00:00:00
teek配置rewrite模式
Teek配置rewrite模式
目录
[toc]
前言
那么,为什么要切换到rewrite呢?
- 左下角会有中文路径提示
- url打开会有中文提示
注意
使用原则
- 必须保证 一级目录下的 所有md都得有同一个一级前缀,例如 /一级前缀/随机uid
- 一级前缀决定了是否都在同一个侧边栏显示
- 你一级目录下,都是其子目录,默认都弄成同一个一级前缀就好了呗。如果不想让他出现在侧边栏,那就单独指定一个一级目录。
- 所以,一级前缀 就统一整成 /技术/xxx /专题/xxx /生活/xxx /兴趣/xxx /关于/xxx (这里的中文可以替换为对应的英文)

环境
在 Teek@1.5.0-2025.9.23 版本上测试
自己的开源库《vitepress-theme-teek-one》 --(克隆自 作者Teeker的文档风开源库《vitepress-theme-teek-docs-template》)
2025年9月26日测试
1、从proxy模式切换到rewrite模式
默认安装的Teek是proxy模式,这里需要手动切换到rewrite模式。
1、导入
编辑docs\.vitepress\config.ts文件
ts
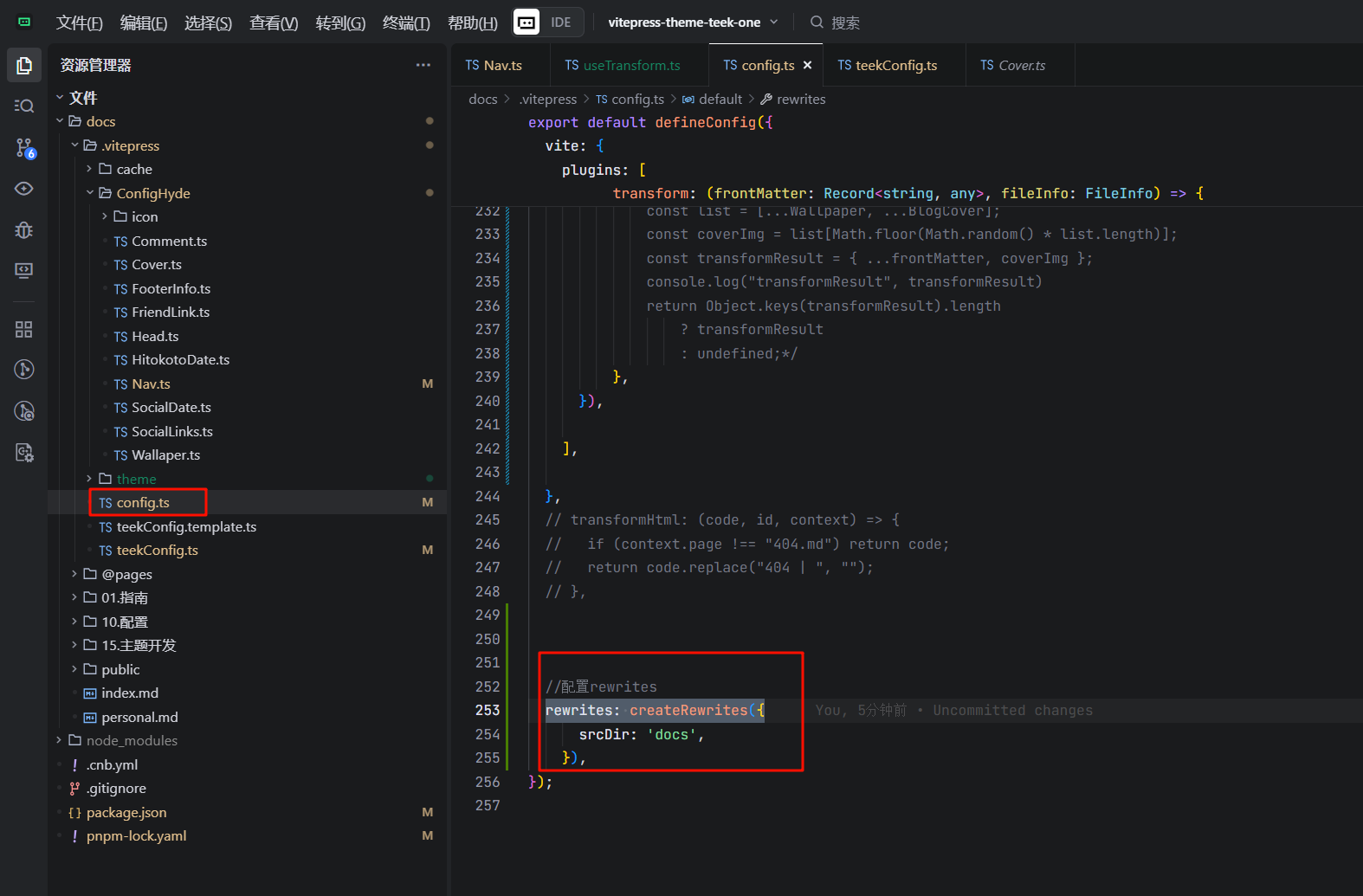
import { createRewrites } from "vitepress-theme-teek/config"; //配置rewrites2、配置
编辑docs\.vitepress\config.ts文件
在export default defineConfig({}) 区域配置。
ts
//配置rewrites
rewrites: createRewrites({
srcDir: 'docs',
}),
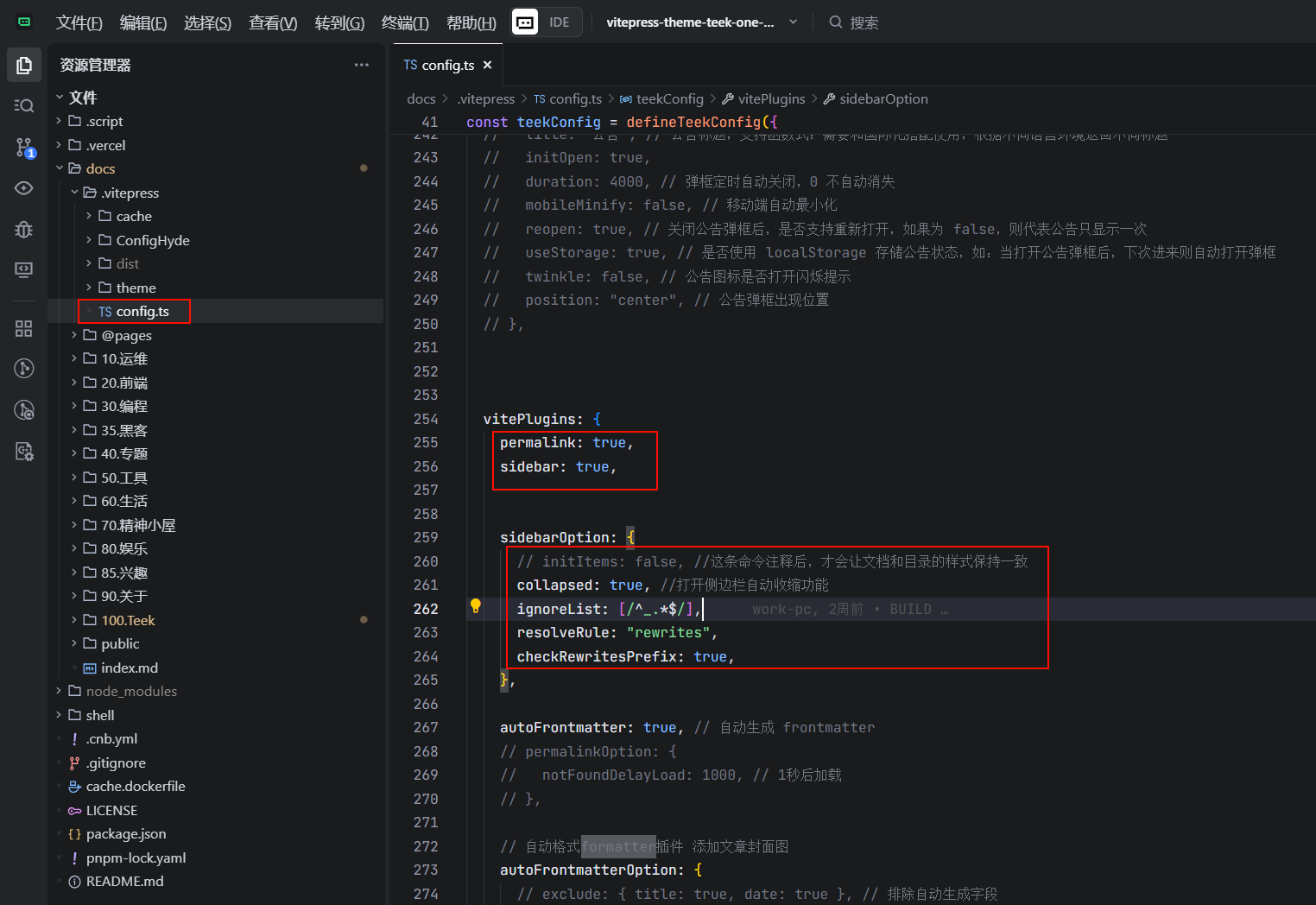
编辑docs\.vitepress\teekConfig.ts文件:
ts
// 开启 permalink 插件
vitePlugins: {
permalink: true,
sidebar: true,
sidebarOption: {
// initItems: false, //这条命令注释后,才会让文档和目录的样式保持一致
collapsed: true, //打开侧边栏自动收缩功能
ignoreList: [/^_.*$/],
resolveRule: "rewrites",
checkRewritesPrefix: true,
ignoreIndexMd: true,
},
autoFrontmatter: true, // 自动生成 frontmatter
// permalinkOption: {
// notFoundDelayLoad: 1000, // 1秒后加载
// },
// 自动格式formatter插件 添加文章封面图
autoFrontmatterOption: {
// exclude: { title: true, date: true }, // 排除自动生成字段
transform: frontmatter => {
// 如果文件本身存在了 coverImg,则不生成
if (frontmatter.coverImg) return;
const list = CoverImgList;
const coverImg = list[Math.floor(Math.random() * list.length)];
const transformResult = { ...frontmatter, coverImg };
return Object.keys(transformResult).length ? transformResult : undefined;
},
},
},
NOTE
以上配置就将我们的Teek从proxy模式切换到了rewrite模式。
但是,如何把自己之前的老库全部迁移过来呢?(老库有成千上万的md文档时,我们的头都要炸了……此时,就可以用到如下autoformatter插件了,让脚本替我们完成。😜)
