容器运行时
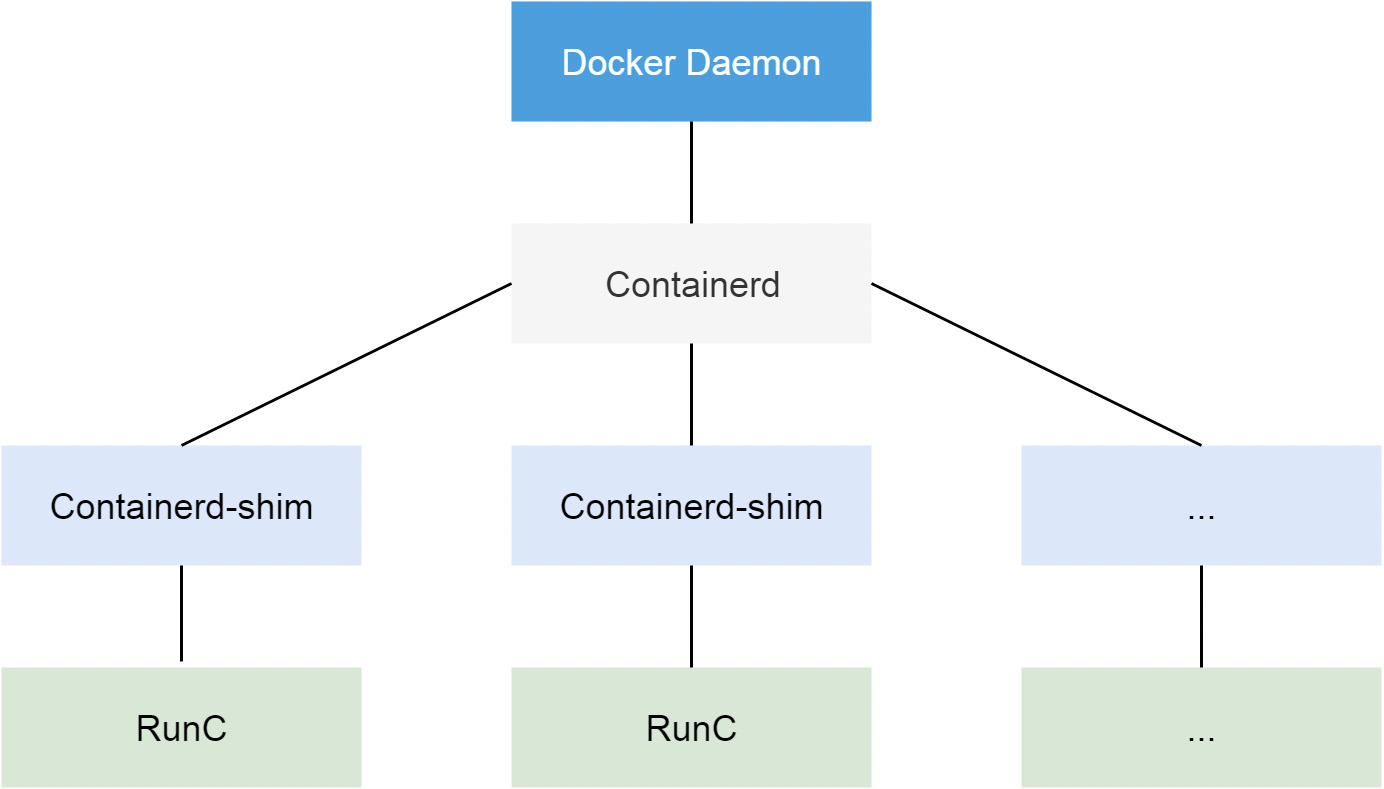
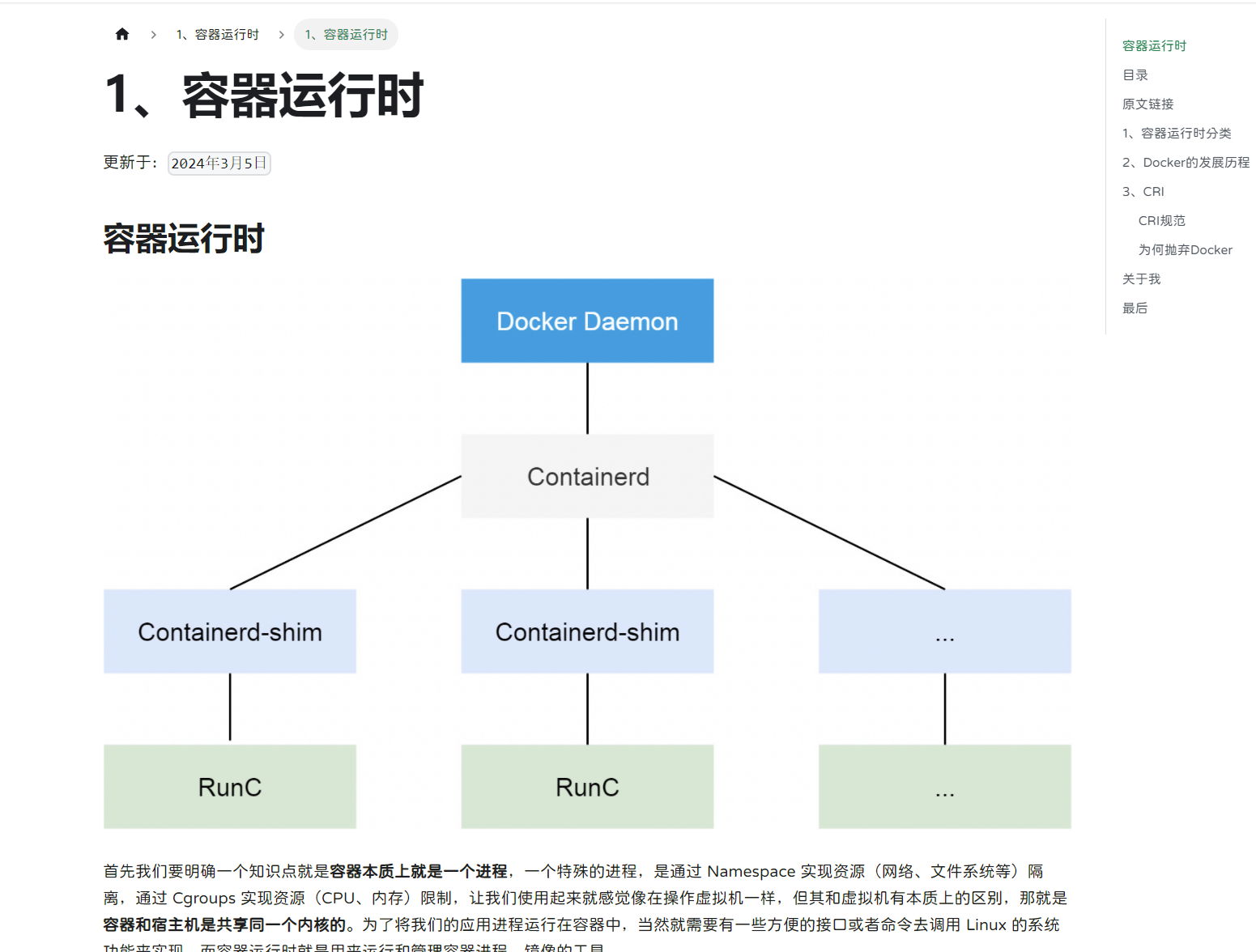
首先我们要明确一个知识点就是容器本质上就是一个进程,一个特殊的进程,是通过 Namespace 实现资源(网络、文件系统等)隔离,通过 Cgroups 实现资源(CPU、内存)限制,让我们使用起来就感觉像在操作虚拟机一样,但其和虚拟机有本质上的区别,那就是容器和宿主机是共享同一个内核的。为了将我们的应用进程运行在容器中,当然就需要有一些方便的接口或者命令去调用 Linux 的系统功能来实现,而容器运行时就是用来运行和管理容器进程、镜像的工具。
目录
[toc]
原文链接
推荐文章
我的开源项目:
https://onedayxyy.cn/docs/MyOpenSourceProject

1、容器运行时分类
当然最火大家最熟悉的容器运行时非 Docker 莫属了,Docker 凭借一己之力大大推进了容器技术的普及。当然随着容器生态的不断发展,业界也慢慢出现了其他的运行时,比如 Containerd、rkt、kata container、cri-o 等等,这些运行时提供的功能不尽相同,有些只有容器运行的功能,有些除运行容器之外还提供了容器镜像的管理功能。根据容器运行时提供的功能,我们可以将容器运行时分为低层运行时和高层运行时。
==低层运行时==主要负责与宿主机操作系统打交道,根据指定的容器镜像在宿主机上运行容器进程,并对容器的整个生命周期进行管理,也就是负责设置容器 Namespace、Cgroups 等基础操作的组件,常见的低层运行时有:
runc:传统的运行时,基于 Linux Namespace 和 Cgroups 技术实现,代表实现 Docker、Containerdrunv:基于虚拟机管理程序的运行时,通过虚拟化 guest kernel,将容器和主机隔离开来,使得其边界更加清晰,代表实现是 Kata Container 和 Firecrackerrunsc:runc+safety,通过拦截应用程序的所有系统调用,提供安全隔离的轻量级容器运行时沙箱,代表实现是谷歌的 gVisor
==高层运行时==主要负责镜像的管理等工作,为容器的运行做准备,主流的高层运行时包括 Containerd、CRI-O。高层运行时与低层运行时各司其职,容器运行时一般先由高层运行时将容器镜像下载下来,并解压转换为容器运行需要的操作系统文件,再由低层运行时启动和管理容器。
2、Docker的发展历程
从 Docker 1.11 版本开始,Docker 容器运行就不是简单通过 Docker Daemon 来启动了,而是通过集成 Containerd、runc 等多个组件来完成的。虽然 Docker Daemon 守护进程模块在不停的重构,但是基本功能和定位没有太大的变化,一直都是 CS 架构,守护进程负责和 Docker Client 端交互,并管理 Docker 镜像和容器。现在的架构中组件 Containerd 就会负责集群节点上容器的生命周期管理,并向上为 Docker Daemon 提供 gRPC 接口。
