
给Teek网站配置Algolia搜索
实战-给Teek网站配置Algolia 实现全站内容搜索功能-2025.8.8(成功测试)
目录
[toc]
版权
感谢w3c大佬手把手指导。💖💖💖
背景
自己的Teek网站已经部署好久了,默认是自带本地搜索的,但是当网站数据量大了后,点击搜索后,会卡顿好久。因此这里直接给自己网站配置Algolia搜索。
前提
具有自己的Teek网站 😜
前言
什么是Algolia
这个配置过程挺简单的,按文档操作,就OK的。
docusaurus搭建的静态网站,默认是不具有全站内容搜索功能的,因此这里配置Algolia 实现内容搜索。
Algolia 是一个搜索、推荐服务平台,可以通过简单的配置来为站点添加全文检索功能。
基本原理:
通过爬虫对目标网站的内容创建 Records (记录), 在用户搜索时调用接口返回相关内容。
为网站添加 实时搜索, 采用 Docusaurus2 官方支持的 Algolia DocSearch
Docsearch 每周一次爬取网站 (可在网页界面上配置具体时间), 并将所有内容汇总到一个 Algolia 索引中
随后,前端页面会调用 Algolia API 来直接查询这些内容。
1、Docsearch 官网申请
一定要先向Docsearch 官网申请成功后,再创建自己的数据源才行,不然可能会测试失败的。
前置条件:
- 准备好自己的域名地址 - 本案例: https://onedayxyy.cn/
这个是自己的Teek文档网站。

- 前置条件准备完成后, 就可到 Docsearch 注册
https://docsearch.algolia.com/apply/
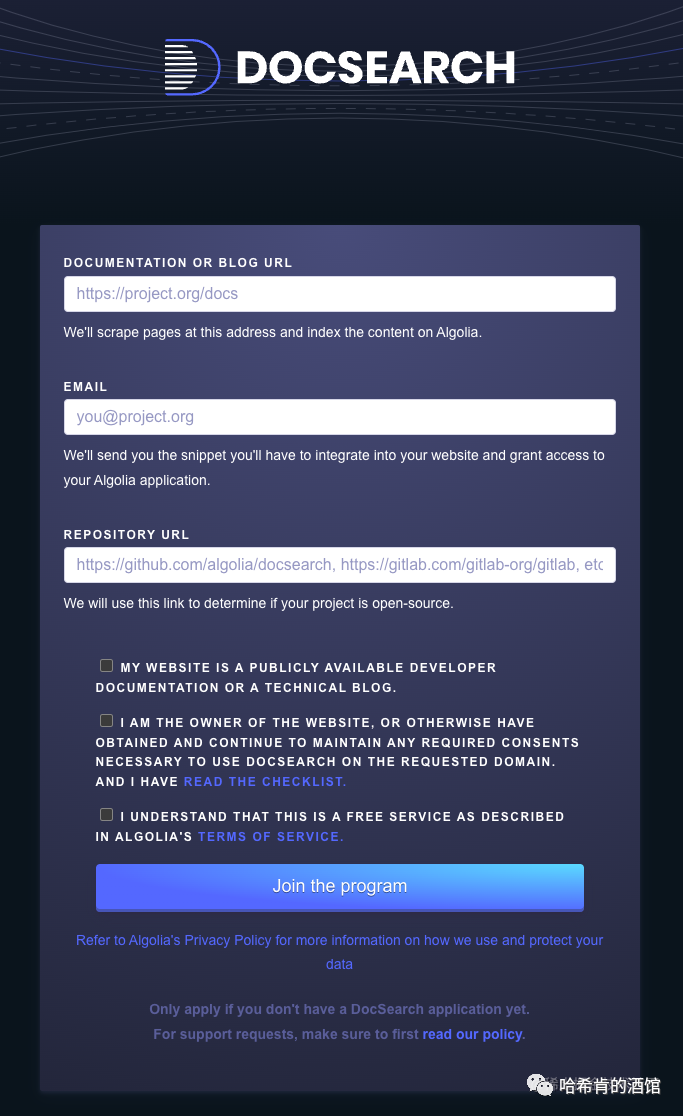
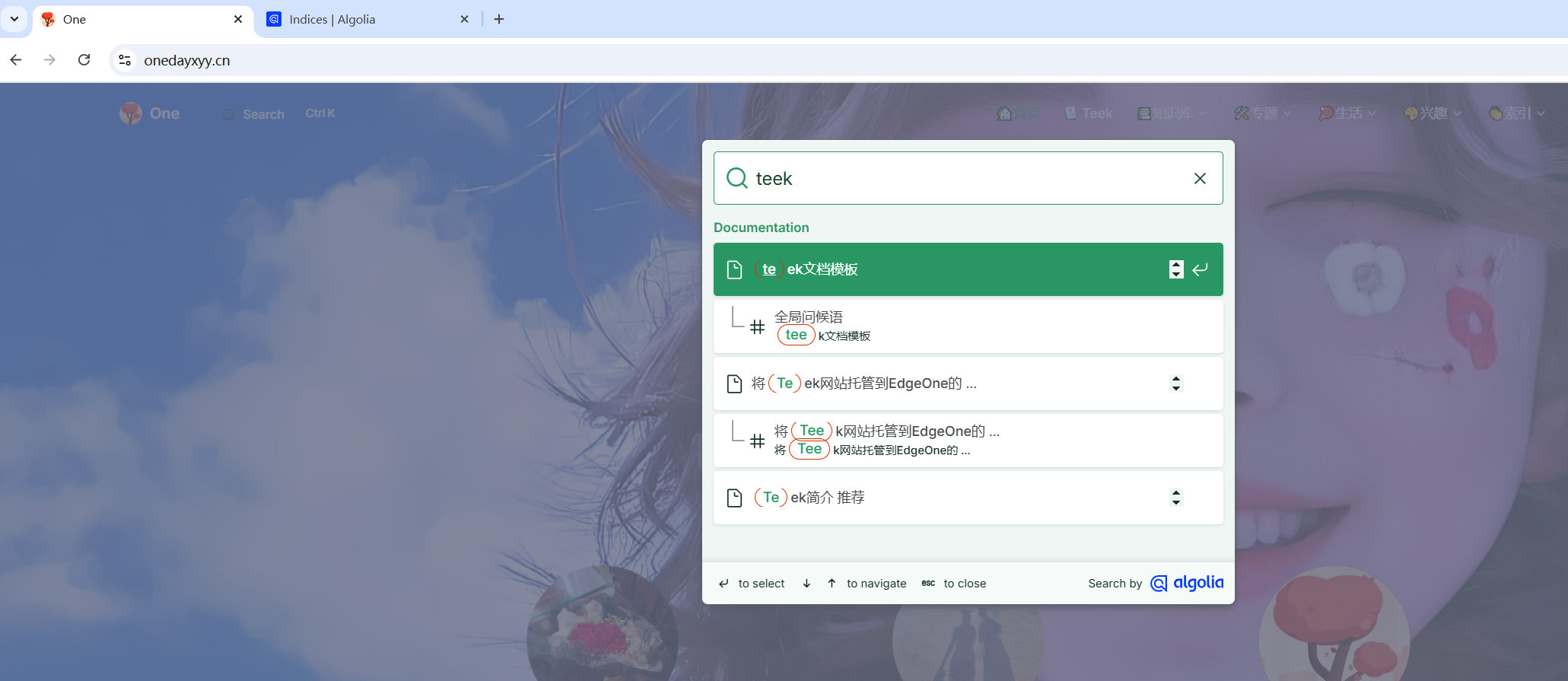
提交后大约 2 天内会收到 反馈邮件, 通知注册成功:
自己的测试过程如下:
https://docsearch.algolia.com/apply/

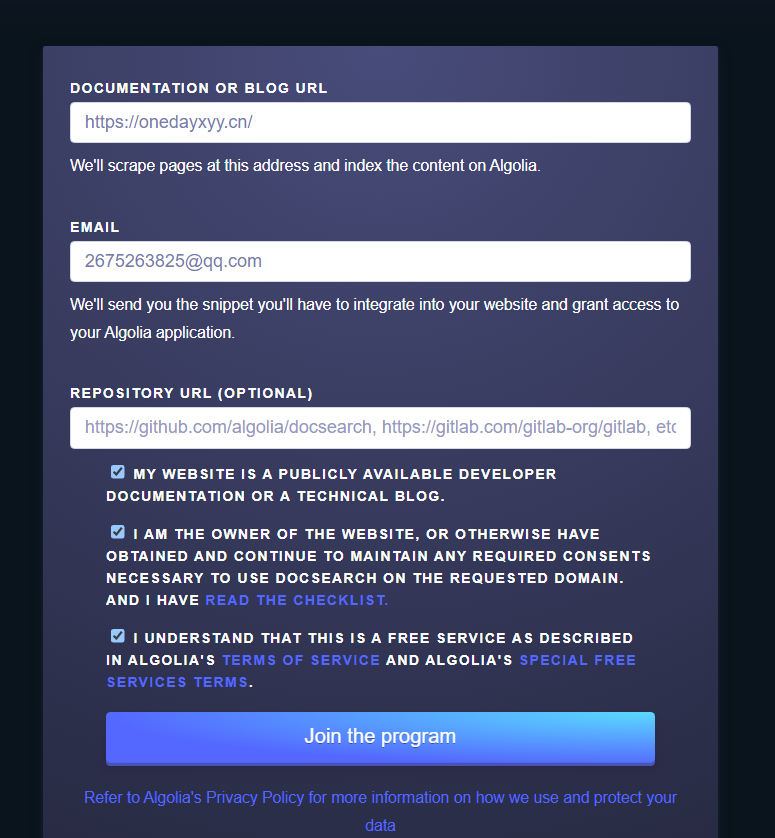
点击Join后,怎么没有反应呢?奇怪。。。(点击后,就自动提交了,我们只需要耐心等待即可)

看下后续是否会收到邮件吧?
