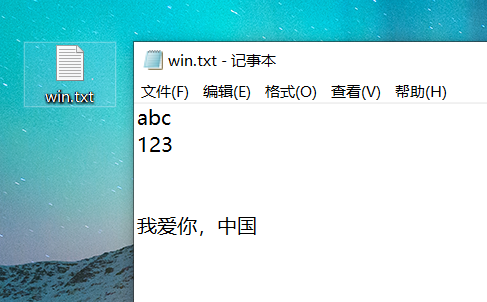
[root@test ~]# cat win.txt abc123ϒ°®ţ£¬א¹[root@test~]#cat-Ewin.txt$bc$23 $$ϒ°®ţ£¬א¹[root@test~]#cat-Twin.txtabc123^I^Iϒ°®ţ£¬א¹[root@test~]#cat-vwin.txt#通过现象可判断,如果是中文格式的话,每行末尾都会出现^M字样!!!abc^M123^M^M^MM-NM-RM-0M-.M-DM-cM-#M-,M-VM-PM-9M-z[root@test~]#cat-Awin.txtabc^M$123^I^I^M$^M$^M$M-NM-RM-0M-.M-DM-cM-#M-,M-VM-PM-9M-z[root@test~]#[root@test ~]# ll win.txt -rw-r--r--.1rootroot28Feb310:14win.txt[root@test ~]# file win.txt win.txt:ISO-8859text,withCRLFlineterminators[root@test ~]# hexdump -C win.txt 000000006162630d0a31323309090d0a0d0a0d0a|abc..123........|00000010ced2b0aec4e3a3acd6d0b9fa|............|0000001c[root@test ~]#案例:cat -n/b/s 用法(关于行号显示)
-n:对显示出的每一行进行编号-b:非空行编号-s:压缩连续的空行成一行[root@test ~]# cat -n f.txt #-n:(1)对显示出的每一行进行编号1a2b3c456d7e8910f11g12h[root@test ~]# cat -b f.txt #-b:(2)非空行编号 等价于 nb f.txt命令1a2b3c4d5e6f7g8h[root@test ~]# cat -s f.txt #-s:(3)压缩连续的空行成一行abcdefgh[root@test ~]#案例:cat 1.txt 2.txt > 12.txt #配合重定向>实现多个文件内容的合并
[root@test ~]# lltotal8-rw-r--r--1rootroot4Feb220:431.txt-rw-r--r--1rootroot9Feb220:432.txt[root@test ~]# cat 1.txt zxl[root@test ~]# cat 2.txt iloveyou[root@test ~]# cat 1.txt 2.txt >12.txt #配合重定向>实现多个文件内容的合并;文件顺序代表合并后内容的先后顺序;[root@test ~]# cat 12.txt zxliloveyou[root@test ~]#tac命令
(逆向显示文本内容(注意,是按行逆向的))
案例:tacfile逆向显示文本内容。[root@centos76 ~]#cat fa.txt 12345[root@centos76 ~]#tac fa.txt 54321[root@centos76 ~]#案例:tac接受标准输入命令root@centos76~]#tacabc#这里输入要输入完的命令后,按ctrl d后,即可实现逆向效果:cba[root@centos76 ~]#案例:tac接收来自管道的内容[root@centos76 ~]#seq 512345[root@centos76 ~]#seq 5|tac54321[root@centos76 ~]#tee命令
"tee"命令是一个在Unix和Linux系统中常用的命令,它从标准输入读取数据,并将其写入一个文件和标准输出。
下面是一些tee命令的常见用法:
将标准输入的内容复制到文件中:
bashcommand|teefile.txt这样可以将命令的输出内容同时输出到屏幕和文件file.txt中。
在执行一个命令的同时将输出内容追加到文件中:
bashcommand|tee-afile.txt使用"-a"选项可以将输出内容追加到文件中,而不是覆盖文件。
将标准输入的内容复制到多个文件:
bashcommand|teefile1.txtfile2.txtfile3.txt这样可以将命令的输出内容同时输出到屏幕和多个文件中。
使用tee命令的输出作为其他命令的输入:
bashcommand1|teefile.txt|command2这里,命令command1的输出会被tee命令复制到屏幕和文件file.txt中,同时也作为命令command2的输入。
这些只是tee命令的一些基本用法,还有其他一些选项和用法可以进一步定制和扩展tee命令的功能。你可以在终端中输入"man tee"来查看完整的tee命令文档。
nl命令
(显示行号,相当于cat -b)
案例:[root@centos76 ~]#cat fa.txt abcde[root@centos76 ~]#cat -b fa.txt #-b:非空行编号1a2b3c4d5e[root@centos76 ~]#nl fa.txt 1a2b3c4d5e[root@centos76 ~]#rev命令
(将同一行的内容逆向显示)
案例:revfile[root@centos76 ~]#cat fa.txt 12345abc[root@centos76 ~]#tac fa.txt abc12345[root@centos76 ~]#rev fa.txt 54321cba案例:接受标准输入[root@centos76 ~]#revabcdeffedcba^C案例:接收从管道过来的消息[root@centos76 ~]#echo {1..10}|rev01987654321[root@centos76 ~]#
more命令
cat命令的主要缺陷是:一旦运行,你就无法控制后面的操作。为了解决这个问题,开发人员编写了more命令。more命令会显示文本文件的内容,但会在显示每页数据之后停下来。
more命令是分页工具。在本章前面的内容里,当使用man命令时,分页工具会显示所选的bash手册页面。和在手册页中前后移动一样,你可以通过按空格键或回车键以翻页或逐行向前的方式浏览文本文件。浏览完之后,按q键退出。
more命令只支持文本文件中的基本移动。如果要更多高级功能,可以试试less命令。
more命令可以实现分页查看文件,可以配合管道实现输出信息的分页。
more有个缺点就是:翻页到末尾后,就会马上退出去了,而less不会,因此less命令用的会多些。
格式:
more[OPTIONS...] FILE...选项:
-d:显示翻页及退出提示
查看时有用的命令包括:
操作功能说明空白键(space): 代表向下翻一页b键代表向上翻一页Enter:代表向下翻「一行』q:代表立刻离开more,不再显示该文件内容Ctr1+F:向下滚动一屏Ctr1+B:返回上一屏=输出当前行的行号:f输出文件名和当前行的行号/文本#搜索文本n/N#跳到下一个或上一个匹配less命令(比较常用)
less 命令是man命令使用的分页器。
从名字上看,它并不像more命令那样高级。但是,less命令的命名实际上是个文字游戏(从俗语**“less is more”**得来),它实为more命令的升级版。它提供了一些极为实用的特性,能够实现在文本文件中前后翻动,而且还有一些高级搜索功能。
less命令的操作和more命令基本一样,一次显示一屏的文件文本。除了支持和more命令相同的命令集,它还包括更多的选项。其中一组特性就是less命令能够识别上下键以及上下翻页键(假设你的终端配置正确)。在查看文件内容时,这给了你全面的控制权。
基本语法:
less要查看的文件。选项:
-e:文件内容显示完毕后,自动退出;
-f:强制显示文件;
-g:不加亮显示搜索到的所有关键词,仅显示当前显示的关键字,以提高显示速度;
-l:搜索时忽略大小写的差异;
-N:每一行行首显示行号;
-s:将连续多个空行压缩成一行显示;
-S:在单行显示较长的内容,而不换行显示;
-x<数字>:将TAB字符显示为指定个数的空格字符。
快捷键:
(1)/name在日志中匹配name的下一个,?name在日志中匹配name的上一个(2)n查看下一个N查看上一个(3)ctrl+f或者f下一页ctrl+b或者b上一页(4)ctrl+d或者d下半页ctrl+u或者u上半页(5)j下一行k上一行这里上下键也可以(6)g第一行开始位置G最后一行(末尾)(7)q退出(8)h帮助案例:less同时查看2个文件
lessinfo.logerror.log查看info.log的文件和error.log的文件,这是查看两个文件(1)lessinfo.log#或者在打开一个文件的情况下,可以通过 :e error.log 打开error.log 第二个文件(2):n浏览下一个文件:p浏览上一个文件1
head命令
查看文档首行
head命令以行为单位,取文件的内容,后面不接参数时默认打印前10行。
它会将指定的内容输出到控制台上;
head也可以支持管道,用于显示管道符前的命令;
格式:
head[OPTION]... [FILE]...选项:
-c # 指定获取前#字节
-n # 指定获取前#行
-# 同上-->与上面那个等价
-v 总是显示文件名的头信息
-q 不显示文件名的头信息
案例:head -n3 /etc/passwd ==head -n /etc/passwd ==head -3 /etc/passwd (3种写法都行)
[root@test ~]# head -n3 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin等价于[root@test ~]# head -n3 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinYouhavenewmailin/var/spool/mail/root[root@test ~]# 等价于[root@test ~]# head -3 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin案例:注意,head -n -8 file 这里的数字如果是负数的话,表示什么含义?