==Docker创建容器过程==
当我们要创建一个容器的时候,现在 Docker Daemon 并不能直接帮我们创建了,而是请求 Containerd 来创建一个容器,Containerd 收到请求后,也并不会直接去操作容器,而是创建一个叫做 Containerd-shim 的进程,让这个进程去操作容器,我们指定容器进程是需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的,假如这个父进程就是 Containerd,那如果 Containerd 挂掉的话,整个宿主机上所有的容器都得退出了,而引入 Containerd-shim 这个垫片就可以来规避这个问题了。
containerd-shim:可以翻译成垫片或者中间件。
Containerd-shim可以认为是托管我们容器父进程的一个工具;
每一个容器起起来之后,都会有一个conatinerd-shim存在;
containerd-shim主要是来控制你的容器的;
然后创建容器需要做一些 Namespaces 和 Cgroups 的配置,以及挂载 root 文件系统等操作,这些操作其实已经有了标准的规范,那就是 ==OCI(开放容器标准)==,runc 就是它的一个参考实现(Docker 被逼无耐将 libcontainer 捐献出来改名为 runc 的),这个标准其实就是一个文档,主要规定了容器镜像的结构、以及容器需要接收哪些操作指令,比如 create、start、stop、delete 等这些命令。runc 就可以按照这个 OCI 文档来创建一个符合规范的容器,既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时也都是符合 OCI 标准的。
所以真正启动容器是通过 Containerd-shim 去调用 runc 来启动容器的,==runc 启动完容器后本身会直接退出==,Containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 Containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。
而 Docker 将容器操作都迁移到 Containerd 中去是因为当前做 Swarm,想要进军 PaaS 市场,做了这个架构切分,让 Docker Daemon 专门去负责上层的封装编排,当然后面的结果我们知道 Swarm 在 Kubernetes 面前是惨败,然后 Docker 公司就把 Containerd 项目捐献给了 CNCF 基金会,这个也是现在的 Docker 架构。
3、CRI
我们知道 Kubernetes 提供了一个 CRI 的容器运行时接口,那么这个 CRI 到底是什么呢?这个其实也和 Docker 的发展密切相关的。**(说明:所谓接口,就是它定义了一个行为,你只要按我的行为来实现了,那么我就能支持你;)**