2、配置autoformatter插件
这里利用autoformatter插件来自动注入 带对应一级前缀的permalink。
📌1.安装插件
bash
pnpm add vitepress-plugin-auto-frontmatter📌2.配置代码
01.导入
编辑docs\.vitepress\config.ts文件
ts
import AutoFrontmatter, {FileInfo} from "vitepress-plugin-auto-frontmatter";
import { useTransformByRules, type TransformRule } from "./theme/composables/useTransform";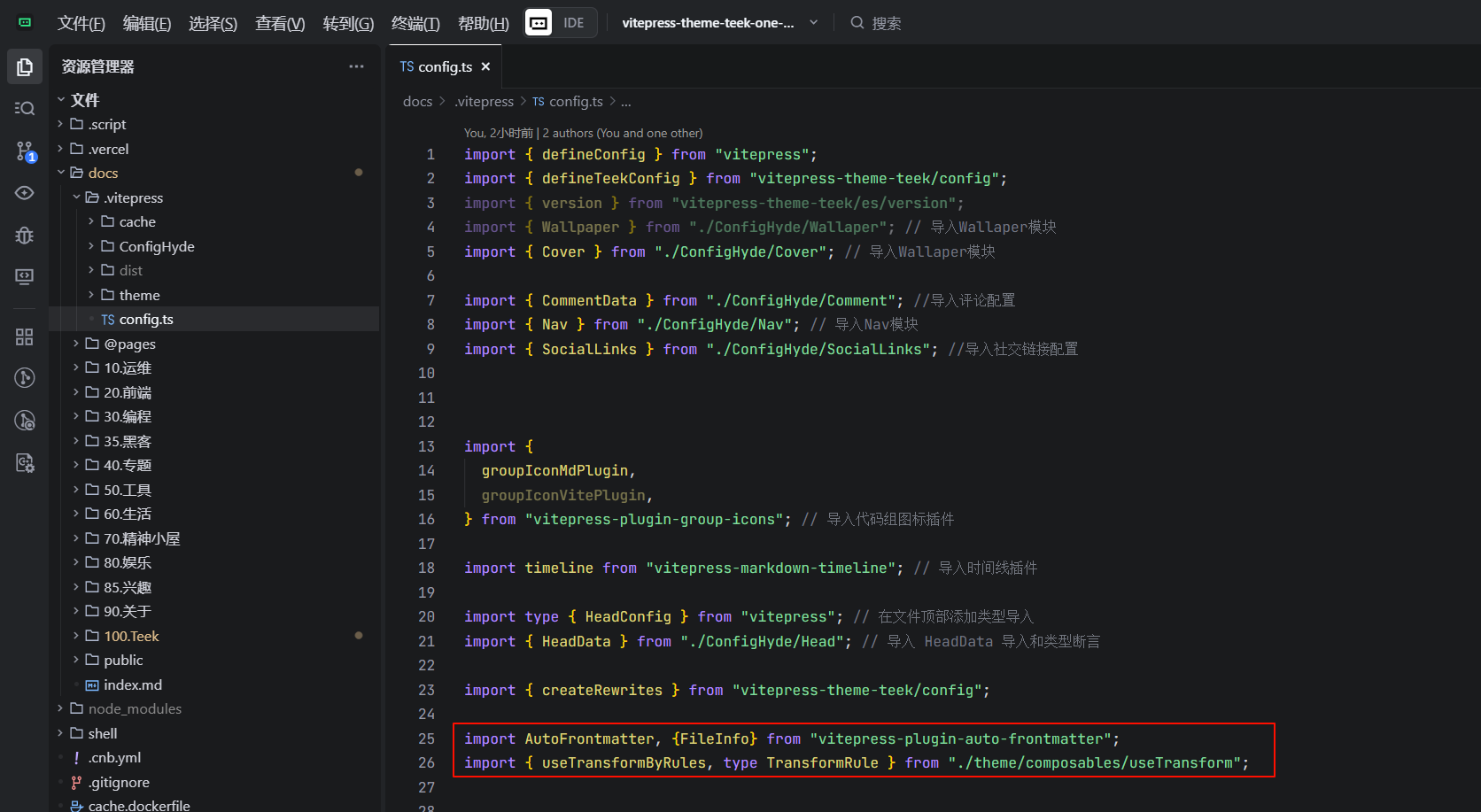
02.配置
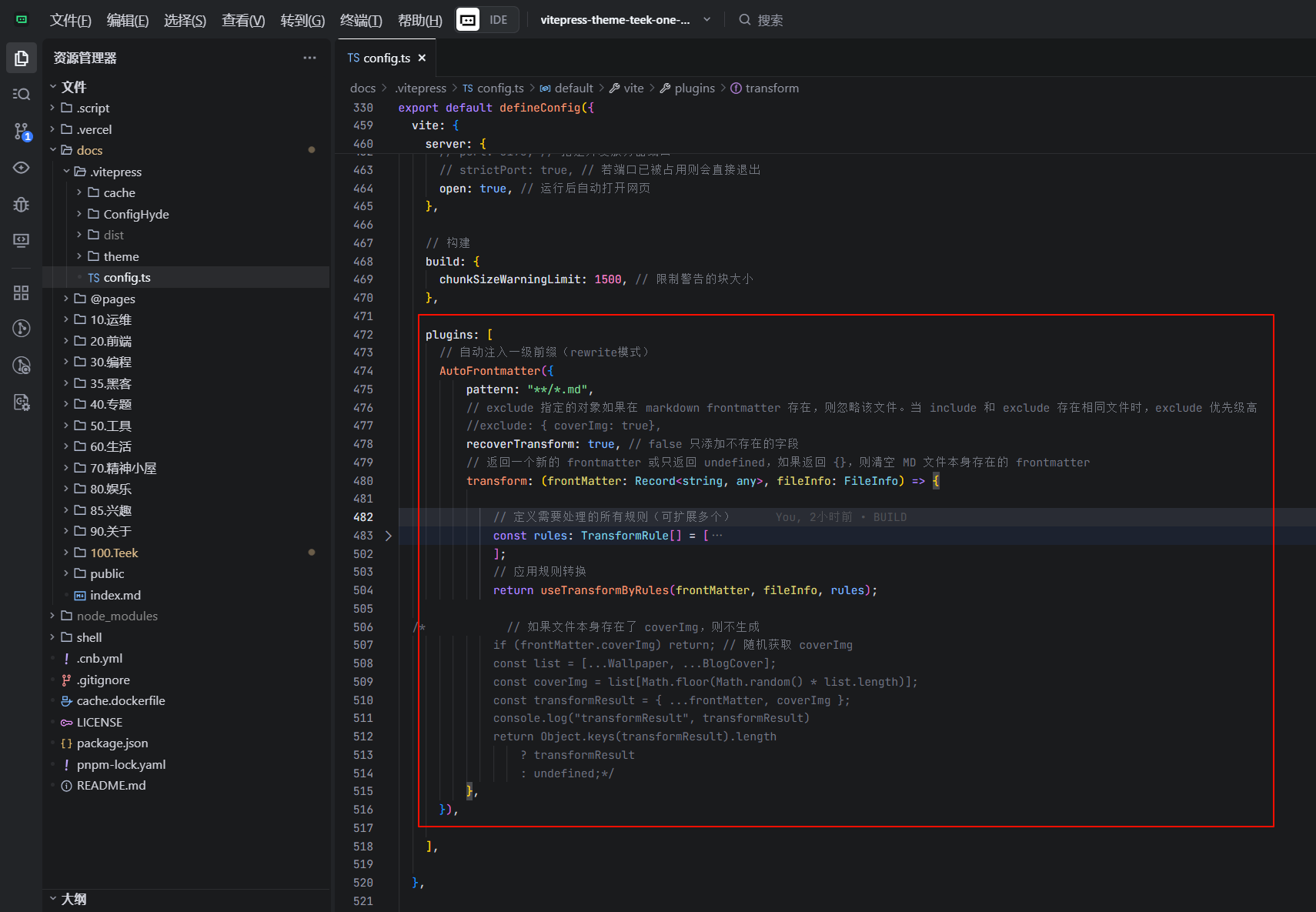
编辑docs\.vitepress\config.ts文件
ts
plugins: [
// 自动注入一级前缀(rewrite模式)
AutoFrontmatter({
pattern: "**/*.md",
// exclude 指定的对象如果在 markdown frontmatter 存在,则忽略该文件。当 include 和 exclude 存在相同文件时,exclude 优先级高
//exclude: { coverImg: true},
recoverTransform: true, // false 只添加不存在的字段
// 返回一个新的 frontmatter 或只返回 undefined,如果返回 {},则清空 MD 文件本身存在的 frontmatter
transform: (frontMatter: Record<string, any>, fileInfo: FileInfo) => {
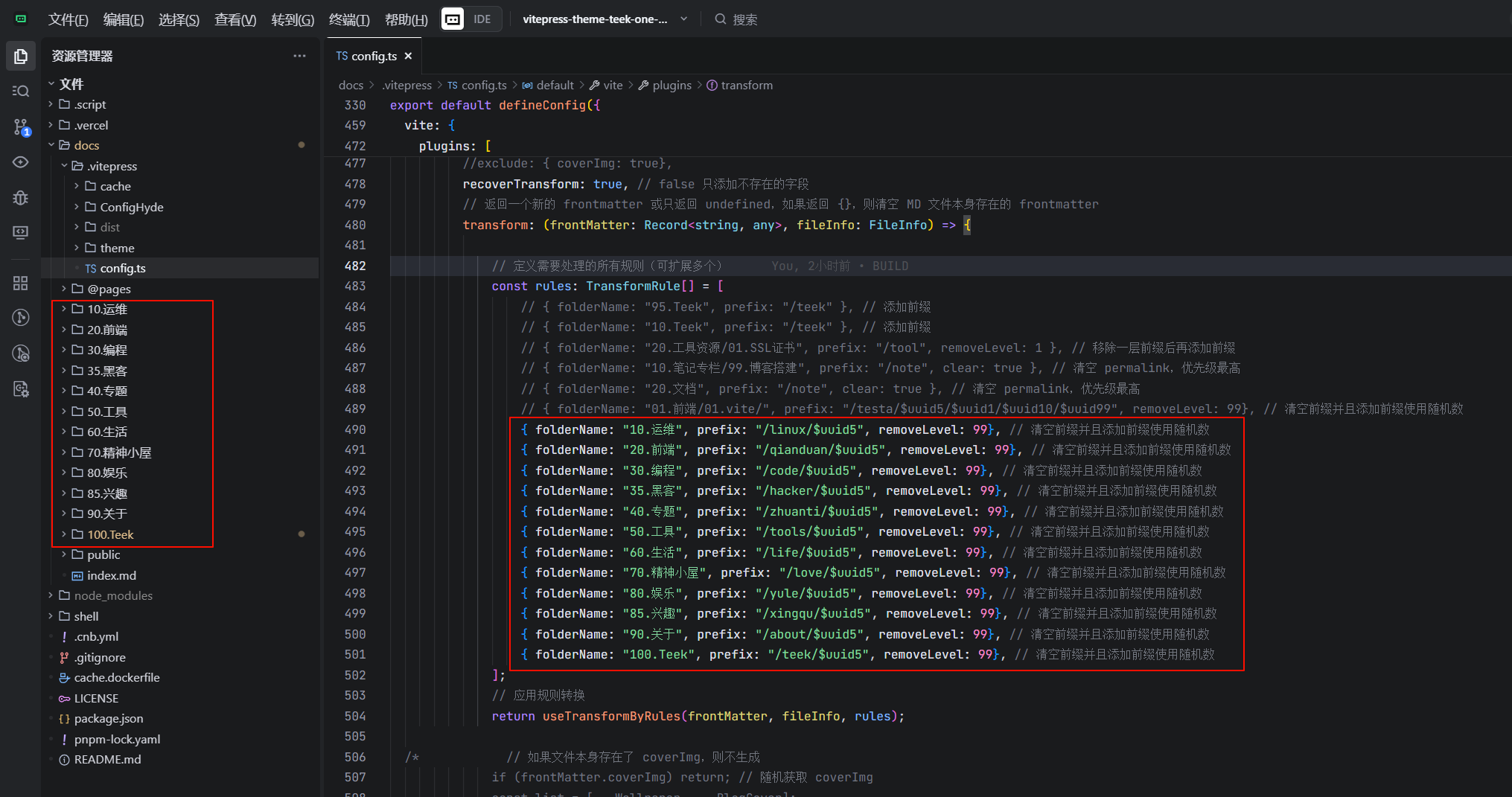
// 定义需要处理的所有规则(可扩展多个)
const rules: TransformRule[] = [
// { folderName: "95.Teek", prefix: "/teek" }, // 添加前缀
// { folderName: "10.Teek", prefix: "/teek" }, // 添加前缀
// { folderName: "20.工具资源/01.SSL证书", prefix: "/tool", removeLevel: 1 }, // 移除一层前缀后再添加前缀
// { folderName: "10.笔记专栏/99.博客搭建", prefix: "/note", clear: true }, // 清空 permalink,优先级最高
// { folderName: "20.文档", prefix: "/note", clear: true }, // 清空 permalink,优先级最高
// { folderName: "01.前端/01.vite/", prefix: "/testa/$uuid5/$uuid1/$uuid10/$uuid99", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "10.运维", prefix: "/linux/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "20.前端", prefix: "/qianduan/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "30.编程", prefix: "/code/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "35.黑客", prefix: "/hacker/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "40.