如果指定的行数为负数的话,则表示head将打印出从文件开始一直到倒数指定行之前的内容:
[root@test ~]# seq 1 1012345678910[root@test ~]# seq 1 10|head-n-8#如果指定的行数为负数的话,则表示head将打印出从文件开始一直到倒数指定行之前的内容12[root@test ~]#案例:head命令可以接受标准输入和管道
[root@test ~]# head -2aabb[root@test ~]#[root@test ~]# head -2 </etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologin[root@test ~]# head -2 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologin[root@test ~]# cat /etc/passwd|head-2root:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologin[root@test ~]#案例:head命令列出某个目录下最大的几个文件
[root@test ~]# ls -lSh /etc/*|head-5-rw-r--r--.1rootroot655KJun72013/etc/services-rw-r--r--.1rootroot23KOct1109:17/etc/ld.so.cache-rw-r--r--.1rootroot12KOct1100:16/etc/aliases.db-rw-r--r--.1rootroot7.2KOct1100:10/etc/kdump.conf-rw-r--r--.1rootroot6.4KOct312018/etc/protocols[root@test ~]#案例:head -v file用法 #显示文件名信息
[root@test ~]# head -q fa.txt #-q 不显示文件名的头信息hhii[root@test ~]# head -v fa.txt #-v 总是显示文件名的头信息==>fa.txt<==hhii[root@test ~]#案例:head -c5 file #显示前5个字节
-c# 指定获取前#字节[root@test ~]# cat fa.txt 1314zxlloveyou[root@test ~]# head -c5 fa.txt 1314z[root@test~]#案例:和-n选项类似,-c选项也指出负数
[root@test ~]# echo abcdef|head-c-3abcd[root@test~]#tail命令
(显示文件最后几行的内容)
tail命令会显示文件最后几行的内容(文件的“尾部”)。默认情况下,它会显示文件的末尾10行。
格式:
tail[OPTION]... [FILE]...选项:
-c # 指定获取后#字节
-n # 指定获取后#行
-# 同上
-f参数是tail命令的一个突出特性。它允许你在其他进程使用该文件时查看文件的内容。tail命令会保持活动状态,并不断显示添加到文件中的内容。这是实时监测系统日志的绝妙方式。
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新建同名文件,将无法继续跟踪文件;
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件;
tailf 类似 tail –f,当文件不增长时并不访问文件;案例:实时监测系统日志
测试-f与-F的区别(常用命令)
-f参数是tail命令的一个突出特性。它允许你在其他进程使用该文件时查看文件的内容。tail命令会保持活动状态,并不断显示添加到文件中的内容。这是实时监测系统日志的绝妙方式。
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新建同名文件,将无法继续跟踪文件;
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件;
tailf 类似 tail –f,当文件不增长时并不访问文件,只不过当查看的文件不可访问时,次命令退出,而不像tail -F命令不退出。
tail-fn0/var/log/messages#推荐或者tail-Fn0/var/log/messages-n0代表只看最新行数据。
测试过程:
tail -f /var/log/messages测试
#在一个终端下用tai -f /var/log/message来检测日志文件:[root@test ~]# tail -f /var/log/messagesFeb218:35:56testroot:thisisatestlogFeb218:40:01testsystemd:StartedSession14ofuserroot.Feb218:50:01testsystemd:StartedSession15ofuserroot.Feb219:00:01testsystemd:StartedSession16ofuserroot.Feb219:01:01testsystemd:StartedSession17ofuserroot.Feb219:10:01testsystemd:StartedSession18ofuserroot.Feb219:20:01testsystemd:StartedSession19ofuserroot.Feb219:30:01testsystemd:StartedSession20ofuserroot.Feb219:40:01testsystemd:StartedSession21ofuserroot.Feb219:50:01testsystemd:StartedSession22ofuserroot.#之类默认会显示log文件后10行的内容,因此我们可以用如下命令来看最新发生的日志[root@test ~]# tail -0f /var/log/messages[root@test ~]# tail -fn0 /var/log/messages#如果要想截止这个进程的话,就用ctrl c就可以了#此时我们用tail -fn0 /var/log/messages来监控日志文件:[root@test ~]# tail -fn0 /var/log/messages#这里我们再打开另一个终端,用logger命令往日志文件里追加日志:[root@test ~]# logger "this is a test log"[root@test ~]# #再返回到原来监控日志文件的终端查看改变情况:[root@test ~]# tail -fn0 /var/log/messagesFeb219:58:53testroot:thisisatestlog#此时如何查看该log文件的描述符呢?#注意:默认tail -f file tail命令跟踪的是文件描述符,linux会对每一个打开的文件分配一个文件描述符的;[root@test ~]# ps -ef|head-1;ps-ef|greptailUIDPIDPPIDCSTIMETTYTIMECMDroot96752747019:57pts/000:00:00tail-fn0/var/log/messagesroot96939470020:00pts/100:00:00grep--color=autotail[root@test ~]# ll /proc/9675/fd/*lrwx------1rootroot64Feb220:01/proc/9675/fd/0->/dev/pts/0lrwx------1rootroot64Feb220:01/proc/9675/fd/1->/dev/pts/0lrwx------1rootroot64Feb220:00/proc/9675/fd/2->/dev/pts/0lr-x------1rootroot64Feb220:01/proc/9675/fd/3->/var/log/messageslr-x------1rootroot64Feb220:01/proc/9675/fd/4->anon_inode:inotify[root@test ~]#tail -f /root/fa.txt测试
#用tail -f命令监控一个文件[root@test ~]# touch fa.txt[root@test ~]# tail -fn0 fa.txt#利用echo命令往该测试文件追加内容,再返回原终端查看改变情况:[root@test ~]# echo aa >>fa.txt [root@test ~]# echo bb >>fa.txt [root@test ~]# [root@test ~]# tail -fn0 fa.txtaabb#此时查看该tail进程的文件描述符:root97179470020:05pts/100:00:00tail-fn0fa.txt[root@test ~]# ll /proc/9717/fd/*lrwx------1rootroot64Feb220:10/proc/9717/fd/0->/dev/pts/1lrwx------1rootroot64Feb220:10/proc/9717/fd/1->/dev/pts/1lrwx------1rootroot64Feb220:07/proc/9717/fd/2->/dev/pts/1lr-x------1rootroot64Feb220:10/proc/9717/fd/3->/root/fa.txtlr-x------1rootroot64Feb220:10/proc/9717/fd/4->anon_inode:inotify[root@test ~]# #此时再删除这个文件,再追加内容,并观看tail -f是否会有输出,并查看其文件描述符[root@test ~]# rm -rf fa.txt [root@test ~]# echo cc >>fa.txt [root@test ~]# echo dd >>fa.txt [root@test ~]# [root@test ~]# tail -fn0 fa.txt #源被监控文件删除后,这里没有提示log,恢复文件后,继续追加,依然没有log提示aabb#再次查看其文件描述符:[root@test ~]# ll /proc/9717/fd/*lrwx------1rootroot64Feb220:10/proc/9717/fd/0->/dev/pts/1lrwx------1rootroot64Feb220:10/proc/9717/fd/1->/dev/pts/1lrwx------1rootroot64Feb220:07/proc/9717/fd/2->/dev/pts/1lr-x------1rootroot64Feb220:10/proc/9717/fd/3->/root/fa.txt(deleted) #可以看到这里显示为deleted状态了lr-x------1rootroot64Feb220:10/proc/9717/fd/4->anon_inode:inotify[root@test ~]# 按上述测试过程使用tail-Fn0fa.txt来测试:[root@test ~]# tail -Fn0 fa.txt #-F 跟踪文件名,**相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件;**eefftail:‘fa.txt’hasbecomeinaccessible:Nosuchfileordirectorytail:‘fa.txt’hasappeared;followingendofnewfilehhii案例:注意,tailf 类似 tail –f,当文件不增长时并不访问文件,只不过当查看的文件不可访问时,次命令退出,而不像tail命令不退出。