当前操作时间为:2023年11月15日14:25:55
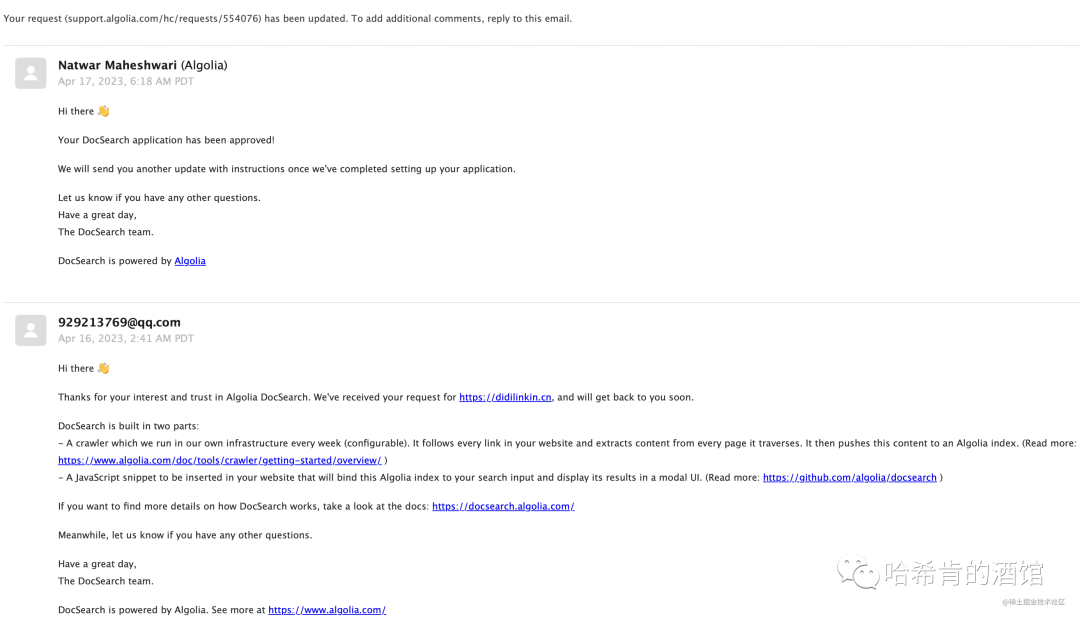
- 哦,后面收到邮件了
(几个小时就会得到回复了)


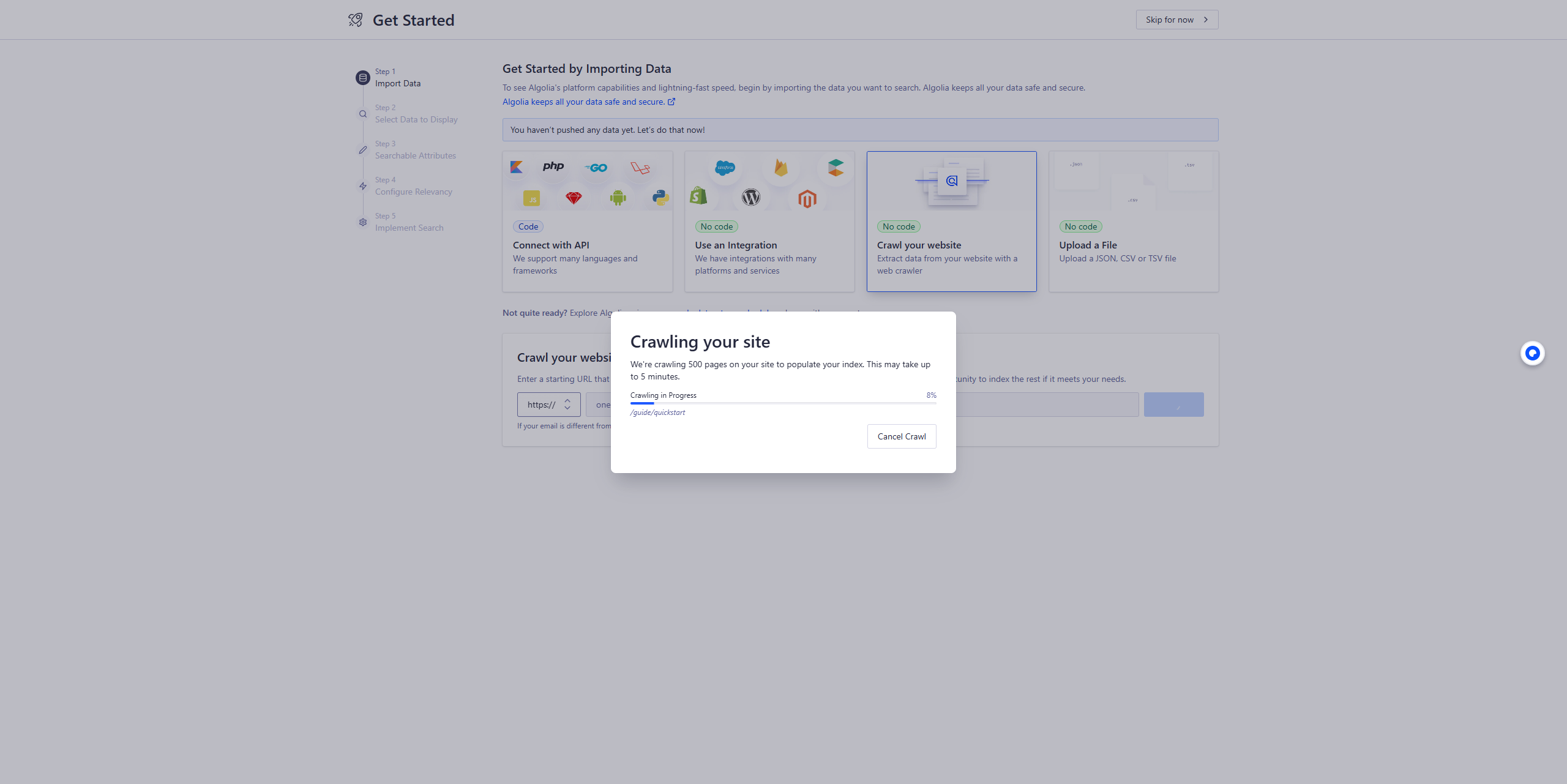
注意:等到官方回复后,这里点击import your data后,就到了具体的配置步骤,我们不用管,按我的文档往下走即可。
2、注册账号&创建 Application
获取 Application ID & API Keys
首先需要去 algolia 官网注册自己的账号,可以直接使用 Github 注册登陆即可。
注册完后,创建数据源 DB:
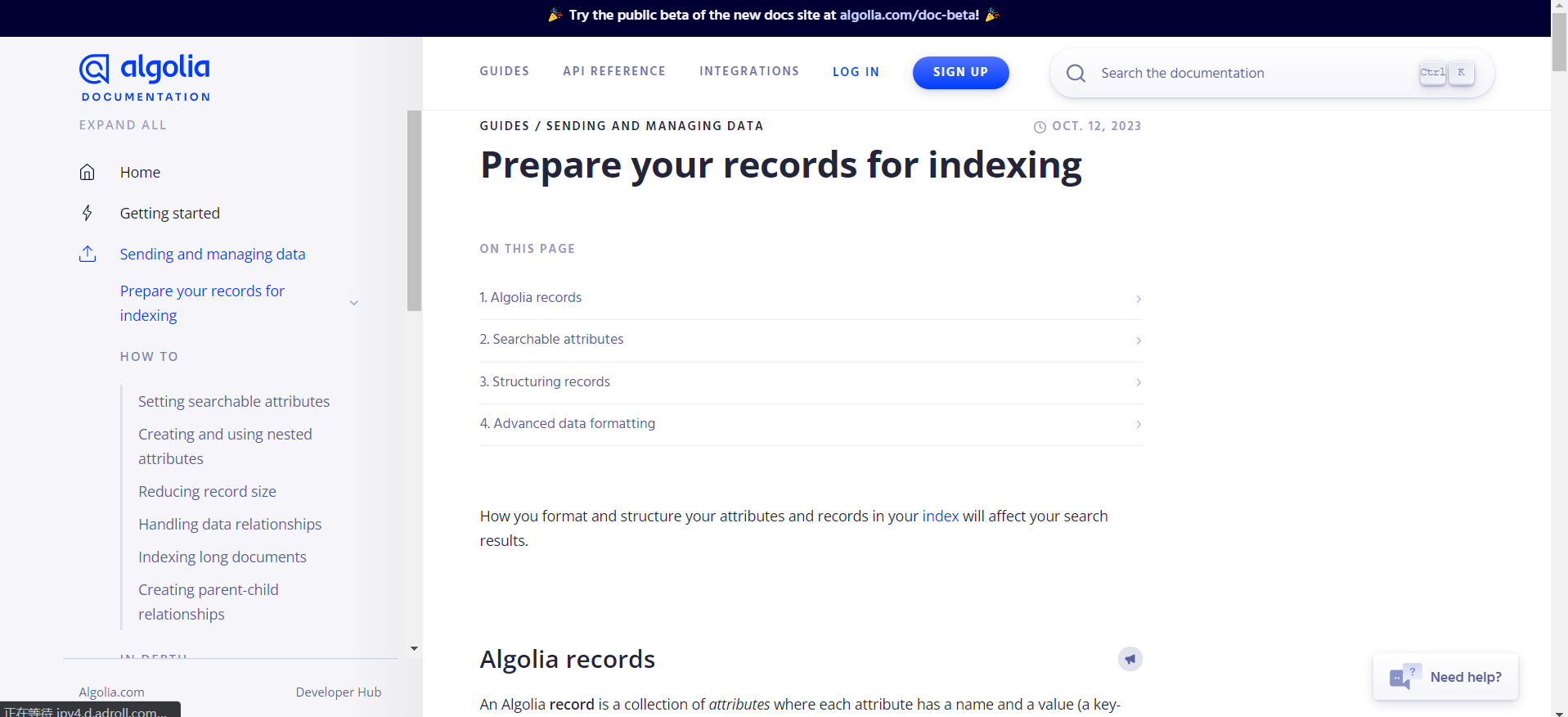
- 前往 Algolia 官网, 登录账户 创建 Application
https://dashboard.algolia.com/apps/EW7M8KMAOC/dashboard
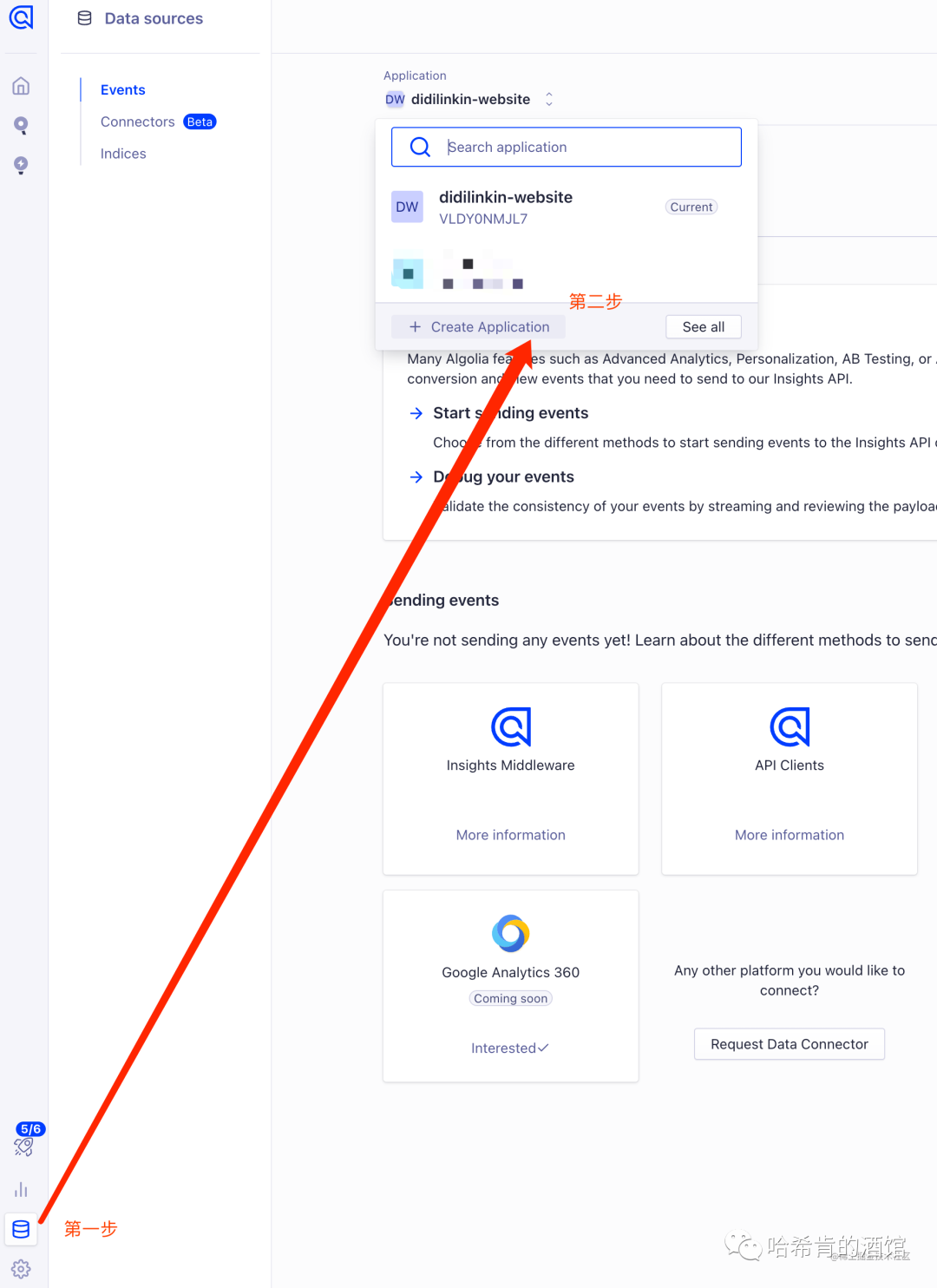