专题", prefix: "/zhuanti/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "50.工具", prefix: "/tools/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "60.生活", prefix: "/life/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "70.精神小屋", prefix: "/love/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "80.娱乐", prefix: "/yule/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "85.兴趣", prefix: "/xingqu/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "90.关于", prefix: "/about/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
{ folderName: "100.Teek", prefix: "/teek/$uuid5", removeLevel: 99}, // 清空前缀并且添加前缀使用随机数
];
// 应用规则转换
return useTransformByRules(frontMatter, fileInfo, rules);
/* // 如果文件本身存在了 coverImg,则不生成
if (frontMatter.coverImg) return; // 随机获取 coverImg
const list = [...Wallpaper, ...BlogCover];
const coverImg = list[Math.floor(Math.random() * list.length)];
const transformResult = { ...frontMatter, coverImg };
console.log("transformResult", transformResult)
return Object.keys(transformResult).length
? transformResult
: undefined;*/
},
}),
],
03.创建docs\.vitepress\theme\composables\useTransform.ts文件
ts
import { FileInfo } from "vitepress-plugin-auto-frontmatter";
// 定义规则类型
export interface TransformRule {
folderName: string; // 匹配文件或文件夹名称
prefix: string; // 要添加的前缀
removeLevel?: number; // 可选:要移除的前缀层级(以 / 分割),可以填写一个很大的数,那么就会全部清空然后添加前缀,适合移除前缀并添加的场景
clear?: boolean; // 可选,是否清空 permalink,适合只想要清空使用。true=清空(即使填了prefix也会清空,clear优先级高),默认false
}
/**
* 获取路径按 / 分割后的第一个有效分组(忽略空字符串)
* @param path
*/
const getFirstPathSegment = (path: string): string => {
// 按 / 分割并过滤空字符串(处理开头/结尾的斜杠或连续斜杠)
const segments = path.split('/').filter(segment => segment.trim() !== '');
return segments.length > 0 ? segments[0] : '';
};
/**