#在一个终端下用ping命令重定向到一个文件[root@test ~]# ping 127.0.0.1 >ping.log#在另一个终端下用tailf命令跟踪文件[root@test ~]# tailf ping.log 64bytesfrom127.0.0.1:icmp_seq=17ttl=64time=0.051ms64bytesfrom127.0.0.1:icmp_seq=26ttl=64time=0.048ms64bytesfrom127.0.0.1:icmp_seq=27ttl=64time=0.051ms64bytesfrom127.0.0.1:icmp_seq=28ttl=64time=0.064ms#在另一个终端下删除这个ping.log文件,tailf命令就会直接退出的:[root@test ~]# rm -rf ping.log [root@test ~]# tailf ping.log 64bytesfrom127.0.0.1:icmp_seq=17ttl=64time=0.051ms64bytesfrom127.0.0.1:icmp_seq=18ttl=64time=0.059ms64bytesfrom127.0.0.1:icmp_seq=19ttl=64time=0.062ms64bytesfrom127.0.0.1:icmp_seq=20ttl=64time=0.058ms64bytesfrom127.0.0.1:icmp_seq=21ttl=64time=0.058ms64bytesfrom127.0.0.1:icmp_seq=27ttl=64time=0.051ms64bytesfrom127.0.0.1:icmp_seq=28ttl=64time=0.064ms64bytesfrom127.0.0.1:icmp_seq=29ttl=64time=0.058ms64bytesfrom127.0.0.1:icmp_seq=30ttl=64time=0.062mstailf:cannotopenping.log:Nosuchfileordirectory[root@test ~]#案例: tail -n +K表示的含义 表示从第K行开始输出
-n,--lines=KoutputthelastKlines,insteadofthelast10;oruse-n+KtooutputstartingwiththeKthseq 1 10|tail -n +3当行数前使用+号时,表示除了前多少行内容不输出,后面的内容全部输出
[root@test ~]# seq 1 10|tail-n38910[root@test ~]# seq 1 10|tail-n+3345678910[root@test ~]#案例:linux命令显示ip地址
[root@test ~]# ifconfig eth0:flags=4163<UP,BROADCAST,RUNNING,MULTICAST>mtu1500inet192.168.10.130netmask255.255.255.0broadcast192.168.10.255inet6fe80::20c:29ff:fefb:40b5prefixlen64scopeid0x20<link>ether00:0c:29:fb:40:b5txqueuelen1000(Ethernet)RXpackets24409bytes2292091(2.1 MiB)RXerrors0dropped0overruns0frame0TXpackets17164bytes10038264(9.5 MiB)TXerrors0dropped0overruns0carrier0collisions0lo:flags=73<UP,LOOPBACK,RUNNING>mtu65536inet127.0.0.1netmask255.0.0.0inet6::1prefixlen128scopeid0x10<host>looptxqueuelen1000(Local Loopback)RXpackets22bytes1166(1.1 KiB)RXerrors0dropped0overruns0frame0TXpackets22bytes1166(1.1 KiB)TXerrors0dropped0overruns0carrier0collisions0Youhavenewmailin/var/spool/mail/root[root@test ~]# ifconfig |head-2|tail-1inet192.168.10.130netmask255.255.255.0broadcast192.168.10.255[root@test ~]#案例:取指定行命令
[root@test ~]# head -n2 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologinYouhavenewmailin/var/spool/mail/root[root@test ~]# head -n2 /etc/passwd|tail-n1bin:x:1:1:bin:/bin:/sbin/nologin[root@test ~]#paste命令(合并多个文件)
paste 合并多个文件同行号的列到一行。
格式:
paste[OPTION]... [FILE]...选项:
-d 分隔符:指定分隔符,默认用TAB
-s :所有行合成一行显示
范例
[root@test ~]# cat alpha.txt abcdefgh[root@test ~]# cat seq.txt 12345[root@test ~]# [root@test ~]# cat alpha.txt seq.txt abcdefgh12345[root@test ~]# [root@test ~]# paste alpha.txt seq.txt a1b2c3d4e5fgh[root@test ~]# [root@test ~]# paste -d:alpha.txt seq.txt a:1b:2c:3d:4e:5f:g:h:[root@test ~]# [root@test ~]# paste -s alpha.txt abcdefgh[root@test ~]# paste -s seq.txt 12345[root@test ~]#wc命令(收集文本统计数据)
wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数。
可以对文件或STDIN中的数据统计。
常用选项:
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
案例:统计行数:-l
- 案例:统计一个文件内文本行数
[root@hg-linux-test ~]# cat test.txt 123[root@hg-linux-test ~]# cat test.txt |wc-l3- 案例:统计某个目录下文件个数
[root@hg-linux-test ~]# ls test1.txt2.txttest[root@hg-linux-test ~]# ls test|wc-l3uniq命令(去重)
diff命令和patch命令(比较文件)
tr命令(转换或删除字符的工具)
🔰 介绍
tr命令是 Linux 系统中用于转换或删除字符的实用工具。其名称代表 "translate"。tr命令可用于从一个字符集映射到另一个字符集,或者删除输入中的字符。
tr命令的功能相对简单,更复杂的文本处理通常会使用sed、awk等工具。
🔰 语法
tr[OPTION] SET1 [SET2]OPTION:可选参数,用于指定一些选项。SET1:指定要被替换的字符集。SET2:指定替换为的字符集。
选项
-d:删除指定字符集中的字符。-s:压缩字符集,将重复的字符替换为一个字符。-c:取补集,替换未在 SET1 中出现的字符。
案例:将文本中的小写字母转换为大写字母
[root@I ~]# echo "hello"|tr'a-z''A-Z'HELLO案例:删除文本中的数字 -d
[root@I ~]# echo "abc123"|tr-d'0-9'abc[root@I ~]#案例:将空格替换为制表符
[root@I ~]# echo "This is a sentence."|tr'''\t'Thisisasentence.[root@I ~]#案例:删除重复的字符 -s
[root@I ~]# echo "mississiiippi"|tr-s'i'mississippi[root@I ~]# echo "i love you,xyy i miss you"|tr-s''iloveyou,xyyimissyou案例:将换行符替换为逗号
[root@I ~]# echo -e "one\ntwo\nthree"|tr'\n'','one,two,three,[root@I~]#案例:-c选项 取补集