设置 Application 名称, 选择免费计划
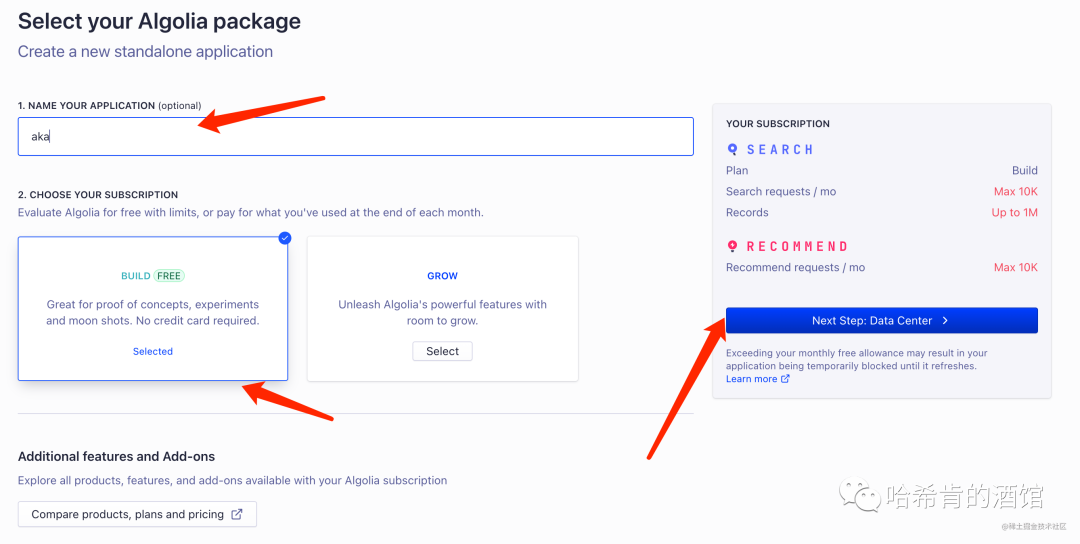
最后选择响应速度快的服务后, 创建成功✅
控制台打开 设置页面,点击 API keys
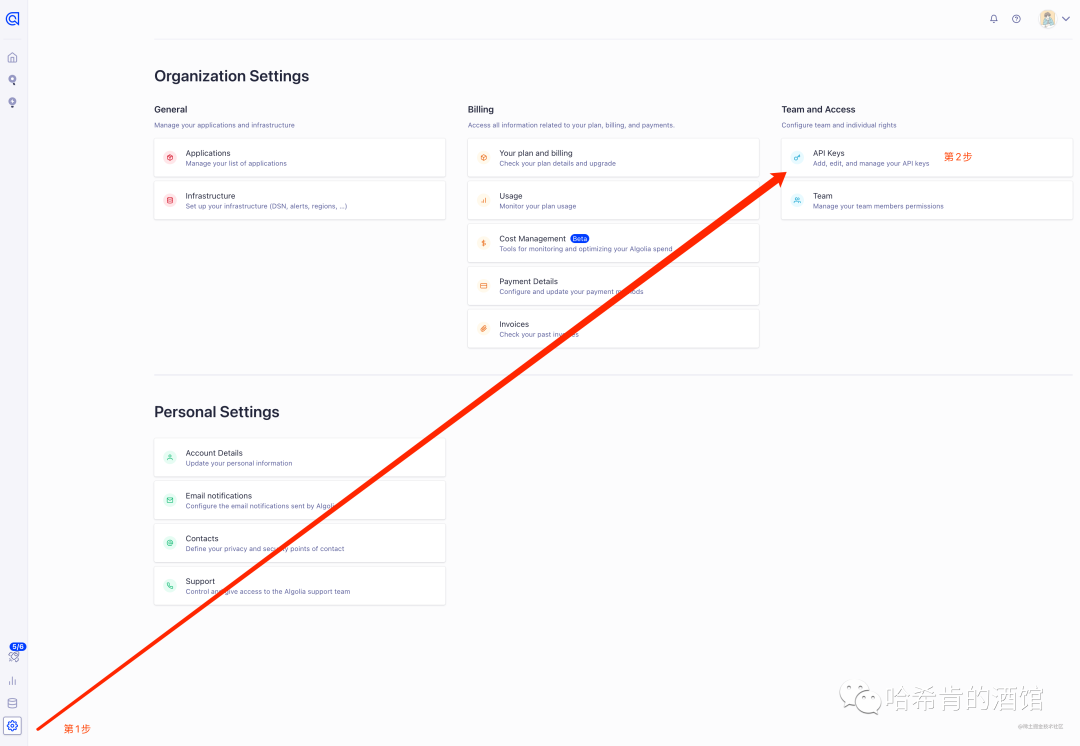
找到 接下来本地配置需要的数据
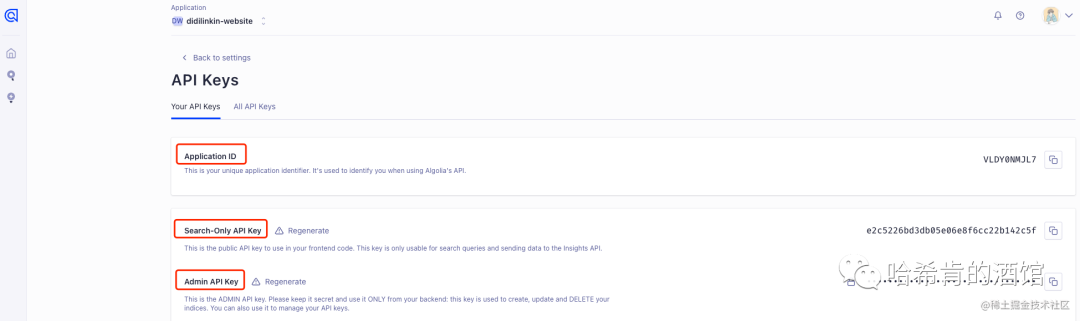
这里记录好需要用到的数据。
3、配置爬虫Crawler
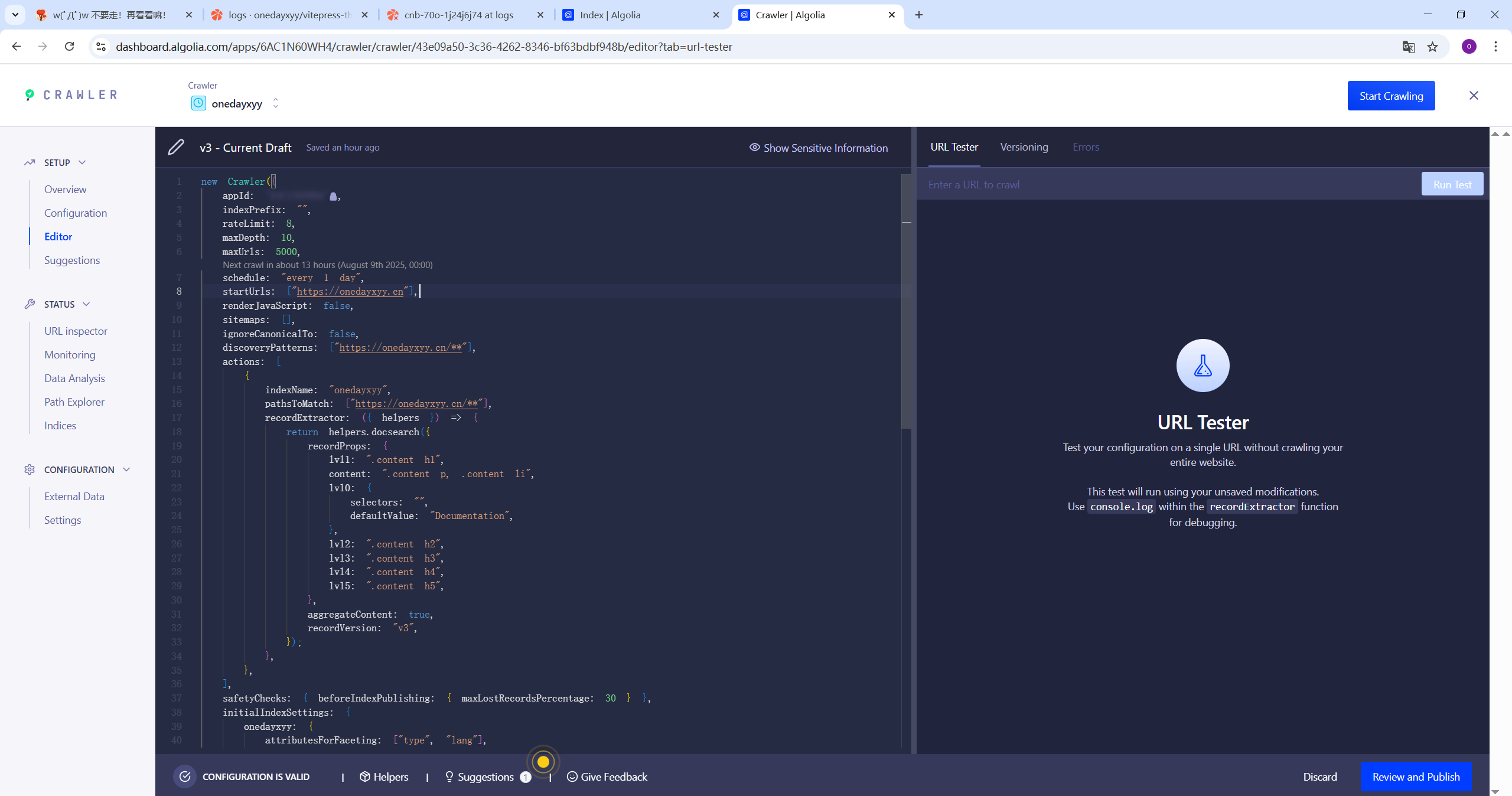
new Crawler({
appId: "6AC1N60WH4",
indexPrefix: "",
rateLimit: 8,
maxDepth: 10,
maxUrls: 5000,
schedule: "every 1 day",
startUrls: ["https://onedayxyy.cn"],
renderJavaScript: false,
sitemaps: [],
ignoreCanonicalTo: false,