在 Kubernetes 早期的时候,当时 Docker 实在是太火了,Kubernetes 当然会先选择支持 Docker,而且是通过硬编码的方式直接调用 Docker API,后面随着 Docker 的不断发展以及 Google 的主导,出现了更多容器运行时介绍,Kubernetes 为了支持更多更精简的容器运行时介绍,Google 就和红帽主导推出了 CRI 标准,用于将 Kubernetes 平台和特定的容器运行时(当然主要是为了干掉 Docker)解耦。
CRI(Container Runtime Interface 容器运行时介绍接口)本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口,所以只要实现了这套接口的容器运行时都可以对接到 Kubernetes 平台上来。不过 Kubernetes 推出 CRI 这套标准的时候还没有现在的统治地位,所以有一些容器运行时介绍可能不会自身就去实现 CRI 接口。**于是就有了 **shim(垫片)**, 一个 shim 的职责就是作为适配器将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上,其中 **dockershim 就是 Kubernetes 对接 Docker 到 CRI 接口上的一个垫片实现。

从上图可以看到,CRI 主要有 gRPC client、gRPC Server 和具体的容器运行时三个组件。其中 Kubelet 作为gRPC 的客户端来调用 CRI 接口;CRI shim 作为 gRPC 服务端来响应 CRI 请求,负责将 CRI 请求的内容转换为具体的容器运行时 API,在 kubelet 和运行时之间充当翻译的角色。具体的容器创建逻辑是,Kubernetes 在通过调度指定一个具体的节点运行 Pod,该节点的 Kubelet 在接到 Pod 创建请求后,调用一个叫作 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求给CRI shim;CRI shim 监听一个端口来响应 Kubelet,在收到 CRI 请求后,将其转化为具体的容器运行时指令,并调用相应的容器运行时来创建 Pod。
CRI规范
所以任何容器运行时想要接入 Kubernetes,都需要实现一个自己的 CRI shim,来实现 CRI 接口规范。
那么 CRI 有哪些接口需要实现呢?
最新的 CRI 定义位于 Kubernetes 源码包 [https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/cri-api/pkg/apis/runtime/v1/api.proto](https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/cri-api/pkg/apis/runtime/v1/api.proto) (api.proto grpc的protobuf),主要定义了两类接口:
ImageService 和 RuntimeService ,比之前的定义多了不少方法。