* 生成指定长度的随机字符串(数字 + 小写字母)
* @param length 字符串长度(最大为10)
* @returns 指定长度的随机字符串
*/
const generateRandomString = (length: number): string => {
if (length <= 0) return '';
const maxLen = 10;
const actualLength = Math.min(length, maxLen); // 最大10位
const chars = '0123456789abcdefghijklmnopqrstuvwxyz';
const charsLength = chars.length;
let result = '';
for (let i = 0; i < actualLength; i++) {
result += chars[Math.floor(Math.random() * charsLength)];
}
return result;
};
/**
* 替换字符串中的 $UUID{n} 占位符
* 支持 $UUID2, $UUID5, $UUID10 等格式
* - n 超过 10 按 10 处理
* - 不区分大小写(可选)
* @param str 原始字符串
* @returns 替换后的字符串
* @example
* replaceUuidPlaceholder('/test/$UUID10') → '/test/a3k9m2x8p1'
* replaceUuidPlaceholder('/user/$UUID5/$UUID2') → '/user/abc12/de'
*/
const replaceUuidPlaceholder = (str: string): string => {
return str.replace(/\$UUID(\d+)/gi, (match, numStr) => {
const length = parseInt(numStr, 10);
return generateRandomString(length);
});
};
export const useTransformByRules = (frontMatter: Record<string, any>, fileInfo: FileInfo, rules: TransformRule[]) => {
// 转换函数:支持移除指定层级前缀后再添加新前缀,新增clear清空逻辑 + UUID占位符替换
for (const rule of rules) {
const { folderName, prefix, removeLevel, clear = false } = rule; // 解构时给clear默认值false
// 1. 检查文件路径是否匹配文件夹规则(精确匹配单个文件时,需完全一致)
if (!fileInfo.relativePath.startsWith(folderName)) {
continue;
}
// 处理日期:减去8小时抵消时区转换(原有逻辑不变)
if (frontMatter.date) {
const originalDate = new Date(frontMatter.date);
originalDate.setHours(originalDate.getHours() - 8);
frontMatter.date = originalDate;
}
// 2. 如果clear为true,直接清空permalink并返回(优先级最高)
if (clear) {
const newFrontMatter = { ...frontMatter, permalink: '' };
console.log(`匹配规则:${folderName}(clear=true)→ 清空permalink`);
return newFrontMatter;
}
/* // 3. 非clear模式:检查permalink是否存在(原有逻辑不变)
if (!frontMatter.permalink) {