discoveryPatterns: ["https://onedayxyy.cn/**"],
actions: [
{
indexName: "onedayxyy",
pathsToMatch: ["https://onedayxyy.cn/**"],
recordExtractor: ({ helpers }) => {
return helpers.docsearch({
recordProps: {
lvl1: ".content h1",
content: ".content p, .content li",
lvl0: {
selectors: "",
defaultValue: "Documentation",
},
lvl2: ".content h2",
lvl3: ".content h3",
lvl4: ".content h4",
lvl5: ".content h5",
},
aggregateContent: true,
recordVersion: "v3",
});
},
},
],
safetyChecks: { beforeIndexPublishing: { maxLostRecordsPercentage: 30 } },
initialIndexSettings: {
onedayxyy: {
attributesForFaceting: ["type", "lang"],
attributesToRetrieve: [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type",
],
attributesToHighlight: ["hierarchy", "content"],
attributesToSnippet: ["content:10"],
camelCaseAttributes: ["hierarchy", "content"],
searchableAttributes: [
"unordered(hierarchy.lvl0)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy.lvl6)",
"content",
],
distinct: true,
attributeForDistinct: "url",
customRanking: [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)",
],
ranking: [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom",
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight">',
highlightPostTag: "</span>",
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: "allOptional",
},
},
apiKey: "a2d720a2aa7cf2c31b3722d0974639c2",
});- 验证
到自己的algolia账户下看下数据情况:
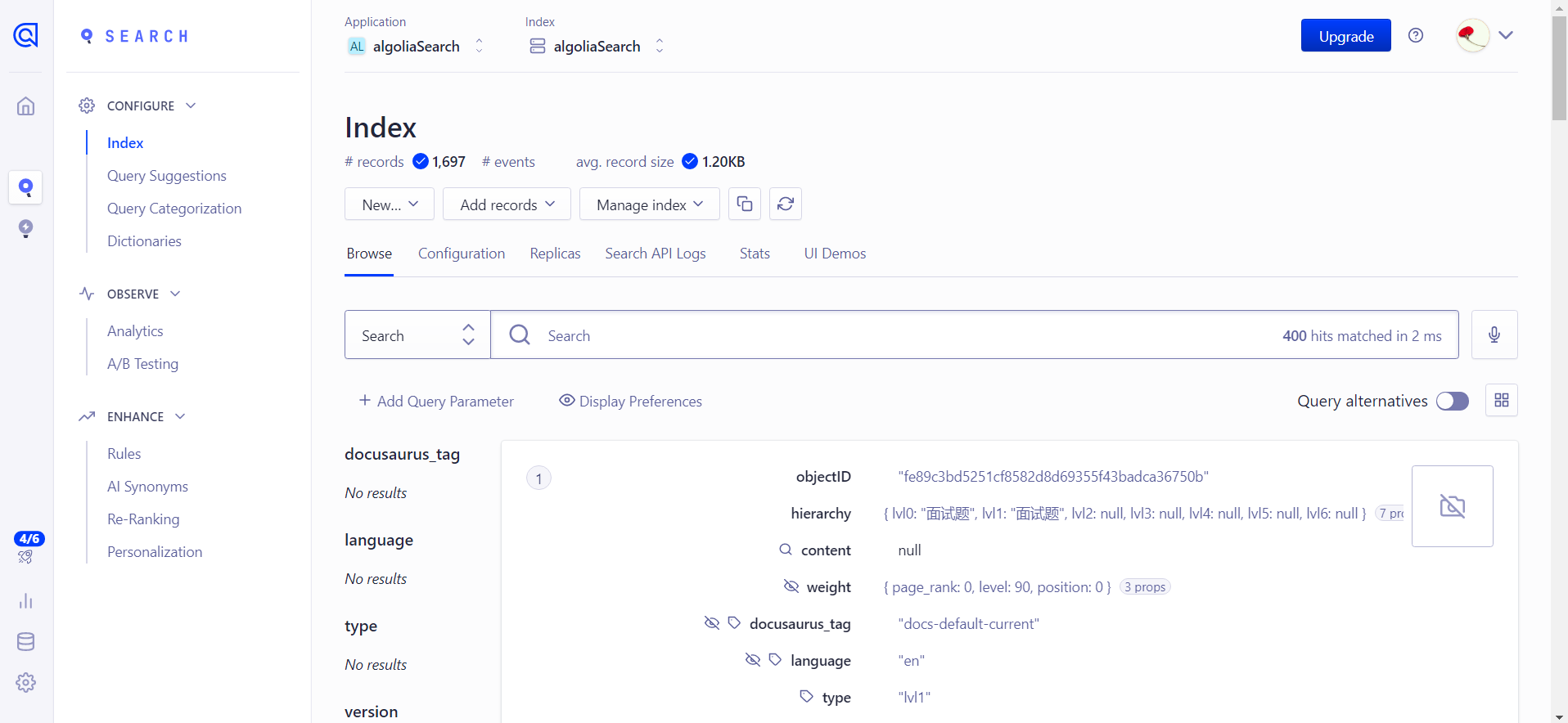
4、Teek项目中配置 algolia