- ImageService 主要定义拉取镜像、查看和删除镜像等操作。
- RuntimeService 定义了容器相关的操作,包括管理容器的生命周期,以及与容器交互的调用(exec/attach/port-forward)等操作。
可以通过 kubelet 中的标志 --container-runtime-endpoint 和 --image-service-endpoint 来配置这两个服务的套接字。

ImageService 的操作比较简单,就是拉取、删除、查看镜像状态及获取镜像列表这几个操作,下面我们着重介绍下RuntimeService 。
从接口中可以看出 RuntimeService 除了有 container 的管理接口外,还包含 PodSandbox 相关的管理接口和exec 、 attach 等与容器交互的接口。
PodSandbox 这个概念对应的是 Kubernetes 里的 Pod,它描述了 Kubernetes 里的 Pod 与容器运行相关的属性或者信息,如 HostName、CgroupParent 等,设计这个的初衷是因为 Pod 里所有容器的资源和环境信息是共享的,但是不同的容器运行时实现共享的机制不同,如 Docker 中 Pod 会是一个 Linux 命名空间,各容器网络信息的共享通过创建pause 容器的方法来实现,而 Kata Containers 则直接将 Pod 具化为一个轻量级的虚拟机,将这个逻辑抽象为PodSandbox 接口,可以让不同的容器运行时在 Pod 实现上自由发挥,自己解释和实现 Pod 的逻辑。
Exec 、 Attach 和 PortForward 是三个和容器进行数据交互的接口,由于交互数据需要长链接来传输,这些接口被称为 Streaming API 。CRI shim 依赖一套独立的 Streaming Server 机制来实现客户端与容器的交互需求。长连接比较消耗网络资源,为了避免因长连接给 kubelet 节点带来网络流量瓶颈,CRI 要求容器运行时启动一个对应请求的单独的流服务器,让客户端直接与流服务器进行连同交互。
上图所示, kubectl exec 命令实现过程如下:
- 客户端发送 kubectl exec 命令给 apiserver;
- apiserver 调用 kubelet 的 Exec API;
- kubelet 调用 CRI 的 Exec 接口(具体的执行者为实现该接口的 CRI Shim );
- CRI Shim 向 kubelet 返回 Streaming Server 的地址和端口;
- kubelet 以 redirect 的方式返回给 apiserver
- apiserver 通过重定向来向 Streaming Server 发起真正的
/exec/{token}请求,与它建立长连接,完成 Exec 的请求和响应。