案例:Linux如何取出分区利用率
-d删除字体
-c取补集
\n 换行符
[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718472475323484%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |tr-s''|cut-d''-f5|tr-dc"[0-9\n]"00204150cut命令(按列抽取文本)
cut 命令可以提取文本文件或STDIN数据的指定列。
格式:
cut[OPTION]... [FILE]...选项:
-d DELIMITER:指明分隔符,默认tab 注意:这里可以写成-d:或者 -d":"-d':'都行。
-f FILEDS:按字段切割
#:第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段,例如:1-6
混合使用:1-3,7
-b:按字节切割; #-b,--bytes=LIST select only these bytes #bytes字节
-c :按字符切割 #-c,--characters=LIST select only these characters #characters 字符
--output-delimiter=STRING指定输出分隔符
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;(取补集)
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
1、范例:标准cut命令测试
[root@test ~]# cut -d:-f1,3-4,7 /etc/passwd#测试过程:[root@test ~]# cut -d:-f1,3-4,7 /etc/passwdroot:0:0:/bin/bashbin:1:1:/sbin/nologindaemon:2:2:/sbin/nologinadm:3:4:/sbin/nologinlp:4:7:/sbin/nologinsync:5:0:/bin/syncshutdown:6:0:/sbin/shutdownhalt:7:0:/sbin/haltmail:8:12:/sbin/nologinoperator:11:0:/sbin/nologingames:12:100:/sbin/nologinftp:14:50:/sbin/nologinnobody:99:99:/sbin/nologinsystemd-network:192:192:/sbin/nologindbus:81:81:/sbin/nologinpolkitd:999:998:/sbin/nologintss:59:59:/sbin/nologinsshd:74:74:/sbin/nologinpostfix:89:89:/sbin/nologinZXL:1000:1000:/bin/bashHG:1001:1001:/bin/bash[root@test ~]#2、范例:如何取出特定网卡ip?
考虑,这个命令是否是通用的?对于不同版本。
1、shell命令
ifconfigens33|head-2|tail-1|tr-s''|cut-d''-f3#注意,此命令在7/8版本中适用,但6版本里不使适用!#测试过程:[root@test ~]# ifconfig ens33ens33:flags=4163<UP,BROADCAST,RUNNING,MULTICAST>mtu1500inet192.168.10.2netmask255.255.255.0broadcast192.168.10.255inet6fe80::9b0d:30fd:adbe:27cfprefixlen64scopeid0x20<link>ether00:0c:29:81:fb:ebtxqueuelen1000(Ethernet)RXpackets15937bytes18067044(17.2 MiB)RXerrors0dropped0overruns0frame0TXpackets5014bytes555652(542.6 KiB)TXerrors0dropped0overruns0carrier0collisions0[root@test ~]# ifconfig ens33|head-2|tail-1inet192.168.10.2netmask255.255.255.0broadcast192.168.10.255[root@test ~]# ifconfig ens33|head-2|tail-1|tr-s''inet192.168.10.2netmask255.255.255.0broadcast192.168.10.255[root@test ~]# ifconfig ens33|head-2|tail-1|tr-s''|cut-d''-f3#最终命令192.168.10.2[root@test ~]#2、hostname -I命令
[root@test ~]# hostname -I #此命令虽然适用于各个版本,但是最大的缺点就是会列出all网卡的ip,但不会显示是具体哪一个网卡的ip192.168.10.2-I,--all-ip-addressesalladdressesforthehost3、范例:Linux如何取出分区利用率?
推荐如下2种方法:
[root@test ~]# df|tr-s''%|cut-d%-f5#方法1:Use00204150[root@test ~]#或者[root@test ~]# df |tr-s''%|cut-d%-f5|tr-d'[:alpha:]'#[:alpha:] 代表所有字母 #方法2:00204150[root@test ~]#(1)按字符数:(这种方法不太友好)
df|cut-c53-55#测试过程:Filesystem1K-blocksUsedAvailableUse[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718460475323604%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |cut-c53-55Use00204150[root@test ~]#(2)这种方法也不是很友好:。。。。
[root@test ~]# df |tr-s''|cut-d''-f5|tr-d%#测试过程:[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718460475323604%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |tr-s''Filesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718460475323604%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |tr-s''|cut-d''-f5Use%0%0%2%0%4%15%0%[root@test ~]# df |tr-s''|cut-d''-f5|tr-d%Use00204150[root@test ~]#(3)再次改进:这个方法还可以。
[root@test ~]# df|tr-s''%|cut-d%-f5下面这种shell还可以:
[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718460475323604%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df|tr-s''%Filesystem%1K-blocks%Used%Available%Use%Mounted%ondevtmpfs%919540%0%919540%0%/devtmpfs%931552%0%931552%0%/dev/shmtmpfs%931552%9816%921736%2%/runtmpfs%931552%0%931552%0%/sys/fs/cgroup/dev/mapper/centos-root%49250820%1718460%47532360%4%//dev/sda1%1038336%152564%885772%15%/boottmpfs%186312%0%186312%0%/run/user/0[root@test ~]# df|tr-s''%|cut-d%-f5Use00204150[root@test ~]#或者:
tr -dc "[0-9\n]"用法:
[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718472475323484%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |tr-s''|cut-d''-f5|tr-dc"[0-9\n]"00204150tr -d '[:alpha:]'用法:
[root@test ~]# dfFilesystem1K-blocksUsedAvailableUse%Mountedondevtmpfs91954009195400%/devtmpfs93155209315520%/dev/shmtmpfs93155298169217362%/runtmpfs93155209315520%/sys/fs/cgroup/dev/mapper/centos-root492508201718472475323484%//dev/sda1103833615256488577215%/boottmpfs18631201863120%/run/user/0[root@test ~]# df |tr-s''%|cut-d%-f5|tr-d'[:alpha:]'#[:alpha:] 代表所有字母 00204150[root@test ~]#4、范例:--output-delimiter选项 指定输出分隔符
[root@test ~]# cut -d:-f1,3,7 --output-delimiter="---"/etc/passwdroot---0---/bin/bashbin---1---/sbin/nologindaemon---2---/sbin/nologinadm---3---/sbin/nologinlp---4---/sbin/nologin5、例子:指定字段的字符或者字节范围**(-b 和 -c的区别)