VitePress官方已经支持了 algolia 搜索,直接去 docs\.vitepress\config.ts 文件配置即可:
来到自己Teek项目仓库,配置 docs\.vitepress\config.ts文件:
// algolia搜索
search: {
provider: 'algolia',
options: {
appId: '6AC1N60WH4',
apiKey: '90f7d1ece3094d290fe42fcaf6cdfd3c',
indexName: 'onedayxyy',
},注意:这里要填搜索key,是可以公开的。

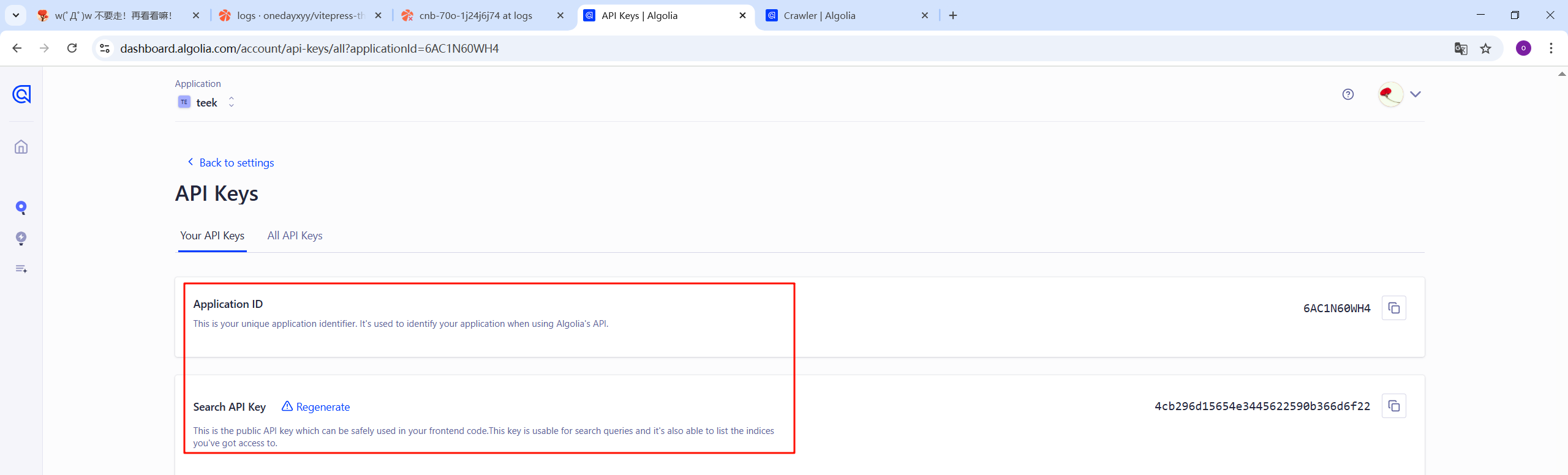
如果是用其他搭建的比如 Hexo,VuePress/ VitePres,也类似,在对应在 config 文件配置就好。
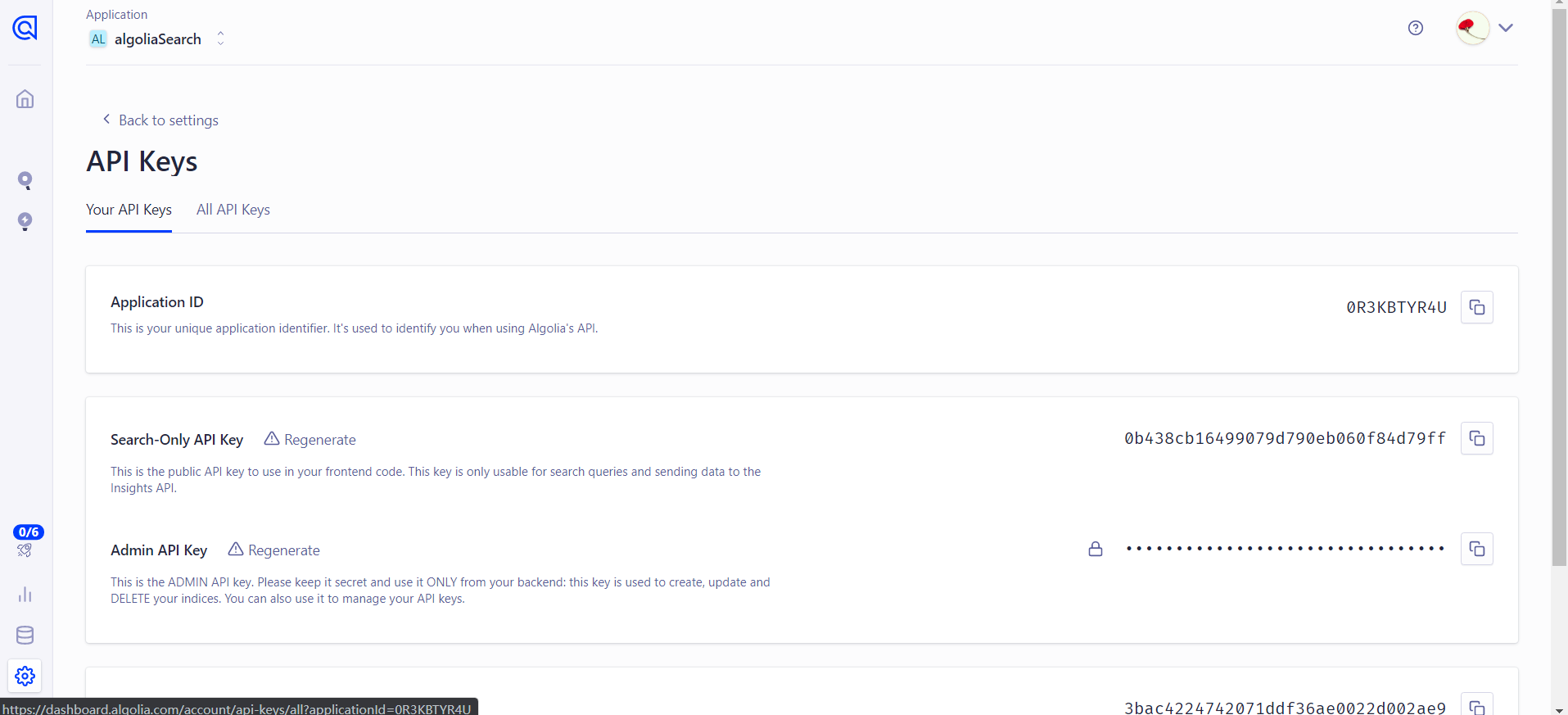
上面 apiKey、appId 可以在 API Keys 里面查看:
运行项目,就可以看到出现搜索功能,这时候还不能用,因为 algolia 还没有爬取自己网站的内容。