kubelet 在引入 CRI 之后,主要的架构如下图所示,其中 Generic Runtime Manager 负责发送容器创建、删除等CRI 请求,Container Runtime Interface(CRI) 负责定义 CRI 接口规范,具体的 CRI 实现可分为两种:kubelet 内置的 dockershim 和远端的 CRI shim。
其中 dockershim 是 Kubernetes 自己实现的适配 Docker接口的 CRI 接口实现,主要用来将 CRI 请求里的内容组装成 Docker API 请求发给 Docker Daemon;
远端的 CRIshim 主要是用来匹配其他的容器运行时工具到kubelet。
CRI shim 主要负责响应 kubelet 发送的 CRI 请求,并将请求转化为具体的运行时命令发送给具体的运行时(如 runc、kata 等);
Stream Server 用来响应客户端与容器的交互。
除此之外,CRI 还提供接入 CNI 的能力以实现 Pod 网络的共享。
常用的远端 CRI 的实现有 CRI-Containerd、CRI-O 等。

为何抛弃Docker
这和 Docker 的整体架构也是有关系的,Docker 最初是一个单体引擎,主要负责容器镜像的制作、上传、拉取及容器的运行及管理。随着容器技术的繁荣发展,为了促进容器技术相关的规范生成和 Docker 自身项目的发展,Docker 将单体引擎拆分为三部分,分别为 runc、containerd 和 dockerd。
其中:
runc 主要负责容器的运行和生命周期的管理、;
containerd 主要负责容器镜像的下载和解压等镜像管理功能;
dockerd 主要负责提供镜像构建、上传等功能,同时提供容器存储和网络的映射功能,同时也是 Docker 服务器端的守护进程,用来响应 Docker 客户端发来的各种容器、镜像管理的任务。
Docker 公司将 runc 捐献给了 OCI,将 containerd 捐献给了 CNCF,剩下的 dockerd 作为 Docker 运行时由 Docker 公司自己维护。
如前所述,Kubernetes 在引入 CRI 之后,kubelet 需要通过 CRI shim 去调用具体的容器运行时工具,由于早期 Kubernetes 对 Docker 的支持是内置的,因此官方自己实现了 dockershim,通过 dockershim 去访问 dockerd。

假设我们使用的是 Docker,当我们在 Kubernetes 中创建一个 Pod 的时候,首先就是 kubelet 通过 CRI 接口调用 dockershim,请求创建一个容器,kubelet 可以视作一个简单的 CRI Client, 而 dockershim 就是接收请求的 Server,不过他们都是在 kubelet 内置的。
dockershim 收到请求后, 转化成 dockerd 能识别的请求, 发到 Docker Daemon 上请求创建一个容器,请求到了 Docker Daemon 后续就是 Docker 创建容器的流程了,去调用 Containerd,然后创建 Containerd-shim 进程,通过该进程去调用 runc 去真正创建容器。