cut命令可以将一串字符作为列来显示,字符字段的记法:
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
-M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
上面是记法,结合下面选项将某个范围的字节、字符指定为字段:
-b 表示字节;
-c 表示字符;
-f 表示定义字段。
-b和-c选线测试过程:
[root@test ~]# cat test.txt abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz(1)打印第1个到第3个字符[root@test ~]# cut -c1-3 test.txt abcabcabcabcabc(2)打印前2个字符[root@test ~]# cut -c-2 test.txt ababababab(3)打印从第5个字符开始到结尾[root@test ~]# cut -c5- test.txt efghijklmnopqrstuvwxyzefghijklmnopqrstuvwxyzefghijklmnopqrstuvwxyzefghijklmnopqrstuvwxyzefghijklmnopqrstuvwxyz[root@test ~]#从以下实验可以知道:一般是用c选项的,代表字符;也可以用b选项,代表字节
#测试过程:[root@test ~]# cat fa.txt 中国美丽美国呵呵[root@test ~]# cut -c1-2 fa.txt 中国美国[root@test ~]# cut -b1-2 fa.txt [root@test ~]# cut -c1-3 test.txt abcabcabcabcabc[root@test ~]# cut -b1-3 test.txt abcabcabcabcabc[root@test ~]# #注意:一个汉字起码2个字节以上,而一个字母就是一个字节。[root@test ~]# echo a >a.txt[root@test ~]# ll a.txt -rw-r--r--.1rootroot2Feb510:03a.txt[root@test ~]# hexdump -C a.txt 00000000610a|a.|00000002[root@test ~]# echo 我 >b.txt[root@test ~]# ll b.txt -rw-r--r--.1rootroot4Feb510:05b.txt[root@test ~]# hexdump -C b.txt 00000000e688910a|....|000000046、范例:--complement:补足被选择的字节、字符或字段
[root@test ~]# head -3 /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin[root@test ~]# cut -d:-f1 --complement /etc/passwd #--complement:补足被选择的字节、字符或字段x:0:0:root:/root:/bin/bashx:1:1:bin:/bin:/sbin/nologinx:2:2:daemon:/sbin:/sbin/nologin[root@test ~]#7、范例:-b选项的使用 取出磁盘分区uuid
[root@test ~]# blkid /dev/sdl1/dev/sdl1:UUID="b4484a71-144b-4426-86be-48f05a401b58"TYPE="xfs"[root@test ~]# blkid /dev/sdl1|cut-b11-54#-b选项的使用UUID="b4484a71-144b-4426-86be-48f05a401b58"[root@test ~]# blkid /dev/sdl1|cut-c11-54UUID="b4484a71-144b-4426-86be-48f05a401b58"[root@test ~]# echo 'UUID="b4484a71-144b-4426-86be-48f05a401b58"/data11 xfs defaults 0 0 '>>/etc/fstab[root@test ~]# mount -a[root@test ~]# df -hT /data11/FilesystemTypeSizeUsedAvailUse%Mountedon/dev/sdl1xfs2.0G33M2.0G2%/data11[root@test ~]#8、范例:如何从日志文件中取出ip?
以下为王老师博客服务器ngnix:

通过百度查找自己的ip:
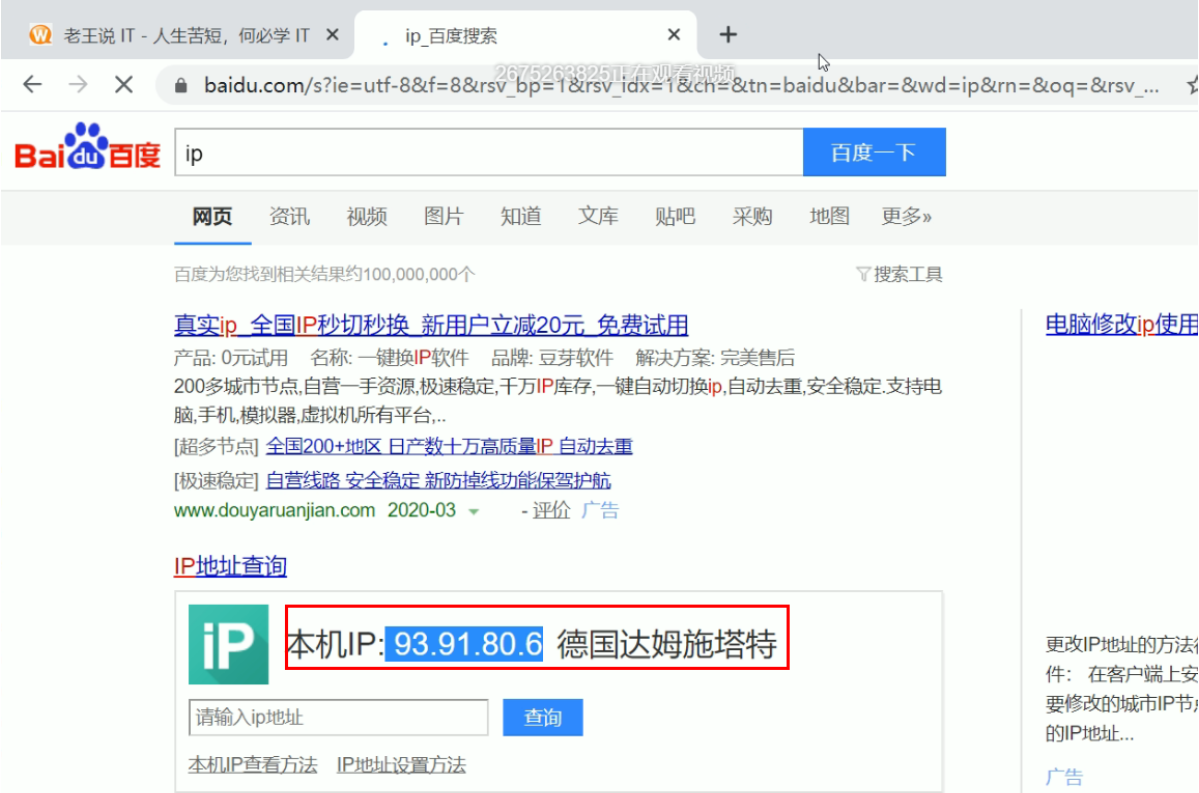
从nginx的审计日志可以看到我们访问博客的ip信息:

进而通过cut命令取出ip信息:

查看非文本文件(也就是二进制文件)内容
1、hexdump命令(比较常用)
选项:
-Ccanonicalhex+ASCIIdisplay#规范的十六进制+ ASCII显示-nlengthinterpretonlylengthbytesofinput#-n length仅解释输入的长度字节**案例:**hexdump -C -n 512 /dev/vda
-Ccanonicalhex+ASCIIdisplay#规范的十六进制+ ASCII显示-nlengthinterpretonlylengthbytesofinput#-n length仅解释输入的长度字节[root@centos76 ~]#hexdump -C -n 512 /dev/vda00000000eb6390108ed0bc00b0b800008ed88ec0|.c..............|00000010fbbe007cbf0006b90002f3a4ea210600|...|.........!..|0000002000bebe073804750b83c61081fefe0775|....8.u........u|00000030f3eb16b402b001bb007cb2808a74018b|.........|...t..|000000404c02cd13ea007c0000ebfe0000000000|L.....|.........|0000005000000000000000000000008001000000|................|0000006000000000fffa9090f6c2807405f6c270|...........t...p|000000707402b280ea797c000031c08ed88ed0bc|t....y|..1......|案例:echo {a..z}|tr -d ''|hexdump -C
[root@centos76 ~]#echo {a..z}abcdefghijklmnopqrstuvwxyz[root@centos76 ~]#echo {a..z}|tr-d''abcdefghijklmnopqrstuvwxyz[root@centos76 ~]#echo {a..z}|tr-d''|hexdump000000062616463666568676a696c6b6e6d706f000001072717473767578777a79000a000001b[root@centos76 ~]#[root@centos76 ~]#echo {a..z}|tr-d''|hexdump-C#000000006162636465666768696a6b6c6d6e6f70|abcdefghijklmnop|000000107172737475767778797a0a|qrstuvwxyz.|0000001b**案例:**hexdump -C fb.txt #查看文件格式
通过命令hexdump-Cfb.txt查看:Linux中换行默认包含了回车,但winodws中回车和换行必须都存在;[root@centos76 ~]#hexdump -C fb.txt #Linux格式00000000610a620a630a|a.b.c.|00000006[root@centos76 ~]#hexdump -C fb.txt #winodws格式00000000610d0a620d0a630d0a|a..b..c..|000000092、od命令(用的较少)
od 即 dump filesin octal and other formats。
od即以八进制和其他格式转储文件。
案例:
[root@test ~]# echo {a..z}abcdefghijklmnopqrstuvwxyz[root@test ~]# echo {a..z}|tr-d''abcdefghijklmnopqrstuvwxyz[root@test ~]# echo {a..z}|tr-d''|od-tx000000064636261686766656c6b6a69706f6e6d00000207473727178777675000a7a790000033[root@test ~]# echo {a..z}|tr-d''|od-tx100000006162636465666768696a6b6c6d6e6f7000000207172737475767778797a0a0000033[root@test ~]# echo {a..z}|tr-d''|od-tx1z00000006162636465666768696a6b6c6d6e6f70>abcdefghijklmnop<00000207172737475767778797a0a>qrstuvwxyz.<0000033[root@test ~]#3、xxd命令
案例:
[root@test ~]# echo {a..z}|tr-d''|xxd0000000:6162636465666768696a6b6c6d6e6f70abcdefghijklmnop0000010:7172737475767778797a0aqrstuvwxyz.[root@test ~]#如何利用linux命令往一个文本里首行插入某条文本呢?(已解决)
如何利用linux命令往一个文本里首行插入某条文本呢?能实现吗?