提交本地数据到服务器端。
Algolia数据
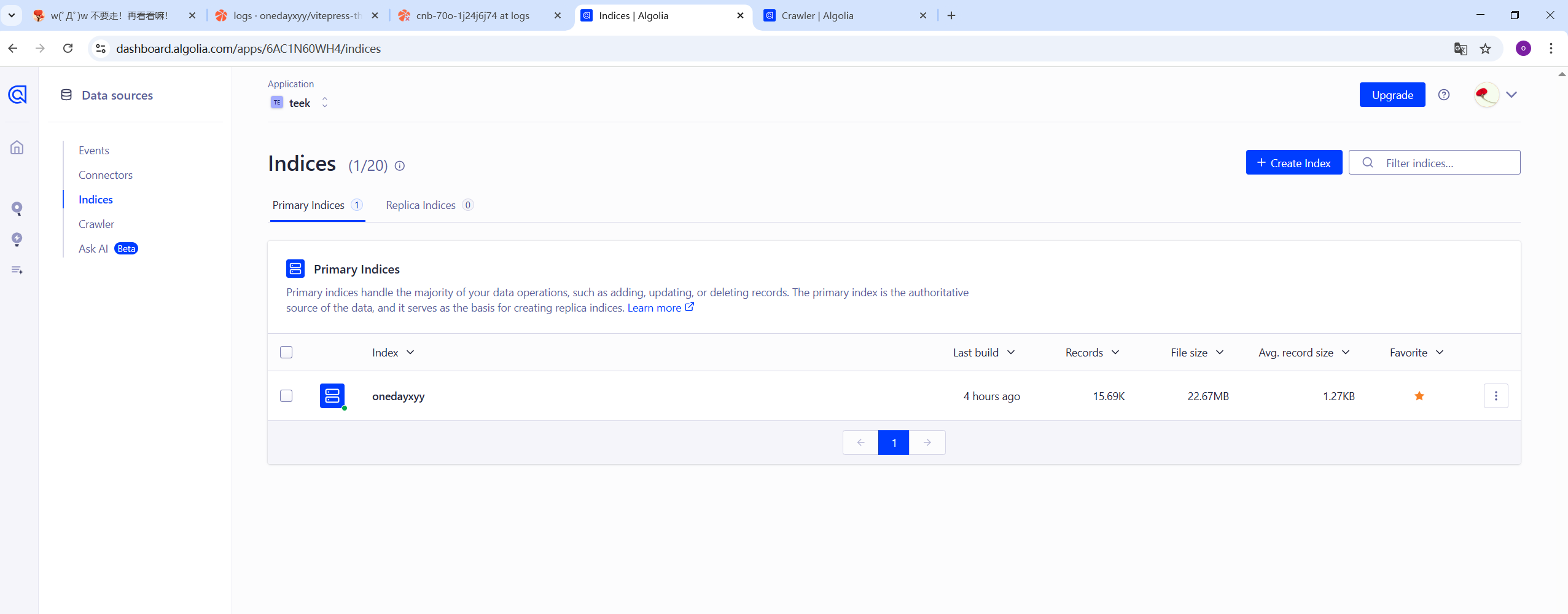
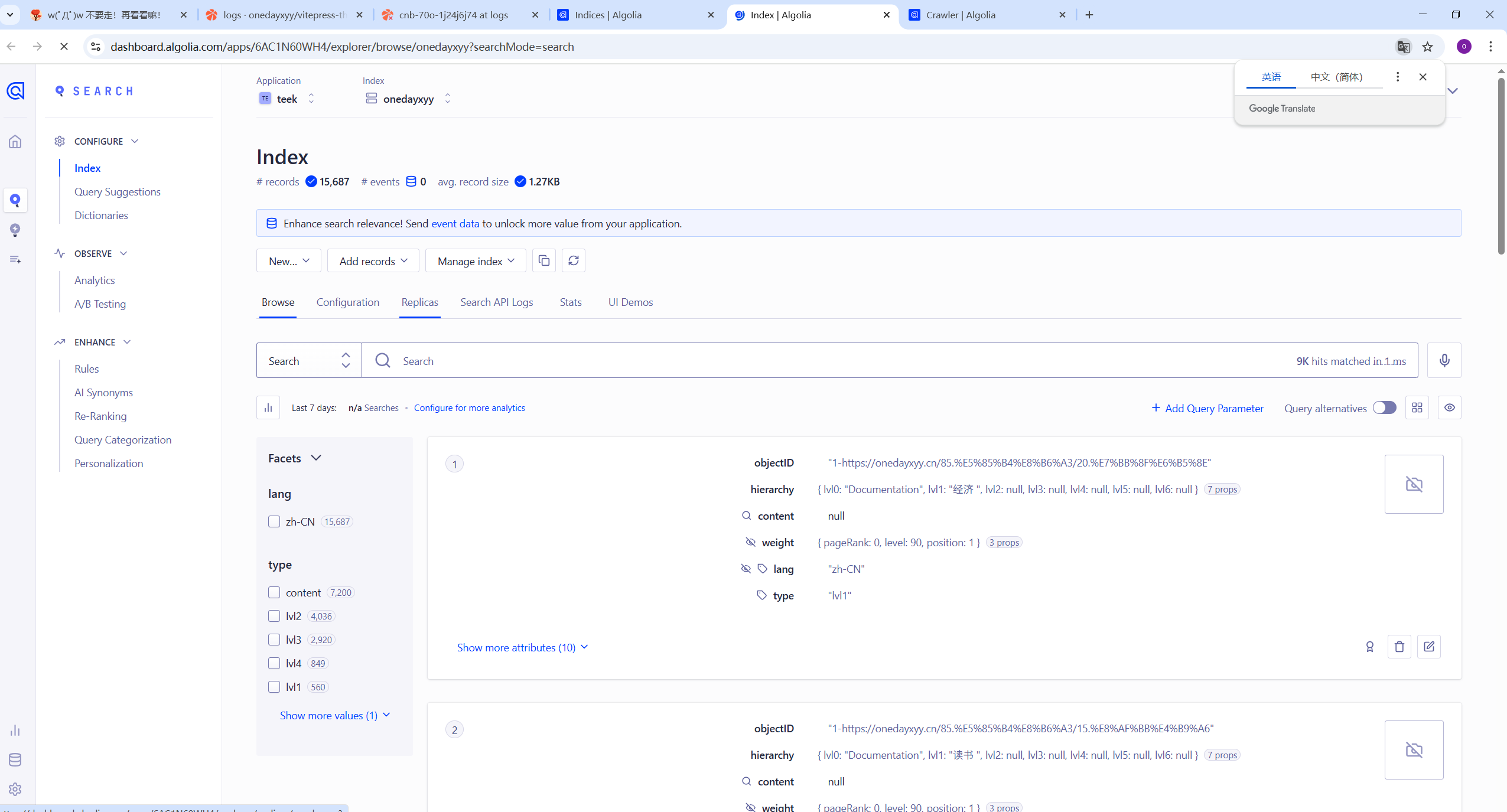
5、测试
可以看到,此时自己博客网站和本地测试就可以正常使用网站搜索功能的:(完美😘)
存在问题
额度不够
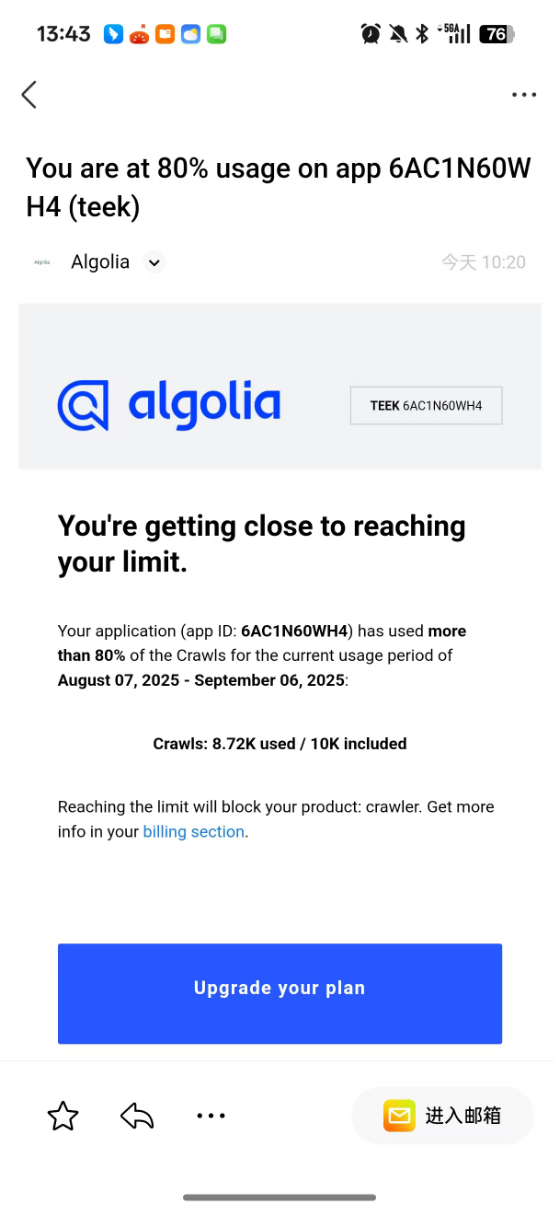
解决办法:
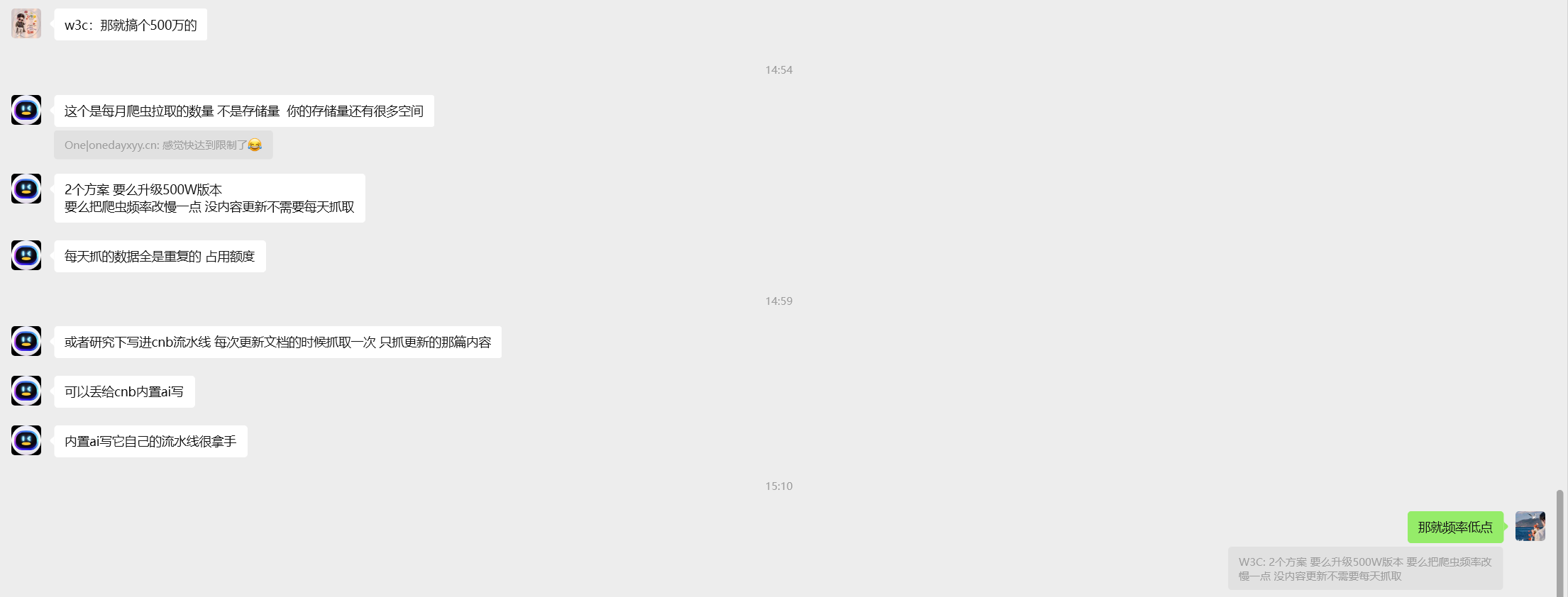
FAQ
加入team
加入team后,协同配置。
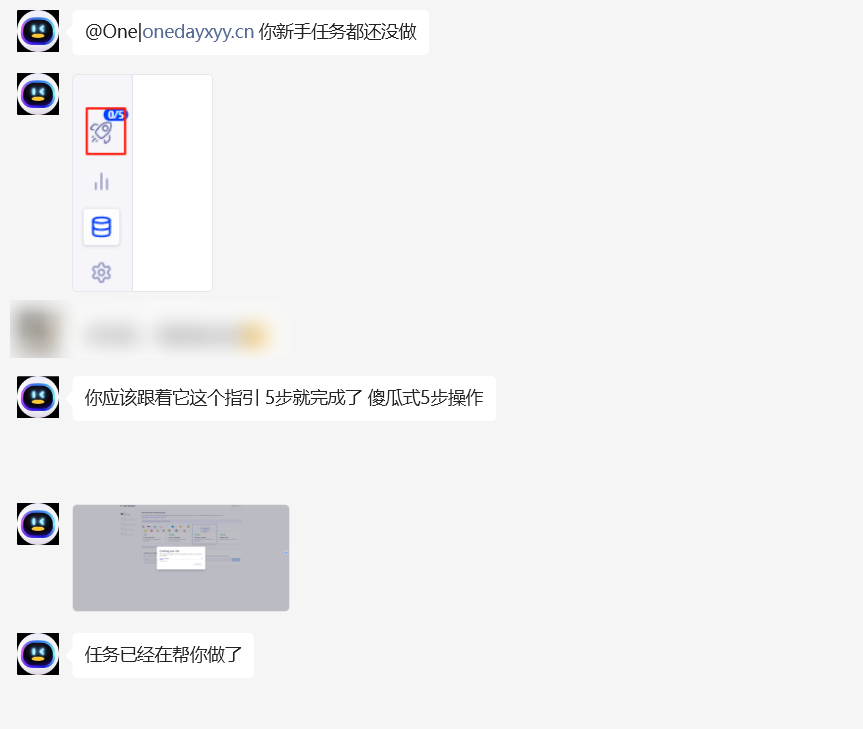
跟着新手任务做
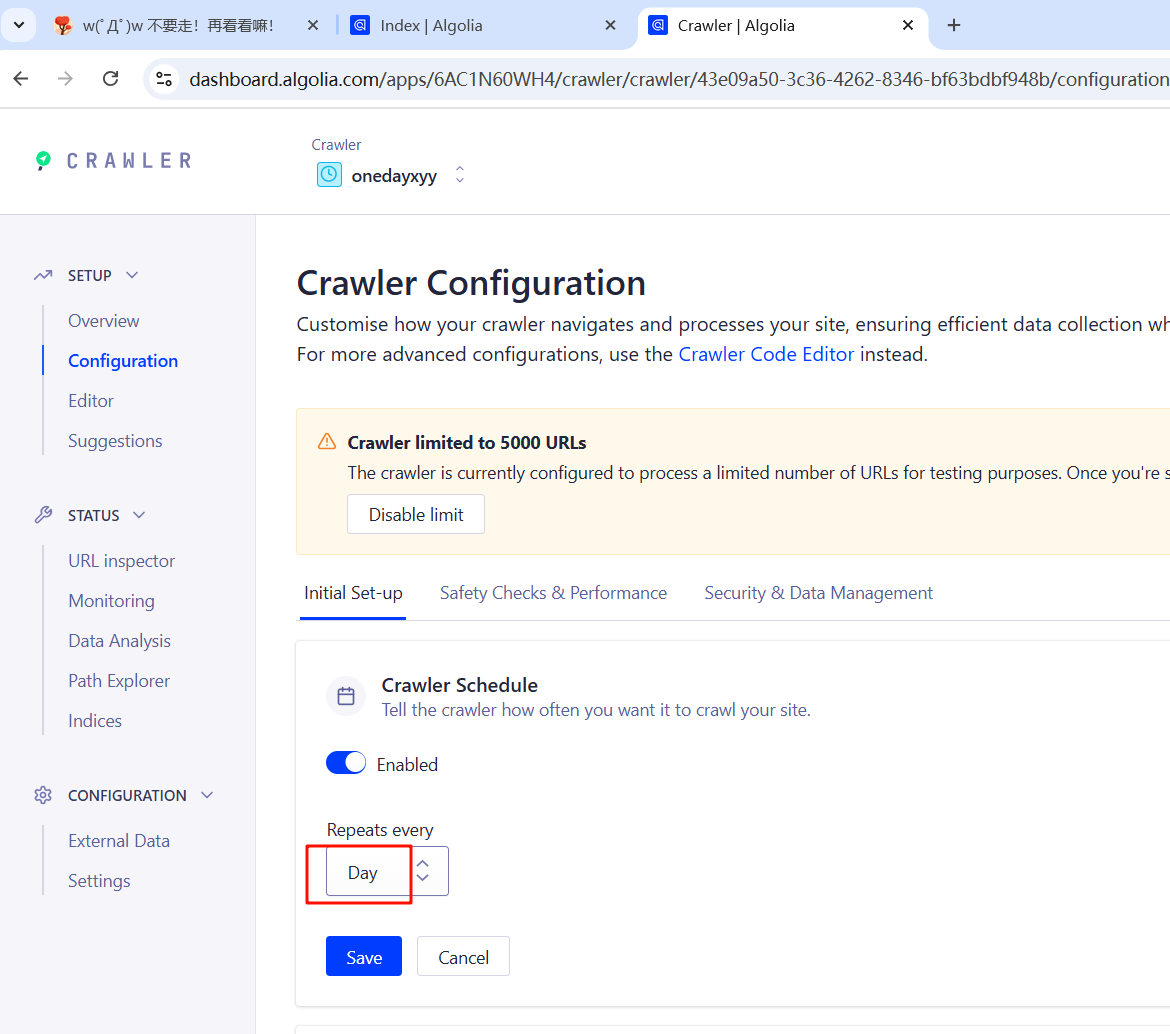
设置每天爬取
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 个人网站

🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