continue;
}*/
// 4. 新增!替换prefix中的$UUID/$UUID10占位符
let normalizedPrefix = replaceUuidPlaceholder(prefix);
// 原有:标准化前缀(确保以 / 开头)
normalizedPrefix = normalizedPrefix.startsWith('/') ? normalizedPrefix : `/${normalizedPrefix}`;
if (prefix === ""){
normalizedPrefix = ""
}
let originalPermalink = frontMatter.permalink;
if (originalPermalink === null || originalPermalink === undefined) {
originalPermalink = "";
}
// 5. 核心调整:按 / 分组,比较第一个前缀是否一致(原有逻辑不变)
// 获取目标前缀的第一个分组(如 "/test/12345" → "test")
const targetFirstSegment = getFirstPathSegment(normalizedPrefix);
// 获取当前 permalink 的第一个分组(如 "/old/path" → "old")
const currentFirstSegment = getFirstPathSegment(originalPermalink);
// 若第一个分组相同,说明已包含目标前缀,无需处理(原有逻辑不变)
if (currentFirstSegment === targetFirstSegment) {
continue;
}
// 7. 处理 permalink:先移除指定层级,再添加新前缀(原有逻辑不变)
if (removeLevel !== undefined && removeLevel > 0) {
// 分割permalink(处理空字符串和开头的 /)
const parts = originalPermalink.split('/').filter(part => part);
// 确保移除的层级不超过实际存在的层级(removeLevel=99时,会移除所有层级,只剩根路径)
const actualRemoveLevel = Math.min(removeLevel, parts.length);
// 移除前N个层级,再重新拼接
const remainingParts = parts.slice(actualRemoveLevel);
originalPermalink = remainingParts.length > 0
? `/${remainingParts.join('/')}`
: ''; // 移除所有层级后,originalPermalink为 ""
}
// 8. 拼接新 permalink 并返回结果(原有逻辑不变,此时prefix已替换占位符)
const newPermalink = `${normalizedPrefix}${originalPermalink}`;
const newFrontMatter = { ...frontMatter, permalink: newPermalink };
console.log(`原permalink:${frontMatter.permalink} → 新permalink:${newPermalink}`);
return newFrontMatter;
}
// 没有匹配的规则,返回undefined(不修改数据)
return undefined;
}📌3.配置一级前缀
警告
根据自己docs下的目录,填好上述代码,然后运行测试:
📌4.修改nav
编辑D:\vitepress-theme-teek-one-private\docs\.vitepress\ConfigHyde\Nav.ts文件:
ts
// nav导航栏配置