其实我们仔细观察也不难发现使用 Docker 的话其实是调用链太长,真正容器相关的操作其实 Containerd 就完全足够了,Docker 太过于复杂笨重了,当然 Docker 深受欢迎的很大一个原因就是提供了很多对用户操作比较友好的功能,但是对于 Kubernetes 来说压根不需要这些功能,因为都是通过接口去操作容器的,所以自然也就可以将容器运行时切换到 Containerd 来。

切换到 Containerd 可以消除掉中间环节,操作体验也和以前一样,但是由于直接用容器运行时调度容器,所以它们对 Docker 来说是不可见的。 因此,你以前用来检查这些容器的 Docker 工具就不能使用了。
你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。由于不能列出容器,因此也不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
当然我们仍然可以下载镜像,或者用 docker build 命令构建镜像,但用 Docker 构建、下载的镜像,对于容器运行时和 Kubernetes均不可见。为了在 Kubernetes 中使用,需要把镜像推送到镜像仓库中去。
从上图可以看出在 Containerd 1.0 中,对 CRI 的适配是通过一个单独的 CRI-Containerd 进程来完成的,这是因为最开始 Containerd 还会去适配其他的系统(比如 swarm),所以没有直接实现 CRI,所以这个对接工作就交给 CRI-Containerd 这个 shim 了。
然后到了 Containerd 1.1 版本后就去掉了 CRI-Containerd 这个 shim,直接把适配逻辑作为插件的方式集成到了 Containerd 主进程中,现在这样的调用就更加简洁了。
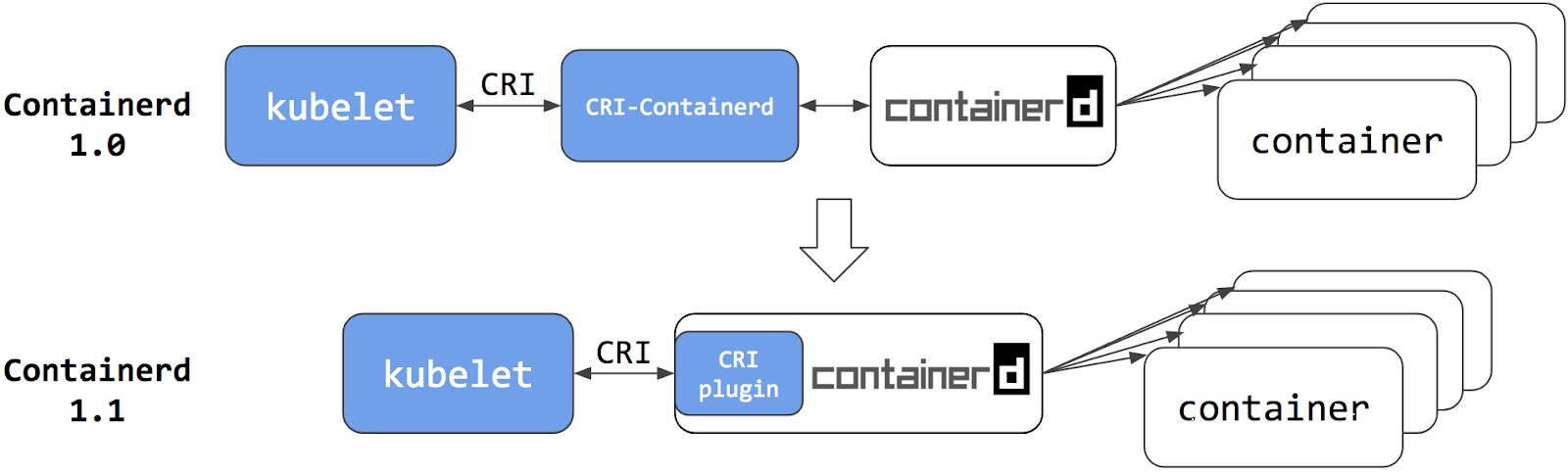
与此同时 Kubernetes 社区也做了一个专门用于 Kubernetes 的 CRI 运行时 CRI-O,直接兼容 CRI 和 OCI 规范。

这个方案和 Containerd 的方案显然比默认的 dockershim 简洁很多,不过由于大部分用户都比较习惯使用 Docker,所以大家还是更喜欢使用 dockershim 方案。
但是随着 CRI 方案的发展,以及其他容器运行时对 CRI 的支持越来越完善,Kubernetes 社区在 2020 年 7 月份就开始着手移除 dockershim 方案了:https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2221-remove-dockershim,现在的移除计划是在 1.20 版本中将 kubelet 中内置的 dockershim 代码分离,将内置的 dockershim 标记为维护模式,当然这个时候仍然还可以使用 dockershim,在 1.24 版本已经移出了 dockershim 代码。