是的,Linux 中可以使用多种方式将文本插入到文件的首行。以下是一些常见的方法:
1. 使用 sed命令(荐)
sed-i'1i\Your Text to Insert'filename这会在 filename文件的第一行之前插入指定的文本。请注意,-i选项表示直接在文件中编辑,如果你不希望修改原始文件,可以省略 -i选项,然后将输出重定向到一个新文件。
- 自己测试(测试成功)
[root@hg-linux-test ~]# cat test.txt 123[root@hg-linux-test ~]# sed -i '1i\Your Text to Insert'test.txt [root@hg-linux-test ~]# cat test.txt YourTexttoInsert123[root@hg-linux-test ~]#2. 使用 awk命令
awk-vtext="Your Text to Insert"'NR==1 {print text} {print}'filename>newfile这会在 filename文件的首行之前插入指定的文本,并将结果写入 newfile文件。
- 自己测试(测试成功)
##1、查看测试文本内容[root@hg-linux-test ~]# cat test.txt 123##2、awk命令替换awk-vtext="Your Text to Insert"'NR==1 {print text} {print}'test.txt>newfile##3、验证[root@hg-linux-test ~]# cat newfile YourTexttoInsert1233. 使用 echo和重定向
{echo'Your Text to Insert';catfilename;} >newfile这种方法使用了大括号 {}将两个命令组合在一起,echo用于插入文本,cat用于读取原始文件。最后将输出重定向到一个新文件。
- 自己测试(测试成功)
##1、查看原文件内容[root@hg-linux-test ~]# cat test.txt 123##2、执行命令{echo'Your Text to Insert';cattest.txt;} >newfile2##3、验证[root@hg-linux-test ~]# cat newfile2 YourTexttoInsert1234. 使用 ed命令
printf'0a\nYour Text to Insert\n.\nw\n'|ed-sfilename这使用了 ed编辑器,通过 printf命令生成编辑命令。0a表示在第一行之前插入文本,.表示结束插入,w表示保存文件。
请根据你的需求选择适合你情况的方法。
上述命令中,filename是目标文件的名称,Your Text to Insert是要插入的文本。在执行这些命令之前,请确保你有足够的权限来编辑文件。
这个用法有点生僻哦,不推荐!
- 自己测试(测试成功)
##1、查看原文件内容[root@hg-linux-test ~]# cat test.txt 123##2、执行命令printf'0a\nYour Text to Insert\n.\nw\n'|ed-stest.txt##3、验证[root@hg-linux-test ~]# cat test.txt YourTexttoInsert123tar命令Linux下的归档使用工具,用来打包和备份
虽然zip命令能够很好地将数据压缩和归档进单个文件,但它不是Unix和Linux中的标准归档工具。目前,Unix和Linux上最广泛使用的归档工具是tar命令。
tar命令 可以为linux的文件和目录创建档案。利用tar,可以为某一特定文件创建档案(备份文件),也可以在档案中改变文件,或者向档案中加入新的文件。tar最初被用来在磁带上创建档案,现在,用户可以在任何设备上创建档案。利用tar命令,可以把一大堆的文件和目录全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便于网络传输是非常有用的。tar指令是打包指令,最后打包后的文件是.tar.gz 的文件。如你所见,tar命令是给整个目录结构创建归档文件的简便方法。这是Linux中分发开源程序源码文件所采用的普遍方法。
首先要弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件。
为什么要区分这两个概念呢?这源于Linux中很多压缩程序只能针对一个文件进行压缩,这样当你想要压缩一大堆文件时,你得先将这一大堆文件先打成一个包(tar命令),然后再用压缩程序进行压缩(gzip bzip2命令)。
🚩 linux文件压缩工具
Linux包含了多种文件压缩工具。虽然听上去不错,但这实际上经常会在用户下载文件时造成混淆。表4-7列出了Linux上的文件压缩工具。表4-7 Linux文件压缩工具。

compress文件压缩工具已经很少在Linux系统上看到了。
语法
tar(选项) (参数)选项
1.-A或--catenate:新增文件到以存在的备份文件;2.-B:设置区块大小;3.-c或--create:建立新的备份文件;#常用4.-C<目录>:切换工作目录,先进入指定目录再执行压缩/解压缩操作,可用于仅压缩特定目录里的内容或解压缩到特定目录;#常用5.-d:记录文件的差别;6.-x或--extract或--get:从归档文件中提取文件,可以搭配-C(大写)在特定目录解开,#常用7.需要注意的是-c、-t、-x不可同时出现在一串命令中;8.-t或--list:列出备份文件的内容;#常用9.-z或--gzip或--ungzip:通过gzip指令压缩/解压缩文件,文件名最好为*.tar.gz;#常用15.-j:通过bzip2指令压缩/解压缩文件,文件名最好为*.tar.bz2;#常用10.-Z或--compress或--uncompress:通过compress指令处理备份文件;11.-f<备份文件>或--file=<备份文件>:指定备份文件;#常用,-f:使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。12.-v或--verbose:显示指令执行过程;#常用13.-r:添加文件到已经压缩的文件;14.-u:添加改变了和现有的文件到已经存在的压缩文件;16.-v:显示操作过程;17.-l:文件系统边界设置;18.-k:保留原有文件不覆盖;19.-m:保留文件不被覆盖;20.-w:确认压缩文件的正确性;21.-p或--same-permissions:保留原来的文件权限与属性;22.-P或--absolute-names:使用文件名的绝对路径,不移除文件名称前的“/”号;23.-N<日期格式>或--newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;24.--exclude=<范本样式>:排除符合范本样式的文件;25.--remove-files:归档/压缩之后删除源文件-O:将文件解开到标准输出参数