import { TeekIcon, VdoingIcon, SSLIcon, BlogIcon } from "./icon/NavIcon";
export const Nav = [
{ text: "🏡首页", link: "/" },
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/teek.svg" alt="" style="width: 16px; height: 16px;">
<span>Teek</span>
</div>
`,
link: '/teek/teek',
},
// 笔记
{
text: '📚知识库',
items: [
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/linux.svg" alt="" style="width: 16px; height: 16px;">
<span>运维</span>
</div>
`,
link: '/linux/linux',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/前端.svg" alt="" style="width: 16px; height: 16px;">
<span>前端</span>
</div>
`,
link: '/qianduan/qianduan',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/编程.svg" alt="" style="width: 16px; height: 16px;">
<span>编程</span>
</div>
`,
link: '/code/code',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/黑客.svg" alt="" style="width: 16px; height: 16px;">
<span>黑客</span>
</div>
`,
link: '/hacker/hacker',
},
],
},
// 专题
{
text: '🛠️专题',
items: [
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/博客.svg" alt="" style="width: 16px; height: 16px;">
<span>博客搭建</span>
</div>
`,
link: '/zhuanti/blog',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/前端demo.svg" alt="" style="width: 16px; height: 16px;">
<span>前端demo</span>
</div>
`,
link: '/zhuanti/qianduan-demo',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/Git.svg" alt="" style="width: 16px; height: 16px;">
<span>Git</span>
</div>
`,
link: '/zhuanti/git',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/面试.svg" alt="" style="width: 16px; height: 16px;">
<span>面试</span>
</div>
`,
link: '/zhuanti/mianshi',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/NAS.svg" alt="" style="width: 16px; height: 16px;">
<span>NAS</span>
</div>
`,