那么这是否就意味这 Kubernetes 不再支持 Docker 了呢?当然不是的,这只是废弃了内置的 dockershim 功能而已,Docker 和其他容器运行时将一视同仁,不会单独对待内置支持,如果我们还想直接使用 Docker 这种容器运行时应该怎么办呢?可以将 dockershim 的功能单独提取出来独立维护一个 cri-dockerd(社区有) 即可,就类似于 Containerd 1.0 版本中提供的 CRI-Containerd,当然还有一种办法就是 Docker 官方社区将 CRI 接口内置到 Dockerd 中去实现。
但是我们也清楚 Dockerd 也是去调用的 Containerd,而 Containerd 1.1 版本后就内置实现了 CRI,所以 Docker 也没必要再去单独实现 CRI 了,当 Kubernetes 不再内置支持开箱即用的 Docker 的以后,最好的方式当然也就是直接使用 Containerd 这种容器运行时,而且该容器运行时也已经经过了生产环境实践的,所以我们也是建议大家使用 Containerd 这种容器运行时的。
🚩
说明:据说,cri-o的性能没有containerd好,并且containerd是已经在生产里经受住了考验,至少目前不推荐使用cri-o,建议使用containerd;
cri-dockerd项目:
https://github.com/Mirantis/cri-dockerd

🚩 注意事项
本地开发依然倾向用docker;
你用docker构建的镜像用contianerd也能跑啊,他们都遵守oci标准;
docker太重了,问题很多,切到containerd以后性能和稳定性都有提升;
其实,现在docker已经在走标准的runc接口了。docker本身的问题:它有一个非常厚重的docker daemon,它本身的稳定性不是很好,所以现在既然它已经走了标准协议了,那么k8s所谓的不支持docker,其实,它可以通过,更轻量级,性能更好,更稳定的容器运行时介绍,例如containerd来替换docker,即docker本身已经在k8s这里已经没有存在的必要了。
为什么这么做?
• Docker内部调用链比较复杂,多层封装和调用,导致性能降低、提升故障率、不易排查;
• Docker还会在宿主机创建网络规则、存储卷,也带来了安全隐患;
如何应对?
在未来的 Kubernetes 版本彻底放弃 Docker 支持之前,引入受支持的容器运行时介绍。
除了docker之外,CRI还支持很多容器运行时介绍,例如:
• containerd:containerd与Docker相兼容,相比Docker轻量很多,目前较为成熟;
• cri-o,podman:都是红帽(RedHat)项目,目前红帽主推podman;
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 个人博客站点

🍀 语雀
https://www.yuque.com/xyy-onlyone
🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!