文件或目录:指定要打包的文件或目录列表。
常见案例
==🚩 打包/解包/查看包/往包里新增文件/更新包里的文件==
tar-cfall.tar*.jpg# 这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。tar-rfall.tar*.gif# 这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。tar-ufall.tarlogo.gif# 这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。tar-cfvarchive.tarfoobar# 从文件foo和bar创建archive.tar。tar-cvftest.tartest--remove-files#包文件之后删除源文件:##查询tar-tfall.tar#条命令是列出all.tar包中所有文件,-t是列出文件的意思或者tar-tvfarchive.tar# 详细列出archive.tar中的所有文件。tar-xfarchive.tar# 从archive.tar提取所有文件。==🚩 打包并压缩/解压/查看压缩包里内容==
(1)打包并压缩
tar-zcvflog.tar.gzlog2012.log#打包后,以 gzip 压缩tar-jcvflog.tar.bz2log2012.log#打包后,以 bzip2 压缩#在选项 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。 如果加 z 选项,则以.tar.gz或.tgz来代表gzip压缩过的tar包;如果加 j 选项,则以.tar.bz2来作为tar包名。案例:压缩多个文件,将/home/al.txt和/home/a2.txt压缩成a.tar.gz
tarzcvfa.tar.gza1.txta2.txt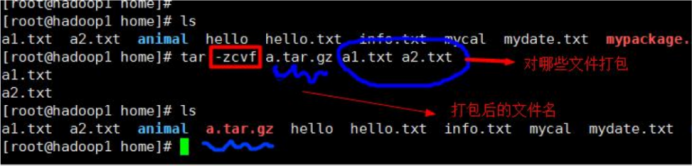
案例:将/home 的文件夹压缩成myhome.tar.gz

(2)解压目录
tar-zxvflog.tar.gz#在预设的情况下,我们可以将压缩档在任何地方解开的案例:-C参数 解压到指定目录
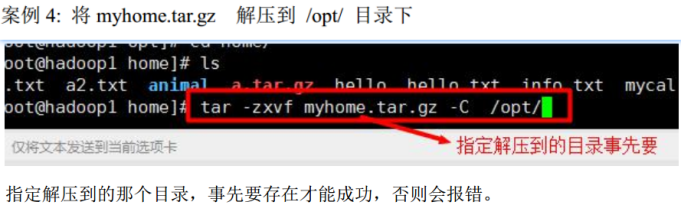
(3)查看压缩包里的内容
tar-ztvflog.tar.gz#由于我们使用 gzip 压缩的log.tar.gz,所以要查阅log.tar.gz包内的文件时,就得要加上 z 这个选项了。扩展
案例:文件备份下来,并且保存其权限 :
tar-zcvpflog31.tar.gzlog2014.loglog2015.loglog2016.log这个 -p 的属性是很重要的,尤其是当您要保留原本文件的属性时。
案例:只将tar内的部分文件解压出来 🤣
tar-zxvf/opt/soft/test/log30.tar.gzlog2013.log我可以透过 tar -ztvf 来查阅 tar 包内的文件名称,如果单只要一个文件,就可以透过这个方式来解压部分文件!
案例:在文件夹当中,比某个日期新的文件才备份 :
tar-N"2012/11/13"-zcvflog17.tar.gztest案例:备份文件夹内容是排除部分文件:
tar--excludescf/service-zcvfscf.tar.gzscf/*zip格式
如果你接触过Microsoft Windows,就必然用过zip文件。它如此流行,以至于微软从Windows XP开始,就已经将其集成进了自家的操作系统中。zip工具可以将大型文件(文本文件和可执行文件)压缩成占用更少空间的小文件。
压缩:zip-r[目标文件名].zip [原文件/目录名] #注:-r参数代表递归解压:unzip[原文件名].zip案例:将/home下的所有文件进行压缩成mypackage.zip
zip-rmypackage.zip/home/# 压缩命令案例:将mypackge.zip解压到/opt/tmp目录下
unzip-d/opt/tmp/mypackage.zip# 解压压缩文件到指定路径下tar格式(该格式仅仅打包,不压缩)
打包:tar-cvf[目标文件名].tar [原文件名/目录名]解包:tar-xvf[原文件名].tar注:c参数代表create(创建),x参数代表extract(解包),v参数代表verbose(详细信息),f参数代表filename(文件名),所以f后必须接文件名。tar.gz格式**(常用)**(.tgz)
方式一:利用前面已经打包好的tar文件,直接用压缩命令。压缩:gzip[原文件名].tar解压:gunzip[原文件名].tar.gz方式二:一次性打包并压缩、解压并解包#推荐打包并压缩:tar-zcvf[目标文件名].tar.gz [原文件名/目录名]解压并解包:tar-zxvf[原文件名].tar.gz#注:z代表用gzip算法来压缩/解压。🚩
gzip是Linux上最流行的压缩工具。gzip软件包是GNU项目的产物,意在编写一个能够替代原先Unix中compress工具的免费版本。这个软件包含有下面的工具:
gzip:用来压缩文件。
gzcat:用来查看压缩过的文本文件的内容。
gunzip:用来解压文件。
当我们使用gzip对文件进行压缩后,不会保留原来的文件。
案例:gzip压缩,将/home 下的 hello.txt 文件进行压缩
[root@linux home]# lsadminfoobarhello.txtjimmyrenetesttest2[root@linux home]# gzip hello.txt [root@linux home]# lsadminfoobarhello.txt.gzjimmyrenetesttest2[root@linux home]#案例:gunzip压缩,将/home下的hello.txt.gz文件进行解压缩
[root@linux home]# lsadminfoobarhello.txt.gzjimmyrenetesttest2[root@linux home]# gunzip hello.txt.gz [root@linux home]# lsadminfoobarhello.txtjimmyrenetesttest2[root@linux home]#🚩 注意:注意:gzip的压缩级别
gzip压缩级别:gziptest# 默认压缩级别3数字1~9越大压缩级别越高,文件越小,同时越消耗CPU,时间越长。gzip-9test# 极限压缩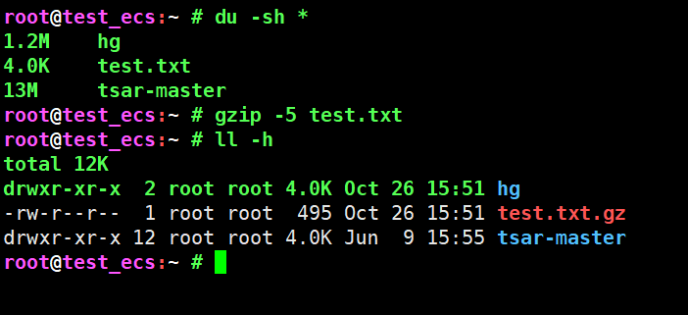
⚠️ 注意:
.tgz是什么格式的包?