link: '/zhuanti/NAS',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/脚本.svg" alt="" style="width: 16px; height: 16px;">
<span>脚本</span>
</div>
`,
link: '/zhuanti/jiaoben',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/工具.svg" alt="" style="width: 16px; height: 16px;">
<span>工具</span>
</div>
`,
link: '/tools/tools',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/开源项目.svg" alt="" style="width: 16px; height: 16px;">
<span>开源项目</span>
</div>
`,
link: '/zhuanti/opensource',
},
],
},
// 生活
{
text: '🏓生活',
items: [
{
// 分组标题1
text: '娱乐',
items: [
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/相册.svg" alt="" style="width: 16px; height: 16px;">
<span>相册</span>
</div>
`,
link: '/yule/photo',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/电影.svg" alt="" style="width: 16px; height: 16px;">
<span>电影</span>
</div>
`,
link: '/yule/movie',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/音乐.svg" alt="" style="width: 16px; height: 16px;">
<span>音乐</span>
</div>
`,
link: '/yule/music',
},
],
},
{
// 分组标题2
text: '小屋',
items: [
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/精神小屋.svg" alt="" style="width: 16px; height: 16px;">
<span>精神小屋</span>
</div>
`,
link: '/love/love',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/时间管理.svg" alt="" style="width: 16px; height: 16px;">
<span>时间管理</span>
</div>
`,
link: '/love/time-plan',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/文案.svg" alt="" style="width: 16px; height: 16px;">
<span>情感文案</span>
</div>
`,
link: '/love/wenan',
},
// { text: "💖情侣空间", link: "https://fxj.onedayxyy.cn/" },
],
},
],
},
// 兴趣
{
text: '🎨兴趣',
items: [
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/旅行.svg" alt="" style="width: 16px; height: 16px;">
<span>旅行</span>
</div>
`,
link: '/xingqu/travel',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/读书.svg" alt="" style="width: 16px; height: 16px;">
<span>读书</span>
</div>
`,
link: '/xingqu/reading',
},
],
},
// 索引
{
text: '👏索引',
items: [
{ text: '📃分类页', link: '/categories' },
{ text: '🔖标签页', link: '/tags' },
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/归档.svg" alt="" style="width: 16px; height: 16px;">
<span>归档页</span>
</div>
`,
link: '/archives',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/清单.svg" alt="" style="width: 16px; height: 16px;">
<span>清单页</span>
</div>
`,
link: '/articleOverview',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/登录.svg" alt="" style="width: 16px; height: 16px;">
<span>登录页</span>
</div>
`,
link: '/login',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/风险提示.svg" alt="" style="width: 16px; height: 16px;">
<span>风险链接提示页</span>
</div>
`,
link: '/risk-link?target=https://onedayxyy.cn/',
},
],
},
// 关于
{
text: '🍷关于',
items: [
{ text: '👋关于我', link: '/about/me' },
{ text: '🎉关于本站', link: '/about/website' },
{ text: '🌐网站导航', link: '/about/websites' },
{ text: "👂留言区", link: "/about/liuyanqu" },
{ text: "💡思考", link: "/about/thinking" },
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/时间轴.svg" alt="" style="width: 16px; height: 16px;">
<span>时间轴</span>
</div>
`,
link: 'https://one.onedayxyy.cn/',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/网站统计.svg" alt="" style="width: 16px; height: 16px;">
<span>网站统计</span>
</div>
`,
link: 'https://umami.onedayxyy.cn/share/DzS4g85V8JkxsNRk/onedayxyy.cn',
},
{
text: `
<div style="display: flex; align-items: center; gap: 4px;">
<img src="/img/nav/站点监控.svg" alt="" style="width: 16px; height: 16px;">
<span>站点监控</span>
</div>
`,
link: 'https://status.onedayxyy.cn/status/monitor',
},
],
},
]以上配置完成后,验证。
3、验证
2025年8月27日测试。
结束。