.tgz文件格式是一个压缩文件的扩展名,通常用来表示经过 gzip压缩的 tar归档文件。tar是一种文件归档程序,可以将多个文件或文件夹合并成一个文件;而 gzip是一个广泛使用的文件压缩程序。当你看到一个以 .tgz结尾的文件时,它通常意味着这个文件首先被 tar归档然后用 gzip压缩。
在 Unix 和 Linux 系统中,.tgz是 .tar.gz的简写,两者都表示同样的文件格式。这种类型的文件很适合在网络上传输,或者保存磁盘空间,因为它们合并了多个文件并且将它们压缩成一个更小的单一文件。要解压这种文件,你可以使用 tar命令行工具,通常配合 -z参数来处理 gzip压缩。
例如,解压 .tgz文件的常用命令是:
tar-xzffile.tgz其中:
x代表提取文件。z代表用gzip进行解压。f代表接下来的是文件名。
在不同的操作系统上也有图形界面的工具可以用来打开 .tgz文件,比如在 Windows 上的 WinRAR 或者 7-Zip。
tar.bz2格式
方式一:利用已经打包好的tar文件,直接执行压缩命令:压缩:bzip2[原文件名].tar解压:bunzip2[原文件名].tar.bz2方式二:一次性打包并压缩、解压并解包打包并压缩:tar-jcvf[目标文件名].tar.bz2 [原文件名/目录名]解压并解包:tar-jxvf[原文件名].tar.bz2#注:小写j代表用bzip2算法来压缩/解压。tar.xz格式
方式一:利用已经打包好的tar文件,直接用压缩命令:压缩:xz[原文件名].tar解压:unxz[原文件名].tar.xz方式二:一次性打包并压缩、解压并解包打包并压缩:tar-Jcvf[目标文件名].tar.xz [原文件名/目录名]解压并解包:tar-Jxvf[原文件名].tar.xz#注:大写J代表用xz算法来压缩/解压。tar.Z格式(已过时)
方式一:利用已经打包好的tar文件,直接用压缩命令:压缩:compress[原文件名].tar解压:uncompress[原文件名].tar.Z方式二:一次性打包并压缩、解压并解包打包并压缩:tar-Zcvf[目标文件名].tar.Z [原文件名/目录名]解压并解包:tar-Zxvf[原文件名].tar.Z#注:大写Z代表用ncompress算法来压缩/解压。另,ncompress是早期Unix系统的压缩格式,但由于ncompress的压缩率太低,现已过时。jar格式
压缩:jar-cvf[目标文件名].jar [原文件名/目录名]解压:jar-xvf[原文件名].jar#注:如果是打包的是Java类库,并且该类库中存在主类,那么需要写一个META-INF/MANIFEST.MF配置文件,内容如下:Manifest-Version:1.0Created-By:1.6.0_27(Sun MicrosystemsInc.)Main-class:the_name_of_the_main_class_should_be_put_here然后用如下命令打包:jar-cvfm[目标文件名].jar META-INF/MANIFEST.MF [原文件名/目录名]这样以后就能用“java-jar[文件名].jar”命令直接运行主类中的public static void main方法了。7z格式
压缩:7za[目标文件名].7z [原文件名/目录名]解压:7zx[原文件名].7z#注:这个7z解压命令支持rar格式,即:7zx[原文件名].rarln命令
案例:给某个文件做软连接 -s -f -n选项
sudoln-sfn/usr/local/bin/python3.8/usr/bin/python这个是什么意思?sudo ln -sfn /usr/local/bin/python3.8 /usr/bin/python这条命令用于创建一个符号链接,使 /usr/bin/python指向 /usr/local/bin/python3.8。以下是每个参数的含义:
sudo:提权命令,意味着需要以超级用户权限执行该命令。ln:创建链接命令。-s:创建符号链接(软链接),而不是硬链接。-f:强制删除已经存在的目标文件(如果/usr/bin/python已经存在,会被删除)。-n:如果目标是一个符号链接,直接覆盖它,而不是在其上创建新的链接。/usr/local/bin/python3.8:链接的源文件,即要指向的实际文件路径。/usr/bin/python:链接的目标文件,即符号链接的路径。
这个命令的最终效果是使系统在执行 python命令时,实际上运行的是 python3.8。
警告
**这种做法在需要特定版本的 Python 并且不想直接更改系统默认 python 版本的情况下非常有用。**然而,需注意以下几点:
- 系统依赖:许多系统工具和脚本依赖于特定版本的 Python(经常是 Python 2.x),将
/usr/bin/python修改为指向 Python 3.x 可能会导致这些工具和脚本无法正常工作。(例如yum) - 环境管理:使用
pyenv或者虚拟环境(virtualenv,venv)工具来管理不同版本的 Python 和依赖项通常是更安全和优雅的方法。
如果你确定没有上述问题,或者你已经做好了相应的准备和测试,那么可以使用这条命令来更改默认的 python 版本。
sort命令
选项含义
sort -rnk +4:
- 按照第四列(通常是内存使用率)以数值方式逆序排列进程。
-r:逆序。-n:按数值排序。-k +4:指定以第四列为排序依据。
案例
psaux|head-1;psaux|grep-vUSER|sort-rnk+4|head-10#这个命令组合用来查看系统中内存使用率最高的10个进程,帮助管理员识别资源消耗较大的进程。psaux|head-1;psaux|grep-vUSER|sort-rnk+3|head-10#这个命令组合用来查看系统中CPU使用率最高的10个进程,帮助管理员识别资源消耗较大的进程。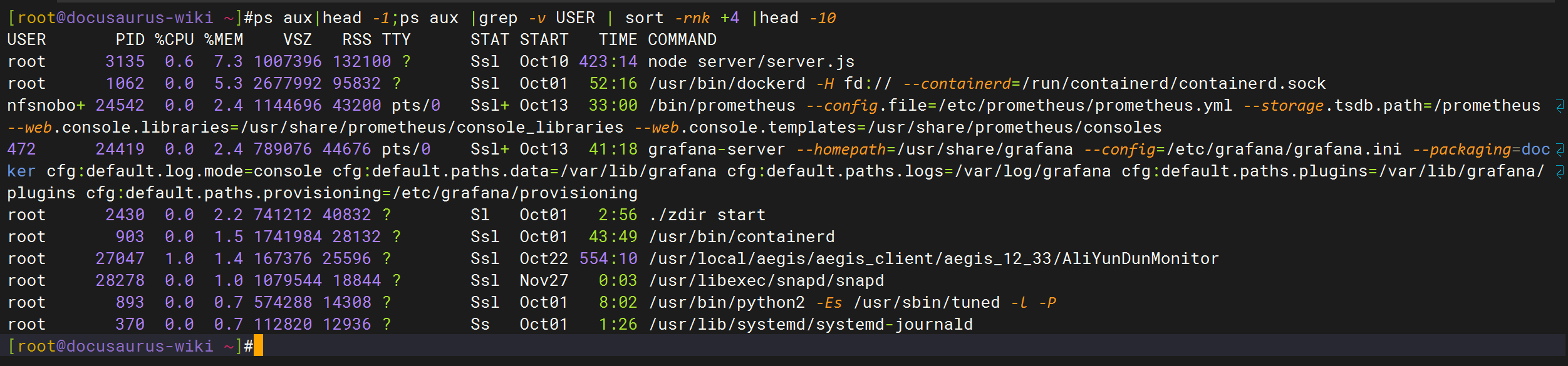
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码 x2675263825 (舍得), qq:2675263825。

🍀 微信公众号 《云原生架构师实战》

🍀 个人博客站点
上次更新时间: